Najlepsze oprocentowanie przynosi inwestycja w wiedzę.
Benjamin Franklin
We współczesnym świecie edukacja jest wszechobecna. Teraz bardziej niż kiedykolwiek wcześniej odgrywa ważną rolę w naszym społeczeństwie. W rzeczywistości jest to tak ważne, aby wielu z nas dobrze kontynuowało naukę po ukończeniu szkoły lub studiów.
Wszyscy słyszeliśmy o uczeniu się przez całe życie, edukacji pozaformalnej i warsztatach dla wszystkich grup wiekowych. Metody te różnią się pod wieloma względami od edukacji formalnej, ale mają też pewne cechy wspólne. Są klasy, lekcje, nauczyciele i uczniowie. I tak jak w tradycyjnym otoczeniu, będziemy chcieli śledzić harmonogram zajęć, dane o frekwencji oraz osiągnięcia instruktora lub ucznia. Jak możemy zaprojektować bazę danych, aby sprostać tym potrzebom? Właśnie to omówimy w tym artykule.
Przedstawiamy nasz model edukacyjnej bazy danych
Model przedstawiony w tym artykule umożliwia nam przechowywanie danych o:
- zajęcia/wykłady
- instruktorzy/wykładowcy
- studenci
- obecność na wykładach
- osiągnięcia uczniów / wykładowców
Moglibyśmy również wykorzystać ten model jako plan zajęć szkolnych, do innych zajęć grupowych (lekcje pływania, warsztaty taneczne) lub nawet do zajęć indywidualnych, takich jak korepetycje. Wciąż jest dużo miejsca na ulepszenia, takie jak przechowywanie danych o lokalizacji zajęć czy czasu trwania warsztatów; omówimy je w nadchodzących artykułach.
Zacznijmy od naszych podstawowych elementów bazy danych edukacji:tabel.
Wielka trójka:tabele uczniów, instruktorów i klas
student , instructor i class tabele stanowią rdzeń naszej bazy danych.
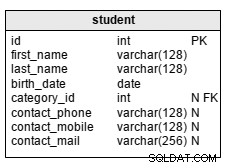
student tabela, pokazana powyżej, służy do przechowywania podstawowych danych o uczniach, ale może być rozbudowywana w zależności od potrzeb. Z wyjątkiem trzech atrybutów kontaktu, wszystkie atrybuty w tabeli są wymagane:
first_name– imię i nazwisko ucznialast_name– nazwisko uczniabirth_date– data urodzenia uczniacontact_phone– numer telefonu uczniacontact_mobile– numer telefonu komórkowego uczniacontact_mail– adres e-mail uczniacategory_id– jest odniesieniem docategorykatalog. Dzięki tej strukturze jesteśmy ograniczeni tylko do jednej kategorii na ucznia. To działa w większości przypadków, ale w niektórych sytuacjach możemy potrzebować miejsca na wymienienie wielu kategorii. Jak widać, dodanie relacji wiele-do-wielu, która łączystudenttabela zcategorysłownik rozwiązuje ten problem. Jednak w tym scenariuszu będziemy musieli napisać bardziej złożone zapytania, aby obsłużyć nasze dane.
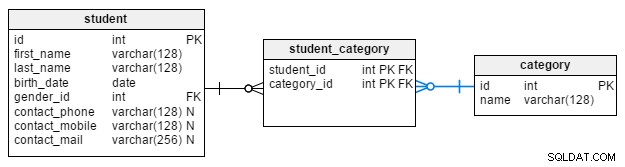
Skoro o tym wspomnieliśmy, przejdźmy dalej i omówmy category tabela tutaj.

Ta tabela jest słownikiem używanym do grupowania uczniów w oparciu o określone kryteria. name atrybut jest jedynymi danymi w tabeli (oprócz id , klucz podstawowy) i jest to obowiązkowe. Jednym z zestawów wartości, które można tu zapisać, jest status zatrudnienia studenta:„student”, „zatrudniony”, „bezrobotny” i „emeryt”. Moglibyśmy również użyć innych zestawów w oparciu o bardzo szczegółowe kryteria, takie jak „lubi jogę”, „lubi wędrówki”, „lubi jeździć na rowerze” i „niczego nie lubi”.
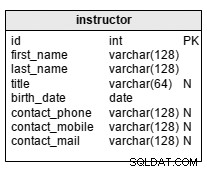
instructor tabela zawiera listę wszystkich instruktorów/wykładowców w organizacji. Atrybuty w tabeli to:
first_name– imię i nazwisko instruktoralast_name– nazwisko instruktoratitle– tytuł instruktora (jeśli jest)birth_date– data urodzenia instruktoracontact_phone– numer telefonu instruktoracontact_mobile– numer telefonu komórkowego instruktoracontact_mail– adres e-mail instruktora
title i wszystkie trzy contact atrybuty nie są obowiązkowe.
student tabela i instructor tabela ma podobną strukturę, ale istnieje inna możliwość uporządkowania tych informacji. Drugim podejściem byłoby posiadanie person tabeli (która przechowuje wszystkie dane pracowników i uczniów) i ma relację wiele-do-wielu, która mówi nam o wszystkich rolach przypisanych do tej osoby. Najważniejszą zaletą drugiego podejścia jest to, że będziemy przechowywać dane tylko raz. Jeśli ktoś jest instruktorem w jednych zajęciach, a uczniem w innych, pojawi się w bazie danych tylko raz, ale ze zdefiniowanymi obydwoma rolami.
Dlaczego wybraliśmy podejście dwutabelowe do naszego modelu edukacyjnej bazy danych? Generalnie studenci i instruktorzy zachowują się inaczej, zarówno w prawdziwym życiu, jak iw naszej bazie danych. Z tego powodu rozsądnie byłoby przechowywać ich dane osobno. Możemy znaleźć inne sposoby scalania dowolnych informacji o tej samej osobie, które pojawiają się w obu tabelach (np. para zapytań wstawiania/aktualizacji na podstawie identyfikatora zewnętrznego, takiego jak numer ubezpieczenia społecznego lub numer VAT).
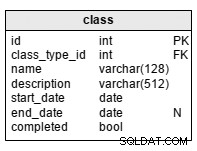
class table to katalog zawierający szczegółowe informacje o wszystkich klasach. Możemy mieć wiele instancji każdego typu klasy. Atrybuty w tabeli są następujące (wszystkie są obowiązkowe z wyjątkiem end_date ):
class_type_id– jest odniesieniem doclass_typesłownik.name– to skrócona nazwa klasy.description– ten opis jest bardziej szczegółowy niż ten wclass_typestół.start_date– data rozpoczęcia zajęć.end_date– data zakończenia zajęć. Nie jest to obowiązkowe, ponieważ nie zawsze możemy z wyprzedzeniem znać dokładną datę zakończenia każdej klasy.completed– to wartość logiczna, która oznacza, że wszystkie zaplanowane zajęcia klasowe zostały zakończone. Jest to przydatne, gdy osiągniemy planowanyend_timedla klasy, ale inne zajęcia klasowe nie zostały jeszcze ukończone.

class_type tabela jest prostym katalogiem, przeznaczonym do przechowywania podstawowych informacji o oferowanych studentom wykładach lub zajęciach. Może zawierać wartości takie jak „Język angielski (grupa)”, „Język polski (grupa)”, „Język chorwacki (grupa)”, „Język angielski (osobiście)” lub „Lekcje tańca”. Ma tylko dwa obowiązkowe atrybuty – name i description , które nie wymagają dalszych wyjaśnień.

class_schedule tabela zawiera konkretne godziny wykładów i zajęć. Wszystkie atrybuty w tabeli są obowiązkowe. class_id atrybut jest odniesieniem do class tabela, podczas gdy start_time i end_time to godziny rozpoczęcia i zakończenia tego konkretnego wykładu.
Kto tu jest? Tabele związane z frekwencją

attend tabela przechowuje informacje o tym, który uczeń uczęszczał na które zajęcia i końcowy wynik. Atrybuty w tabeli to:
student_id– jest odniesieniem dostudentstółclass_id– jest odniesieniem doclassstółclass_enrollment_date– to data, kiedy uczeń zaczął uczęszczać na te zajęciaclass_drop_date– data zakończenia zajęć przez ucznia. Atrybut ten ma wartość tylko wtedy, gdy uczeń opuścił zajęcia przed datą zakończenia zajęć. W takim przypadkudrop_class_reason_idwartość atrybutu również musi być ustawiona.drop_class_reason_id– jest odniesieniem dodrop_class_reasonstółattendance_outcome_id– jest odniesieniem doattendance_outcomestół
Wszystkie dane z wyjątkiem class_drop_date i drop_class_reason_id jest wymagane. Te dwa zostaną wypełnione wtedy i tylko wtedy, gdy uczeń opuści zajęcia.

drop_attendance_reason table to słownik zawierający różne powody, dla których uczeń może zrezygnować z kursu. Ma tylko jeden atrybut, reason_text i jest to obowiązkowe. Przykładowy zestaw wartości może obejmować:„choroba”, „utrata zainteresowania”, „nie ma wystarczająco dużo czasu” i „inne powody”.

attendance_outcome tabela zawiera opisy aktywności studenta na danym kursie. outcome_text jest jedynym atrybutem w tabeli i jest wymagany. Zestaw możliwych wartości to:„w toku”, „ukończono pomyślnie”, „ukończono częściowo” i „nie ukończył zajęć”.
Kto rządzi? Tabele związane z nauczaniem
teach , drop_teach_reason i teach_outcome tabele używają tej samej logiki, co attend , drop_attendance_reason i attendance_outcome tabele. Wszystkie te tabele przechowują dane o działaniach instruktorów związanych z kursami.
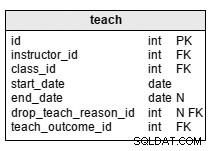
teach tabela służy do przechowywania informacji o tym, który instruktor prowadzi daną klasę. Atrybuty w tabeli to:
instructor_id– jest odniesieniem doinstructorstół.class_id– jest odniesieniem doclassstół.start_date– to data rozpoczęcia pracy przez instruktora na tych zajęciach.end_date– to data, w której instruktor przestał pracować na tych zajęciach. Nie jest to obowiązkowe, ponieważ nie możemy z góry wiedzieć, czy instruktor będzie nauczał do daty zakończenia zajęć.drop_teach_reason_id– jest odniesieniem dodrop_teach_reasonstół. Nie jest to obowiązkowe, ponieważ instruktor nie może porzucić zajęć.teach_outcome_id– jest odniesieniem doteach_outcome_reasonstół.

drop_teach_reason tabela to prosty słownik. Zawiera zestaw możliwych wyjaśnień, dlaczego instruktor zakończył zajęcia przed ich zakończeniem. Jest tylko jeden obowiązkowy atrybut:reason_text . Może to być „choroba”, „przeniesienie do innego projektu/pracy”, „rezygnacja” lub „inny powód”.

teach_outcome tabela opisuje sukces instruktora na danym kursie. outcome_text jest jedynym atrybutem tabeli i jest wymagany. Możliwe wartości dla tej tabeli to:„w toku”, „ukończony pomyślnie”, „ukończony częściowo” i „nie ukończył zajęć dydaktycznych”.

student_presence tabela służy do przechowywania danych o obecności studenta na konkretnym wykładzie. Możemy założyć, że na każdym wykładzie prowadzący odnotuje obecność i/lub nieobecność wszystkich studentów. Atrybuty w tabeli to:
student_id– jest odniesieniem dostudentstółclass_schedule_id– jest odniesieniem doclass_schedulestółpresent– jest boolowskim oznaczeniem, czy student jest obecny na wykładzie, czy nie
Moglibyśmy monitorować obecność uczniów w określonej klasie za pomocą zapytania podobnego do tego, które następuje (zakładając, że @id_class zawiera identyfikator klasy, który chcemy).
SELECT a.id, CONCAT(a.pierwsze_imię, ' ', a.nazwisko) AS student_name, a.liczba_łączna, CONCAT(CONCAT(a.liczba_obecna / a.liczba_łączna * 100, DECIMAL(5,2)), '%') Procent AS, a.attendance_outcomeFROM(SELECT student.id, student.first_name, student.last_name, SUM(CASE WHEN student_presence.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS number_total, audience_outcome.outcome_text AS audience_outcomeFROM klasa INNER JOIN uczestniczyć ON class.id =seek.class_id INNER JOIN student ON uczestniczyć.student_id =student.id LEFT JOIN class_schedule ON class_schedule.class_id =class.id LEFT JOIN student_presence =student_student_presence. .id ORAZ student_presence.class_schedule_id =class_schedule.id DOŁĄCZ PO LEWEJ frekwencji_outcome WŁĄCZONA audience_outcome.id =uczęszczać.attendance_outcome_idWHERE class.id =@id_classGROUP BY student.id, student.first_name, student.last_name, frekwencja_e_outcome)).

Tabela „instructor_presence” wykorzystuje tę samą logikę, co tabela „student_presence”, ale tutaj chcemy skupić się na instruktorach. Atrybuty w tabeli to:
instructor_id– jest odniesieniem doinstructorstółclass_schedule_id– jest odniesieniem doclass_schedulestółpresent– jest wartością logiczną reprezentującą, czy instruktor jest obecny na wykładzie, czy nie
Moglibyśmy użyć poniższego zapytania do monitorowania aktywności instruktora na zajęciach:
SELECT a.id, CONCAT(a.pierwsze_imię, ' ', a.nazwisko) AS nazwa_instruktora, a.liczba_łączna, CONCAT(CONVERT(a.liczba_obecna / a.liczba_łączna * 100, DECIMAL(5,2)), '%') Procent AS, a.teach_outcomeFROM(SELECT instruktor.id, instruktor.pierwsza_nazwa, instruktor.nazwisko, SUM(CASE WHEN instruktor_obecność.present =True THEN 1 ELSE 0 END) AS number_present, COUNT(DISTINCT class_schedule.id) AS number_total, tea_outcome.outcome_text AS learn_outcomeFROM class INNER JOIN uczyć ON class.id =uczyć.class_id INNER JOIN instruktor ON teacher.instructor_id =instruktor.id DOŁĄCZ PO LEWEJ class_schedule ON class_schedule.class_id =class.id DOŁĄCZ PO LEWEJ instruktor_presence. .id ORAZ teacher_presence.class_schedule_id =class_schedule.id DOŁĄCZ PO LEWEJ tea_outcome WŁĄCZONE learn_outcome.id =uczyć.teach_outcome_idWHERE class.id =@id_classGROUP BY instruktor.id, instruktor.pierwsza_nazwa, instruktor.last_nazwa, naucz_outcome.outcome)Teraz zakończmy omawiając tabele osób kontaktowych.
Do kogo możemy zadzwonić? Tabele osób kontaktowych
W większości przypadków nie musimy przechowywać danych kontaktowych w nagłych wypadkach (tj. w nagłych wypadkach skontaktuj się z tą osobą). Jednak to się zmienia, gdy uczymy dzieci. Zgodnie z prawem lub zwyczajem potrzebujemy osoby kontaktowej dla każdego dziecka, którego uczymy. W naszych tabelach modeli –
contact_person,contact_person_typeicontact_person_student– pokazujemy, jak można to zrobić.
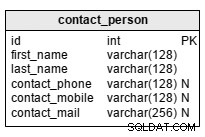
contact_persontabela to lista osób powiązanych ze studentami. Oczywiście nie musimy wymieniać wszystkich krewnych; najczęściej będziemy mieć jeden lub dwa kontakty na ucznia. Jest to dobry sposób na znalezienie „do kogo zadzwonisz”, gdy uczeń potrzebuje lub chce wyjść wcześniej. Atrybuty w tabeli to:
first_name– to imię i nazwisko osoby kontaktowejlast_name– to nazwisko osobycontact_phone– to numer telefonu osobycontact_mobile– to numer telefonu komórkowego osobycontact_mail– to adres e-mail osoby
Dane kontaktowe nie są obowiązkowe, chociaż są bardzo przydatne.
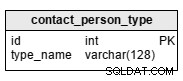
contact_person_type table to słownik z jednym, wymaganym atrybutem:type_name . Przykładami wartości przechowywanych w tej tabeli są:„matka”, „ojciec”, „brat”, „siostra” lub „wujek”.

contact_person_student tabela to relacja wiele-do-wielu, która łączy osoby kontaktowe i ich typ ze studentami. Atrybuty w tabeli to (wszystkie są obowiązkowe):
contact_person_id– jest odniesieniem docontact_personstółstudent_id– jest odniesieniem dostudentstółcontact_person_type_id– jest odniesieniem docontact_person_typestół
Warto wspomnieć, że ta relacja wiele-do-wielu łączy ze sobą trzy tabele. Para atrybutów contact_person_id i student_id jest używany jako klucz alternatywny (UNIKALNY). W ten sposób wyłączymy zduplikowane wpisy, które łączą poszczególnych uczniów z tą samą osobą kontaktową. Atrybut contact_person_type_id nie jest częścią klucza alternatywnego. Jeśli tak, moglibyśmy mieć wiele relacji dla tej samej osoby kontaktowej i tego samego ucznia (używając różnych typów relacji), a to nie ma sensu w sytuacjach z życia codziennego.
Model przedstawiony w tym artykule powinien być w stanie zaspokoić większość typowych potrzeb. Mimo to w niektórych przypadkach można było wykluczyć części modelu, np. prawdopodobnie nie potrzebowalibyśmy całego segmentu osoby kontaktowej, gdyby nasi uczniowie byli dorośli. Jak powiedziałem wcześniej, z czasem dodamy do tego ulepszenia. Zapraszam do dodawania sugestii i dzielenia się swoimi doświadczeniami w sekcjach dyskusji.