Co jakiś czas pojawia się rozmowa, w której ludzie są przekonani, że komentarze mają lub nie mają wpływu na wydajność.
Ogólnie powiem, że nie, komentarze nie wpływają na wydajność , ale zawsze jest miejsce na zastrzeżenie „to zależy”. Stwórzmy przykładową bazę danych i tabelę pełną śmieci:
CREATE DATABASE CommentTesting; GO USE CommentTesting; GO SELECT TOP (1000) n = NEWID(), * INTO dbo.SampleTable FROM sys.all_columns ORDER BY NEWID(); GO CREATE UNIQUE CLUSTERED INDEX x ON dbo.SampleTable(n); GO
Teraz chcę utworzyć cztery procedury składowane — jedną z 20 znakami komentarzy, jedną z 2000, jedną z 20 000 i jedną z 200 000. I chcę to zrobić ponownie, gdy komentarze są osadzone *w* instrukcji zapytania w ramach procedury, w przeciwieństwie do bycia niezależnymi (co będzie miało wpływ na XML planu). Na koniec powtórzyłem proces dodając OPTION (RECOMPILE) do zapytania.
DECLARE @comments nvarchar(max) = N'',
@basesql nvarchar(max),
@sql nvarchar(max);
SELECT TOP (5000) -- * 40 character strings
@comments += N'--' + RTRIM(NEWID()) + CHAR(13) + CHAR(10)
FROM sys.all_columns;
SET @basesql = N'CREATE PROCEDURE dbo.$name$
AS
BEGIN
SET NOCOUNT ON;
/* $comments1$ */
DECLARE @x int;
SELECT @x = COUNT(*) /* $comments2$ */ FROM dbo.SampleTable OPTION (RECOMPILE);
END';
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Small_Separate'), N'$comments1$', LEFT(@comments, 20));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Medium_Separate'), N'$comments1$', LEFT(@comments, 2000));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Large_Separate'), N'$comments1$', LEFT(@comments, 20000));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'ExtraLarge_Separate'), N'$comments1$', LEFT(@comments, 200000));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Small_Embedded'), N'$comments2$', LEFT(@comments, 20));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Medium_Embedded'), N'$comments2$', LEFT(@comments, 2000));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'Large_Embedded'), N'$comments2$', LEFT(@comments, 20000));
EXEC sys.sp_executesql @sql;
SET @sql = REPLACE(REPLACE(@basesql, N'$name$', N'ExtraLarge_Embedded'), N'$comments2$', LEFT(@comments, 200000));
EXEC sys.sp_executesql @sql;
Teraz musiałem wygenerować kod, aby uruchomić każdą procedurę 100 000 razy, zmierzyć czas trwania z sys.dm_exec_procedure_stats , a także sprawdź rozmiar planu w pamięci podręcznej.
DECLARE @hammer nvarchar(max) = N''; SELECT @hammer += N' DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; GO EXEC dbo.' + [name] + N'; GO 100000 SELECT [size of ' + [name] + ' (b)] = DATALENGTH(definition) FROM sys.sql_modules WHERE [object_id] = ' + CONVERT(varchar(32),([object_id])) + N'; SELECT [size of ' + [name] + ' (b)] = size_in_bytes FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t WHERE t.objectid = ' + CONVERT(varchar(32),([object_id])) + N'; SELECT N''' + [name] + N''', avg_dur = total_elapsed_time*1.0/execution_count FROM sys.dm_exec_procedure_stats WHERE [object_id] = ' + CONVERT(varchar(32),([object_id])) + N';' FROM sys.procedures WHERE [name] LIKE N'%[_]Separate' OR [name] LIKE N'%[_]Embedded'; PRINT @hammer;
Najpierw spójrzmy na wielkość organów zabiegowych. Nie ma tu niespodzianek, tylko potwierdzenie, że mój kod konstrukcyjny powyżej wygenerował oczekiwany rozmiar komentarzy w każdej procedurze:
| Procedura | Rozmiar (w bajtach) |
|---|---|
| Small_Separate / Small_Embedded | 378 |
| Średni_oddzielny/Średnio osadzony | 4340 |
| Large_Separate / Large_Separate | 40 338 |
| ExtraLarge_Separate / ExtraLarge_Separate | 400 348 |
Następnie, jak duże były plany w pamięci podręcznej?
| Procedura | Rozmiar (w bajtach) |
|---|---|
| Small_Separate / Small_Embedded | 40 360 |
| Średni_oddzielny/Średnio osadzony | 40 360 |
| Large_Separate / Large_Separate | 40 360 |
| ExtraLarge_Separate / ExtraLarge_Separate | 40 360 |
Na koniec, jak wyglądał występ? Bez OPTION (RECOMPILE) , oto średni czas wykonania w milisekundach – dość spójny we wszystkich procedurach:
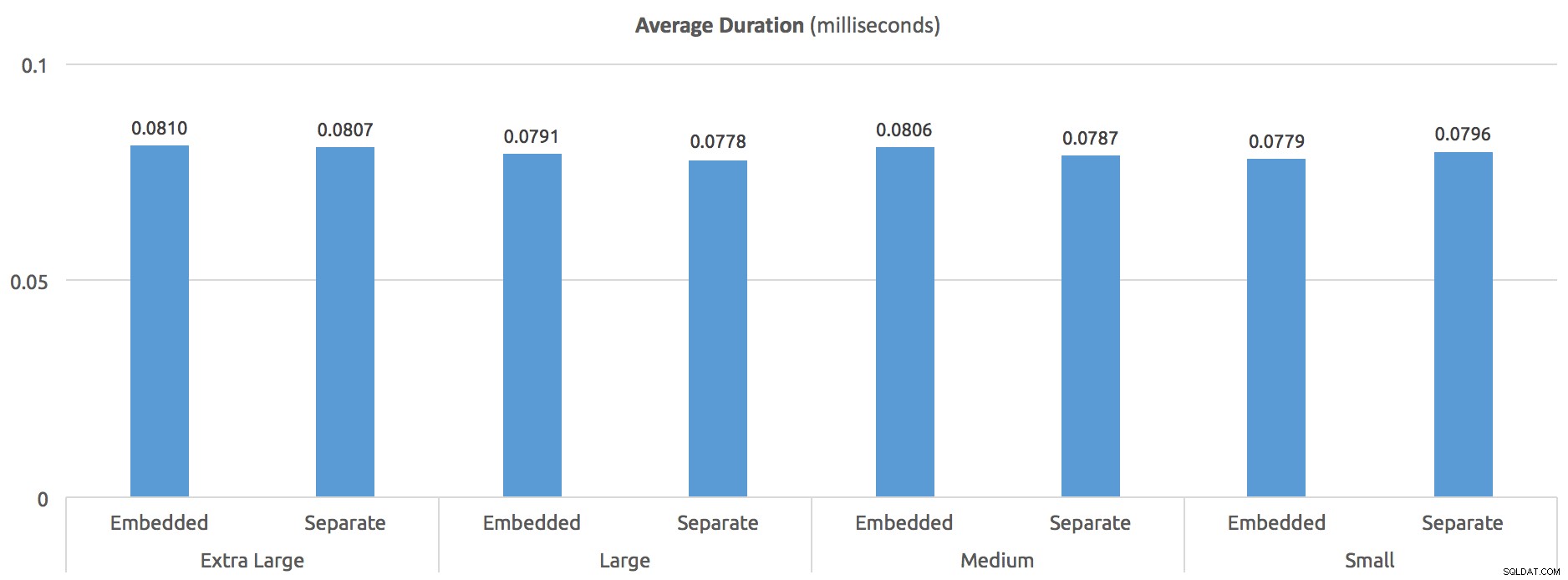
Średni czas trwania (milisekundy) – bez OPCJI (PRZEKOMPILIUJ)
Z poziomu instrukcji OPTION (RECOMPILE) , możemy zauważyć około 50% trafienia w średnim czasie trwania na całej tablicy w porównaniu z brakiem ponownej kompilacji, ale nadal dość wyrównane:
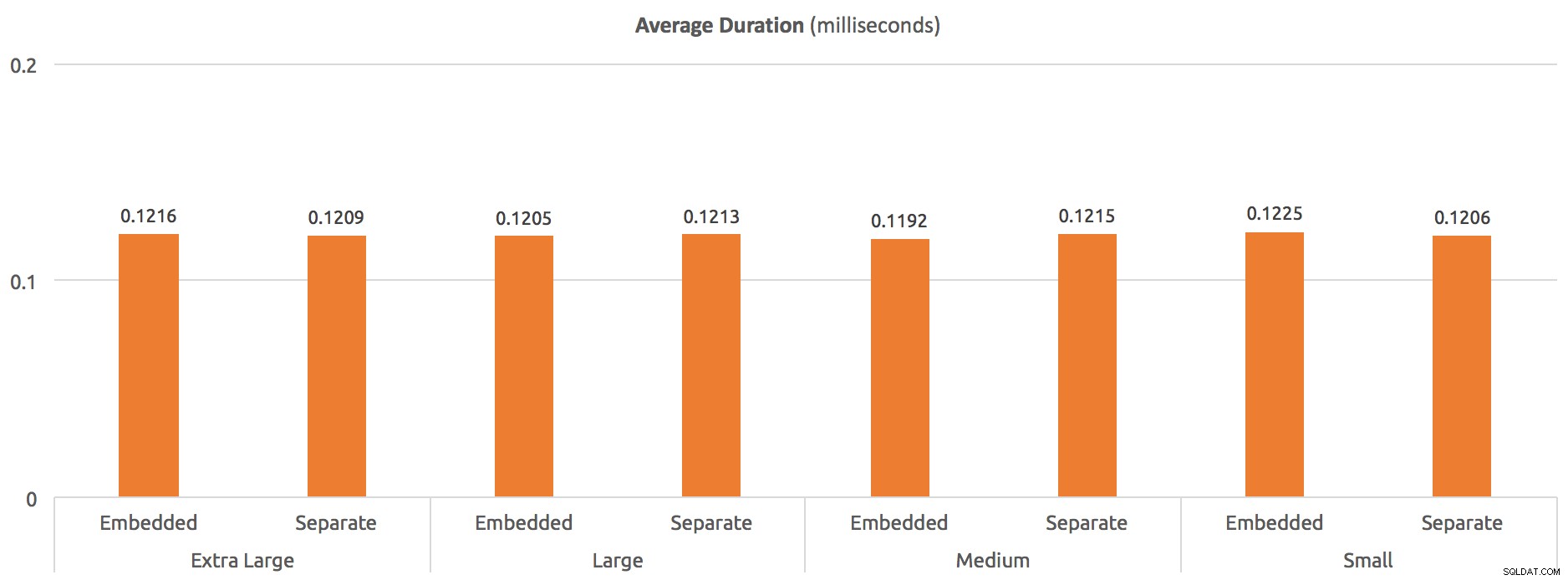
Średni czas trwania (milisekundy) – z OPCJĄ (RECOMPILE)
W obu przypadkach, gdy OPTION (RECOMPILE) wersja generalnie działała wolniej, praktycznie było ZERO różnica w czasie wykonywania, niezależnie od rozmiaru komentarza w treści procedury.
A co z wyższymi kosztami kompilacji?
Następnie chciałem sprawdzić, czy te duże komentarze będą miały ogromny wpływ na koszty kompilacji, na przykład czy procedury zostały utworzone WITH RECOMPILE . Powyższy kod konstrukcyjny można było łatwo zmienić, aby to uwzględnić. Ale w tym przypadku nie mogłem polegać na sys.dm_exec_procedure_stats , ponieważ nie działa to w przypadku procedur WITH RECOMPILE . Więc mój kod generacji do testu był trochę inny, ponieważ musiałbym ręcznie śledzić średni czas trwania:
DECLARE @hammer nvarchar(max) = N''; SELECT @hammer += N' DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; SELECT SYSDATETIME(); GO EXEC dbo.' + [name] + N'; GO 100000 SELECT SYSDATETIME();'; PRINT @hammer;
W tym przypadku nie mogłem sprawdzić rozmiaru planów w pamięci podręcznej, ale byłem w stanie określić średni czas wykonywania procedur i była różnica na podstawie rozmiaru komentarza (lub może po prostu rozmiar ciała procedury):
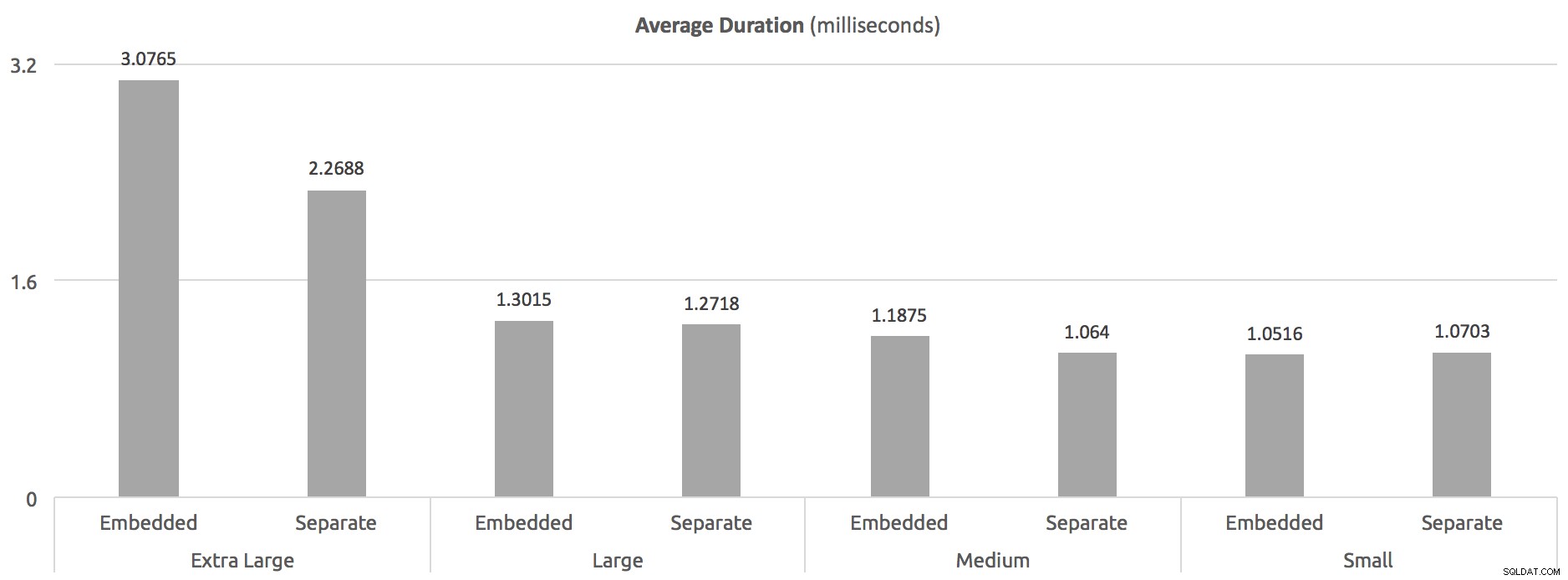
Średni czas trwania (milisekundy) – Z RECOMPILE na poziomie procedury
Jeśli umieścimy je wszystkie razem na wykresie, będzie jasne, o ile droższe jest WITH RECOMPILE użycie może być:
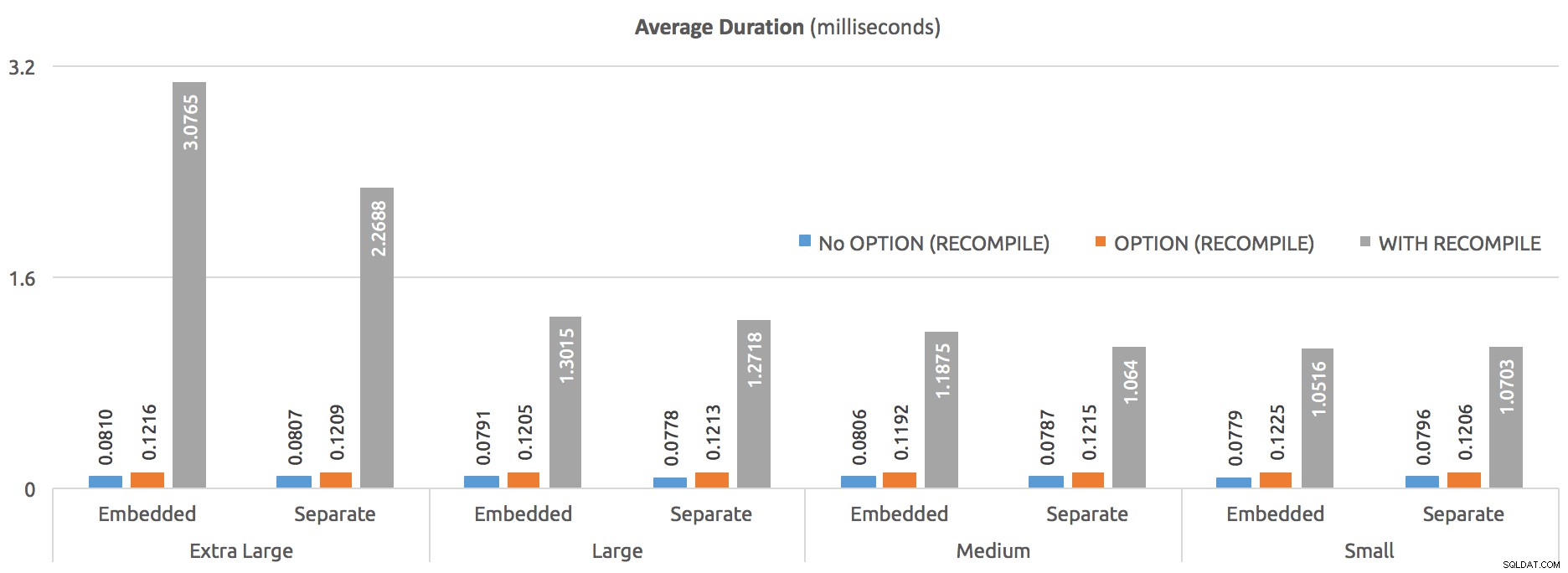
Średni czas trwania (milisekundy) – porównanie wszystkich trzech metod
Prawdopodobnie przyjrzę się temu bliżej później, aby zobaczyć dokładnie, gdzie ten kij hokejowy wchodzi w grę – wyobrażam sobie testowanie w krokach co 10 000 znaków. Na razie jednak jestem całkiem zadowolony, że odpowiedziałem na to pytanie.
Podsumowanie
Komentarze wydają się być całkowicie niezwiązane z rzeczywistą, obserwowalną wydajnością procedury składowanej, z wyjątkiem przypadku, gdy procedura jest zdefiniowana WITH RECOMPILE . Osobiście nie widzę już używania tego na wolności, ale YMMV. Dla subtelnych różnic między tą opcją a OPTION (RECOMPILE) na poziomie instrukcji , zobacz artykuł Paula White'a „Parameter Sniffing, Embedding and the RECOMPILE Options”.
Osobiście uważam, że komentarze mogą być niezwykle cenne dla każdego, kto musi przeglądać, konserwować lub rozwiązywać problemy z Twoim kodem. Obejmuje to Ciebie w przyszłości. Zdecydowanie odradzam martwienie się o wpływ rozsądnej liczby komentarzy na wydajność, a zamiast tego skoncentruj się na priorytetyzacji użyteczności kontekstu, który dostarczają komentarze. Jak powiedział ktoś na Twitterze, istnieje limit. Jeśli twoje komentarze są skróconą wersją Wojny i pokoju, możesz rozważyć – ryzykując oddzielenie kodu od dokumentacji – umieścić tę dokumentację w innym miejscu i odwołać się do linku w komentarzach do procedury.
Aby zminimalizować ryzyko rozłączenia lub braku synchronizacji dokumentacji i kodu z upływem czasu, możesz utworzyć drugą procedurę z sufiksem _documentation lub _comments i umieszczając tam komentarze (lub skomentowaną wersję kodu). Może umieścić go w innym schemacie, aby nie mieścił się w głównych listach sortowania. Przynajmniej dokumentacja pozostaje w bazie danych, gdziekolwiek się pojawi, chociaż nie gwarantuje, że zostanie utrzymana. Szkoda, że nie można utworzyć normalnej procedury WITH SCHEMABINDING , w takim przypadku możesz wyraźnie powiązać procedurę komentarzy ze źródłem.