Podczas projektowania bazy danych należy pamiętać o wielu rzeczach, a bardzo niewielu z nas pamięta wszystkie cenne wskazówki i sztuczki, których się nauczyliśmy. Przyjrzyjmy się więc niektórym zasobom online, które zawierają wskazówki dotyczące projektowania baz danych i najlepsze praktyki. Po drodze podzielę się własnymi opiniami na temat przedstawionych pomysłów, opartymi na moim doświadczeniu w projektowaniu baz danych.
Oczywiście ten artykuł nie jest wyczerpującą listą, ale próbowałem przejrzeć i skomentować przekrój źródeł. Mamy nadzieję, że znajdziesz informacje, które najlepiej odpowiadają Twoim potrzebom i celom.
Na marginesie, zdziwiłem się, że wiele artykułów związanych z praktykami projektowania baz danych zawierało bardzo mało przykładów; zasoby internetowe, które przeglądałem pod kątem artykułu o błędach i pomyłkach, miały ich wyższy odsetek. Ten brak jest wadą, ponieważ przykłady są niezwykle ważne dla przekazania sedna sprawy.
Wskazówki dotyczące baz danych dla doświadczonych projektantów
Najpierw zacznijmy od źródeł zawierających zaawansowane wskazówki dotyczące projektowania baz danych i najlepsze praktyki. Są one przeznaczone dla projektantów, którzy już od jakiegoś czasu pracują w modelowaniu danych. Niektóre artykuły są skierowane na bardziej średniozaawansowany poziom, ale jeśli omawiają zaawansowane koncepcje, umieściłem je na tej liście.
Wytyczne dotyczące baz danych (RDBMS/SQL)
Steve Djajasaputra | SOA, Java, tworzenie oprogramowania – BlogSpot | 16 stycznia 2013
Ten artykuł pana Djajasaputry robi wrażenie:wymienia liczne wskazówki dotyczące schematu, indeksów i widoków; podaje też dość szczegółową konwencję nazewnictwa. A jego wskazówki są kontynuowane (i trwają). Rozpiętość jest imponująca, ale przykładów prawie nie ma. Niektóre z jego punktów można uznać za dyskusyjne, ale ogólnie jest to bardzo solidna prezentacja.
W szczególności byłem pod wrażeniem, że podaje precyzyjną regułę dotyczącą używania naturalnych i sztucznych (tj. zastępczych lub generowanych) kluczy podstawowych. Utrzymuje to ładnie i prosto, stwierdzając, że powinniśmy preferować naturalny klucz, ponieważ ma on znaczenie. Podaje również wskazówki dotyczące najlepszego wykorzystania klucza sztucznego – w szczególności, gdy klucz naturalny nie jest unikalny lub gdy trzeba zmienić wartość klucza naturalnego. Własnymi słowami:
Po pierwsze, wolę używać klucza naturalnego, ponieważ ma on większe znaczenie i uniknąć duplikacji (ponowne wykorzystanie istniejącej kolumny). Ale zdarzają się przypadki, kiedy potrzebny jest klucz sztuczny:gdy klucz naturalny nie jest unikalny (np. nazwy) lub gdy trzeba zmienić wartość.Ponieważ jego lista wskazówek jest tak długa, nie wyobrażam sobie ich wszystkich. Ale do każdej sekcji można się odwoływać podczas pracy nad projektem bazy danych, wydajnością, procedurami składowanymi i przechowywaniem wersji. Istnieje również sekcja dotycząca punktów specyficznych dla Oracle, która byłaby przydatna, jeśli pracujesz lub planujesz wspierać Oracle.
Podsumowując, jest to bardzo wartościowe i wszechstronne źródło.
9 wskazówek dotyczących lepszego projektowania baz danych
przez Jeffrey Edisona | Blog Vertabelo | 22 września 2015
Oddam się tutaj małej autopromocji.
Ten artykuł zawierający 9 wskazówek dotyczących lepszego projektowania baz danych opiera się na moim doświadczeniu jako projektanta i architekta. Znalazłem również dodatkowe spostrzeżenia, badając najlepsze praktyki innych dotyczące projektowania baz danych.
Moja lista przedstawia niektóre z głównych problemów, które mogą wystąpić podczas pracy z modelami danych. Uporządkowałem wskazówki w kolejności, w jakiej pojawiają się w cyklu życia projektu (a nie według ważności lub częstotliwości występowania), ponieważ byłoby to najbardziej przydatne, przynajmniej moim zdaniem. Czytelnicy mogą śledzić tę listę kontrolną najlepszych praktyk przez cały cykl życia projektu.
Z artykułu:
Parafrazując Ala Capone (lub Johna Van Burena, syna ósmego prezydenta USA), „testuj wcześnie, testuj często”. W ten sposób podążasz ścieżką Ciągłej Integracji. Testowanie na wczesnym etapie rozwoju pozwala zaoszczędzić czas i pieniądze. Celem testowania bazy danych powinno być zasymulowanie środowiska produkcyjnego:„Dzień z życia bazy danych”. Jakich ilości można się spodziewać? Jakie interakcje użytkownika są prawdopodobne? Czy sprawy graniczne są obsługiwane?Zwracając uwagę na te wskazówki, odkryłem, że bazy danych są lepiej zaprojektowane i bardziej niezawodne. Chociaż żadna z tych czynności nie zajmie dużo czasu, każda z nich może mieć ogromny wpływ na jakość Twojego modelu danych.
Mam nadzieję, że moja lista wskazówek będzie przydatna dla średnio zaawansowanych i zaawansowanych projektantów.
20 najlepszych praktyk projektowania baz danych
przez Cagdas Basaraner | Balans kodów – BlogSpot | 24 lipca 2011
Pan Basaraner przedstawia nam ciekawą listę 20 najlepszych praktyk projektowania baz danych. Wolałbym, żeby niektóre z nich pogrupował; na przykład wszystkie pierwsze cztery pozycje można opisać w ramach „Używaj konwencji dobrego nazewnictwa”.
Ponadto stwierdza, że najlepszym rozwiązaniem jest użycie syntetycznego, wygenerowanego (liczby całkowitej) identyfikatora jako klucza podstawowego wszystkich tabel. W rzeczywistości jest to nadal temat dyskusji, z argumentami za i przeciw. Niektóre z jego najlepszych praktyk są dość ogólne, na przykład „Dla… krytycznych systemów baz danych [sic!] używaj usług odzyskiwania po awarii i usług bezpieczeństwa…” Nie zgadzam się z tym punktem, ale jest to bardzo wysoki poziom.
Plusem jest to, że ten artykuł był jednym z nielicznych, w których wspomniano o użyciu frameworka mapowania obiektowo-relacyjnego (ORM). Niektórzy komentatorzy nie zgadzali się ze sposobem sformułowania wskazówki, ale wspomina się przynajmniej o użyciu frameworka ORM:
Użyj frameworka ORM (object relacyjnego mapowania) (np. Hibernate, iBatis ...), jeśli kod aplikacji jest wystarczająco duży. Problemy z wydajnością frameworków ORM można rozwiązać za pomocą szczegółowych parametrów konfiguracyjnych.Mimo to lista ta mogłaby zostać ulepszona. Powinien wyraźnie wskazywać punkty, które są specyficzne tylko dla niektórych systemy zarządzania bazami danych (na przykład SQL Server). Dokładne statystyki dotyczące wydajności, heurystyki lub znaczenia spędzania czasu na projektowaniu zamiast konserwacji i przeprojektowanie byłoby dobrze. Potrzebnych było również więcej przykładów, ale jest to problem w przypadku większości tych artykułów.
Jeśli pracujesz z SQL Server, rozważasz użycie frameworka ORM lub potrzebujesz wypunktowanej listy wskazówek zamiast długiego i szczegółowego artykułu, ten artykuł jest dla Ciebie.
(Uwaga:ten artykuł pojawił się również w kilku innych witrynach, w tym CodeBuild, Java Code Geeks i DZone).
Podstawy projektowania baz danych. 10 rzeczy, które koniecznie musisz zrobić
Michelle A. Poolet | SQL Server Pro | 1 marca 2011
Część wskazówek pani Poolet jest dość standardowa i można je znaleźć w wielu innych zasobach, ale jest też kilka dość nietypowych punktów. Wśród swoich ogólnych punktów promuje użycie podtypów i supertypów (z czym zdecydowanie się zgadzam), ponieważ odzwierciedla to projektowanie zorientowane obiektowo i może być łatwo zrozumiane przez programistów. Z jej artykułu:
Nie bój się włączać jednostek nadtypu i podtypu do swojego projektu w CDM i dalej. Podtypy reprezentują klasyfikacje lub kategorie nadtypu… Encje są reprezentowane jako podtypy, gdy do kategoryzacji encji potrzeba więcej niż jednego słowa lub frazy.
Jeśli kategoria żyje własnym życiem, z osobnymi atrybutami opisującymi wygląd i zachowanie kategorii oraz oddzielnymi relacjami z innymi bytami, to czas wywołać strukturę nadtypu/podtypu . Niezastosowanie się do tego uniemożliwi pełne zrozumienie danych i reguł biznesowych, które kierują gromadzeniem danych.
Niektóre z jej komentarzy odnoszą się do MS SQL Server, nawet jeśli są to w rzeczywistości ogólne kwestie. Jedna z głównych kwestii, które wysuwa pani Poolet, jest bardzo specyficzna dla SQL Server:„Kod sklepu, który dotyka danych bazy danych jako procedury składowanej”.
Jest to w porządku, jeśli planujesz obsługiwać tylko jeden system zarządzania bazą danych, taki jak SQL Server. Ale w przypadku przenośnych implementacji nie byłaby to dobra rada. Generalnie projektuję z myślą o przenoszeniu do co najmniej dwóch systemów zarządzania z obsługą różnych języków procedur składowanych. Dlatego unikałbym tej praktyki.
Ten artykuł jest najbardziej przydatny dla osób rozwijających SQL Server i koncentrujących się na rynku amerykańskim (a nie systemie międzynarodowym). Jednak jako Amerykanka mieszkająca za granicą stwierdziłam, że niektóre z jej przykładów są nieco zbyt „amerykańsko-centryczne”. Na przykład osoba niebędąca Amerykaninem może nie rozumieć, co oznacza Zip+4 domena jest i dlatego nie miałaby pojęcia, dlaczego ta domena powinna mieć charakterystykę NOT NULL.
Aby to zilustrować, stworzyłem model danych dla obu amerykańskich adresów nieamerykańskich. Założymy, że nasz model danych może wymagać, aby podmioty były połączone z więcej niż jednym adresem:na przykład jeden do rozliczeń, jeden do wysyłki. Pierwszy adres byłby powiązany z metodą płatności; w takim przypadku adres zostanie wykorzystany do zweryfikowania Twojego prawa do autoryzacji tej płatności. Oczywiście adres wysyłki to miejsce, do którego zostanie dostarczone zamówienie.
Stwórzmy adres amerykański w ramach modelu bazy danych zamówień klientów. (Uwaga:nie jest to kompletny model, ale przykład przechowywania zamówień produktów.)
Wise Coders Solutions zaleca zdefiniowanie oddzielnych pól dla numerów domów i nazw ulic oraz ustawienie tych pól jako NIE NULL; to uniemożliwiłoby dostęp do dowolnego adresu, który nie ma numeru domu i nazwy ulicy. Ale co z ludźmi, którzy używają skrytek pocztowych? Ich adresy są zwykle pisane jako „PO Box 123”. Czy powinniśmy zmusić ich do umieszczenia numeru skrytki pocztowej jako numeru domu i „Skrzynka pocztowa” jako nazwy ulicy? Nie sądzę.
Zamiast tego użyjemy formularza z „Wiersz adresu 1” i „Wiersz adresu 2”. Kilka osób sprzeciwiało się używaniu liczb w nazwach pól, ale dla mnie jest to dość oczywiste rozwiązanie. Zdefiniowałem również maksymalne długości pól (35 i 70 znaków), które są typowe w płatnościach międzynarodowych.
Zwróć uwagę, że zarówno projekty amerykańskie, jak i inne, mają pole dla regionów w kraju, ale projekt amerykański wymaga uwzględnienia dwuznakowego skrótu stanu. Zwróć też uwagę, że projekt w USA nie pozwala na adresy w innych krajach.
Jeśli masz obawy dotyczące globalnego wykorzystania Twojej bazy danych, musisz myśleć globalnie na etapie projektowania. Czy nasze bazy danych są przygotowane do międzynarodowego użytkowania naszych aplikacji?
Wnioski wyciągnięte ze złego projektu hurtowni danych
Michelle A. Poolet | SQL Server Pro | 15 czerwca 2009
W tym artykule przyjrzymy się hurtowni danych (DWH) oraz niektórym problemom związanym z jej projektowaniem i implementacją. W niewielkim stopniu skupiono się na SQL Server, ale jest to dość ortodoksyjny przegląd projektowania pod kątem hurtowni danych i analizy biznesowej. Posiadanie wpisowego i tworzenie przyjaznych dla użytkownika interfejsów może nie być najbardziej użytecznymi wskazówkami, ale nie zgadzam się z nimi – po prostu nie sądzę, że są one częścią projektu DWH.
Pani Poolet twierdzi, że proces ekstrakcji-transformacji-ładowania (ETL) powinien przeprowadzać kontrole jakości danych i potencjalnie „czyścić” dane, dopóki nie będzie akceptowalnego standardu jakości danych. Moim zdaniem grozi to stworzeniem hurtowni danych, która nie będzie właściwie odzwierciedlać informacji wydobytych z systemu źródłowego. Czyszczenie danych powinno odbywać się w systemach źródłowych. ETL powinien przekształcać dane tylko w taki sposób, aby można je było załadować do hurtowni danych.
Z pozytywnej strony zalecenie dotyczące recyklingu lub tworzenia procedur ETL wielokrotnego użytku jest bardzo istotne. Dodatkowo zgadzam się z Panią Poolet co do skalowalności. Jej komentarze na temat zarządzania ryzykiem i zgodności, zwłaszcza ustawy Sarbanes-Oxley, wydają się dość konkretne; Zakładam, że pochodzą one z jej obszaru działalności.
Wreszcie ma ładną listę kontrolną punktów związanych z wymiarami, tabelami faktów i wyborem schematu podczas projektowania OLAP (przetwarzanie analityczne online). Wydaje się, że są one bardzo istotne w procesie projektowania bazy danych. Chciałbym, aby ta lista była dłuższa, zawierała więcej szczegółów lub przykładów, ale cieszyłem się, że te praktyczne wskazówki zostały uwzględnione.
11 ważnych zasad projektowania baz danych, których przestrzegam
przez Shivprasad Koirala | Kod Projekt | 25 lutego 2014
Bardzo podoba mi się rozsądna i jasna rada na początku tego artykułu. Pojęcia takie jak „rozważ naturę aplikacji” i „podziel dane na logiczne części” są na miejscu. Są to ważne pomoce podczas tworzenia modelu danych. Jak mówi pan Koirala:
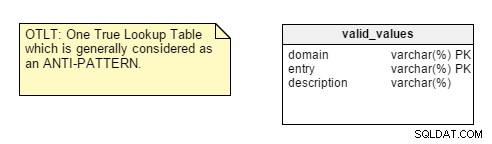
Kiedy zaczynasz projektowanie bazy danych, pierwszą rzeczą do przeanalizowania jest charakter aplikacji, dla której projektujesz, czy jest to transakcyjna czy analityczna. Wielu programistów domyślnie stosuje reguły normalizacji, nie zastanawiając się nad naturą aplikacji, a później wchodząc w problemy z wydajnością i dostosowywaniem.Jest jednak kilka punktów, które mnie nie przekonują. Na przykład weź centralizację par Nazwa-Wartość w jednej tabeli. Ten projekt jednej prawdziwej tabeli wyszukiwania (OTLT) jest przedmiotem dyskusji, ale ogólnie uważa się go za złą praktykę lub przynajmniej za antywstrzał w projektowaniu. Jestem po stronie grupy anty-OTLT; tabele te wprowadzają liczne problemy. Jako ekwiwalent tej praktyki możemy zastosować analogię tworzenia oprogramowania polegającą na użyciu pojedynczego enumeratora do reprezentowania wszystkich możliwych wartości wszystkich możliwych stałych.
Dla przypomnienia, tabela OTLT zazwyczaj wygląda mniej więcej tak, z wpisami z wielu domen wrzuconymi do tej samej tabeli. Zgadzam się z grupą anty-OTLT; te tabele wprowadzają liczne problemy.
Ponadto niektóre punkty wydają się nieco ezoteryczne, jak np. „szukaj danych oddzielonych separatorami”. Chociaż jest to słuszny punkt, zwykle nie myślę o nim podczas tworzenia nowego modelu danych.
Pan Koirala ma kilka elementów projektowania OLAP, które na ogół nie są wymienione na innych listach najlepszych praktyk. Jego włączenie projektu wymiaru i faktów może być przydatne, ale może być również niebezpieczne dla początkujących projektantów.
Ten artykuł jest interesujący, jeśli od początku przechodzisz do bardziej zaawansowanego modelowania danych. Pomoże Ci rozważyć analityczny i transakcyjny charakter Twoich przyszłych modeli.
Wielkie dane:pięć prostych wskazówek dotyczących wydajności projektowania baz danych
Autor:Dave Beulke | davebeulke.com | 19 marca 2013

Artykuł pana Beulke dotyczy wskazówek projektowych zorientowanych na wydajność. Pokazuje, jak sprawdzić, czy normalizacja jest prawidłowa:ani za dużo, ani za mało. (Nadmierna normalizacja będzie miała negatywny wpływ na wydajność bazy danych).
Ponadto używanie naturalnych kluczy biznesowych zamiast wygenerowanych kluczy podstawowych jest dobrą radą, gdy chcesz uniknąć tłumaczenia z klucza biznesowego na wygenerowany identyfikator wiersza dla każdego dostępu do bazy danych.
Dobrą radą jest również stosowanie odpowiednich standardów nazewnictwa i typów kolumn. Kwestia nadużywania kolumn dopuszczających wartość null jest słuszna:tworzenie wszystkich kolumn jako dopuszczających wartość null jest błędem, ale zdefiniowanie kolumny jako dopuszczającej wartość null może być wymagane dla określonej funkcji biznesowej. Własnymi słowami autora:
Czy wszystkie kolumny mogą mieć wartość NULL? W ramach definicji kolumn bazy danych dobre domeny danych, zakresy i wartości powinny być analizowane, oceniane i prototypowane pod kątem aplikacji biznesowej. Dobre wartości domyślne, ograniczony zakres wartości i zawsze wartość są najlepsze dla wydajności i logiki aplikacji. Kolumny dopuszczające wartość NULL są dobre tylko wtedy, gdy dane są nieznane lub nie mają jeszcze wartości. Dane dotyczące czyjejś daty śmierci są klasycznym przykładem kolumny NULLable, ponieważ są nieznane, chyba że osoba już nie żyje. Upewnij się, że projekt bazy danych reprezentuje znane dane i używa tylko co najmniej kolumn dopuszczających wartość NULL.Wskazówki pana Beulke są bardzo solidne, nawet jeśli nieco nieoryginalne. Chciałbym więcej pozycji Big Data – czyli w końcu tytuł artykułu. W końcu poczułem, że artykułowi brakuje zarówno głębi, jak i szerokości, i nie ma przykładów wyjaśniających kwestie. Oferuje jednak cenne rady związane z normalizacją i kluczami naturalnymi.
10 najlepszych praktyk projektowania bazy danych
Autor:Ann All | Aplikacje dla przedsiębiorstw dzisiaj | 15 lipca 2014
Dziesięć najlepszych praktyk projektowania baz danych jest w rzeczywistości przedstawionych jako seria slajdów. Ms. All zawiera informacje od doświadczonych programistów, takich jak Michael Blaha. Zachęca do ponownego wykorzystywania najlepszych praktyk i wzorców. Są one zrozumiałe i sprawdzone i pod tym względem lepsze niż modele danych, które trzeba tworzyć od podstaw. Z artykułu pani All:
Na przykład często zajmuję się inżynierią wsteczną baz danych – baz danych aplikacji do zastąpienia oraz baz danych aplikacji powiązanych. Te istniejące bazy danych często nie mają dostępnego modelu danych. Jednak model danych jest ukryty w schemacie bazy danych i można go przynajmniej częściowo wyodrębnić za pomocą technik inżynierii odwrotnej bazy danych. … Istnieją wypróbowane i prawdziwe reprezentacje danych, które często występują i nie muszą być odtwarzane od zera.Jest to krótki pokaz slajdów, który projektanci modeli danych mogą szybko przejrzeć i zebrać wskazówki, które pasują do nich. Dla mnie wskazówka dotycząca ponownego użycia jest jedną z moich ulubionych.
Najlepsze praktyki dotyczące baz danych
Cunningham &Cunningham, Inc.
Te najlepsze praktyki zaczęły się dobrze, ale potem pojawiły się kilka lepkich problemów. Nie jestem przekonany, że oferowane porady są zawsze trafne.
Z drugiej strony są bardzo ładne opisy kontrowersyjnych „najlepszych praktyk”, takich jak zawsze używanie automatycznie generowanych kluczy zastępczych i używanie lub unikanie procedur składowanych. Jako przykład:
Poprzedni autor napisał:„Zasadniczo unikaj kluczy podstawowych, które mają znaczenie. Nazwy nie są unikalne, a wiele pozornie unikalnych identyfikatorów, takich jak numery ubezpieczenia społecznego, w rzeczywistości nie jest, ze względu na problemy z wiarygodnością danych w świecie rzeczywistym”. Krótko mówiąc, jest to zalecenie, aby zawsze mieć automatycznie generowany (zazwyczaj numeryczny) klucz zastępczy zamiast klucza logicznego opartego na domenie. Jest to raczej rozsądna odpowiedź na złożony problem, chociaż wystarczy w wielu przypadkach i jest przynajmniej lepsza niż brak klucza podstawowego.(Uwaga autora:nie udało mi się znaleźć tego „poprzedniego autora” podczas wyszukiwania tych dwóch zdań w Google).
Dostępny jest również link do artykułu podsumowującego o głównych argumentach po obu stronach debaty na temat kluczy automatycznych kontra klucze domeny.
Z drugiej strony znalazłem wskazówki dotyczące „dzielenia systemu operacyjnego, danych i logowania na różne dyski fizyczne” oraz „używania macierzy RAID” nieco tajemne. Nie zrozumcie mnie źle – w pewnych okolicznościach jest to prawdopodobnie rozsądna rada, ale nie umieściłbym jej na mojej liście Top 20.
Wskazówki dotyczące projektowania bazy danych
przez Wise Coders
W tej kolekcji znajduje się kilka unikalnych i interesujących wskazówek, takich jak zalecenie jak najszybszego zamknięcia transakcji.
Jednak nie zgadzam się całkowicie ze wszystkimi wskazówkami projektowymi tutaj. Na przykład:
Załóżmy, że pole „Status” ma wartości „Aktywny”, „Nieaktywny” i „Nieaktywny”. Możesz zapisać wartość jako pełną nazwę, ale może to być nieefektywne. Przechowywanie wyliczenia lub char(1) z możliwymi wartościami „a”, „i”, „d”, na przykład, zajmie mniej miejsca w bazie danych.Jest to co najmniej kontrowersyjne – inne źródła odradzają stosowanie takich „tajnych kodów”. Zamiast tego użyj oddzielnej tabeli do przechowywania tych kodów stanu.
Ponadto statystyki związane ze wskazówkami dotyczącymi wydajności są wątpliwe i w artykule nie ma przykładów.
Pozytywnie, jest to ładna krótka lista wskazówek, które powinny być dostępne dla średniozaawansowanych modelarzy baz danych.
Zasoby dla początkujących projektantów baz danych
Przyjrzyjmy się teraz kilku artykułom dla tych, którzy dopiero rozpoczynają projektowanie baz danych.
Podstawy dobrego projektowania baz danych w tworzeniu stron internetowych
Kayla Knight | Onextrapixel.com | 17 marca 2011
Tutaj otrzymujemy nieco bardziej zaawansowani, z poradami od funkcjonalności po narzędzia do modelowania.
Pani Knight prowadzi nas przez wprowadzenie do projektowania baz danych. Jej artykuł jest interesujący, ponieważ kładzie nacisk na bazy danych do tworzenia stron internetowych. Mimo to jej punkty są dość uniwersalne i można je zastosować do projektowania baz danych w wielu sytuacjach.
Artykuł zaczyna się od poproszenia nas o szerokie myślenie o funkcjonalności, a nie tylko o bazie danych:
Myśl poza bazą danych. Spróbuj zastanowić się, co strona będzie musiała zrobić. Na przykład, jeśli potrzebna jest witryna członkowska, pierwszym odruchem może być myślenie o wszystkich danych, które każdy użytkownik będzie musiał przechowywać. Zapomnij o tym, to na później. Raczej zapisz, że użytkownicy i ich informacje będą musiały być przechowywane w bazie danych, a co jeszcze? Co ci członkowie będą musieli zrobić na stronie? Czy będą publikować posty, przesyłać pliki lub zdjęcia lub wysyłać wiadomości? Wtedy baza danych będzie potrzebować miejsca na pliki/zdjęcia, posty i wiadomości.Stamtąd pani Knight zabiera czytelnika do narzędzi do projektowania baz danych i kroków związanych z tym procesem. Jej artykuł zawiera przykłady i linki do innych zasobów.
Myślę, że ten artykuł byłby świetnym wprowadzeniem dla początkujących projektantów baz danych i powinien dobrze współpracować z Geek Girl seria.
Porady dotyczące projektowania baz danych
Autor:Doug Lowe | Dla głupków
Lista „Dummies” pana Lowe'a to szeroka seria podstawowych wskazówek projektowych. Wiele z nich można znaleźć gdzie indziej, ale warto mieć je w jednym miejscu. Nie znajdziesz niczego wyjątkowego ani wysoce kontrowersyjnego, z wyjątkiem zalecenia korzystania z procedur składowanych. Zawsze kwestionuję to mocne stwierdzenie, ponieważ jestem bardzo zaniepokojony przenośnością modelu danych dla wielu systemów DBM.
Oto jedna ze zdroworozsądkowych wskazówek pana Lowe:
Unikaj pól o nazwach takich jak CustomerType, gdzie wartość pola jest jedną z kilku stałych, które nie są zdefiniowane nigdzie indziej w bazie danych, takich jak R dla handlu detalicznego lub W dla hurtu. Obecnie możesz mieć tylko te dwa typy klientów, ale potrzeby aplikacji mogą się zmienić w przyszłości, wymagając trzeciego typu klienta.Te zalecenia są najbardziej odpowiednie podczas pracy z SQL Server.
Pięć prostych wskazówek dotyczących projektowania baz danych
Lamont Adams | TechRepublic | 25 czerwca 2001
Kluczowym słowem dla tego zasobu jest „prosty”. Możesz znaleźć te informacje, wraz z dodatkowymi wyjaśnieniami i przykładami, w innych artykułach.
Jednak rada pana Adamsa „Zabierz klucze użytkownika” jest ciekawym punktem, rzadko wspominanym w innych miejscach. Kontynuuje:
Decydując, które pole lub pola mają być używane jako klucze w tabeli, zawsze bierz pod uwagę pola, które będą edytować użytkownicy. Wybór pola edytowalnego przez użytkownika jako klucza jest zwykle złym pomysłem.Pan Adams ma na myśli to, że przy podejmowaniu decyzji, które pola mają być użyte jako klucze, należy wziąć pod uwagę potencjalne wymagania użytkownika dotyczące edytowania pól. Chciałbym więcej wyjaśnień dotyczących alternatyw, takich jak klucze syntetyczne/generowane, ale koncepcja jest dobra.
Nie zgadzam się z ostatnim punktem. Zaleca „współczynnik krówki” dla każdego projektowanego stołu:
Niewiele jest gorsze niż odkrycie lub otrzymanie informacji, że w Twojej „skończonej” bazie danych brakuje pola na kluczową informację. W jednej z firm, dla której pracowałem, było to tak powszechne, że zaczęliśmy odnosić się do „zamrożenia baz danych” jako „zamrożonych baz danych”.Moim zdaniem jest to w zasadzie „dodanie kilku dodatkowych pól tekstowych na koniec”. Wydaje się, że jest to sprzeczne z niektórymi innymi wskazówkami pana Adamsa, w szczególności dotyczącymi zrozumienia potrzeb biznesowych i używania znaczących nazw. Te dodatkowe pola krówki nazwano by po prostu czymś w rodzaju „extra1” lub „extra2”. Jakie są ich potrzeby biznesowe? A jakie znaczenie mają te nazwy? Chociaż podoba mi się większość jego wskazówek projektowych, ten „czynnik krówki” nie jest czymś, do czego się stosuję.
Projekt bazy danych:wyróżnienia
Oczywiście istnieją inne artykuły, które opisują wskazówki dotyczące projektowania baz danych i najlepsze praktyki. Dodatkowe materiały można znaleźć pod następującymi linkami:
Projekt relacyjnej bazy danych:podstawa najlepszych praktyk | autorstwa Digital Ethos | 24 grudnia 2012
Najlepsze praktyki w zakresie projektowania schematów baz danych (początkujący) | autor:Jim Murphy | 28 marca 2011
Najlepsze praktyki IT:projektowanie baz danych | przez University of Nebraska-Lincoln
Zasoby do projektowania baz danych online:dokąd byś się udał?
Jak wspomniano, ta lista zdecydowanie nie jest wyczerpującą analizą każdego artykułu dotyczącego projektowania baz danych w Internecie. Zamiast tego zidentyfikowaliśmy kilka artykułów, które naszym zdaniem są przydatne lub które koncentrują się na konkretnych kwestiach, które mogą okazać się pomocne.
Zachęcamy do polecania dodatkowych artykułów.