Posiadanie tabel referencyjnych w bazie danych to nic wielkiego, prawda? Wystarczy powiązać kod lub identyfikator z opisem dla każdego typu referencyjnego. Ale co, jeśli masz dosłownie dziesiątki tabel referencyjnych? Czy istnieje alternatywa dla podejścia „jeden stół na typ”? Czytaj dalej, aby odkryć ogólne i rozszerzalne projekt bazy danych do obsługi wszystkich danych referencyjnych.
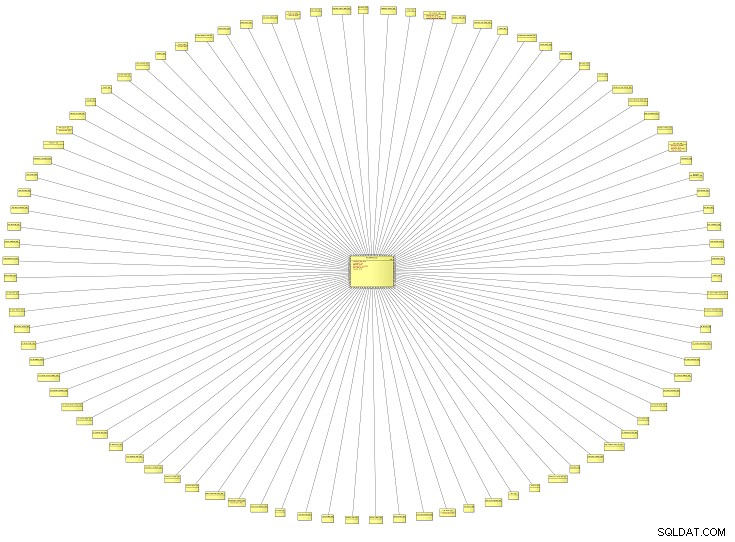
Ten nietypowo wyglądający diagram to widok z lotu ptaka na logiczny model danych (LDM) zawierający wszystkie typy referencyjne dla systemu korporacyjnego. Pochodzi z instytucji edukacyjnej, ale może mieć zastosowanie do modelu danych dowolnej organizacji. Im większy model, tym więcej typów referencyjnych prawdopodobnie odkryjesz.
Przez typy referencyjne rozumiem dane referencyjne lub wartości wyszukiwania lub – jeśli chcesz być flash – taksonomie . Zazwyczaj wartości zdefiniowane tutaj są używane na listach rozwijanych w interfejsie użytkownika aplikacji. Mogą również pojawiać się jako nagłówki w raporcie.
Ten konkretny model danych miał około 100 typów referencyjnych. Powiększmy i przyjrzyjmy się tylko dwóm z nich.
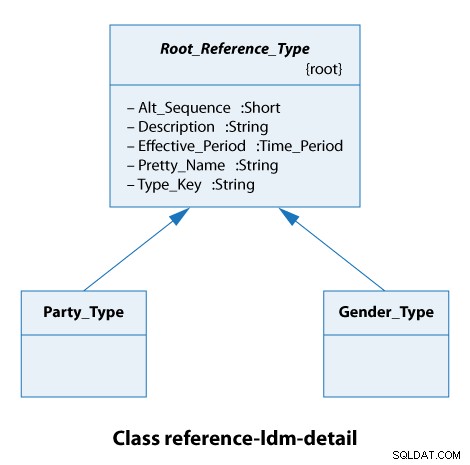
Na tym diagramie klas widzimy, że wszystkie typy odwołań rozszerzają Root_Reference_Type . W praktyce oznacza to po prostu, że wszystkie nasze typy referencyjne mają te same atrybuty z Alt_Sequence przez Type_Key włącznie, jak pokazano poniżej.
| Atrybut | Opis |
|---|---|
Alt_Sequence | Służy do definiowania alternatywnej sekwencji, gdy wymagana jest kolejność niealfabetyczna. |
Description | Opis typu. |
Effective_Period | Efektywnie określa, czy wpis odniesienia jest włączony. Po użyciu odniesienia nie można go usunąć z powodu ograniczeń referencyjnych; można go tylko wyłączyć. |
| Ładna nazwa tego typu. To właśnie widzi użytkownik na ekranie. |
Type_Key | Unikalny wewnętrzny KLUCZ dla typu. Jest to ukryte przed użytkownikiem, ale twórcy aplikacji mogą w szerokim zakresie wykorzystać to w swoim SQL. |
Rodzaj imprezy to organizacja lub osoba. Rodzaje płci są męskie i żeńskie. To są naprawdę proste przypadki.
Tradycyjne rozwiązanie tabeli referencyjnej
Jak więc zaimplementujemy model logiczny w fizycznym świecie rzeczywistej bazy danych?
Moglibyśmy przyjąć, że każdy typ referencyjny będzie mapowany na własną tabelę. Możesz odnieść się do tego jako bardziej tradycyjnego jeden stół na klasę rozwiązanie. Jest to dość proste i wyglądałoby mniej więcej tak:
Wadą tego jest to, że mogą istnieć dziesiątki takich tabel, wszystkie z tymi samymi kolumnami, robiące bardzo to samo.
Ponadto możemy tworzyć znacznie więcej prac programistycznych . Jeśli dla administratorów wymagany jest interfejs użytkownika dla każdego typu, aby zachować wartości, ilość pracy szybko się mnoży. Nie ma na to twardych i szybkich reguł – to naprawdę zależy od Twojego środowiska programistycznego – więc musisz porozmawiać z programistami aby zrozumieć, jaki to ma wpływ.
Ale biorąc pod uwagę, że wszystkie nasze typy referencyjne mają te same atrybuty lub kolumny, czy istnieje bardziej ogólny sposób implementacji naszego logicznego modelu danych? Tak jest! I wymaga tylko dwóch stołów .
Rozwiązanie dwóch stołów
Pierwsza dyskusja, jaką miałem na ten temat, miała miejsce w połowie lat 90., kiedy pracowałem dla firmy ubezpieczeniowej London Market. Wtedy przeszliśmy od razu do projektowania fizycznego i używaliśmy głównie kluczy naturalnych/biznesowych, a nie identyfikatorów. Tam, gdzie istniały dane referencyjne, zdecydowaliśmy się zachować jedną tabelę dla każdego typu, która składała się z unikalnego kodu (VARCHAR PK) i opisu. W rzeczywistości tabel referencyjnych było wtedy znacznie mniej. Częściej niż nie, ograniczony zestaw kodów biznesowych byłby używany w kolumnie, prawdopodobnie ze zdefiniowanym ograniczeniem sprawdzania bazy danych; nie byłoby żadnej tabeli referencyjnej.
Ale od tego czasu gra toczyła się dalej. To właśnie jest rozwiązanie z dwoma stołami może wyglądać tak:
Jak widać, ten fizyczny model danych jest bardzo prosty. Ale różni się to znacznie od modelu logicznego i nie dlatego, że coś przybrało kształt gruszki. To dlatego, że wiele rzeczy zostało wykonanych w ramach projektu fizycznego .
reference_type tabela reprezentuje każdą indywidualną klasę odniesienia z LDM. Więc jeśli masz 20 typów referencyjnych w LDM, będziesz mieć 20 wierszy metadanych w tabeli. reference_value tabela zawiera dopuszczalne wartości dla wszystkich typy referencyjne.
W czasie tego projektu toczyły się dość ożywione dyskusje między programistami. Niektórzy preferowali rozwiązanie z dwoma stołami, a inni woleli opcję jeden stół na typ metoda.
Każde rozwiązanie ma swoje plusy i minusy. Jak można się domyślić, programiści byli głównie zaniepokojeni ilością pracy, jakiej wymagałby interfejs użytkownika. Niektórzy myśleli, że stworzenie interfejsu administratora dla każdego stołu byłoby dość szybkie. Inni uważali, że tworzenie jednego interfejsu administratora byłoby bardziej skomplikowane, ale ostatecznie się opłaci.
W tym konkretnym projekcie preferowano rozwiązanie z dwoma stołami. Przyjrzyjmy się temu bardziej szczegółowo.
Rozszerzalny i elastyczny wzorzec danych referencyjnych
Ponieważ model danych ewoluuje w czasie i wymagane są nowe typy odwołań, nie musisz wprowadzać zmian w bazie danych dla każdego nowego typu odwołania. Wystarczy zdefiniować nowe dane konfiguracyjne. Aby to zrobić, dodaj nowy wiersz do reference_type tabeli i dodaj kontrolowaną listę dopuszczalnych wartości do reference_value tabela.
Ważną koncepcją zawartą w tym rozwiązaniu jest definiowanie efektywnych okresów czasu dla pewnych wartości. Na przykład Twoja organizacja może potrzebować przechwycić nową reference_value „Dowód tożsamości”, który będzie akceptowany w przyszłości. Wystarczy dodać tę nową reference_value z effective_period_from data prawidłowo ustawiona. Można to zrobić wcześniej. Do tej daty nowy wpis nie pojawi się na rozwijanej liście wartości, które widzą użytkownicy Twojej aplikacji. Dzieje się tak, ponieważ Twoja aplikacja wyświetla tylko wartości, które są aktualne lub włączone.
Z drugiej strony może być konieczne powstrzymanie użytkowników przed używaniem określonej reference_value . W takim przypadku po prostu zaktualizuj go za pomocą effective_period_to data prawidłowo ustawiona. Gdy ten dzień minie, wartość nie będzie już wyświetlana na liście rozwijanej. Od tego momentu staje się wyłączony. Ale ponieważ nadal fizycznie istnieje jako wiersz w tabeli, zachowywana jest integralność referencyjna dla tych tabel, do których już się odniesiono.
Teraz, gdy pracowaliśmy nad rozwiązaniem z dwoma tabelami, stało się jasne, że niektóre dodatkowe kolumny będą przydatne w reference_type stół. Skupiały się one głównie na problemach związanych z interfejsem użytkownika.
Na przykład pretty_name na reference_type tabela została dodana do użytku w interfejsie użytkownika. W przypadku dużych taksonomii pomocne jest użycie okna z funkcją wyszukiwania. Następnie pretty_name może być użyty jako tytuł okna.
Z drugiej strony, jeśli wystarczy rozwijana lista wartości, pretty_name może być używany do monitu LOV. W podobny sposób opis może być użyty w interfejsie użytkownika do wypełnienia pomocy po najechaniu myszą.
Spojrzenie na typ konfiguracji lub metadanych, które trafiają do tych tabel, pomoże nieco wyjaśnić.
Jak zarządzać tym wszystkim
Chociaż użyty tutaj przykład jest bardzo prosty, wartości referencyjne dla dużego projektu mogą szybko stać się dość złożone. Może więc być wskazane, aby zachować to wszystko w arkuszu kalkulacyjnym. Jeśli tak, możesz użyć samego arkusza kalkulacyjnego do wygenerowania kodu SQL przy użyciu konkatenacji ciągów. Jest to wklejane do skryptów, które są wykonywane na docelowych bazach danych, które obsługują cykl rozwoju i produkcyjną (żywą) bazę danych. Spowoduje to zaszczepienie bazy danych wszystkimi niezbędnymi danymi referencyjnymi.
Oto dane konfiguracyjne dla dwóch typów LDM, Gender_Type i Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
W reference_type dla każdego podtypu LDM Root_Reference_Type . Opis w reference_type pochodzi z opisu klasy LDM. Dla Gender_Type , to brzmiałoby „Identyfikuje płeć osoby”. Fragmenty kodu DML pokazują różnice w opisach między typem a wartością, które mogą być używane w interfejsie użytkownika lub w raportach.
Zobaczysz, że reference_type o nazwie Gender_Type został przydzielony zakres od 13000000 do 13999999 dla powiązanych reference_value.ids . W tym modelu każdy reference_type otrzymuje unikalny, nienakładający się zakres identyfikatorów. Nie jest to bezwzględnie konieczne, ale pozwala nam na grupowanie powiązanych identyfikatorów wartości. To trochę naśladuje to, co można by uzyskać, gdybyś miał osobne stoły. Fajnie jest mieć, ale jeśli uważasz, że nie ma z tego żadnych korzyści, możesz się z tego obejść.
Kolejna kolumna dodana do PDM to admin_role . Oto dlaczego.
Kim są administratorzy
Niektóre taksonomie mogą mieć dodane lub usunięte wartości z niewielkim wpływem lub bez żadnego wpływu. Będzie to miało miejsce, gdy żaden program nie użyje wartości w swojej logice lub gdy typ nie jest połączony z innymi systemami. W takich przypadkach administratorzy użytkowników mogą bezpiecznie je aktualizować.
Ale w innych przypadkach należy zachować znacznie większą ostrożność. Nowa wartość odniesienia może spowodować niezamierzone konsekwencje dla logiki programu lub dalszych systemów.
Załóżmy na przykład, że do taksonomii Gender Type dodamy:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
To szybko staje się problemem, jeśli mamy gdzieś wbudowaną następującą logikę:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Oczywiście, logika „jeśli nie jesteś mężczyzną, musisz być kobietą” nie ma już zastosowania w rozszerzonej taksonomii.
W tym miejscu admin_role kolumna wchodzi w grę. Narodził się z dyskusji z programistami na temat fizycznego projektu i działał w połączeniu z ich rozwiązaniem interfejsu użytkownika. Ale jeśli wybrano rozwiązanie jedna tabela na klasę, to reference_type by nie istniał. Zawarte w nim metadane zostałyby na stałe zakodowane w aplikacji Gender_Type tabela – , która nie jest ani elastyczna, ani rozszerzalna.
Tylko użytkownicy z odpowiednimi uprawnieniami mogą administrować taksonomią. Prawdopodobnie będzie to oparte na wiedzy merytorycznej (MŚP ). Z drugiej strony, niektóre taksonomie mogą wymagać administrowania przez dział IT, aby umożliwić analizę wpływu, dokładne testowanie i harmonijne publikowanie wszelkich zmian w kodzie przed nową konfiguracją. (Niezależnie od tego, czy odbywa się to poprzez prośby o zmianę, czy w inny sposób, zależy to od Twojej organizacji).
Być może zauważyłeś, że kolumny kontrolne created_by , created_date , updated_by i updated_date nie są w ogóle przywoływane w powyższym skrypcie. Ponownie, jeśli nie jesteś nimi zainteresowany, nie musisz ich używać. Ta konkretna organizacja miała standard, który nakazywał umieszczanie kolumn kontrolnych w każdej tabeli.
Przyczyny:utrzymywanie spójności
Wyzwalacze zapewniają, że te kolumny kontrolne są stale aktualizowane, bez względu na źródło SQL (skrypty, aplikacja, zaplanowane aktualizacje wsadowe, aktualizacje ad-hoc itp.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Moje tło to głównie Oracle i niestety Oracle ogranicza identyfikatory do 30 bajtów. Aby uniknąć przekroczenia tego, każdej tabeli nadawany jest krótki alias składający się z trzech do pięciu znaków, a inne artefakty związane z tabelą używają tego aliasu w swoich nazwach. A więc reference_value alias to reva – pierwsze dwa znaki z każdego słowa. Przed wstawieniem wiersza i zanim aktualizacja wiersza zostanie skrócona do bri i bru odpowiednio. Nazwa sekwencji reva_seq i tak dalej.
Takie ręczne kodowanie wyzwalaczy, tabela po tabeli, wymaga od programistów dużo demoralizującej pracy z płytą kotłową. Na szczęście te wyzwalacze można tworzyć poprzez generowanie kodu , ale to temat innego artykułu!
Znaczenie kluczy
ref_type_key i type_key obie kolumny są ograniczone do 30 bajtów. Pozwala to na ich użycie w zapytaniach SQL typu PIVOT (w Oracle. Inne bazy danych mogą nie mieć takiego samego ograniczenia długości identyfikatora).
Ponieważ unikalność klucza jest zapewniana przez bazę danych, a wyzwalacz zapewnia, że jego wartość pozostaje taka sama przez cały czas, te klucze mogą – i powinny – być używane w zapytaniach i kodzie, aby były bardziej czytelne . Co przez to rozumiem? Cóż, zamiast:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Piszesz:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Zasadniczo klucz wyraźnie określa, co robi zapytanie .
Od LDM do PDM, z możliwością rozwoju
Podróż z LDM do PDM niekoniecznie jest prostą drogą. Nie jest to też bezpośrednia przemiana jednego w drugie. To osobny proces, który wprowadza własne przemyślenia i własne obawy.
Jak modelujesz dane referencyjne w swojej bazie danych?