Aby wdrożyć obsługę wielu języków w swoim modelu danych, nie musisz wymyślać koła na nowo. Ten artykuł pokaże Ci różne sposoby na zrobienie tego i pomoże Ci wybrać ten, który najbardziej Ci odpowiada.
Koncepcja lokalizacji ma kluczowe znaczenie dla rozwoju aplikacji, zwłaszcza gdy jej zakres jest globalny. Obsługa wielu języków jest głównym aspektem do rozważenia; projekt bazy danych, który obsługuje aplikację wielojęzyczną, pozwala na dywersyfikację rynków docelowych, a tym samym dotarcie do znacznie większej liczby klientów. Poza tym taki projekt bazy danych może być częścią Twojej długoterminowej strategii projektowania systemów gotowych do lokalizacji.
Kluczem do włączenia obsługi wielu języków do aplikacji jest zrobienie tego w sposób, który nie zwiększy drastycznie kosztów rozwoju lub utrzymania. Ponieważ modelowanie baz danych jest nieodłączną częścią procesu tworzenia oprogramowania, musisz pomyśleć o najlepszej strategii projektowania modelu danych, aby zapewnić swojej aplikacji obsługę wielu języków.
Właściwy model danych powinien umożliwiać modyfikację aplikacji lub dodanie nowych funkcjonalności przy zachowaniu obsługi wielu języków – bez dodatkowych nakładów pracy i kosztów. Powinno również umożliwiać włączanie nowych języków bez dotykania aplikacji; wystarczy dodać odpowiednie dane tłumaczenia do bazy danych.
Prosta implementacja a elastyczność i funkcjonalność
Istnieją różne podejścia do tworzenia projektu bazy danych dla aplikacji wielojęzycznych. Każda ma swoje wady i zalety. Te, które są łatwiejsze do wdrożenia, oferują mniejszą elastyczność i mniejszą funkcjonalność; te, które oferują większą elastyczność i funkcjonalność, mają bardziej złożone implementacje.
Radzę zawsze wybierać te, które oferują większą funkcjonalność i elastyczność , nawet jeśli ich wdrożenie jest droższe. Czasami popełniamy błąd myśląc, że aplikacja jest za mała, że nie warto wdrażać skomplikowanych schematów do rozwiązywania problemów takich jak obsługa wielu języków. Ale w końcu ta aplikacja będzie się rozwijać i będziemy żałować, że wybraliśmy „szybkie i brudne” podejście, które wydawało się prostsze i tańsze.
Idealnym rozwiązaniem do implementacji funkcji dodatkowych w aplikacji – czy to obsługa wielu języków, rejestrowanie zmian, uwierzytelnianie użytkowników, czy coś innego – jest posiadanie przez tę funkcjonalność własnego podschematu i logiki zawartej w składnikach wielokrotnego użytku. W ten sposób zarówno funkcjonalność akcesoriów, jak i ich podschemat można włączyć do dowolnej nowej aplikacji przy minimalnym wysiłku.
Inteligentne narzędzie do projektowania i modelowania baz danych, takie jak Vertabelo, jest bardzo pomocne w efektywnym zarządzaniu schematami i podschematymi. Zapoznaj się również z tymi wskazówkami dotyczącymi lepszego projektowania baz danych i upewnij się, że postępujesz zgodnie z nimi wszystkimi. Zanim zaczniesz rysować swój diagram ER, sugeruję, abyś rozważył tę podstawową serię wskazówek dotyczących modelowania baz danych.
Niektóre atrakcyjne (ale niewskazane) wielojęzyczne rozwiązania do projektowania baz danych
Najłatwiejszy – ale najmniej zalecany
Zacznijmy od najmniej zalecanego, ale najłatwiejszego sposobu na zaimplementowanie wielojęzycznej bazy danych aplikacji. Pozwala szybko rozwiązać potrzebę obsługi aplikacji wielojęzycznej, ale przyniesie problemy, gdy aplikacja zwiększy swoją funkcjonalność lub zasięg geograficzny.
Ta prosta strategia polega na dodaniu dodatkowej kolumny dla każdej kolumny tekstu wymagającego tłumaczenia i dla każdego języka, na który tekst musi zostać przetłumaczony.
Na przykład w sekcji Movies tabela poniżej znajduje się OriginalTitle pole. Do każdego języka do tłumaczenia dodawana jest dodatkowa kolumna tytułu:
| Identyfikator filmu | Oryginalny tytuł | Title_sp | Tytuł_it | Title_fr |
|---|---|---|---|---|
| 1 | Twardo na śmierć | Czas trwania | Trappola di cristallo | Piege de cristal |
| 2 | Powrót do przyszłości | Zmieniaj przyszłość | Przyszłość | Powrót do przyszłości |
| 3 | Park Jurajski | Park jurásico | Giurassico parco | Park jurajski |
Aplikacja musi pobrać dane opisowe z kolumny odpowiadającej wybranemu przez użytkownika językowi. Gdy potrzebujesz dodać nowy język, musisz dodać do tabeli dodatkową kolumnę, aby zawierała teksty przetłumaczone na nowy język. Musisz również dostosować aplikację, aby potwierdzała dodany język i kolumny.
Rozwiązanie to nie wymaga skomplikowanych JOIN w celu uzyskania przetłumaczonych tekstów, ani nie wymaga duplikowania rekordów – jedynie replikacji kolumn z treścią tekstu. Ale jego zastosowanie jest ograniczone do sytuacji, w których trzeba przetłumaczyć tylko kilka tabel.
Załóżmy na przykład, że masz Products tabela i Processes stół. Każdy z nich ma pole Opis, które wymaga tłumaczenia; wydaje się dość łatwe, prawda? Ale jeśli cała aplikacja (w tym wszystkie jej opcje menu, komunikaty o błędach itp.) musi być wielojęzyczna, to rozwiązanie nie ma zastosowania.
Bardziej wszechstronny, ale też niewskazany
Kontynuując ideę utrzymywania tłumaczeń w tej samej tabeli, alternatywą dla poprzedniej opcji jest powiększenie pól tekstowych. To pozwoliłoby nam przechowywać wszystkie tłumaczenia w tym samym polu, organizując je w strukturę danych (np. dokument XML lub obiekt JSON). Poniżej mamy przykład:
| Identyfikator filmu | Oryginalny tytuł | Tłumaczenia |
| 1 | Trudne do śmierci | [ {"language":"sp", "title":"Duro de matar"}, {"language":"it", "title":"Trappola di cristallo"}, {"język":"fr", "title":"Piège de cristal"} ] |
| 2 | Powrót do przyszłości | [ {"language":"sp", "title":"Volver al futuro"}, {"language":"it", "title":"Ritorno al futuro"}, {"language":"fr", "title":"Retour vers le futur"} ] |
| 3 | Park Jurajski | [ {"language":"sp", "title":"Parque jurásico"}, {"language":"it", "title":"Giurassico parco"}, {"language":"fr", "title":"Parc jurassique"} ] |
Ta opcja nie wymaga dodatkowych kolumn, ale zwiększa złożoność. Zapytania o dane muszą teraz być w stanie poprawnie przetworzyć i zinterpretować strukturę danych używaną do obsługi wielu języków. Na przykład, jeśli JSON lub XML jest używany do przechowywania tłumaczeń, zapytania SQL muszą używać wersji SQL, która obsługuje wybrany typ danych.
Następujące polecenie SQL używa MS SQL Server OPENJSON() funkcja do korzystania z zawartości Translations pole jako tabela podrzędna:
SELECT m.MovieId, m.OriginalTitle, t.TranslatedTitle FROM Movies AS m CROSS APPLY OPENJSON(m.Translations) WITH ( language char(2) '$.language', TranslatedTitle varchar(100) '$.title’ ) AS t WHERE t.language = 'fr';
Ponieważ nie ma funkcji ani operatorów do manipulowania danymi w formacie JSON lub XML w standardowym SQL, jesteś zmuszony do pisania zapytań dla konkretnego RDBMS, jeśli chcesz użyć tej techniki do przechowywania przetłumaczonych tekstów. Na przykład poprzednie zapytanie nie jest obsługiwane przez MySQL. Jeśli chcesz przeczytać dane JSON w Movies tabeli z MySQL, napisałbyś to zapytanie:
SELECT m.MovieId, m.OriginalTitle, JSON_EXTRACT(m.Translations, '$.title') AS TranslatedTitle FROM Movies AS m WHERE JSON_EXTRACT(m.Translations. '$.language') = 'fr';
Przechowywanie przetłumaczonego tekstu w różnych rekordach
Możesz także użyć różnych rekordów dla każdego języka. Musisz jednak pogodzić się z utratą normalizacji:te same dane powtarzają się w kilku rekordach, w których zmienia się tylko tłumaczenie.
| Identyfikator filmu | Identyfikator języka | Tytuł |
|---|---|---|
| 1 | pl | Twardo na śmierć |
| 1 | sp | Czas trwania |
| 1 | to | Trappola di cristallo |
| 1 | fr | Piege de cristal |
| 2 | pl | Powrót do przyszłości |
| 2 | sp | Zmieniaj przyszłość |
| 2 | to | Przyszłość |
Dzięki tej opcji możesz tworzyć widoki każdej tabeli, które zwracają tylko wiersze w danym języku:
CREATE VIEW Movies_en AS SELECT MovieId, Title FROM Movies WHERE LanguageId = 'en'; CREATE VIEW Movies_sp as SELECT MovieId, Title FROM Movies WHERE LanguageId = 'sp';
Następnie, aby wysłać zapytanie do tabeli, możesz użyć innego widoku, zgodnie z docelowym językiem tłumaczenia. Ale normalizacja modelu zostaje utracona, a utrzymanie tabeli jest niepotrzebnie skomplikowane.
Przechowywanie przetłumaczonego tekstu w oddzielnych tabelach
Jednym ze sposobów przechowywania przetłumaczonych tekstów bez naruszania modelu relacyjnego jest posiadanie tabeli szczegółów dla każdej tabeli zawierającej teksty do przetłumaczenia. Tabela podrzędna zawierająca tłumaczenia musi mieć te same pola kluczowe co tabela macierzysta, plus pole wskazujące język tłumaczenia.
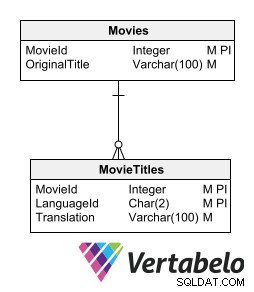
Tabela podrzędna z tłumaczeniami musi mieć te same pola kluczowe co tabela macierzysta, plus pole wskazujące język tłumaczenia.
Ta opcja umożliwia dodawanie nowych języków bez zmiany struktury tabeli. Nie wymaga generowania zbędnych informacji ani przerywania normalizacji modelu.
Wadą tej opcji jest to, że wymaga utworzenia podrzędnej tabeli dla każdej tabeli, która przechowuje dane tekstowe wymagające tłumaczenia. Jednak pomysł przechowywania tłumaczeń w powiązanych tabelach przybliża nas do najbardziej wskazanego sposobu projektowania wielojęzycznej bazy danych.
Uniwersalne rozwiązanie:podschemat tłumaczenia
Aby aplikacja i jej baza danych były naprawdę wielojęzyczne, wszystkie teksty powinny mieć tłumaczenie na każdy z obsługiwanych języków – a nie tylko dane tekstowe w określonej tabeli. Osiąga się to za pomocą podschematu tłumaczenia, w którym przechowywane są wszystkie dane o treści tekstowej, które mogą dotrzeć do oczu użytkownika.
W aplikacjach internetowych przeznaczonych do użytku w różnych językach podschemat tłumaczenia jest koniecznością, a nie opcją. Wszystko inne doprowadzi do komplikacji, które uniemożliwią prawidłowe utrzymanie aplikacji.
Kluczem do trzymania tłumaczeń w osobnym schemacie jest utrzymywanie indeksowanego katalogu ze wszystkimi tekstami, które wymagają tłumaczenia, niezależnie od tego, czy są to opisy jednostek, komunikaty o błędach, czy opcje menu. Pomysł polega na tym, że żaden tekst, który może dotrzeć do oczu użytkownika, nie jest przechowywany w żadnej tabeli poza tym podschematem.
Jednym ze sposobów uporządkowania katalogu tłumaczeń jest użycie trzech tabel:
- Wzorcowa tabela języków.
- Tabela tekstów w oryginalnym języku.
- Tabela przetłumaczonych tekstów.
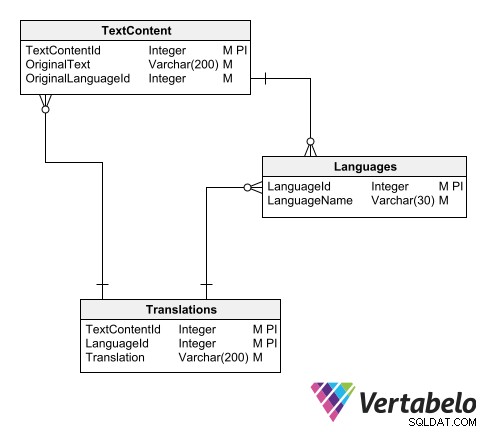
Schemat uniwersalnego katalogu tłumaczeń.
W głównej tabeli języków po prostu wstawiamy rekord dla każdego języka obsługiwanego przez model danych. Każdy z nich ma kod identyfikacyjny i nazwę:
| Identyfikator języka | Nazwa języka |
|---|---|
| pl | angielski |
| sp | hiszpański |
| to | włoski |
| fr | Francuski |
W tabeli tekstowej zapisywane są wszystkie teksty, które wymagają tłumaczenia. Każdy rekord ma dowolny identyfikator, oryginalny tekst i identyfikator oryginalnego języka.
W TextContent tabeli, oryginalny tekst i identyfikator oryginalnego języka nie są bezwzględnie konieczne. Upraszczają jednak zapytania, które nie wymagają tłumaczenia. Na przykład podczas wykonywania analiz statystycznych lub zapytań kontrolnych zarządzania (które są zwykle dostępne tylko dla użytkowników rozumiejących język oryginalny) zapytania można uprościć, używając domyślnych (nieprzetłumaczonych) tekstów.
Teksty oryginalne są również przydatne dla tych, którzy muszą wypełnić tabelę przetłumaczonych tekstów. Wprowadzanie danych tłumaczeniowych może odbywać się za pomocą miniaplikacji pokazującej oryginalny tekst i tłumaczenia we wszystkich dostępnych językach. Możliwe jest również generowanie informacji dla podschematu tłumaczenia za pomocą automatycznego procesu przy użyciu interfejsu API tłumaczenia.
Łączenie z głównym schematem
W głównym schemacie aplikacji kolumny z wartościami tekstowymi, które wymagają przetłumaczenia, są zastępowane identyfikatorami wskazującymi na tabelę przetłumaczonych tekstów:
Główny schemat jest połączony ze schematem tłumaczenia za pomocą tabel z tekstami, które wymagają tłumaczenia.
Możesz zostawić oryginalne pole tekstowe w niektórych głównych tabelach schematów, aby ułatwić zapytania, w których tłumaczenie nie jest wymagane, nawet jeśli generuje to zbędne informacje. Na przykład możemy zachować ProductDescription pole w Products tabela w celu ułatwienia zapytań statystycznych lub wypełnienia wymiarów hurtowni danych, pomijając podschemat tłumaczenia, gdy nie jest on potrzebny.
- Wielojęzyczny projekt bazy danych:zrób to raz i zrób to dobrze
Widzieliśmy kilka alternatyw dla tworzenia wielojęzycznego projektu bazy danych. Niektóre są łatwiejsze i szybsze do wdrożenia. Ostatnie rozwiązanie jest nieco bardziej złożone, ale daje znacznie większą elastyczność. Zaoszczędzi Ci to również kłopotów, gdy przyjdzie czas na utrzymanie aplikacji i bazy danych. W ten sposób na dłuższą metę będzie znacznie tańszy.
Czasami najkrótsza ścieżka w projektowaniu bazy danych skłania do przekonania, że zaoszczędzisz czas i wysiłek. Ale kiedy ją wybierzesz, przeoczysz fakt, że prawdopodobnie będziesz musiał zejść na nią kilka razy. Jeśli zignorujesz najlepsze praktyki dotyczące wielojęzycznego projektowania baz danych, prawdopodobnie będziesz wykonywał tę samą pracę w kółko.