Przed podjęciem próby wprowadzenia jakichkolwiek zmian w schemacie w produkcyjnych bazach danych należy upewnić się, że dysponujesz solidnym planem wycofania; oraz że Twoja procedura zmiany została pomyślnie przetestowana i zweryfikowana w oddzielnym środowisku. Jednocześnie Twoim obowiązkiem jest upewnienie się, że zmiana nie spowoduje żadnego lub najmniejszego możliwego wpływu akceptowalnego dla firmy. To zdecydowanie nie jest łatwe zadanie.
W tym artykule przyjrzymy się, jak w kontrolowany sposób przeprowadzać zmiany w bazie danych na MySQL i MariaDB. Porozmawiamy o dobrych nawykach w Twojej codziennej pracy DBA. Skoncentrujemy się na wymaganiach wstępnych i zadaniach podczas rzeczywistych operacji i problemach, które możesz napotkać, gdy masz do czynienia ze zmianami schematu bazy danych. Porozmawiamy również o narzędziach typu open source, które mogą Ci w tym pomóc.
Scenariusze testowania i przywracania
Kopia zapasowa
Istnieje wiele sposobów na utratę danych. Jednym z nich jest niepowodzenie aktualizacji schematu. W przeciwieństwie do kodu aplikacji, nie możesz upuścić pakietu plików i zadeklarować, że nowa wersja została pomyślnie wdrożona. Nie możesz też po prostu przywrócić starszego zestawu plików, aby cofnąć zmiany. Oczywiście możesz uruchomić inny skrypt SQL, aby ponownie zmienić bazę danych, ale zdarzają się przypadki, gdy jedynym dokładnym sposobem cofnięcia zmian jest przywrócenie całej bazy danych z kopii zapasowej.
Co jednak, jeśli nie możesz sobie pozwolić na przywrócenie bazy danych do najnowszej kopii zapasowej lub okres konserwacji nie jest wystarczająco duży (biorąc pod uwagę wydajność systemu), więc nie możesz wykonać pełnej kopii zapasowej bazy danych przed zmianą?
Można mieć wyrafinowane, nadmiarowe środowisko, ale dopóki dane są modyfikowane zarówno w lokalizacji podstawowej, jak i rezerwowej, niewiele można z tym zrobić. Wiele skryptów można uruchomić tylko raz lub zmian nie można cofnąć. Większość kodu zmian SQL dzieli się na dwie grupy:
- Uruchom raz – nie możesz dwukrotnie dodać tej samej kolumny do tabeli.
- Nie można cofnąć — po upuszczeniu tej kolumny znika. Bez wątpienia możesz przywrócić swoją bazę danych, ale to nie jest dokładnie cofnięcie.
Możesz rozwiązać ten problem na co najmniej dwa możliwe sposoby. Jednym z nich byłoby włączenie dziennika binarnego i wykonanie kopii zapasowej, która jest zgodna z PITR. Taka kopia zapasowa musi być pełna, kompletna i spójna. W przypadku xtrabackup, o ile zawiera pełny zestaw danych, będzie on kompatybilny z PITR. W przypadku mysqldump istnieje również możliwość uczynienia go kompatybilnym z PITR. W przypadku mniejszych zmian, odmiana kopii zapasowej mysqldump polegałaby na zmianie tylko podzbioru danych. Można to zrobić za pomocą opcji --where. Kopia zapasowa powinna być częścią planowanej konserwacji.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlInną możliwością jest użycie CREATE TABLE AS SELECT.
Możesz przechowywać dane lub proste zmiany struktury w postaci stałej tabeli tymczasowej. Dzięki takiemu podejściu otrzymasz źródło, jeśli musisz wycofać zmiany. Może to być bardzo przydatne, jeśli nie zmieniasz zbyt wielu danych. Wycofanie można wykonać, wyciągając z niego dane. Jeśli wystąpią jakiekolwiek błędy podczas kopiowania danych do tabeli, zostaną one automatycznie odrzucone i nie zostaną utworzone, więc upewnij się, że Twoja instrukcja tworzy kopię, której potrzebujesz.
Oczywiście są też pewne ograniczenia.
Ponieważ nie zawsze można określić kolejność wierszy w bazowych instrukcjach SELECT, CREATE TABLE ... IGNORE SELECT i CREATE TABLE ... REPLACE SELECT są oznaczone jako niebezpieczne dla replikacji opartej na instrukcjach. Takie instrukcje generują ostrzeżenie w dzienniku błędów podczas korzystania z trybu opartego na instrukcjach i są zapisywane w dzienniku binarnym przy użyciu formatu opartego na wierszach, gdy używany jest tryb MIXED.
Bardzo prostym przykładem takiej metody może być:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Inną ciekawą opcją może być baza flashbacków MariaDB. Gdy zdarzy się niewłaściwa aktualizacja lub usunięcie i chcesz powrócić do stanu bazy danych (lub tylko tabeli) w określonym momencie, możesz użyć funkcji retrospekcji.
Wycofanie do określonego momentu umożliwia administratorom baz danych szybsze odzyskiwanie danych poprzez wycofywanie transakcji do poprzedniego punktu w czasie, zamiast wykonywania przywracania z kopii zapasowej. Na podstawie zdarzeń DML opartych na ROW, flashback może przekształcić dziennik binarny i odwrócić cele. Oznacza to, że może pomóc szybko cofnąć wprowadzone zmiany w wierszach. Na przykład może zmienić zdarzenia DELETE na INSERT i odwrotnie, a także zamienić części WHERE i SET zdarzeń UPDATE. Ten prosty pomysł może znacznie przyspieszyć odzyskiwanie z niektórych rodzajów błędów lub katastrof. Dla tych, którzy znają bazę danych Oracle, jest to dobrze znana funkcja. Ograniczeniem flashbacku MariaDB jest brak obsługi DDL.
Utwórz opóźnioną replikację podrzędną
Od wersji 5.6 MySQL obsługuje opóźnioną replikację. Serwer podrzędny może pozostawać w tyle za serwerem głównym przynajmniej o określoną ilość czasu. Domyślne opóźnienie to 0 sekund. Użyj opcji MASTER_DELAY opcji CHANGE MASTER TO, aby ustawić opóźnienie na N sekund:
CHANGE MASTER TO MASTER_DELAY = N;Byłaby to dobra opcja, gdybyś nie miał czasu na przygotowanie odpowiedniego scenariusza odzyskiwania. Musisz mieć wystarczająco dużo opóźnienia, aby zauważyć problematyczną zmianę. Zaletą tego podejścia jest to, że nie trzeba przywracać bazy danych, aby usunąć dane potrzebne do naprawy zmiany. Gotowa baza danych jest uruchomiona i gotowa do pobierania danych, co minimalizuje potrzebny czas.
Utwórz asynchroniczne urządzenie podrzędne, które nie jest częścią klastra
W przypadku klastra Galera testowanie zmian nie jest łatwe. Wszystkie węzły obsługują te same dane, a duże obciążenie może zaszkodzić kontroli przepływu. Musisz więc nie tylko sprawdzić, czy zmiany zostały pomyślnie zastosowane, ale także jaki był wpływ na stan klastra. Aby procedura testowa była jak najbardziej zbliżona do obciążenia produkcyjnego, możesz dodać asynchroniczne urządzenie podrzędne do klastra i tam uruchomić test. Test nie wpłynie na synchronizację między węzłami klastra, ponieważ technicznie nie jest on częścią klastra, ale będziesz miał możliwość sprawdzenia go z rzeczywistymi danymi. Takie urządzenie podrzędne można łatwo dodać z ClusterControl.
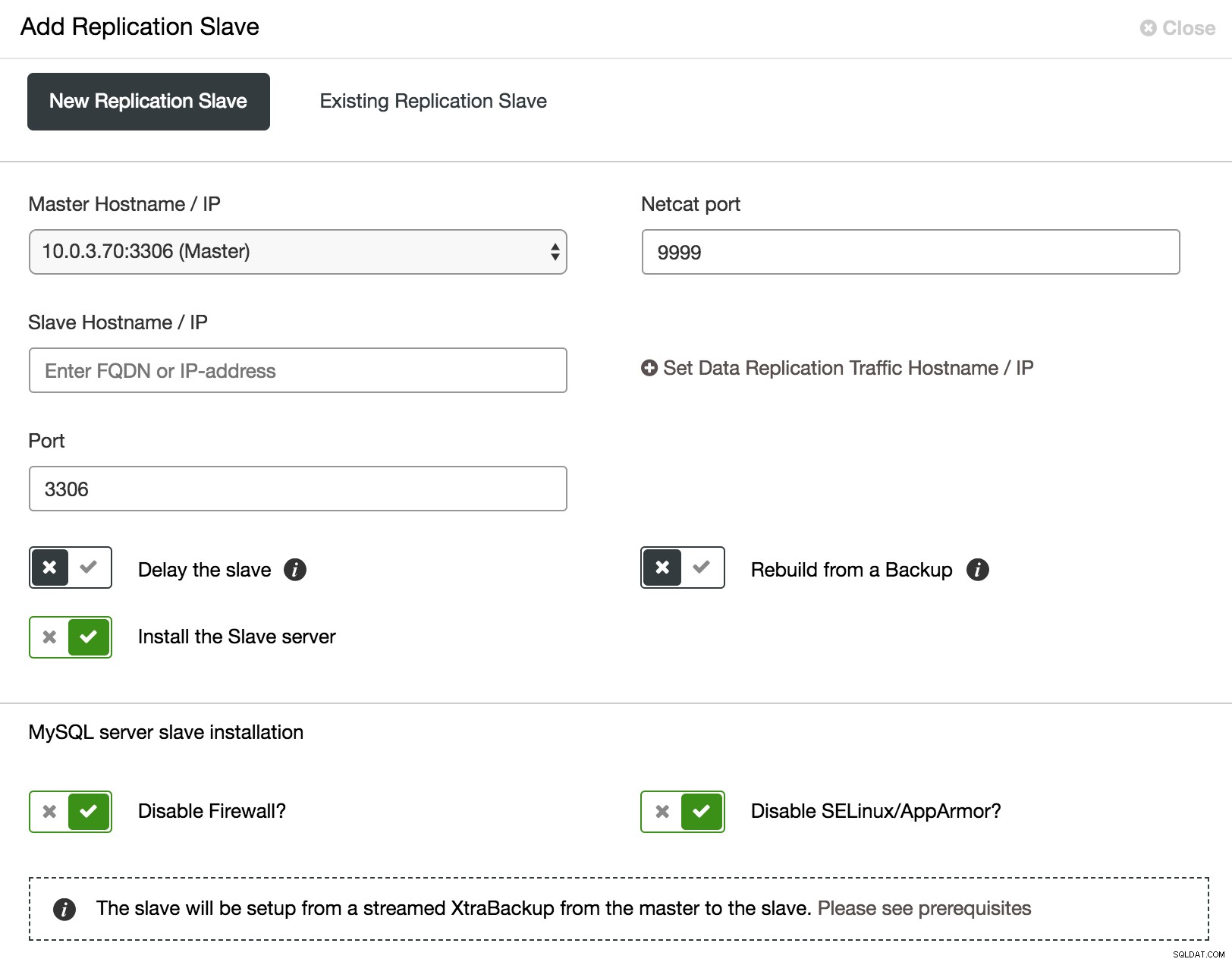 ClusterControl dodaje asynchroniczne urządzenie podrzędne
ClusterControl dodaje asynchroniczne urządzenie podrzędne Jak pokazano na powyższym zrzucie ekranu, ClusterControl może na kilka sposobów zautomatyzować proces dodawania asynchronicznego urządzenia podrzędnego. Możesz dodać węzeł do klastra, opóźnić niewolnika. Aby zmniejszyć wpływ na mastera, możesz użyć istniejącej kopii zapasowej zamiast mastera jako źródła danych podczas budowania slave.
Klonuj bazę danych i mierz czas
Dobry test powinien być jak najbliżej zmiany produkcyjnej. Najlepszym sposobem na to jest sklonowanie istniejącego środowiska.
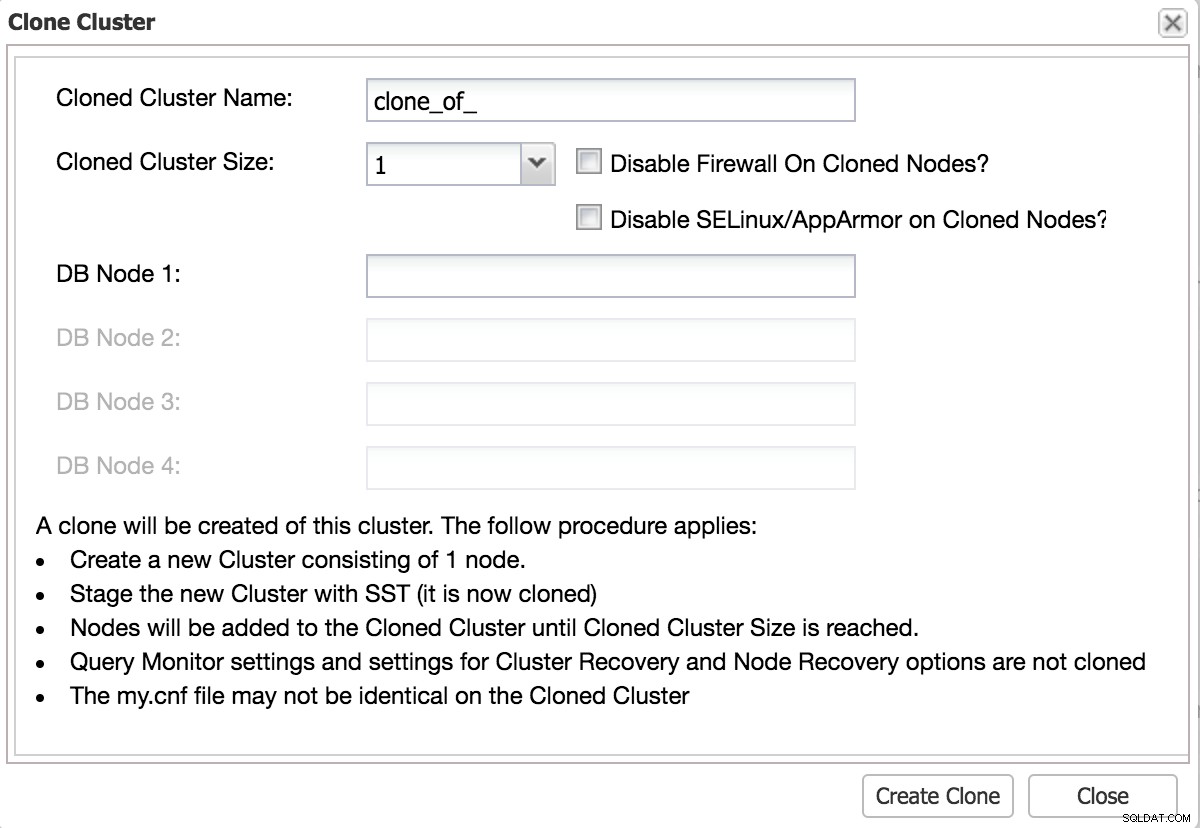 ClusterControl Clone Cluster do testu
ClusterControl Clone Cluster do testu Wykonywanie zmian przez replikację
Aby mieć lepszą kontrolę nad zmianami, możesz zastosować je wcześniej na serwerze podrzędnym, a następnie dokonać przełączenia. W przypadku replikacji opartej na instrukcjach działa to dobrze, ale w przypadku replikacji opartej na wierszach może to działać do pewnego stopnia. Replikacja oparta na wierszach umożliwia istnienie dodatkowych kolumn na końcu tabeli, więc dopóki może zapisać pierwsze kolumny, wszystko będzie dobrze. Najpierw zastosuj te ustawienia do wszystkich urządzeń podrzędnych, a następnie przełącz się do jednego z podrzędnych, a następnie zaimplementuj zmianę w urządzeniu głównym i dołącz go jako podrzędny. Jeśli modyfikacja obejmuje wstawienie lub usunięcie kolumny w środku tabeli, będzie działać z replikacją opartą na wierszach.
Operacja
Podczas okna konserwacji nie chcemy mieć ruchu aplikacji w bazie danych. Czasami trudno jest wyłączyć wszystkie aplikacje rozsiane po całej firmie. Alternatywnie, chcemy zezwolić tylko określonym hostom na zdalny dostęp do MySQL (na przykład system monitorowania lub serwer kopii zapasowych). W tym celu możemy wykorzystać filtrowanie pakietów w Linuksie. Aby zobaczyć, jakie reguły filtrowania pakietów są dostępne, możemy uruchomić następujące polecenie:
iptables -L INPUT -vAby zamknąć port MySQL na wszystkich używanych przez nas interfejsach:
iptables -A INPUT -p tcp --dport mysql -j DROPi aby ponownie otworzyć port MySQL po okresie konserwacji:
iptables -D INPUT -p tcp --dport mysql -j DROPDla tych, którzy nie mają dostępu do roota, możesz zmienić max_connection na 1 lub „pomiń sieć”.
Logowanie
Aby rozpocząć proces logowania, użyj polecenia tee w wierszu poleceń klienta MySQL, w następujący sposób:
mysql> tee /tmp/my.out;To polecenie mówi MySQL, aby rejestrował zarówno dane wejściowe, jak i wyjściowe bieżącej sesji logowania MySQL do pliku o nazwie /tmp/my.out . Następnie uruchom plik skryptu za pomocą polecenia źródłowego.
Aby uzyskać lepszy obraz czasu wykonania, możesz połączyć go z funkcją profilera. Uruchom profiler za pomocą
SET profiling = 1;Następnie wykonaj zapytanie za pomocą
SHOW PROFILES;zobaczysz listę zapytań, dla których profiler ma statystyki. Na koniec wybierasz zapytanie do zbadania za pomocą
SHOW PROFILE FOR QUERY 1;Narzędzia do migracji schematów
W wielu przypadkach proste ALTER na masterze nie jest możliwe - w większości przypadków powoduje to opóźnienie na slave, co może być nie do zaakceptowania przez aplikacje. Można jednak dokonać zmiany w trybie kroczącym. Możesz zacząć od urządzeń podrzędnych, a gdy zmiana zostanie zastosowana do urządzenia podrzędnego, przenieść jeden z podrzędnych jako nowy nadrzędny, zdegradować starego nadrzędnego do podrzędnego i wykonać na nim zmianę.
Narzędziem, które może pomóc w takim zadaniu jest pt-online-schema-change firmy Percona. Pt-online-schema-change jest proste - tworzy tymczasową tabelę z pożądanym nowym schematem (na przykład, jeśli dodaliśmy indeks lub usunęliśmy kolumnę z tabeli). Następnie tworzy wyzwalacze na starej tabeli. Te wyzwalacze są po to, aby odzwierciedlać zmiany zachodzące w oryginalnej tabeli w nowej tabeli. Zmiany są odzwierciedlane podczas procesu zmiany schematu. Jeśli wiersz zostanie dodany do oryginalnej tabeli, zostanie również dodany do nowej. Emuluje sposób, w jaki MySQL zmienia wewnętrznie tabele, ale działa na kopii tabeli, którą chcesz zmienić. Oznacza to, że oryginalna tabela nie jest zablokowana, a klienci mogą nadal czytać i zmieniać w niej dane.
Podobnie, jeśli wiersz zostanie zmodyfikowany lub usunięty w starej tabeli, zostanie również zastosowany w nowej tabeli. Następnie rozpoczyna się proces kopiowania danych w tle (przy użyciu LOW_PRIORITY INSERT) między starą a nową tabelą. Po skopiowaniu danych wykonywana jest RENAME TABLE.
Innym ciekawym narzędziem jest gh-ost. Gh-ost tworzy tymczasową tabelę ze zmienionym schematem, tak jak robi to pt-online-schema-change. Wykonuje zapytania INSERT, które używają następującego wzorca do kopiowania danych ze starej do nowej tabeli. Niemniej jednak nie używa wyzwalaczy. Niestety wyzwalacze mogą być źródłem wielu ograniczeń. gh-ost używa strumienia dziennika binarnego do przechwytywania zmian w tabeli i asynchronicznie stosuje je do tabeli duchów. Po sprawdzeniu, czy gh-ost może poprawnie wykonać zmianę naszego schematu, nadszedł czas, aby ją faktycznie wykonać. Pamiętaj, że może być konieczne ręczne usunięcie starych tabel, które zostały utworzone przez gh-ost podczas procesu testowania migracji. Możesz także użyć flag --initially-drop-ghost-table i --initially-drop-old-table, aby poprosić gh-osta o zrobienie tego za Ciebie. Ostatnie polecenie do wykonania jest dokładnie takie samo, jak przy testowaniu naszej zmiany, właśnie dodaliśmy do niego --execute.
pt-online-schema-change i gh-ost są bardzo popularne wśród użytkowników Galera. Niemniej jednak Galera ma kilka dodatkowych opcji. Dwie metody Total Order Isolation (TOI) i Rolling Schema Upgrade (RSU) mają swoje zalety i wady.
TOI — Jest to domyślna metoda replikacji DDL. Węzeł, z którego pochodzi zbiór zapisów, wykrywa kod DDL w czasie analizowania i wysyła zdarzenie replikacji instrukcji SQL jeszcze przed rozpoczęciem przetwarzania DDL. Uaktualnienia schematu są uruchamiane we wszystkich węzłach klastra w tej samej kolejności całkowitej, co zapobiega zatwierdzaniu innych transakcji na czas trwania operacji. Ta metoda jest dobra, gdy chcesz, aby uaktualnienia schematu online były replikowane przez klaster i nie masz nic przeciwko blokowaniu całej tabeli (podobnie jak w przypadku domyślnych zmian schematu w MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU — wykonaj uaktualnienia schematu lokalnie. W tej metodzie twoje zapisy wpływają tylko na węzeł, na którym są uruchamiane. Zmiany nie są replikowane w pozostałej części klastra. Ta metoda jest dobra dla operacji bez konfliktów i nie spowalnia klastra.
SET GLOBAL wsrep_OSU_method='RSU';Podczas gdy węzeł przetwarza uaktualnienie schematu, następuje desynchronizacja z klastrem. Po zakończeniu przetwarzania uaktualnienia schematu stosuje zdarzenia opóźnionej replikacji i synchronizuje się z klastrem. To może być dobra opcja do uruchamiania rozbudowanych kreacji indeksowych.
Wniosek
Przedstawiliśmy tutaj kilka różnych metod, które mogą pomóc w planowaniu zmian w schemacie. Oczywiście wszystko zależy od aplikacji i wymagań biznesowych. Możesz zaprojektować swój plan zmian, wykonać niezbędne testy, ale wciąż jest niewielka szansa, że coś pójdzie nie tak. Zgodnie z prawem Murphy’ego „w każdej sytuacji wszystko pójdzie nie tak, jeśli dasz im szansę”. Dlatego wypróbuj różne sposoby wprowadzania tych zmian i wybierz ten, który Ci odpowiada.