Możesz pomyśleć, że utrzymanie bazy danych to nie twoja sprawa. Ale jeśli projektujesz swoje modele proaktywnie, otrzymujesz bazy danych, które ułatwiają życie tym, którzy muszą nimi zarządzać.
Dobry projekt bazy danych wymaga proaktywności, dobrej jakości w każdym środowisku pracy. Jeśli nie jesteś zaznajomiony z tym terminem, proaktywność to umiejętność przewidywania problemów i przygotowania rozwiązań w przypadku ich wystąpienia – lub jeszcze lepiej, planowania i działania tak, aby problemy w ogóle się nie pojawiały.
Pracodawcy rozumieją, że proaktywność ich pracowników lub kontrahentów to oszczędność kosztów. Dlatego cenią to i zachęcają ludzi do jej praktykowania.
W roli projektanta danych najlepszym sposobem wykazania proaktywności jest projektowanie modeli, które przewidują i unikają problemów, które rutynowo nękają konserwację baz danych. A przynajmniej znacznie upraszcza rozwiązanie tych problemów.
Nawet jeśli nie jesteś odpowiedzialny za konserwację bazy danych, modelowanie łatwej konserwacji bazy danych przynosi wiele korzyści. Na przykład zapobiega wzywaniu Cię w dowolnym momencie w celu rozwiązania problemów związanych z danymi, które zabierają cenny czas, który mógłbyś poświęcić na zadania związane z projektowaniem lub modelowaniem, które tak bardzo lubisz!
Ułatwianie życia informatykom
Projektując nasze bazy danych, musimy wyjść poza dostarczanie DER i generowanie skryptów aktualizacji. Gdy baza danych trafi do produkcji, inżynierowie utrzymania ruchu muszą radzić sobie z wszelkiego rodzaju potencjalnymi problemami, a częścią naszego zadania jako modelarzy baz danych jest zminimalizowanie prawdopodobieństwa wystąpienia tych problemów.
Zacznijmy od przyjrzenia się, co to znaczy stworzyć dobry projekt bazy danych i jak ta czynność wiąże się z regularnymi zadaniami konserwacji bazy danych.
Co to jest modelowanie danych?
Modelowanie danych to zadanie polegające na stworzeniu abstrakcyjnej, zwykle graficznej reprezentacji repozytorium informacji. Celem modelowania danych jest ujawnienie atrybutów i relacji między podmiotami, których dane są przechowywane w repozytorium.
Modele danych są budowane wokół potrzeb problemu biznesowego. Reguły i wymagania są definiowane z wyprzedzeniem dzięki wkładowi ekspertów biznesowych, dzięki czemu można je włączyć do projektu nowego repozytorium danych lub dostosować w iteracji istniejącego.
Idealnie, modele danych to żywe dokumenty, które ewoluują wraz ze zmieniającymi się potrzebami biznesowymi. Odgrywają ważną rolę we wspieraniu decyzji biznesowych oraz w planowaniu architektury i strategii systemów. Modele danych muszą być zsynchronizowane z bazami danych, które reprezentują, aby były przydatne w procedurach konserwacji tych baz danych.
Typowe wyzwania związane z konserwacją bazy danych
Utrzymanie bazy danych wymaga ciągłego monitorowania, zautomatyzowanego lub innego, aby upewnić się, że nie straci ona swoich zalet. Najlepsze praktyki w zakresie konserwacji baz danych zapewniają, że bazy danych zawsze zachowują swoje:
- Integralność i jakość informacji
- Wydajność
- Dostępność
- Skalowalność
- Możliwość dostosowania do zmian
- Identyfikowalność
- Bezpieczeństwo
Dostępnych jest wiele wskazówek dotyczących modelowania danych, które pomogą Ci za każdym razem stworzyć dobry projekt bazy danych. Te omówione poniżej mają na celu w szczególności zapewnienie lub ułatwienie utrzymania wyżej wymienionych cech bazy danych.
Integralność i jakość informacji
Podstawowym celem najlepszych praktyk dotyczących konserwacji bazy danych jest zapewnienie integralności informacji w bazie danych. Ma to kluczowe znaczenie dla zachowania wiary użytkowników w informacje.
Istnieją dwa rodzaje integralności:integralność fizyczna i spójność logiczna .
Integralność fizyczna
Utrzymanie fizycznej integralności bazy danych odbywa się poprzez ochronę informacji przed czynnikami zewnętrznymi, takimi jak awarie sprzętu lub zasilania. Najpopularniejszym i powszechnie akceptowanym podejściem jest zastosowanie odpowiedniej strategii tworzenia kopii zapasowych, która umożliwia odzyskanie bazy danych w rozsądnym czasie, jeśli zniszczy ją katastrofa.
Dla administratorów baz danych i administratorów serwerów, którzy zarządzają przechowywaniem baz danych, warto wiedzieć, czy bazy danych można podzielić na sekcje o różnej częstotliwości aktualizacji. Dzięki temu mogą zoptymalizować wykorzystanie pamięci masowej i plany tworzenia kopii zapasowych.
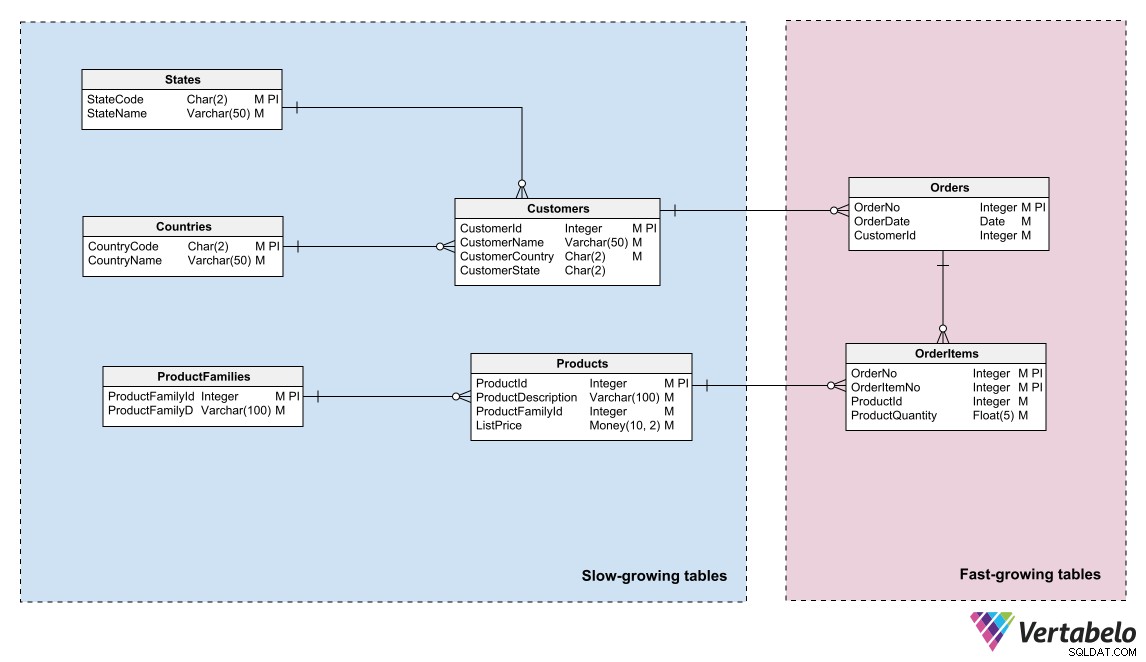
Modele danych mogą odzwierciedlać ten podział, identyfikując obszary o różnych „temperaturach” danych i grupując jednostki w te obszary. „Temperatura” odnosi się do częstotliwości, z jaką tabele otrzymują nowe informacje. Tabele, które są aktualizowane bardzo często, są „najgorętsze”; te, które nigdy lub rzadko są aktualizowane, są „najzimniejsze”.

Model danych systemu e-commerce rozróżniający gorące, ciepłe i zimne dane.
Administrator DBA lub administrator systemu może użyć tego logicznego grupowania do partycjonowania plików bazy danych i tworzenia różnych planów tworzenia kopii zapasowych dla każdej partycji.
Integralność logiczna
Utrzymanie logicznej integralności bazy danych ma zasadnicze znaczenie dla wiarygodności i użyteczności dostarczanych przez nią informacji. Jeśli baza danych nie ma logicznej spójności, aplikacje, które z niej korzystają, prędzej czy później ujawnią niespójności w danych. W obliczu tych niespójności użytkownicy nie ufają informacjom i po prostu szukają bardziej wiarygodnych źródeł danych.
Wśród zadań związanych z utrzymaniem bazy danych utrzymanie logicznej integralności informacji jest rozszerzeniem zadania modelowania bazy danych, tyle że rozpoczyna się ono po wprowadzeniu bazy danych do produkcji i trwa przez cały okres jej istnienia. Najbardziej krytyczną częścią tego obszaru konserwacji jest dostosowywanie się do zmian.
Zarządzanie zmianami
Zmiany reguł biznesowych lub wymagań są stałym zagrożeniem dla logicznej integralności baz danych. Możesz czuć się zadowolony ze zbudowanego modelu danych, wiedząc, że jest on doskonale dostosowany do biznesu, że odpowiada właściwymi informacjami na każde zapytanie oraz że pomija wszelkie anomalie związane z wstawianiem, aktualizacją lub usuwaniem. Ciesz się tą chwilą satysfakcji, ponieważ jest ona krótkotrwała!
Utrzymanie bazy danych wiąże się z koniecznością codziennego wprowadzania zmian w modelu. Zmusza Cię do dodawania nowych obiektów lub zmiany istniejących, modyfikowania liczności relacji, ponownego definiowania kluczy podstawowych, zmiany typów danych i robienia innych rzeczy, które przyprawiają nas o dreszcze.
Zmiany dzieją się cały czas. Być może jakieś wymagania zostały źle wyjaśnione od samego początku, pojawiły się nowe wymagania lub przypadkowo wprowadziłeś jakiś błąd w swoim modelu (w końcu my, zajmujący się modelowaniem danych, jesteśmy tylko ludźmi).
Twoje modele muszą być łatwe do modyfikacji, gdy zajdzie potrzeba zmian. Bardzo ważne jest, aby używać narzędzia do projektowania baz danych do modelowania, które umożliwia wersjonowanie modeli, generowanie skryptów do migracji bazy danych z jednej wersji do drugiej i prawidłowe dokumentowanie każdej decyzji projektowej.
Bez tych narzędzi każda zmiana, którą wprowadzasz w swoim projekcie, stwarza zagrożenia dla integralności, które ujawniają się w najbardziej nieodpowiednich momentach. Vertabelo zapewnia całą tę funkcjonalność i dba o utrzymanie historii wersji modelu bez konieczności myślenia o tym.
Automatyczne wersjonowanie wbudowane w Vertabelo jest ogromną pomocą w utrzymaniu zmian w modelu danych.
Zarządzanie zmianami i kontrola wersji są również kluczowymi czynnikami we wprowadzaniu działań związanych z modelowaniem danych w cykl życia oprogramowania.
Refaktoryzacja
Gdy wprowadzasz zmiany do używanej bazy danych, musisz mieć 100% pewność, że żadne informacje nie zostaną utracone i że w wyniku zmian nie zostanie naruszona jej integralność. Aby to zrobić, możesz użyć technik refaktoryzacji. Są one zwykle stosowane, gdy chcesz ulepszyć projekt bez wpływu na jego semantykę, ale można je również wykorzystać do poprawienia błędów projektowych lub dostosowania modelu do nowych wymagań.
Istnieje wiele technik refaktoryzacji. Zwykle stosuje się je, aby tchnąć nowe życie w dotychczasowe bazy danych, a istnieją podręcznikowe procedury, które zapewniają, że zmiany nie zaszkodzą istniejącym informacjom. Napisano o tym całe książki; Polecam je przeczytać.
Podsumowując, możemy pogrupować techniki refaktoryzacji w następujące kategorie:
- Jakość danych: Wprowadzanie zmian zapewniających spójność i spójność danych. Przykłady obejmują dodanie tabeli przeglądowej i migrację do niej danych powtórzonych w innej tabeli oraz dodanie ograniczenia do kolumny.
- Strukturalne: Dokonywanie zmian w strukturach tabeli, które nie zmieniają semantyki modelu. Przykłady obejmują połączenie dwóch kolumn w jedną, dodanie klucza zastępczego i podzielenie kolumny na dwie.
- Integralność referencyjna: Stosowanie zmian w celu upewnienia się, że wiersz, do którego istnieje odwołanie, istnieje w powiązanej tabeli lub że można usunąć wiersz, do którego nie ma odniesień. Przykłady obejmują dodanie ograniczenia klucza obcego do kolumny i dodanie ograniczenia wartości innej niż null do tabeli.
- Architektoniczne: Wprowadzanie zmian mających na celu poprawę interakcji aplikacji z bazą danych. Przykłady obejmują tworzenie indeksu, tworzenie tabeli tylko do odczytu i hermetyzację jednej lub więcej tabel w widoku.
Techniki, które modyfikują semantykę modelu, a także te, które w żaden sposób nie zmieniają modelu danych, nie są uważane za techniki refaktoryzacji. Obejmują one wstawianie wierszy do tabeli, dodawanie nowej kolumny, tworzenie nowej tabeli lub widoku oraz aktualizowanie danych w tabeli.
Utrzymanie jakości informacji
Jakość informacji w bazie danych to stopień, w jakim dane spełniają oczekiwania organizacji dotyczące dokładności, ważności, kompletności i spójności. Utrzymanie jakości danych przez cały cykl życia bazy danych jest niezbędne dla jej użytkowników do podejmowania prawidłowych i świadomych decyzji z wykorzystaniem zawartych w niej danych.
Twoim obowiązkiem jako projektanta danych jest upewnienie się, że Twoje modele utrzymują jakość informacji na najwyższym możliwym poziomie. Aby to zrobić:
- Projekt musi odpowiadać co najmniej trzeciej formie normalnej, aby nie występowały anomalie wstawiania, aktualizacji lub usuwania. Ta uwaga dotyczy głównie baz danych do użytku transakcyjnego, w których dane są regularnie dodawane, aktualizowane i usuwane. Nie dotyczy to ściśle baz danych do użytku analitycznego (tj. hurtowni danych), ponieważ aktualizacja i usuwanie danych są rzadko wykonywane, jeśli w ogóle.
- Typy danych każdego pola w każdej tabeli muszą być odpowiednie do atrybutu, który reprezentują w modelu logicznym. Wykracza to poza właściwe zdefiniowanie, czy pole ma numeryczny, datowany czy alfanumeryczny typ danych. Ważne jest również prawidłowe zdefiniowanie zakresu i precyzji wartości obsługiwanych przez każde pole. Przykład:atrybut typu Date zaimplementowany w bazie danych jako pole Data/Czas może powodować problemy w zapytaniach, ponieważ wartość przechowywana z częścią czasową inną niż zero może wykraczać poza zakres zapytania korzystającego z zakresu dat.
- Wymiary i fakty, które definiują strukturę hurtowni danych, muszą być zgodne z potrzebami firmy. Projektując hurtownię danych należy od samego początku poprawnie zdefiniować wymiary i fakty modelu. Wprowadzanie modyfikacji po uruchomieniu bazy danych wiąże się z bardzo wysokimi kosztami utrzymania.
Zarządzanie rozwojem
Innym poważnym wyzwaniem związanym z utrzymaniem bazy danych jest zapobieganie nieoczekiwanemu osiągnięciu przez jej wzrost limitu pojemności pamięci masowej. Aby pomóc w zarządzaniu przestrzenią dyskową, możesz zastosować tę samą zasadę, co w procedurach tworzenia kopii zapasowych:pogrupuj tabele w swoim modelu zgodnie z tempem ich wzrostu.
Zwykle wystarczy podział na dwa obszary. Umieść tabele z częstymi dodawaniem wierszy w jednym obszarze, a te, do których wiersze są rzadko wstawiane w innym. Podział modelu na sektory w ten sposób umożliwia administratorom pamięci masowej partycjonowanie plików bazy danych zgodnie z tempem wzrostu każdego obszaru. Mogą dystrybuować partycje na różne nośniki pamięci o różnych pojemnościach lub możliwościach wzrostu.
Grupowanie tabel według ich tempa wzrostu pomaga określić wymagania dotyczące pamięci masowej i zarządzać jej wzrostem.
Logowanie
Tworzymy model danych, oczekując od niego dostarczenia informacji takich, jakie są w momencie zapytania. Jednak zwykle pomijamy potrzebę zapamiętywania przez bazę danych wszystkiego, co wydarzyło się w przeszłości, chyba że użytkownicy wyraźnie tego wymagają.
Częścią utrzymania bazy danych jest wiedza jak, kiedy, dlaczego i przez kogo konkretna część danych została zmieniona. Może to dotyczyć takich rzeczy, jak sprawdzenie zmiany ceny produktu lub przegląd zmian w dokumentacji medycznej pacjenta w szpitalu. Rejestrowanie może być używane nawet do poprawiania błędów użytkownika lub aplikacji, ponieważ pozwala cofnąć stan informacji do punktu z przeszłości bez konieczności uciekania się do skomplikowanych procedur przywracania kopii zapasowych.
Ponownie, nawet jeśli użytkownicy nie potrzebują tego wprost, rozważenie potrzeby proaktywnego rejestrowania jest bardzo cennym sposobem na ułatwienie konserwacji bazy danych i zademonstrowanie zdolności przewidywania problemów. Posiadanie danych rejestrowania umożliwia natychmiastową reakcję, gdy ktoś musi przejrzeć informacje historyczne.
Istnieją różne strategie dla modelu bazy danych do obsługi rejestrowania, z których wszystkie zwiększają złożoność modelu. Jedno podejście nazywa się rejestrowaniem w miejscu, które dodaje kolumny do każdej tabeli w celu rejestrowania informacji o wersji. Jest to prosta opcja, która nie wymaga tworzenia osobnych schematów ani tabel specyficznych dla rejestrowania. Ma to jednak wpływ na projekt modelu, ponieważ oryginalne klucze podstawowe tabel nie są już ważne jako klucze podstawowe – ich wartości są powtarzane w wierszach reprezentujących różne wersje tych samych danych.
Inną opcją przechowywania informacji dziennika jest użycie tabel cieni. Tabele cieni to repliki tabel modeli z dodatkiem kolumn do rejestrowania danych dziennika śladu. Ta strategia nie wymaga modyfikowania tabel w oryginalnym modelu, ale musisz pamiętać, aby zaktualizować odpowiednie tabele cieni po zmianie modelu danych.
Jeszcze inną strategią jest zastosowanie podschematu ogólnych tabel, które rejestrują każde wstawienie, usunięcie lub modyfikację dowolnej innej tabeli.
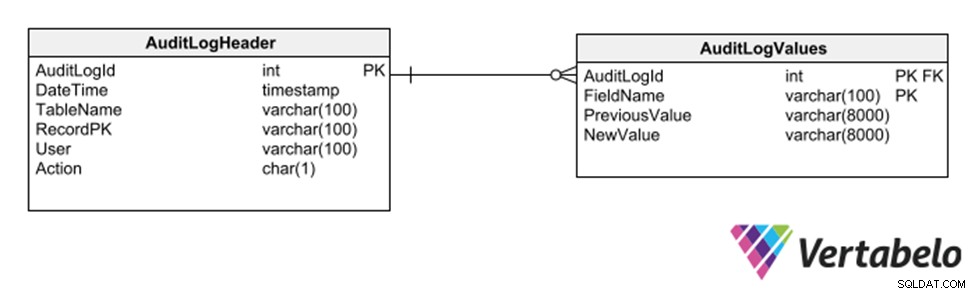
Ogólne tabele do przechowywania ścieżki audytu bazy danych.
Ta strategia ma tę zaletę, że nie wymaga modyfikacji modelu w celu zapisania ścieżki audytu. Jednak ponieważ używa ogólnych kolumn typu varchar, ogranicza typy danych, które mogą być rejestrowane w ścieżce dziennika.
Utrzymanie wydajności i tworzenie indeksów
Praktycznie każda baza danych ma dobrą wydajność, gdy dopiero zaczyna być używana, a jej tabele zawierają tylko kilka wierszy. Jednak gdy tylko aplikacje zaczną wypełniać go danymi, wydajność może bardzo szybko ulec pogorszeniu, jeśli nie zostaną podjęte środki ostrożności podczas projektowania modelu. Kiedy tak się dzieje, administratorzy baz danych i administratorzy systemu proszą Cię o pomoc w rozwiązaniu problemów z wydajnością.
Automatyczne tworzenie/sugerowanie indeksów na produkcyjnych bazach danych jest przydatnym narzędziem do rozwiązywania problemów wydajnościowych „w gorączce chwili”. Silniki baz danych mogą analizować działania bazy danych, aby zobaczyć, które operacje trwają najdłużej i gdzie istnieją możliwości przyspieszenia poprzez tworzenie indeksów.
Jednak znacznie lepiej jest być proaktywnym i przewidywać sytuację, definiując indeksy w ramach modelu danych. To znacznie zmniejsza nakłady na konserwację w celu poprawy wydajności bazy danych. Jeśli nie znasz zalet indeksów baz danych, sugeruję przeczytanie wszystkiego o indeksach, zaczynając od samych podstaw.
Istnieją praktyczne zasady, które zapewniają wystarczające wskazówki dotyczące tworzenia najważniejszych indeksów dla wydajnych zapytań. Pierwszym z nich jest generowanie indeksów dla klucza podstawowego każdej tabeli. Praktycznie każdy RDBMS automatycznie generuje indeks dla każdego klucza podstawowego, więc możesz zapomnieć o tej regule.
Inną zasadą jest generowanie indeksów dla alternatywnych kluczy tabeli, szczególnie w tabelach, dla których tworzony jest klucz zastępczy. Jeśli tabela ma klucz naturalny, który nie jest używany jako klucz podstawowy, zapytania łączące tę tabelę z innymi najprawdopodobniej robią to za pomocą klucza naturalnego, a nie zastępczego. Te zapytania nie działają dobrze, chyba że utworzysz indeks na kluczu naturalnym.
Kolejną praktyczną zasadą dotyczącą indeksów jest generowanie ich dla wszystkich pól będących kluczami obcymi. Te pola są świetnymi kandydatami do ustanawiania złączeń z innymi tabelami. Jeśli są zawarte w indeksach, są używane przez parsery zapytań w celu przyspieszenia wykonania i poprawy wydajności bazy danych.
Na koniec, dobrym pomysłem jest użycie narzędzia do profilowania bazy danych tymczasowej lub kontroli jakości podczas testów wydajności w celu wykrycia wszelkich nieoczywistych możliwości tworzenia indeksów. Włączenie indeksów sugerowanych przez narzędzia do profilowania do modelu danych jest niezwykle pomocne w osiąganiu i utrzymywaniu wydajności bazy danych po jej uruchomieniu.
Bezpieczeństwo
Pełniąc rolę modelarza danych, możesz pomóc w utrzymaniu bezpieczeństwa bazy danych, zapewniając solidną i bezpieczną bazę do przechowywania danych do uwierzytelniania użytkowników. Pamiętaj, że te informacje są bardzo wrażliwe i nie mogą być narażone na cyberataki.
Aby Twój projekt uprościł utrzymanie bezpieczeństwa bazy danych, postępuj zgodnie z najlepszymi praktykami dotyczącymi przechowywania danych uwierzytelniających, z których najważniejszą jest nie przechowywanie haseł w bazie danych nawet w postaci zaszyfrowanej. Przechowywanie tylko jego skrótu zamiast hasła dla każdego użytkownika umożliwia aplikacji uwierzytelnienie logowania użytkownika bez stwarzania ryzyka narażenia na hasło.
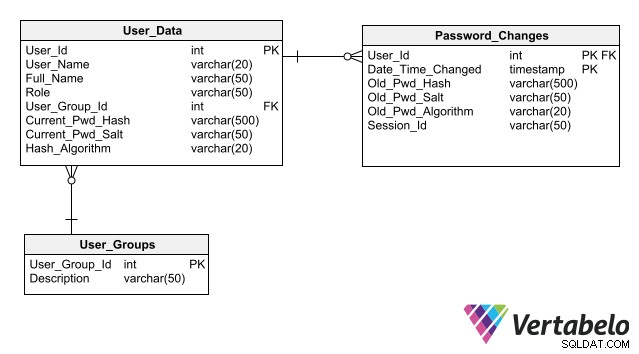
Pełny schemat uwierzytelniania użytkowników, który zawiera kolumny do przechowywania skrótów haseł.
Wizja przyszłości
Dlatego stwórz swoje modele dla łatwej konserwacji bazy danych z dobrymi projektami baz danych, biorąc pod uwagę powyższe wskazówki. Dzięki łatwiejszym w utrzymaniu modelom danych Twoja praca wygląda lepiej i zyskujesz uznanie administratorów baz danych, inżynierów utrzymania ruchu i administratorów systemu.
Inwestujesz również w spokój ducha. Tworzenie łatwych w utrzymaniu baz danych oznacza, że możesz spędzać godziny pracy na projektowaniu nowych modeli danych, zamiast biegać po łataniu baz danych, które nie dostarczają poprawnych informacji na czas.