W części 1 tej serii pomyślnie zaimportowaliśmy strukturę bazy danych SuiteCRM do naszego internetowego narzędzia do modelowania baz danych. Wtedy zobaczyliśmy, że model zawiera 201 tabel bez relacji między nimi. Mamy dzikie stoły, które wyglądały na naprawdę niechlujne. W tym artykule pokażę, jak zorganizować tak duży model.
Zaraz po zaimportowaniu do Vertabelo model bazy danych SuiteCRM wygląda następująco:
Model działa – ale nie wydajnie. Będziemy musieli go zmodyfikować, aby był naprawdę użyteczny. Ponieważ chcemy analizować bazę danych SuiteCRM po akcje są wykonywane na jego GUI, musimy zrozumieć definicje tabel i relacje między tabelami. Zacznijmy od pogrupowania tabel w obszary tematyczne i ustalenia najważniejszych relacji.
Vertabelo oferuje trzy główne narzędzia ułatwiające organizowanie dużych diagramów:
- Obszary tematyczne
- Tabele i skróty widoków
- Skróty referencyjne
Opiszę je w dalszej części tego artykułu, ale możesz również dowiedzieć się więcej, oglądając ten film.
Krok 1. Wyłącz automatyczne generowanie kluczy obcych
Przede wszystkim wyłączymy automatyczne generowanie kluczy obcych. Domyślnie Vertabelo generuje atrybuty klucza obcego, gdy ściągamy relacje z tabeli podstawowej do tabeli, do której się odwołujemy. To zwykle dobrze, ale nie tutaj. Mamy już atrybuty reprezentujące klucze obce. Brakuje nam „prawdziwych” relacji między stołami. Aby wyłączyć tę opcję, kliknij „Moje konto” w górnym menu i znajdź „Preferencje osobiste” sekcja.
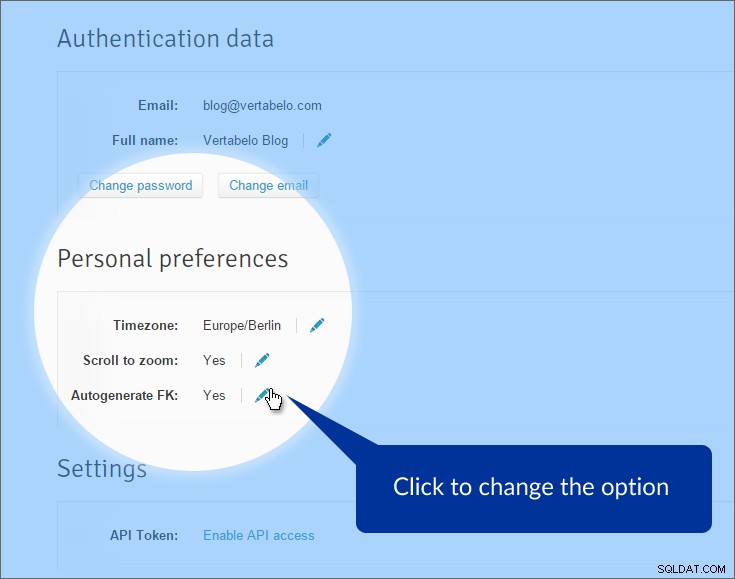
Opcja jest wyłączona. Teraz, kiedy rysujemy linię odniesienia między tabelami, linia jest tworzona – ale będziemy musieli określić, które atrybuty są używane, zarówno po stronie pierwotnej, jak i obcej.
Krok 2. Grupuj tabele z prefiksami z obszarami tematycznymi
Następnie zgrupujmy kilka tabel. Zrobimy to za pomocą Obszaru tematycznego narzędzie pozwalające kojarzyć tabele na podstawie wybranych kryteriów. W naszym przypadku próbujemy zidentyfikować tabele, które są powiązane lub stanowią część tego samego procesu. Spowoduje to powstanie grup takich jak „Połączenia”, „Spotkania” i „Kampanie”.
Możemy utworzyć obszar tematyczny, klikając „Dodaj nowy obszar” ikona w przyborniku:
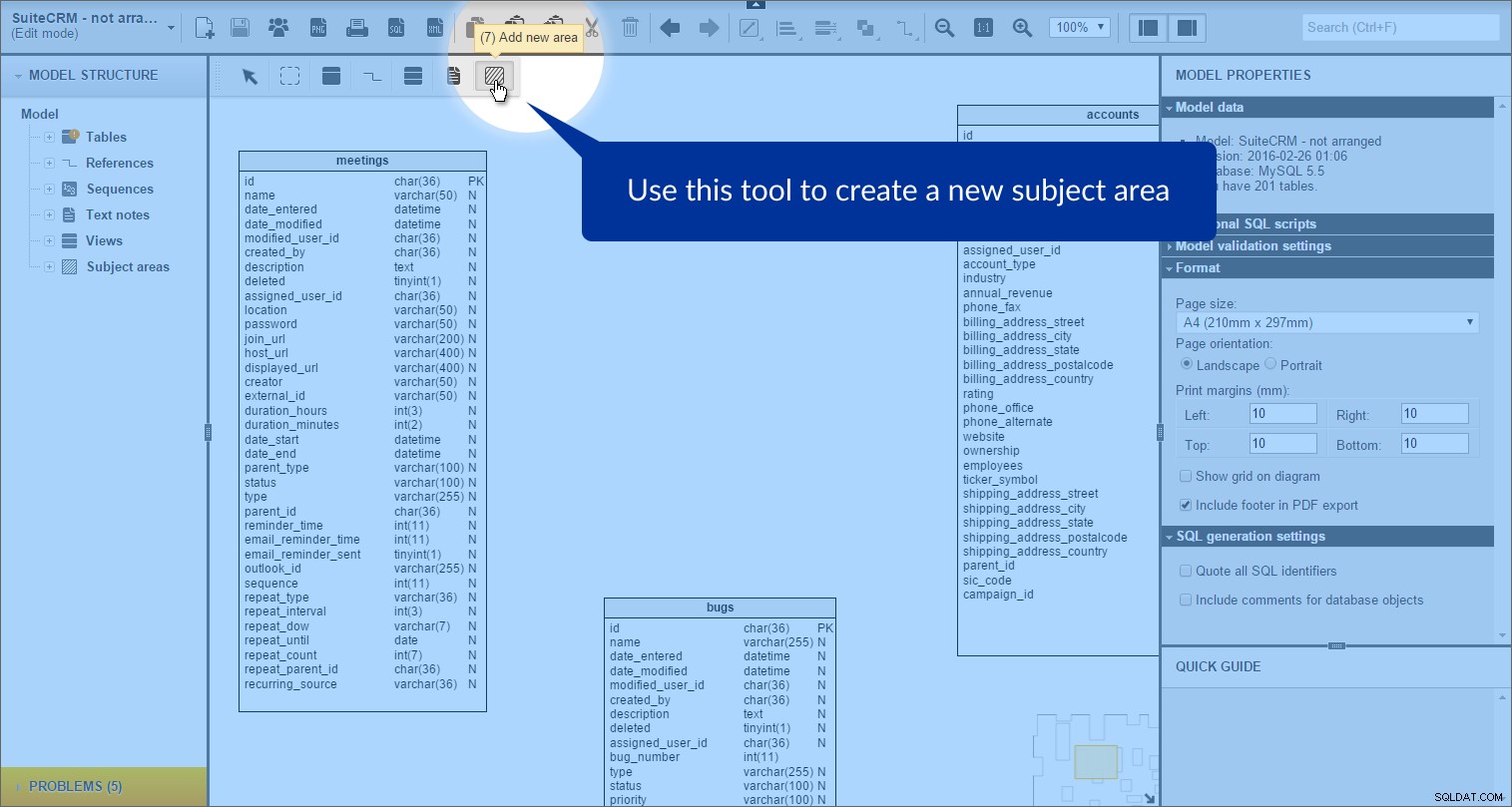
a następnie narysuj prostokąt na naszym modelu:
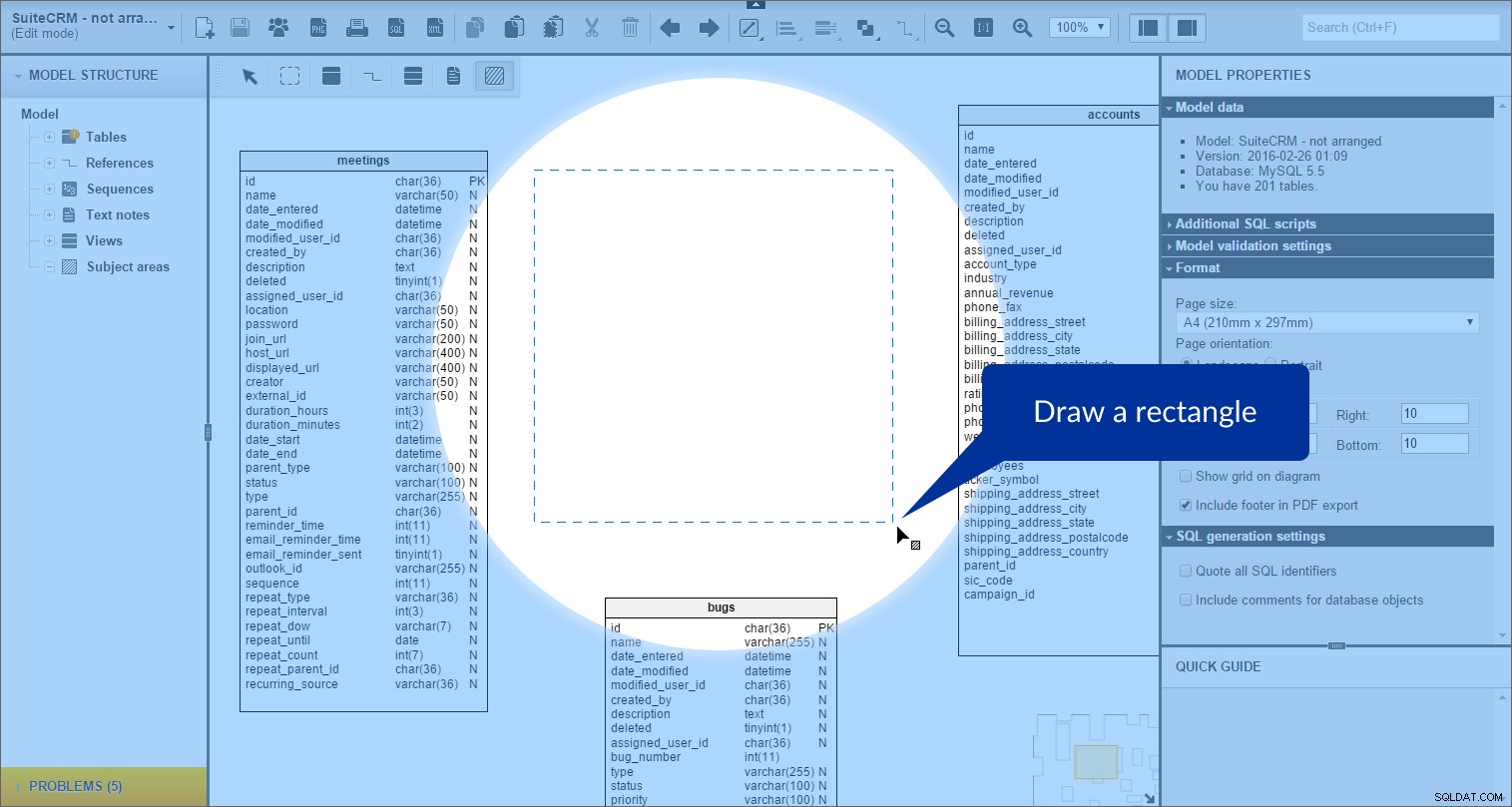
Utworzono obszar tematyczny. Możemy to zobaczyć w „Strukturze modelu” panel po lewej:
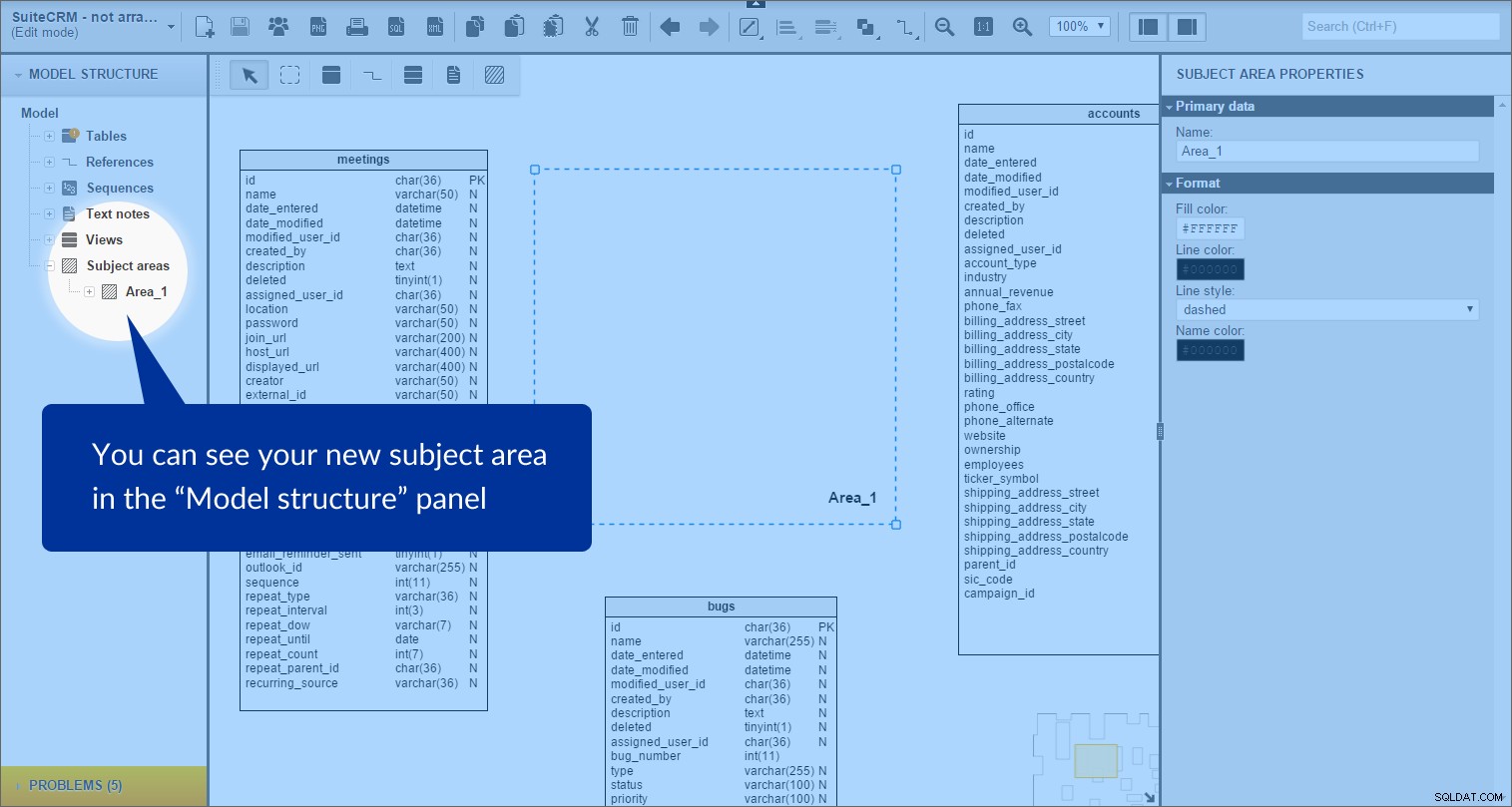
Każdy obszar tematyczny zawiera listę wszystkich obiektów znajdujących się w jego granicach; w tym przypadku są to tabele i typy referencyjne.
W SuiteCRM istnieje wiele tabel, które mają wspólny przedrostek. Zacząłem więc grupować tabele z prefiksami. Spójrz na tabele „acl” jako przykład. W panelu „Struktura modelu” znalazłem wszystkie tabele, których nazwy zaczynały się od „acl_”:
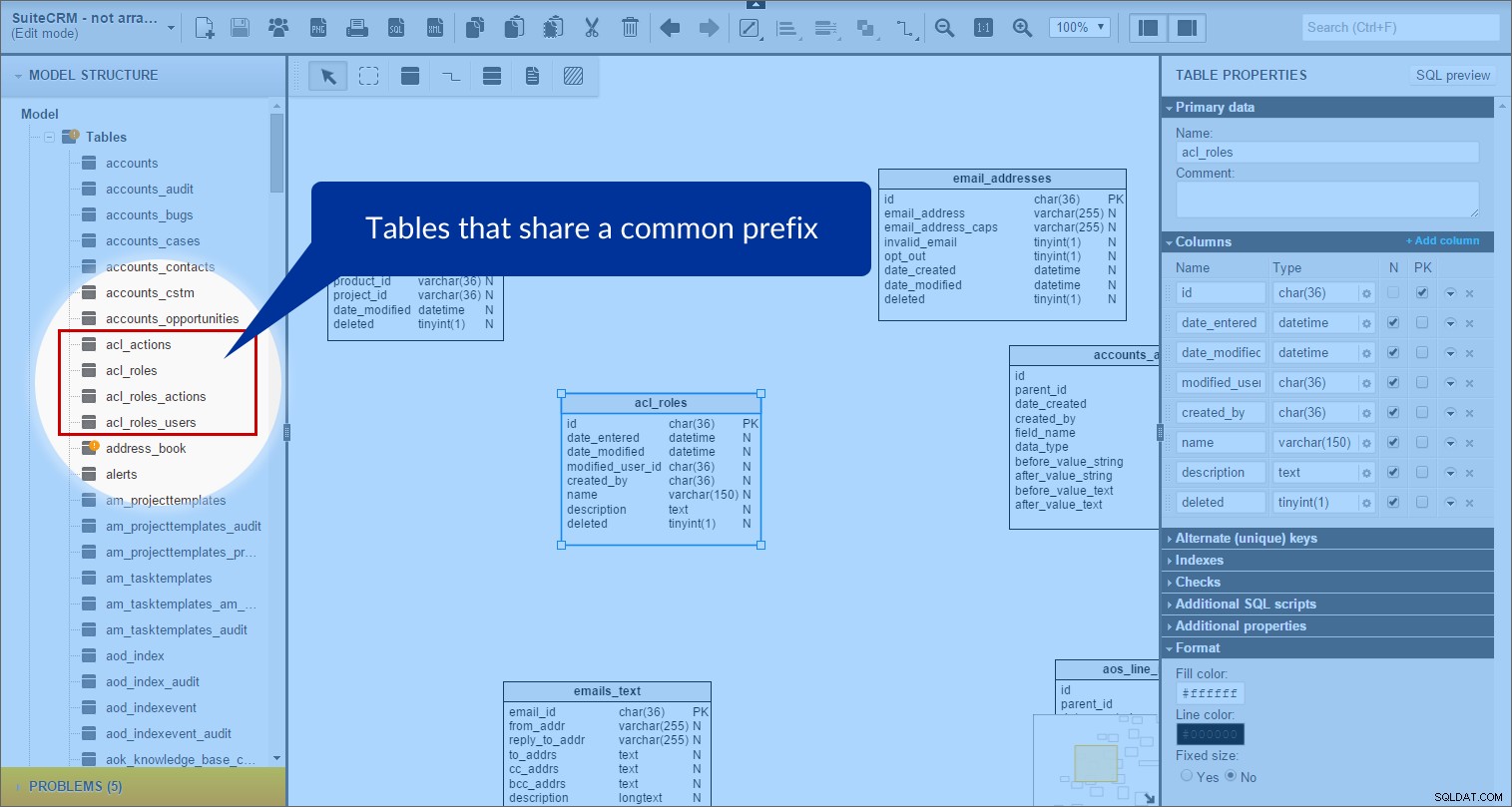
Następnie utworzyłem w modelu obszar tematyczny „acl” i przeciągnąłem do niego wszystkie odpowiednie tabele. (Dla lepszej widoczności ustawiłem kolor tła na fioletowy).
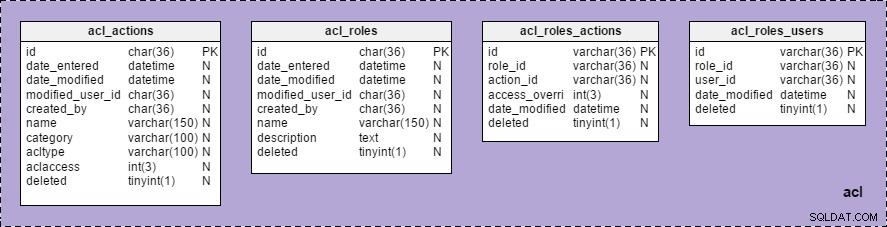
Teraz możemy zobaczyć grupę „acl” z listą wszystkich należących do niej tabel w sekcji „Obszary tematyczne” w „Strukturze modelu” :
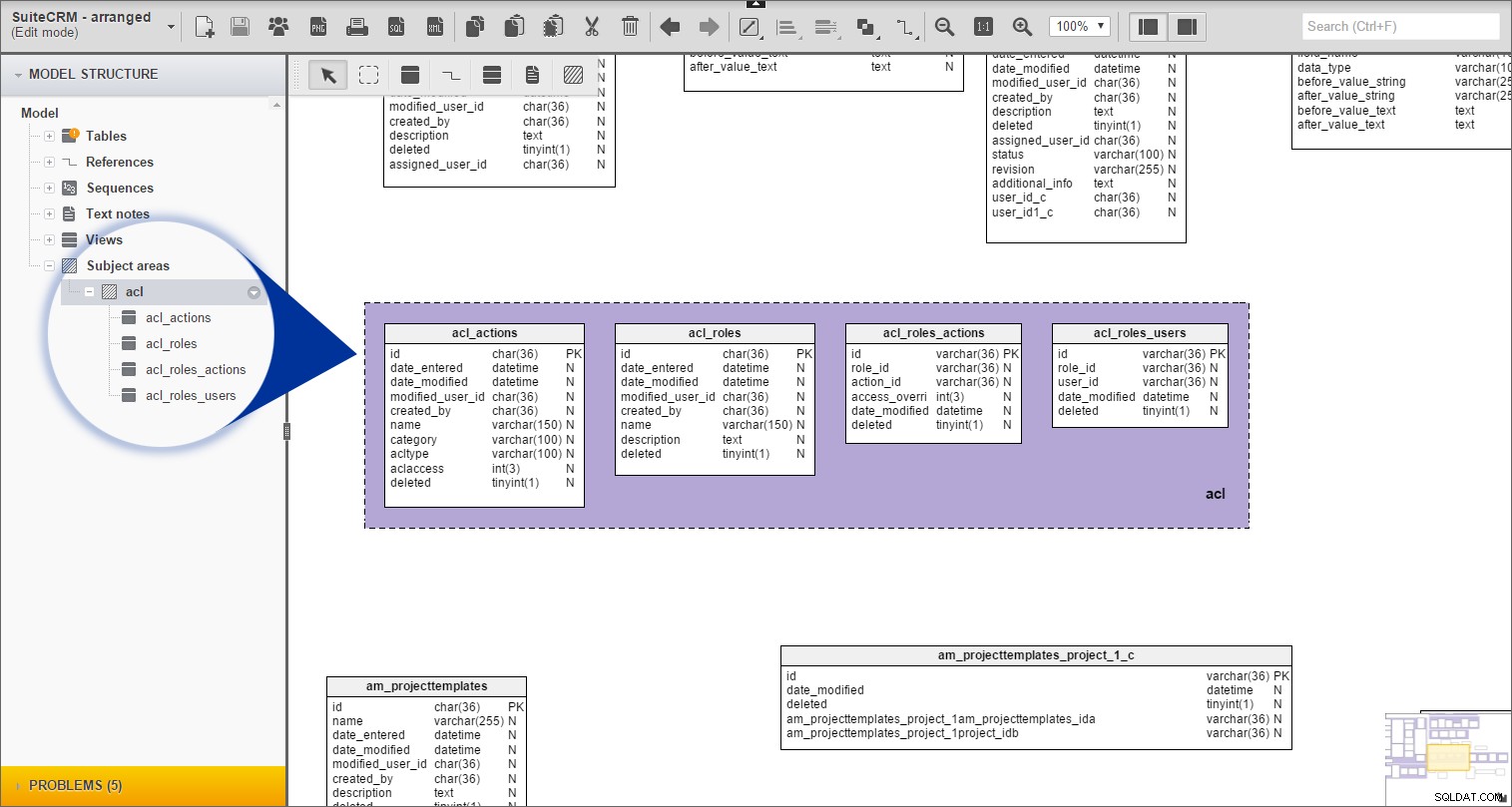
Powtórzyłem tę samą procedurę dla wszystkich pozostałych tabel z prefiksami.
Krok 3:Ułóż pozostałe tabele.
Ta sama tabela dwa razy na diagramie? Skróty do stołu!
Istnieje około 80 tabel z prefiksami. Po ich pogrupowaniu zostało mi około 120 „dzikich” stolików. Są one znaczące:przechowują informacje o użytkownikach, klientach, rozmowach telefonicznych, spotkaniach i innych rzeczach CRM. To dużo informacji, które należy pozostawić na wolności, więc posortujmy te tabele.
Funkcja, którą uznałem za najbardziej przydatną do rozmieszczania tych tabel, nazywa się skróty do tabel . Czasami chcesz użyć tej samej tabeli więcej niż raz w modelu. (Dlaczego? Aby spłaszczyć model i uniknąć nakładania się). Możemy to łatwo zrobić, używając „Kopiuj” i „Wklej jako skrót” przyciski.
Po prostu wybierz tabelę, dla której chcesz utworzyć skrót, i kliknij „Kopiuj” na górnym pasku narzędzi (lub naciśnij Ctrl + C ):
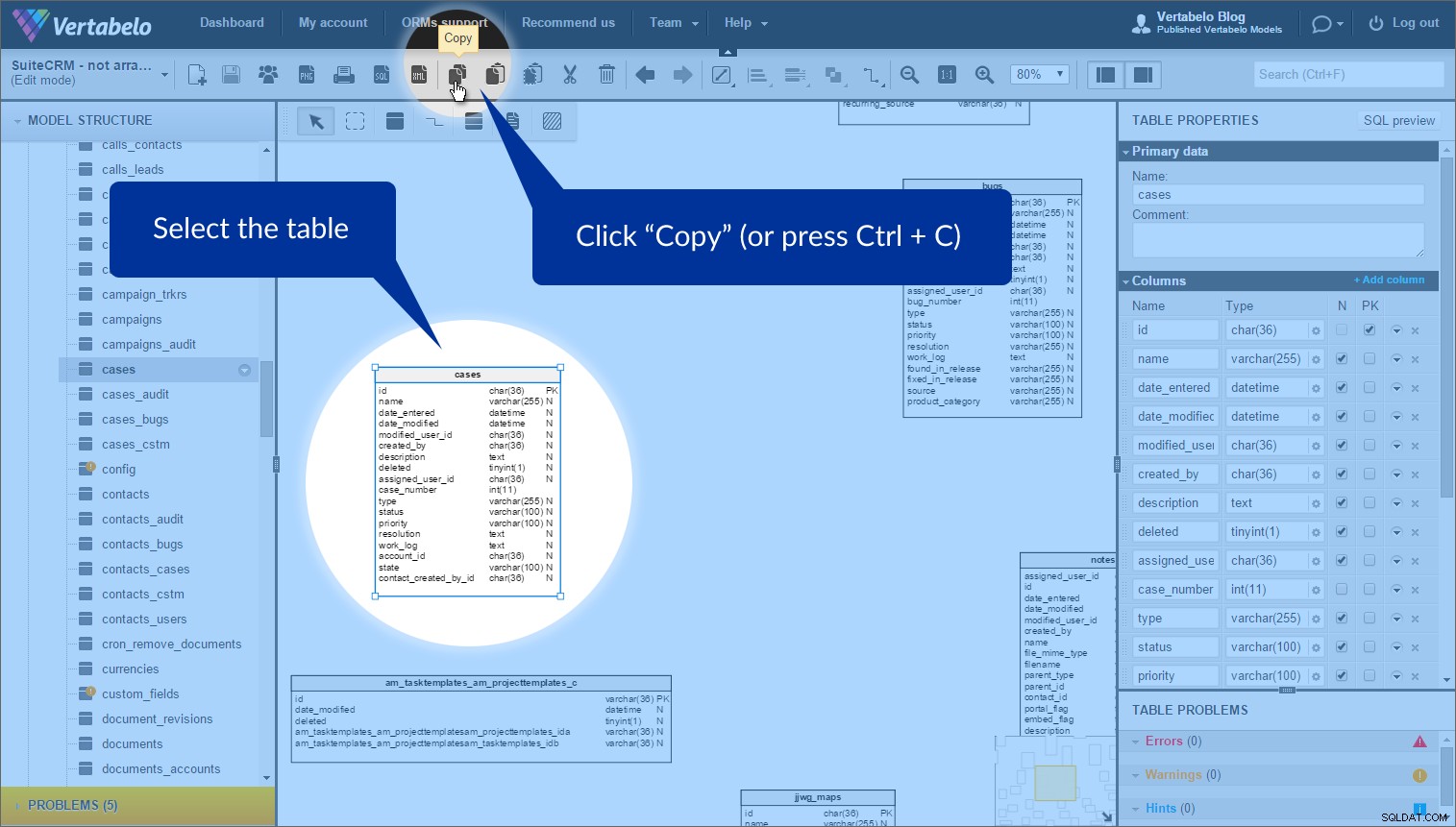
Aby utworzyć skrót, kliknij „Wklej jako skrót” (lub naciśnij Ctrl + K ). Następnie pojawi się nowa tabela z kropkowanym konturem:
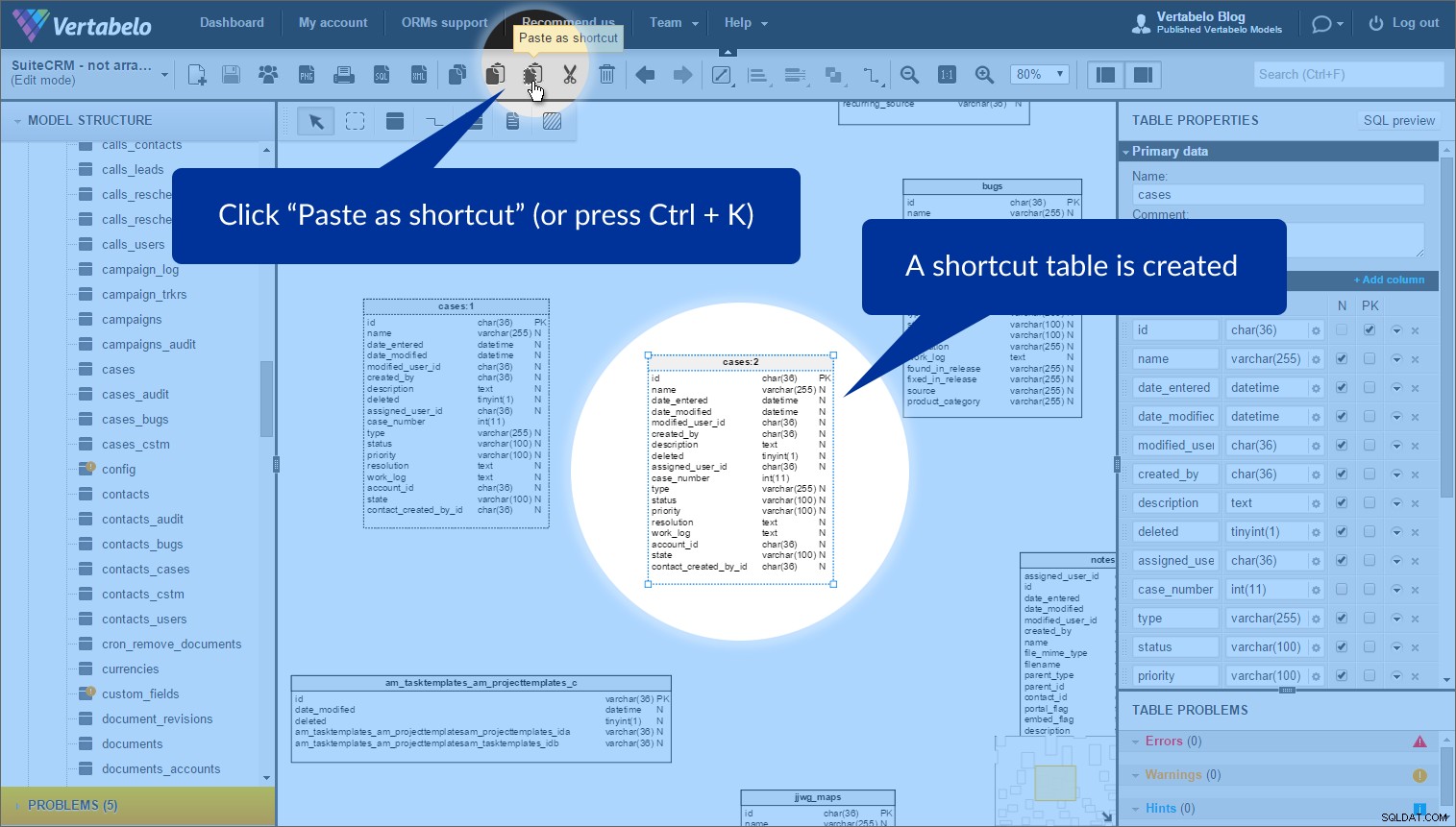
To nie kopię tabeli, ale inne wystąpienie oryginalnej tabeli. Możemy umieścić go w dowolnym miejscu naszego modelu. Użyłem wystąpień tej samej tabeli w różnych obszarach tematycznych, aby uniknąć nakładania się odniesień. Warto wspomnieć, że każda instancja tabeli ma przypisaną nazwę obszaru tematycznego (obok nazwy), gdy znajduje się w tym obszarze tematycznym.
Dobrym przykładem tego, jak to działa, są users stół. Można go znaleźć w „Użytkownikach i kontach”, „Rolach”, „Dokumentach” i innych obszarach tematycznych. Zobaczymy to później w modelu.
Podczas tworzenia obszarów tematycznych z ustalonymi relacjami między tabelami intensywnie korzystam ze skrótów tabel. Aby zobaczyć, jak to działa, spójrz na obszar tematyczny „Możliwości” przedstawiony poniżej. Zauważ, że wszystkie tabele w tym obszarze tematycznym są nazwane zgodnie z tą zasadą:{nazwa tabeli} :{nazwa obszaru tematycznego} .
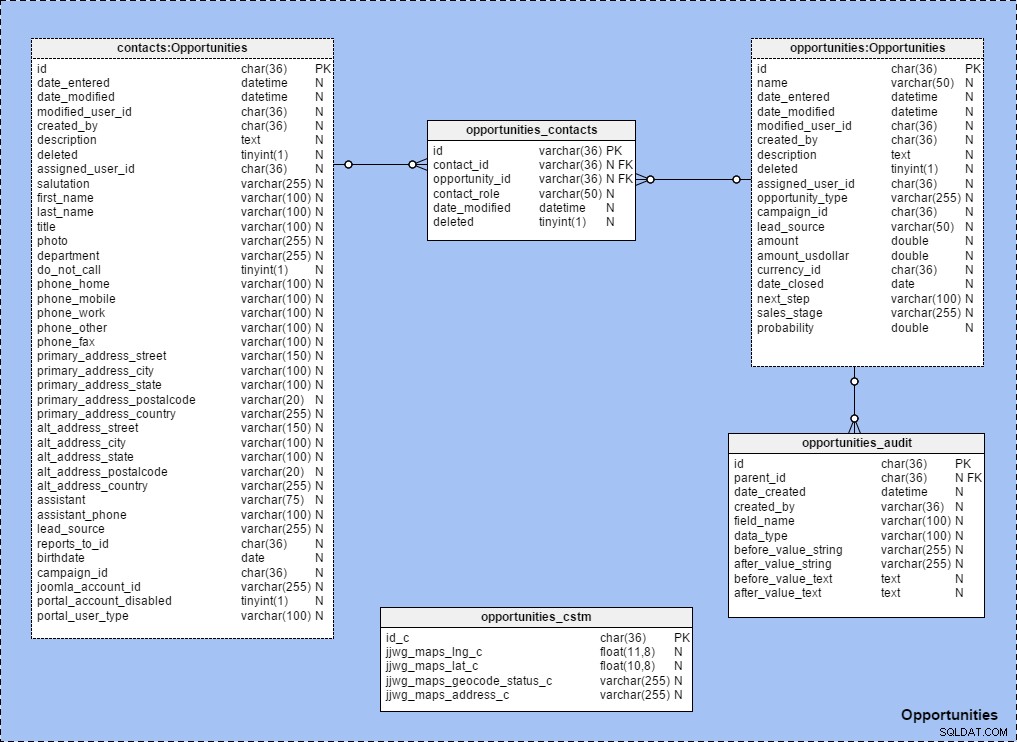
Gdy rozwiniemy {nazwa obszaru tematycznego} w panelu „Struktura modelu” wyraźnie widać, że zawiera on tabele i referencje:
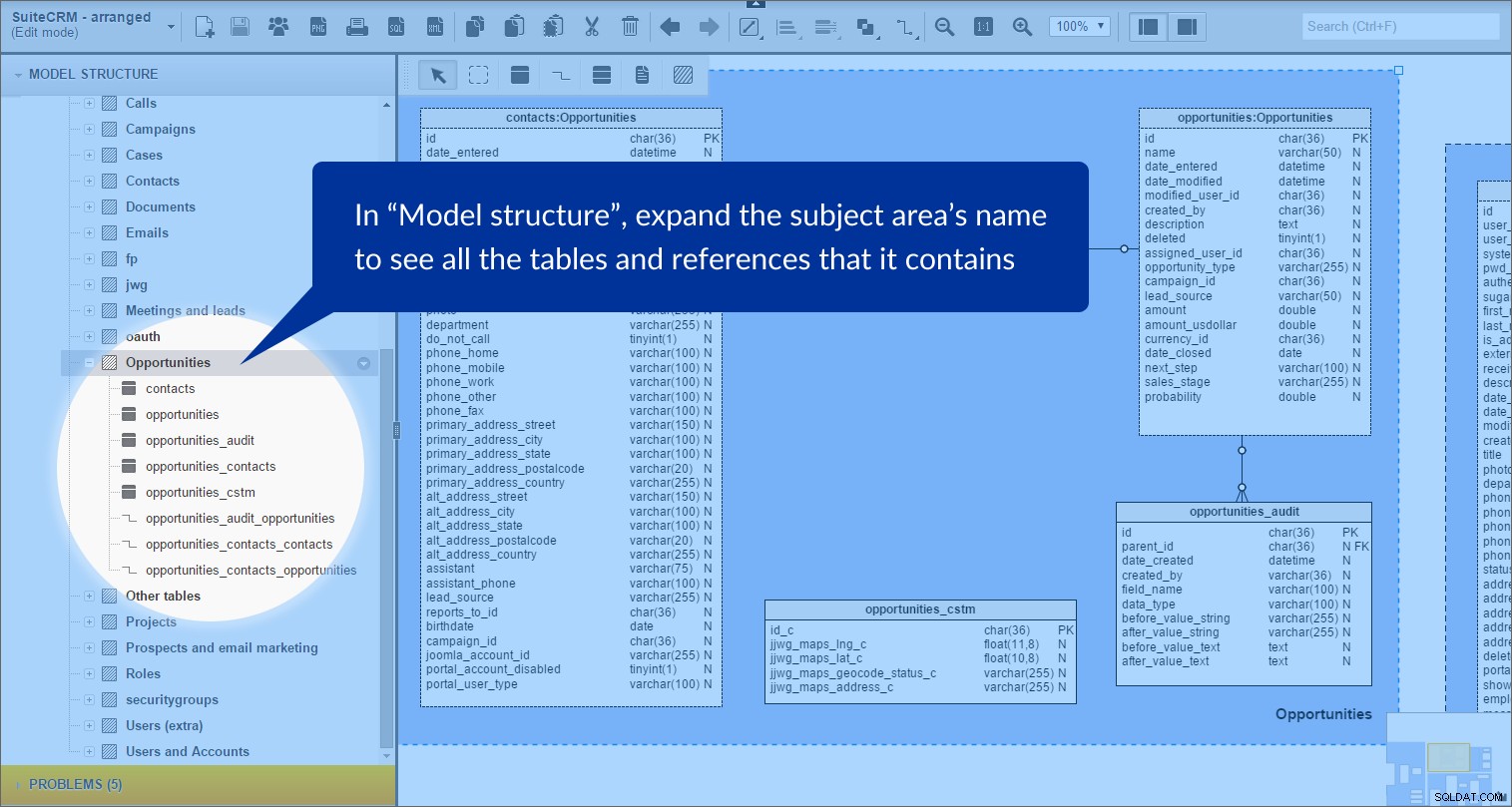
Zrobiłem to dla następujących obszarów tematycznych:„Połączenia”, „Sprawy”, „Kampania”, „Kontakty”, „Dokumenty”, „Spotkania i leady”, „Oauth”, „Projekty”, „Prospekty i e-mail marketing”, „Role” oraz „Użytkownicy i konta”. Wszystkie te obszary mają jasnoniebieskie tło.
Pozostałe tabele są pogrupowane według ich nazwy i domniemanego znaczenia:„E-maile”, „Użytkownicy (dodatkowi)” i „Inne tabele”. Te grupy mają kolor tła ustawiony na jasnoczerwony.
Po dwukrotnym kliknięciu nazwy tabeli w drzewie nawigacyjnym widok powiększy się do tej tabeli w modelu i wybierze ją. Gdy powiększasz, obracając kółko myszy, widok powiększa się w kierunku wskaźnika myszy.Model ułożony
Wykorzystałem wcześniej opisane opcje, aby maksymalnie spłaszczyć model podczas logicznego grupowania tabel. Rezultatem jest 26 obszarów tematycznych, z których niektóre zawierają tylko tabele, podczas gdy inne mają tabele i relacje. Zróbmy krótki przegląd każdej kategorii:
Obszary tematyczne zawierające tabele i relacje:
„Rozmowy”, „Kampanie”, „Sprawy”, „Kontakty”, „Dokumenty”, „Spotkania i potencjalni klienci”, „Szanse”, „Projekty”, „Prospekty i e-mail marketing”, „Role”, „Użytkownicy i konta”
Wszystkie relacje są ustawione jako nieobowiązkowe. Dzięki temu zachowana jest informacja, że te tabele są powiązane i przez jakie atrybuty.
Obszary tematyczne zawierające tylko tabele:
„acl”, „am”, „aod”, „aok”, „aop”, „aor”, „aos”, „aow”, „E-maile”, „fp”, „jwg”, „oauth”, „security_groups ”, „Dodatkowi użytkownicy”
Nie oznacza to, że nie istnieją tu relacje; po prostu nie są podkreślane.
Obszar tematyczny „Inne tabele” dotyczy tabel, które tak naprawdę nie pasują do określonej grupy.
Jak wygląda model?
Zmieniony model wygląda tak:
Oczywiście zastosowano konwencję nazewnictwa. Oto przegląd wytycznych, których przestrzegaliśmy:
- Nazwy tabel są przeważnie w liczbie mnogiej:
users,contracts,folders,roles,tasks. Niektóre nazwy tabel są pojedyncze, na przykładproject. - Klucz podstawowy w większości tabel nazywa się po prostu
idi jest typem char(36). - Gdy występuje relacja jeden-do-wielu, klucz obcy jest zwykle nazywany
parent_id. (Przykład:contacts_audit.parent_idjest odniesieniem docontacts.id.) - W relacjach wiele-do-wielu „
parent_id” nie może być używane jako nazwa dla wielu kolumn. Zamiast tego używana jest pojedyncza nazwa tabeli z przyrostkiem „_id”. (Przykład:contacts_bugs.bug_idjest odniesieniem dobug.id.) - Są sytuacje, w których ta sama kolumna jest używana jako klucz obcy dla wielu tabel. (Przykład:
calls.parent_idodwołuje się do kolumny id w każdej z poniższych tabel:accounts,bugs,cases,contacts,leads,tasks,opportunities and prospects. Nie sprawdziłem wartości w bazie danych, ale przypuszczam, że w tych tabelach nie ma takich samych wartości kluczy. Ponieważ wszystkie są typu char(36), prawdopodobnie używana jest jakaś kombinacja nazwy tabeli i autoinkrementacji. Sprawdzimy to w kolejnych artykułach). - Używamy tych samych nazw dla kolumn, które mają to samo znaczenie w różnych tabelach. (Przykład:
modified_user_id,created_byiassigned_user_idmożna znaleźć w wielu tabelach w modelu. Wszystkie z nich odnoszą się dousers.id.)
Co dalej?
W nadchodzących artykułach będziemy korzystać z GUI SuiteCRM i obserwować zmiany, jakie to powoduje w bazie danych. Dzięki tym informacjom postaramy się wprowadzić zmiany w modelu, zreorganizować obszary tematyczne i tam, gdzie będzie to potrzebne, nawiązać kontakty. Poszukamy również innych reguł specyficznych dla SuiteCRM, takich jak sposób generowania kluczy podstawowych.
Obsługa dużych diagramów baz danych nigdy nie jest łatwym zadaniem. Podobnie jak budowanie dobrego fundamentu domu, spędzanie większej ilości czasu na podstawach teraz przyniesie korzyści później. Jeśli chcemy analizować modele, takie jak ten stojący za SuiteCRM, analiza przed zorganizowaniem struktury modelu i zdefiniowaniem relacji między tabelami odbywa się w stylu Syzyfa.