Inteligentne domy były kiedyś wyłącznie przyszłością; teraz są rzeczywistością. Większość z nas o nich słyszała, ale nie są one tak rozpowszechnione, jak będą w najbliższej przyszłości. Zarządzanie domem w „inteligentny” sposób z pewnością przyniesie dużo danych. Dzisiaj przeanalizujemy model danych, który moglibyśmy wykorzystać do przechowywania danych dotyczących inteligentnego domu.
Model danych
Kiedy myślisz o inteligentnym domu, prawdopodobnie myślisz o zdalnym blokowaniu i odblokowywaniu domu, aktywowaniu alarmów, świateł lub kamer z telefonu, posiadaniu termometrów, które automatycznie zarządzają ogrzewaniem i chłodzeniem itp. Ale inteligentne domy mogą zrobić znacznie więcej. Możesz podłączyć wiele inteligentnych urządzeń i kontrolerów, aby osiągnąć wiele złożonych funkcji. Możesz wysyłać instrukcje do urządzeń lub odczytywać ich statusy z dowolnego miejsca.
Przyjrzyjmy się modelowi danych, który pozwoliłby nam zaimplementować takie funkcjonalności. Oprócz tego modelu danych moglibyśmy zbudować aplikację internetową i aplikację mobilną, które pozwoliłyby zarejestrowanym użytkownikom zarządzać swoimi kontami, wysyłać instrukcje i śledzić statusy.
Model składa się z trzech obszarów tematycznych:
Estates & devicesUsers & profilesCommands & data
Opiszę każdy z tych obszarów tematycznych w kolejności, w jakiej są wymienione. Jednak przede wszystkim opiszę user_account tabela.
Tabela User_Account
Zaczynamy od user_account tabeli, ponieważ jest używany we wszystkich trzech obszarach tematycznych. Przechowuje listę wszystkich zarejestrowanych użytkowników naszej aplikacji.
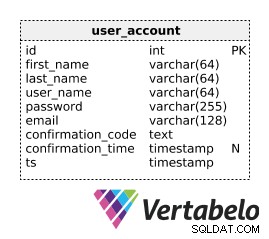
user_account tabela zawiera wszystkie standardowe atrybuty, których można się spodziewać, w tym:
first_nameilast_name– Imię i nazwisko użytkownika.user_name– UNIKALNA nazwa użytkownika wybrana przez użytkownika.password– Wartość skrótu hasła użytkownika.email– Adres e-mail podany przez użytkownika podczas procesu rejestracji.confirmation_code– Kod wygenerowany podczas procesu rejestracji.confirmation_time– Znacznik czasu, kiedy użytkownik potwierdził swoje konto i zakończył proces rejestracji.ts– Znacznik czasu, kiedy ten rekord został wstawiony do bazy danych.
Sekcja 1:Komponenty i urządzenia
Cała motywacja do stworzenia tej bazy danych polega na monitorowaniu tego, co dzieje się z naszymi osiedlami (tj. domami lub nieruchomościami). Mogą to być osiedla prywatne, takie jak mieszkania lub domy, lub nieruchomości biznesowe, takie jak biura, magazyny itp. Jeśli naprawdę chcemy wykorzystać nasz system do granic możliwości, możemy go również wykorzystać w pojazdach.
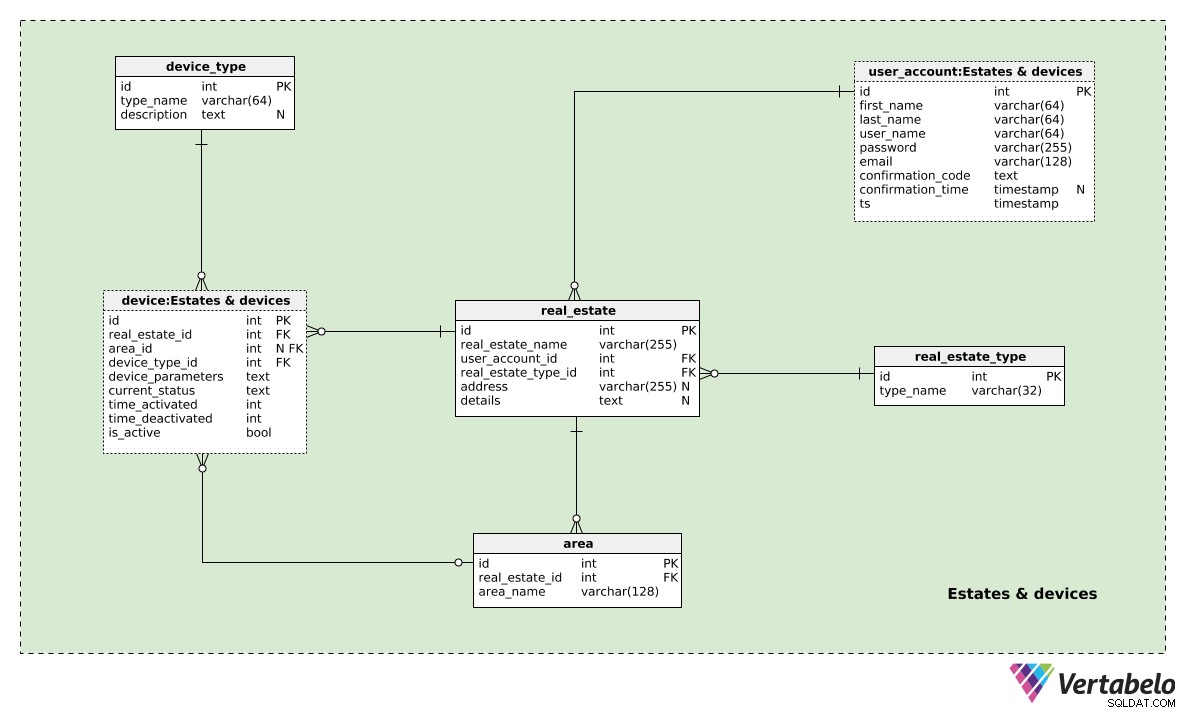
Centralną tabelą w tym obszarze tematycznym jest real_estate stół. Tutaj będziemy przechowywać wszystkie różne osiedla lub nieruchomości połączone z naszą aplikacją inteligentnego domu. Dla każdego osiedla przechowamy:
real_estate_name– Nazwa wybrana przez użytkownika, która odnosi się do określonej właściwości.user_account_id– Identyfikator użytkownika, z którym powiązana jest ta posiadłość. Razem z atrybutem real_estate_name tworzy to UNIKATOWY (alternatywny) klucz tej tabeli.real_estate_type– Wskazuje rodzaj nieruchomości, jaką jest ta nieruchomość.address– Faktyczny adres tej nieruchomości. Jest to nieważne, ponieważ możemy używać tego systemu do innych rodzajów własności (np. pojazdów).details– Wszystkie dodatkowe szczegóły w formacie tekstowym.
Wspomnieliśmy już o rodzajach nieruchomości. Pełna lista możliwych typów jest przechowywana w real_estate_type słownik. Zawiera tylko jedną UNIKALNĄ wartość, type_name . Możemy spodziewać się tutaj wartości takich jak „mieszkanie”, „dom” lub „garaż”.
Jedną nieruchomość można podzielić na kilka obszarów. Mogą to być pokoje w mieszkaniu lub domu; może chcemy zgrupować kilka pokoi razem lub chcemy wszystko związane z podwórkiem lub ogrodem w jednej grupie itp. A może mamy osiedle przemysłowe lub kompleks z kilkoma biurami; jeśli nasza nieruchomość jest naprawdę duża, posiadanie określonych powierzchni może być bardzo przydatne. Aby to osiągnąć, użyjemy area stół. Zawiera UNIKALNĄ parę real_estate_id i area_name wybrany przez użytkownika.
Ostatnie dwie tabele w tym obszarze tematycznym dotyczą urządzeń.
W device_type tabeli, przechowamy pełną listę wszystkich różnych typów urządzeń. Dla każdego typu użyjemy UNIKALNEGO type_name i wstaw dodatkowy description Jeśli potrzebne. Typami urządzeń mogą być różne czujniki (temperatury, gazu), zamki do drzwi lub okien, światła, systemy klimatyzacji i ogrzewania itp.
Teraz jesteśmy gotowi na zabawną część. Użyjemy device tabela do przechowywania listy wszystkich urządzeń wchodzących w skład różnych inteligentnych domów. Urządzenia te są dodawane przez użytkownika, ręcznie lub automatycznie, jeśli urządzenie ma taką opcję. Dla każdego urządzenia musimy przechowywać:
real_estate_id– Identyfikator nieruchomości, w której zainstalowano to urządzenie.area_id– Odwołuje się doareagdzie to urządzenie jest zainstalowane. Jest to wartość opcjonalna, ponieważ posiadłość może być podzielone na obszary, ale też nie może być dzielone.device_type_id– Identyfikatordevice_typeto urządzenie należy.device_parameters– Wykorzystamy ten atrybut do przechowywania wszystkich możliwych parametrów urządzenia (np. interwałów przechowywania danych) w ustrukturyzowanym formacie tekstowym. Te parametry mogą być ustawione przez użytkownika lub część normalnej funkcji urządzenia (np. różne środki).current_status– Aktualny stan parametrów urządzenia.time_activateditime_deactivated– Określ odstęp czasu, w którym to urządzenie było aktywne. Jeślitime_deactivatednie jest ustawione, to urządzenie jest aktywne, ais_activeatrybut jest również ustawiony na True.
Sekcja 2:Użytkownicy i profile
Wspomnieliśmy już o user_account stół. W naszej aplikacji użytkownicy powinni mieć możliwość tworzenia różnych profili i udostępniania ich innym użytkownikom, jeśli chcą.
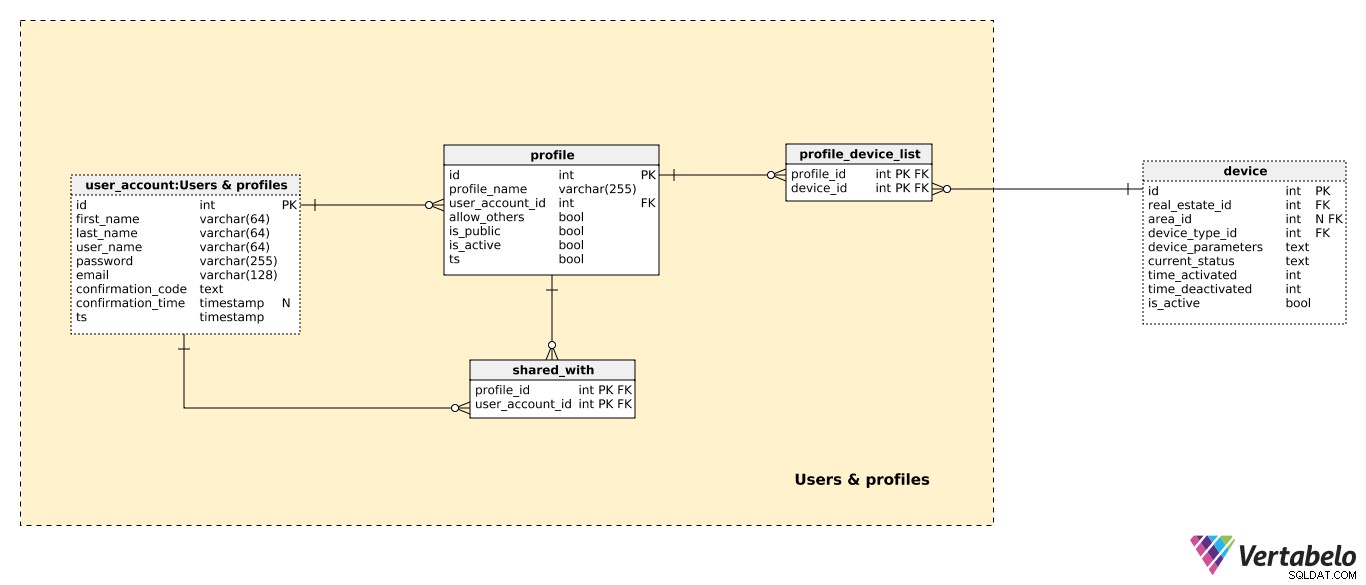
Profile to w zasadzie podzbiory urządzeń zainstalowanych w każdej nieruchomości będącej własnością użytkownika. Każdy użytkownik może mieć jeden lub więcej profili. Chodzi o to, aby użytkownik mógł w odpowiedni sposób pogrupować swoje urządzenia inteligentnego domu. Chociaż użytkownik może mieć jeden profil ze wszystkimi swoimi urządzeniami, może również mieć jeden profil pokazujący tylko kamery frontowe dla wszystkich swoich nieruchomości. A może jeden profil tylko dla termometrów zainstalowanych we wszystkich pokojach w ich mieszkaniu.
Wszystkie profile utworzone przez użytkowników są przechowywane w profile stół. Dla każdego rekordu będziemy mieć:
profile_name– Nazwa profilu wybrana przez użytkownika.user_account_id– Odwołuje się do użytkownika, który utworzył ten profil. Ten atrybut iprofile_nameatrybut z UNIKATOWEGO klucza tabeli.allow_others– Flaga wskazująca, czy ten profil jest udostępniany innym użytkownikom.is_public– Flaga wskazująca, czy ten profil jest widoczny publicznie. Chociaż możemy się spodziewać, że w większości przypadków będzie to Fałsz, mogą się zdarzyć przypadki, gdy będziemy chcieli udostępnić profil wszystkim.is_active– Flaga informująca, czy ten profil jest aktywny, czy nie.ts– Znacznik czasu wstawienia tego rekordu.
Dla każdego profilu zdefiniujemy listę wszystkich zawartych w nim urządzeń. Ta lista jest przechowywana na profile_device_list tabela i zawiera listę UNIKALNYCH profile_id – device_id pary. Ta para kluczy obcych tworzy klucz podstawowy naszej tabeli.
Ostatnia tabela w tym temacie umożliwia użytkownikom udostępnianie swoich profili innym zarejestrowanym użytkownikom. Może to być bardzo przydatne, m.in. jeśli jedna osoba zarządza wszystkim, a inni zarejestrowani użytkownicy (np. członkowie rodziny) chcą przeglądać profile utworzone przez właściciela. W shared_with tabeli, przechowamy listę wszystkich UNIKATOWYCH par profile_id – user_account_id . Po raz kolejny ta para kluczy obcych jest kluczem podstawowym tabeli. Pamiętaj, że udostępnianie będzie działać tylko wtedy, gdy profile.allow_others atrybut jest ustawiony na True.
Sekcja 3:Polecenia i dane
Użyjemy tabel z tego ostatniego obszaru tematycznego do przechowywania komunikacji między użytkownikami i urządzeniami. Będzie to komunikacja dwukierunkowa. Urządzenia będą generować dane podczas swojej pracy, a nasza baza danych będzie je przechowywać, jak również wszelkie komunikaty generowane przez system (lub urządzenia). Użytkownicy będą chcieli widzieć te wiadomości i dane wysyłane przez ich urządzenia. Na podstawie tych danych użytkownicy mogli tworzyć programy do swojego inteligentnego domu. Te programy są ręcznie lub automatycznie generowanymi poleceniami, a nawet seriami poleceń, które zrobią dokładnie to, czego chce każdy użytkownik.
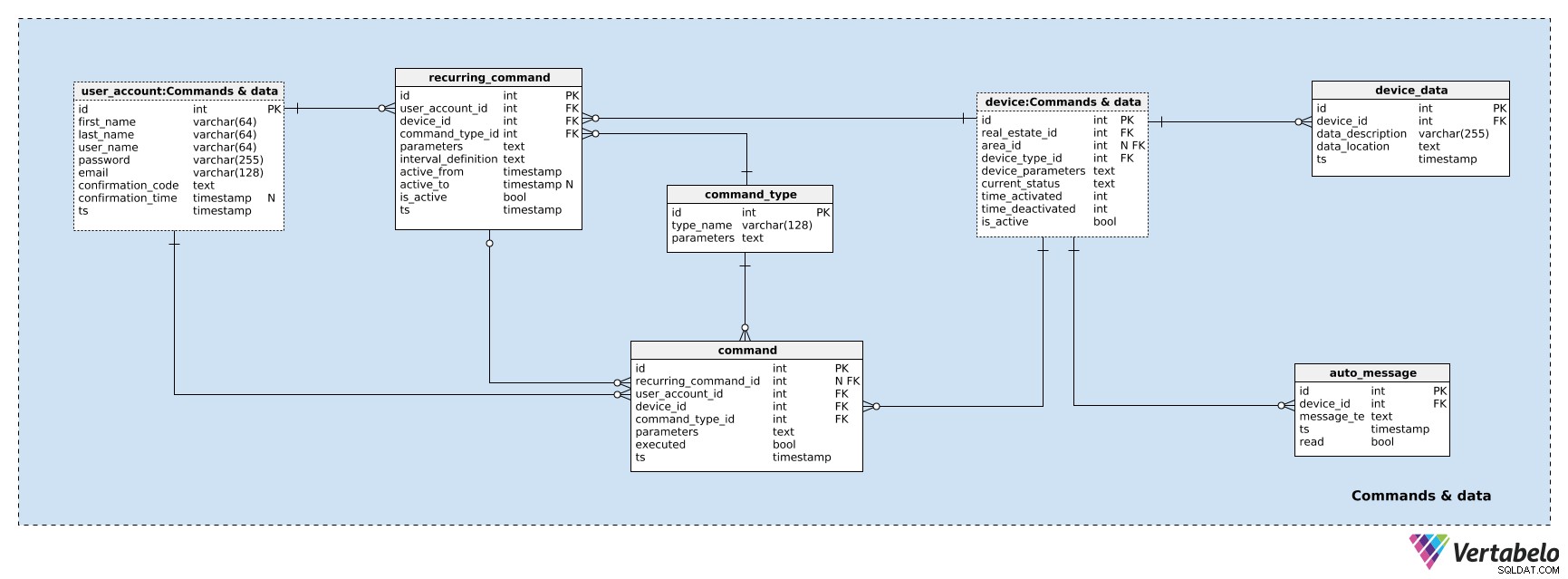
Zaczniemy od urządzeń danych. W device_data tabeli, przechowamy opis danych wygenerowanych przez urządzenie oraz lokalizację(e) danych. Ponownie dane są generowane automatycznie przez urządzenia. Może to być seria pomiarów, statusy (dane tekstowe) lub dane audiowizualne. Dla każdego rekordu w tej tabeli będziemy przechowywać:
device_id– Identyfikator urządzenia, które wygenerowało te dane.data_description– opis przechowywanych danych, m.in. co jest przechowywane, kiedy dane były przechowywane w naszym systemie i w jakim formacie.data_location– Pełna ścieżka do lokalizacji, w której przechowywane są te dane.ts– Znacznik czasu wstawienia tego rekordu.
Dane urządzenia będą przechowywane niezależnie od tego, czy urządzenie działa prawidłowo lub czy dane są poza oczekiwanym zakresem. Jest to w zasadzie dziennik wszystkiego, co zostało zarejestrowane przez urządzenia. Możemy spodziewać się strategii usuwania starych plików danych urządzeń, ale to wykracza poza zakres tego artykułu.
W przeciwieństwie do danych urządzenia możemy oczekiwać, że komunikaty będą generowane tylko wtedy, gdy wydarzy się coś nieoczekiwanego – np. jeśli pomiar urządzenia wykracza poza normalny zakres, jeśli czujnik wykrył ruch itp. W takich przypadkach urządzenie generuje komunikaty. Wszystkie takie wiadomości są przechowywane w auto_message stół. W każdym rekordzie będziemy mieć:
device_id– Identyfikator urządzenia, które wygenerowało tę wiadomość.message_text– Tekst generowany przez urządzenie. Może to być wstępnie zdefiniowany tekst, wartość spoza oczekiwanego zakresu lub kombinacja tych dwóch.ts– Znacznik czasu przechowywania tego rekordu.read– Flaga wskazująca, czy wiadomość została przeczytana przez użytkownika.
Pozostałe trzy tabele służą do przechowywania poleceń użytkowników. Polecenia pozwalają użytkownikom przejąć kontrolę nad sterowanymi urządzeniami i nawiązać dwukierunkową komunikację z inteligentnym domem.
Najpierw zdefiniujemy listę wszystkich możliwych typów poleceń. Mogą to być wartości typu „włącz/wyłącz”, „zwiększ/zmniejsz temperaturę” itp. Moglibyśmy również mieć polecenia warunkowe, tj. polecenia, które są spełnione tylko wtedy, gdy spełniony jest określony warunek. Lista wszystkich różnych typów poleceń jest przechowywana w command_type słownik. Dla każdego typu przechowamy UNIKALNĄ type_name . Przechowamy również listę wszystkich parametrów, które powinny być zdefiniowane dla tego typu polecenia. Będzie to tekst strukturalny z wstawionymi wartościami domyślnymi. Użytkownik ustawi te wartości podczas wstawiania nowych poleceń.
Użytkownik może również zdefiniować wszystkie recurring_commands z przodu. Może chcemy mieć ciepłą wodę codziennie o 7 rano lub aktywować system ogrzewania/chłodzenia codziennie o 16:00. Zestaw reguł i wszystkie atrybuty potrzebne do wykonania powtarzających się poleceń są przechowywane w tej tabeli. Będziemy mieli:
user_account_id– Identyfikator użytkownika, który wstawił to powtarzające się polecenie.device_id– Identyfikator urządzenia związanego z tym powtarzającym się poleceniem.command_type_id– Odwołanie docommand_typesłownik.parameters– Wszystkie parametry, które powinny być zdefiniowane dla tego typu polecenia, wraz z ich pożądanymi wartościami.interval_definition– Odstęp między dwoma powtórzeniami tego polecenia. Podobnie jak w przypadku parametrów poleceń, będzie to uporządkowane pole tekstowe.active_fromiactive_to– Interwał, w którym to polecenie powinno być powtarzane.active_toatrybut może mieć wartość NULL jeśli chcemy aby to polecenie było powtarzane w nieskończoność (lub dopóki nie zdefiniujemyactive_todata).ts– Znacznik czasu wstawienia tego rekordu.
Ostatnia tabela w naszym modelu zawiera listę pojedynczych poleceń. Polecenia te mogą być wstawiane ręcznie przez użytkownika lub generowane automatycznie (tj. w ramach powtarzających się poleceń). Dla każdego polecenia przechowujemy:
recurring_command_id– Identyfikator powtarzającego się polecenia wyzwalającego to polecenie, jeśli istnieje.user_account_id– Identyfikator użytkownika, który wstawił to polecenie.device_id– Identyfikator odpowiedniego urządzenia.command_type_id– Odwołuje się docommand_typesłownik.parameters– Wszystkie parametry związane z tym poleceniem.executed– Flaga wskazująca, czy to polecenie zostało wykonane.ts– Znacznik czasu wstawienia tego rekordu.
Co myślisz o modelu danych inteligentnego domu?
W tym artykule staraliśmy się omówić najważniejsze aspekty zarządzania inteligentnym domem. Jednym z nich jest zdecydowanie dwustronna komunikacja pomiędzy użytkownikiem a systemem. Większość „prawdziwych” akcji jest przechowywana jako parametry tekstowe i te wartości powinny być analizowane podczas wykonywania określonych akcji. Zrobiliśmy to, abyśmy mogli mieć wystarczającą elastyczność do pracy z wieloma różnymi typami urządzeń.
Masz jakieś sugestie, które możesz dodać do naszego modelu inteligentnego domu? Co byś zmienił lub co usunął? Powiedz nam w komentarzach poniżej.