Uwaga:W tym artykule przedstawiono migrację modelu relacyjnej bazy danych (RDB) do schematu gwiaździstego przy użyciu środowiska Eclipse IDE for Voracity (i dołączonych produktów), IRI Workbench, po wprowadzeniu do obu architektur. Jeśli jesteś zainteresowany migracją bazy danych lub danych do modelu Data Vault 2.0, nowy kreator Workbench zadebiutuje w World Wide Data Vault Consortium w maju 2019 r.; zasubskrybuj blog IRI, aby otrzymać te szczegółowe instrukcje, gdy tylko zostaną opublikowane!
Hurtownia danych (DW) to zbiór danych wyodrębnionych z systemu operacyjnego lub transakcyjnego w firmie, przekształconych w celu usunięcia niespójności, a następnie uporządkowanych w celu umożliwienia szybkiej analizy i/lub raportowania. DW wymaga schematu lub logicznego opisu i graficznej reprezentacji swojej operacyjnej bazy danych. Ten artykuł porusza te tematy, jednocześnie dostarczając przewodnika, jak przejść z konwencjonalnego schematu relacyjnej bazy danych do popularnego schematu DW, zwanego schematem gwiaździstym.
Schemat gwiazdy kontra relacyjny
Większość relacyjnych struktur danych jest zilustrowanych na diagramach relacji encji (ER). Diagram ER jest używany podczas opracowywania modeli koncepcyjnych dla systemu zarządzania bazą danych przetwarzania transakcji online (OLTP). Jest to źródło, z którego jest tłumaczona struktura tabeli.
Schemat gwiaździsty jest jednak powszechnie akceptowanym standardem podstawowej struktury tabeli hurtowni danych. Jego prosty kształt gwiazdy (gdy ER-diagram) pokazuje tabelę faktów (zawierającą wartości transakcji lub miary) w środku oraz tabele wymiarów (zawierające wartości opisowe lub atrybutowe) promieniujące od niej. Zwykle tabela faktów ma postać trzeciej normalnej (3NF), podczas gdy tabele wymiarów są zdenormalizowane.
Podstawowe różnice między modelem encji (ER) a modelem gwiazdy są następujące:
- Modele ER wykorzystują logiczne i fizyczne struktury do znormalizowanego projektowania baz danych
- Modele wymiarowania wykorzystują fizyczną strukturę do projektowania zdenormalizowanej bazy danych
Aby zobaczyć, jak oprogramowanie IRI może de/normalizować dane poprzez przestawianie wiersz-kolumna, kliknij tutaj.
Tło procesu konwersji
W tym artykule pokazuję, jak konwertować dane z modelu relacyjnego na gwiazdę za pomocą zadań, które należy zdefiniować mniej więcej ręcznie, ale można je tworzyć i uruchamiać automatycznie oraz łatwo modyfikować.
Zobaczysz tutaj dane 4GL i specyfikacje zadań IRI — wyrażone w skryptach „SortCL”[1] — które mapują dane do tabel wymiarów i łączą dane w centralnej tabeli faktów. SortCL to podstawowy program do manipulacji i mapowania danych w IRI Vorcity do zarządzania danymi i na platformie ETL. Kluczem jest jednak zrozumienie metodologii i mapowań w moich zadaniach SortCL, a nie składni skryptów.
Bezpłatny graficzny interfejs użytkownika Eclipse, IRI Workbench, udostępnia edytor SortCL uwzględniający składnię, a także schematy graficzne i okna dialogowe, diagramy przepływu pracy i mapowania oraz intuicyjne kreatory zadań do automatycznego tworzenia lub modyfikowania tych skryptów, jeśli nie chcesz tego robić ręcznie. FYI, IRI używają tych samych metadanych i GUI do profilowania i tworzenia diagramów baz danych, generowania danych testowych, wykonywania ETL, formatowania raportów, maskowania PII, przechwytywania zmienionych danych, migracji i replikacji danych, czyszczenia i weryfikowania danych itp.
Workbench korzysta z rozszerzonej wersji wtyczki Data Tools Platform (DTP) dla środowiska Eclipse do łączenia się z bazami danych przez JDBC oraz do włączania operacji SQL i wymiany metadanych IRI w widoku Data Source Explorer (DSE). W takim przypadku Workbench obsługuje:
- Tworzenie i populacja ograniczonych tabel testowych Oracle (źródłowych) za pośrednictwem SortCL (lub zadań IRI RowGen, zgodnie z tym artykułem)
- mapowanie danych z tabeli encji do tabel wymiarów za pomocą SortCL
- odwzorowanie elementów faktów jako relacji n-arnej w celu skojarzenia głównej tabeli wymiarów; czyli wykonanie połączenia wielu tabel w SortCL w celu utworzenia tabeli faktów
- populacja wszystkich tabel docelowych (schematu gwiaździstego)
- Diagramy ER schematu źródłowego i docelowego
Typy encji w moim oryginalnym modelu relacyjnym to:Dział, Emp, Projekt, Kategoria, Element, Item_Use i Sprzedaż:
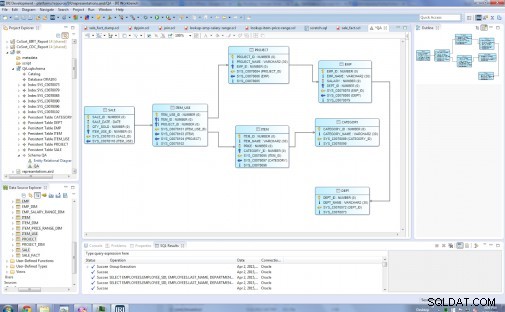
Przed…
Następny diagram pokazuje ostateczny model Star z ośmioma tabelami wymiarów i jedną tabelą faktów. Tabele wymiarów to:Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, Category_Dim, Item_Price_Range_Dim, Item_Dim. Tabela faktów pośrodku to Sale_Fact, która zawiera klucze do wszystkich tabel wymiarów.

… Po
Kroki konwersji
- Zdefiniuj i utwórz tabelę faktów
W tym dokumencie przedstawiono strukturę tabeli Sale_Fact. Kluczem podstawowym jest sale_id, a pozostałe atrybuty to klucze obce odziedziczone z tabel wymiarów. Używam bazy danych Oracle (choć działa każda RDB) połączonej z Workbench DSE (przez JDBC) i SortCL do transformacji i mapowania danych ( przez ODBC). Stworzyłem swoje tabele w skryptach SQL edytowanych w notatniku SQL DSE i wykonywanych w Workbench.
- Zdefiniuj i utwórz tabele wymiarów
Użyj tej samej techniki i metadanych, które zostały połączone powyżej, aby utworzyć te tabele wymiarów, które w następnym kroku otrzymają relacyjne dane mapowane z zadań SortCL:tabela Category_Dim, Dept to Dept_Dim, Project to Project_Dim, Item do Item_Dim i Emp to Emp_Dim. Możesz uruchomić ten program .SQL z całą logiką CREATE naraz, aby zbudować tabele.
- Przenieś oryginalne dane z tabeli Entity do tabel wymiarów
Zdefiniuj i uruchom pokazane tutaj zadania SortCL, aby zmapować dane (testowe utworzone przez RowGen) ze schematu relacyjnego do tabel wymiarów dla schematu Star. W szczególności skrypty te ładują dane z tabeli Category do tabeli Category_Dim, Dept do Dept_Dim, Project do Project_Dim, Item do Item_Dim i Emp do Emp_Dim.
- Wypełnij tabelę faktów
Użyj SortCL, aby połączyć dane z oryginalnych tabel Sale, Emp, Project, Item_Use, Item i Category w celu przygotowania danych dla nowej tabeli Sale_Fact. Użyj drugiego (dołącz do pracy) skryptu tutaj.
Aby ulepszyć nasz przykład, użyjemy również SortCL, aby wprowadzić nowe dane wymiarowe do schematu Star, na którym będzie również opierać się moja tabela faktów. Na powyższym diagramie gwiazdy widać te dodatkowe tabele, których nie było w moim schemacie relacyjnym:Emp_Salary_Range_Dim i Item_Price_Range_Dim. Te tabele są tworzone w tym samym pliku .SQL dla tabeli faktów i innych tabel wymiarów.
Tabela faktów wymaga danych emp_salary_range_id i item_price_range_id z tych tabel, aby reprezentować zakres wartości w tych tabelach wymiarów. Kiedy na przykład ładuję wartości cen wymiarowych do hurtowni danych, chcę przypisać je do przedziału cenowego:
| Item_Price | Range_Id | Range_Name | Zakres_Koniec |
|---|---|---|---|
| 1 | Niski | 1 | 100 |
| 2 | Środek | 101 | 500 |
| 3 | Wysokie | 501 | 999 |
Najprostszym sposobem przypisania identyfikatorów zakresów w skrypcie zadania (czyli przygotowującym dane dla mojej tabeli Sale_Fact) jest użycie instrukcji IF-THEN-ELSE w sekcji danych wyjściowych. Zobacz ten artykuł na temat grupowania wartości w tle.
W każdym razie stworzyłem całą tę pracę za pomocą Nowej oferty dołączania CoSort kreatora w Workbenchu. A kiedy go uruchomiłem, moja tabela faktów została wypełniona:
 Wyświetlanie tabeli Sale_Fact w IRI Workbench DSE
Wyświetlanie tabeli Sale_Fact w IRI Workbench DSE
Wniosek
Główną zaletą reprezentacji danych wymiarowych jest zmniejszenie złożoności struktury bazy danych. Ułatwia to ludziom zrozumienie i pisanie zapytań dzięki zminimalizowaniu liczby tabel, a tym samym liczby wymaganych sprzężeń. Jak wspomniano wcześniej, modele wymiarowe optymalizują również wydajność zapytań. Ma jednak zarówno słabość, jak i siłę. Stała struktura Star Schema ogranicza zapytania. Tak więc, ponieważ ułatwia pisanie najczęstszych zapytań, ogranicza również sposób analizy danych.
IRI Workbench GUI for Vorcity zawiera potężny i wszechstronny zestaw narzędzi, które upraszczają integrację danych, w tym tworzenie, konserwację i rozbudowę hurtowni danych. Dzięki temu intuicyjnemu, łatwemu w użyciu interfejsowi Vorality umożliwia szybkie, elastyczne, kompleksowe tworzenie procesów ETL (wyodrębnianie, przekształcanie, ładowanie) obejmujące struktury danych na różnych platformach.
W operacjach ETL dane są wyodrębniane z różnych źródeł, oddzielnie przekształcane i ładowane do hurtowni danych i ewentualnie innych celów. Budowanie procesu ETL jest potencjalnie jednym z największych zadań budowy magazynu; jest to złożone i czasochłonne. Podejście IRI ETL wspiera ten proces w bardzo wydajny i niezależny od bazy danych sposób, wykonując całą integrację danych i przemieszczanie w systemie plików.
[1] Jeśli jesteś miłośnikiem składni, pamiętaj, że skrypty SortCL używane w produkcie IRI CoSort lub platformie IRI Voracity obsługują tę samą składnię i definicje danych, co IRI RowGen do generowania danych testowych, IRI NextForm do migracji danych oraz IRI FieldShield do maskowania danych. Wszystkie te narzędzia są obsługiwane w graficznym interfejsie użytkownika IRI Workbench, a ich metadane można również udostępniać i zarządzać zespołem w celu kontroli wersji, pochodzenia zadań/danych oraz bezpieczeństwa w chmurze.
[2] Aby wyświetlić diagramy E-R w IRI Workbench:
- Wybierz Nowy projekt IRI i utwórz nowy folder
- Wybierz ten folder i zaznacz wszystkie odpowiednie tabele bazy danych w Eksploratorze źródeł danych; następnie kliknij prawym przyciskiem myszy IRI, Nowy schemat ER
- Plik (Schema.QA) zostanie utworzony
- Kliknij prawym przyciskiem myszy ten plik i wybierz Nowa reprezentacja, Nowy diagram relacji encji.
[3] Elementy diagramu ER ilustrujące takie modele obejmują:
- zdefiniowane typy jednostek
- zdefiniowane atrybuty
- związek między typami jednostek
- ogólny obraz lub diagram koncepcyjny
[4] IRI FACT i SQL*Loader są odpowiednio opcjami zbiorczego wyodrębniania i ładowania.