Kiedy SQL Server 2012 był jeszcze w wersji beta, pisałem na blogu o nowej funkcji FORMAT() funkcja:SQL Server v.Next (Denali) :CTP3 Rozszerzenia T-SQL :FORMAT().
W tamtym czasie byłem tak podekscytowany nową funkcjonalnością, że nawet nie pomyślałem o testowaniu wydajności. Odniosłem się do tego w nowszym poście na blogu, ale wyłącznie w kontekście usuwania czasu z daty i czasu:Przycinanie czasu z daty i czasu – kontynuacja.
W zeszłym tygodniu mój dobry przyjaciel Jason Horner (blog | @jasonhorner) trollował mnie tymi tweetami:
| |
Mój problem polega na tym, że FORMAT() wygląda na wygodne, ale jest wyjątkowo nieefektywne w porównaniu z innymi podejściami (och i to AS VARCHAR jest też źle). Jeśli robisz to onesy-twosy i dla małych wyników, nie martwiłbym się tym zbytnio; ale na dużą skalę może być dość drogie. Pozwolę sobie zilustrować przykładem. Najpierw utwórzmy małą tabelkę z 1000 pseudolosowymi datami:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Teraz wypełnijmy pamięć podręczną danymi z tej tabeli i zilustrujmy trzy popularne sposoby, w jakie ludzie prezentują tylko czas:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Teraz wykonajmy indywidualne zapytania, które wykorzystują te różne techniki. Uruchomimy je co 5 razy i uruchomimy następujące odmiany:
- Wybieranie wszystkich 1000 wierszy
- Wybieranie TOP (1) uporządkowane według klucza indeksu klastrowego
- Przypisywanie do zmiennej (co wymusza pełne skanowanie, ale zapobiega zakłócaniu wydajności przez renderowanie SSMS)
Oto skrypt:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Teraz możemy zmierzyć wydajność za pomocą następującego zapytania (mój system jest dość cichy; na twoim może być konieczne wykonanie bardziej zaawansowanego filtrowania niż tylko execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Wyniki w moim przypadku były dość spójne:
| Zapytanie (obcięte) | Czas trwania (mikrosekundy) | |||
|---|---|---|---|---|
| total_elapsed | średnio_upłynął | total_clr | ||
| WYBIERZ 1000 wierszy | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time wyjście (kliknij, aby powiększyć):
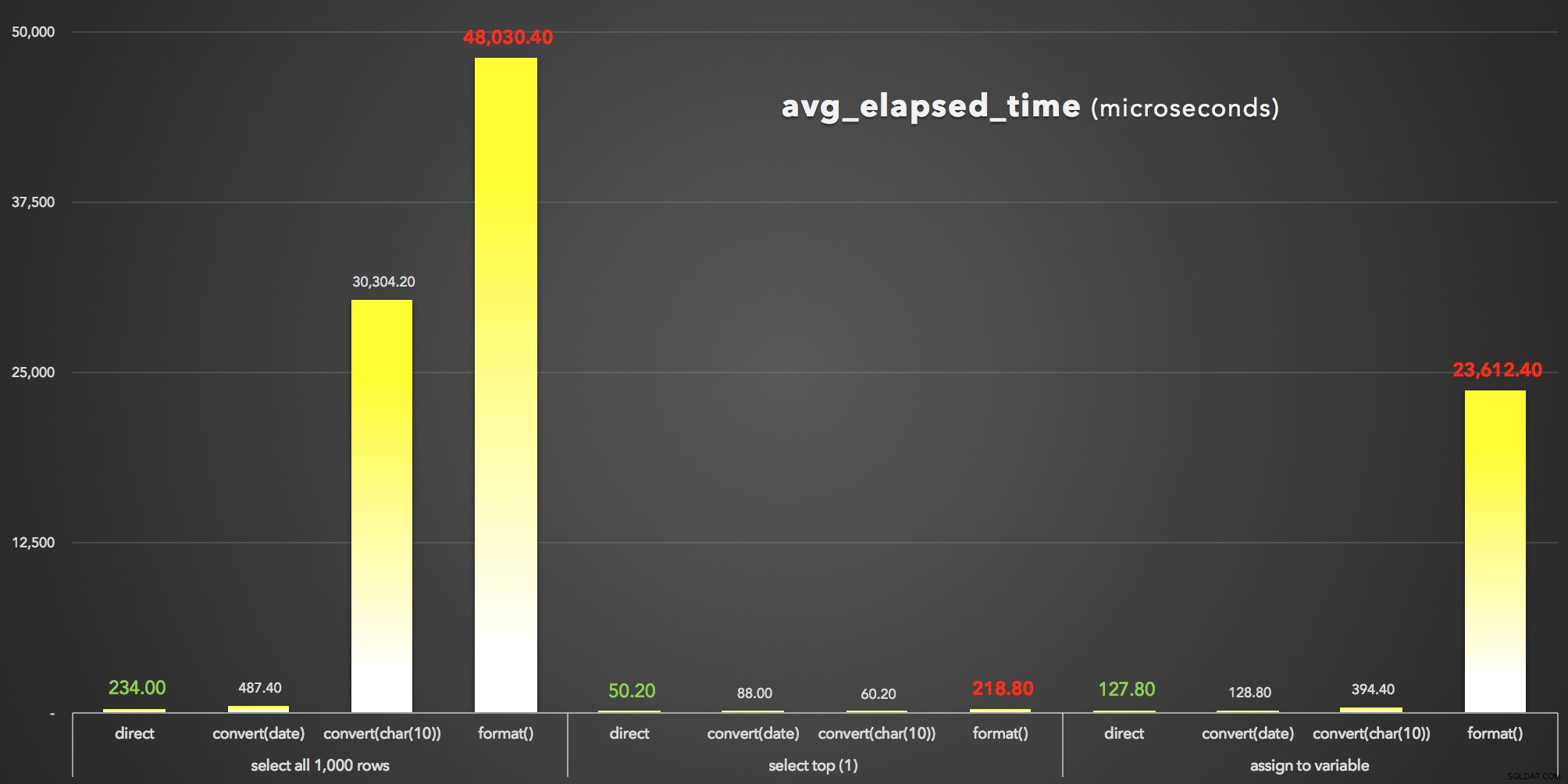 FORMAT() wyraźnie przegrywa:wyniki avg_elapsed_time (mikrosekundy)
FORMAT() wyraźnie przegrywa:wyniki avg_elapsed_time (mikrosekundy)
Czego możemy się nauczyć z tych wyników (ponownie):
- Przede wszystkim
FORMAT()jest drogie . FORMAT()co prawda zapewnia większą elastyczność i bardziej intuicyjne metody, które są spójne z tymi w innych językach, takich jak C#. Jednak oprócz narzutu i podczas gdyCONVERT()Numery stylów są zagadkowe i mniej wyczerpujące, być może będziesz musiał użyć starszego podejścia, ponieważFORMAT()obowiązuje tylko w SQL Server 2012 i nowszych.- Nawet w trybie gotowości
CONVERT()Metoda może być drastycznie kosztowna (choć tylko poważnie, więc w przypadku, gdy SSMS musiał renderować wyniki - wyraźnie obsługuje łańcuchy inaczej niż wartości dat). - Po prostu pobranie wartości daty i godziny bezpośrednio z bazy danych było zawsze najbardziej wydajne. Powinieneś określić, jaki dodatkowy czas zajmuje Twojej aplikacji sformatowanie daty zgodnie z wymaganiami w warstwie prezentacji — jest wysoce prawdopodobne, że nie będziesz chciał, aby SQL Server w ogóle zajmował się formatowaniem (w rzeczywistości wielu by się spierał że to jest miejsce, do którego ta logika zawsze należy).
Mówimy tutaj tylko o mikrosekundach, ale mówimy też tylko o 1000 wierszy. Skaluj to do rzeczywistych rozmiarów stołów, a wpływ wyboru niewłaściwego podejścia do formatowania może być druzgocący.
Jeśli chcesz wypróbować ten eksperyment na własnym komputerze, przesłałem przykładowy skrypt:FormatIsNiceAndAllBut.sql_.zip