Czasami widzę, jak ludzie próbują „zoptymalizować” swoje instrukcje aktualizacji, aby uniknąć zapisywania tej samej wartości w określonej kolumnie. Zawsze rozumiem, że jeśli zamierzasz zaktualizować wiersz, zakładając, że wszystkie wartości są w wierszu, koszty zablokowania wiersza są znacznie wyższe niż przyrostowy koszt aktualizacji jednej, dwóch lub wszystkich kolumn w tym wierszu .
Stworzyłem więc prostą tabelę, aby to przetestować:
CREATE TABLE dbo.whatever ( ID INT IDENTITY(1,1) PRIMARY KEY, v1 NVARCHAR(50) NOT NULL, v2 NVARCHAR(50) NOT NULL, v3 NVARCHAR(50) NOT NULL, v4 NVARCHAR(50) NOT NULL, v5 NVARCHAR(50) NOT NULL, v6 NVARCHAR(50) NOT NULL );
Następnie stworzyłem procedurę składowaną, aby wypełnić tabelę 50 000 wierszy różnymi małymi ciągami:
CREATE PROCEDURE dbo.clean
AS
BEGIN
SET NOCOUNT ON;
TRUNCATE TABLE dbo.whatever;
;WITH x(d) AS
(
SELECT d FROM
(
VALUES (N'abc'),(N'def'),(N'ghi'),
(N'jkl'),(N'mno'),(N'pqr')
) AS y(d)
)
INSERT dbo.whatever(v1, v2, v3, v4, v5, v6)
SELECT TOP (50000) x1.d, x2.d, x3.d, x4.d, x5.d, x6.d
FROM x AS x1, x AS x2, x AS x3, x AS x4,
x AS x5, x AS x6, x AS x7;
END
GO Następnie napisałem instrukcje aktualizacji sformułowane na dwa sposoby, dzięki którym można „unikać” pisania do określonej kolumny, biorąc pod uwagę to przypisanie zmiennej:
DECLARE @v1 NVARCHAR(50) = N'abc', @v2 NVARCHAR(50) = N'def', @v3 NVARCHAR(50) = N'ghi', @v4 NVARCHAR(50) = N'jkl', @v5 NVARCHAR(50) = N'mno', @v6 NVARCHAR(50) = N'pqr';
Najpierw za pomocą wyrażenia CASE, aby sprawdzić, czy wartość w kolumnie jest taka sama jak wartość w zmiennej:
UPDATE dbo.whatever SET
v1 = CASE WHEN v1 <> @v1 THEN @v1 ELSE v1 END,
v2 = CASE WHEN v2 <> @v2 THEN @v2 ELSE v2 END,
v3 = CASE WHEN v3 <> @v3 THEN @v3 ELSE v3 END,
v4 = CASE WHEN v4 <> @v4 THEN @v4 ELSE v4 END,
v5 = CASE WHEN v5 <> @v5 THEN @v5 ELSE v5 END,
v6 = CASE WHEN v6 <> @v6 THEN @v6 ELSE v6 END
WHERE
(
v1 <> @v1 OR v2 <> @v2 OR v3 <> @v3
OR v4 <> @v4 OR v5 <> @v5 OR v6 <> @v6
); A po drugie, wydając niezależną aktualizację dla każdej kolumny (każda jest kierowana tylko na wiersze, w których ta wartość w rzeczywistości uległa zmianie):
UPDATE dbo.whatever SET v1 = @v1 WHERE v1 <> @v1; UPDATE dbo.whatever SET v2 = @v2 WHERE v2 <> @v2; UPDATE dbo.whatever SET v3 = @v3 WHERE v3 <> @v3; UPDATE dbo.whatever SET v4 = @v4 WHERE v4 <> @v4; UPDATE dbo.whatever SET v5 = @v5 WHERE v5 <> @v5; UPDATE dbo.whatever SET v6 = @v6 WHERE v6 <> @v6;
Następnie porównałbym to ze sposobem, w jaki większość z nas robiłaby to dzisiaj:po prostu Zaktualizuj wszystkie kolumny, nie przejmując się, czy była to wcześniejsza wartość dla tej konkretnej kolumny:
UPDATE dbo.whatever SET
v1 = @v1, v2 = @v2, v3 = @v3,
v4 = @v4, v5 = @v5, v6 = @v6
WHERE
(
v1 <> @v1 OR v2 <> @v2 OR v3 <> @v3
OR v4 <> @v4 OR v5 <> @v5 OR v6 <> @v6
); (Wszystko to zakłada, że kolumny i parametry/zmienne nie podlegają wartości NULL – w takim przypadku musiałyby użyć funkcji COALESCE, aby uwzględnić porównywanie wartości NULL po obu stronach. Zakładają również, że będziesz mieć dodatkową klauzulę WHERE do celuj w określone wiersze – w tym przykładzie możesz uruchomić pierwsze i trzecie zapytanie bez całej klauzuli WHERE i zobaczyć prawie identyczne wyniki. Zachowałem to dla zwięzłości.)
Następnie chciałem zobaczyć, co dzieje się w tych trzech przypadkach, kiedy można zmienić dowolną wartość, kiedy poszczególne wartości mogą zostać zmienione, kiedy żadne wartości nie zostaną zmienione i kiedy wszystkie wartości zostaną zmienione. Mogłem na to wpłynąć, zmieniając procedurę składowaną, aby wstawić stałe do określonych kolumn lub zmieniając sposób przypisywania zmiennych.
-- to show when any value might change in a row, the procedure uses the full cross join: SELECT TOP (50000) x1.d, x2.d, x3.d, x4.d, x5.d, x6.d -- to show when particular values will change on many rows, we can hard-code constants: -- two values exempt: SELECT TOP (50000) N'abc', N'def', x3.d, x4.d, x5.d, x6.d -- four values exempt: SELECT TOP (50000) N'abc', N'def', N'ghi', N'jkl', x5.d, x6.d -- to show when no values will change, we hard-code all six values: SELECT TOP (50000) N'abc', N'def', N'ghi', N'jkl', N'mno', N'pqr' -- and to show when all values will change, a different variable assignment would take place: DECLARE @v1 NVARCHAR(50) = N'zzz', @v2 NVARCHAR(50) = N'zzz', @v3 NVARCHAR(50) = N'zzz', @v4 NVARCHAR(50) = N'zzz', @v5 NVARCHAR(50) = N'zzz', @v6 NVARCHAR(50) = N'zzz';
Wyniki
Po przeprowadzeniu tych testów „ślepa aktualizacja” wygrała w każdym scenariuszu. Teraz myślisz, co to jest kilkaset milisekund? Ekstrapolować. Jeśli wykonujesz wiele aktualizacji w swoim systemie, może to naprawdę zacząć zbierać straty.
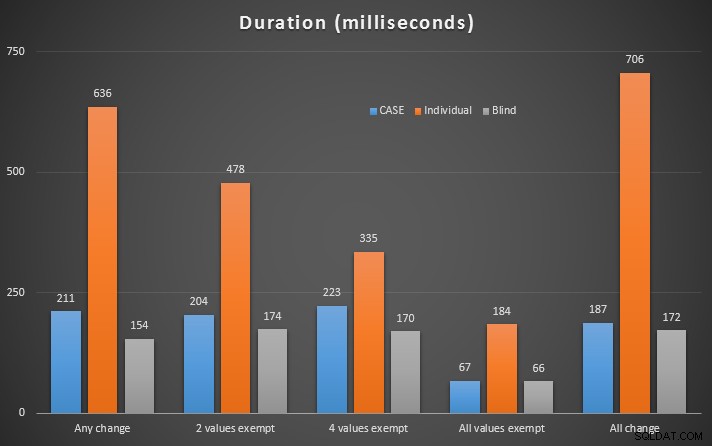
Szczegółowe wyniki w Eksploratorze planów:Dowolna zmiana | 2 wartości wyłączone | 4 wartości zwolnione | Wszystkie wartości zwolnione | Wszystkie zmiany
Na podstawie opinii Roji zdecydowałem się przetestować to również z kilkoma indeksami:
CREATE INDEX x1 ON dbo.whatever(v1); CREATE INDEX x2 ON dbo.whatever(v2); CREATE INDEX x3 ON dbo.whatever(v3) INCLUDE(v4,v5,v6);
Dzięki tym indeksom czas trwania został znacznie wydłużony:
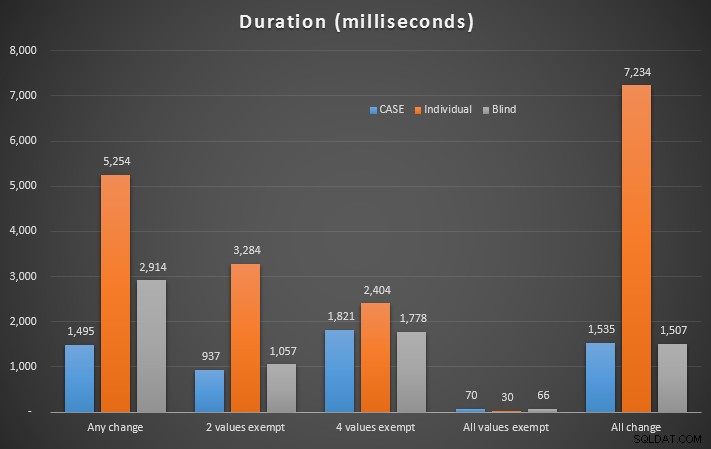
Szczegółowe wyniki w Eksploratorze planów:Dowolna zmiana | 2 wartości wyłączone | 4 wartości zwolnione | Wszystkie wartości zwolnione | Wszystkie zmiany
Wniosek
Z tego testu wydaje mi się, że zwykle nie warto sprawdzać, czy wartość powinna być aktualizowana. Jeśli instrukcja UPDATE dotyczy wielu kolumn, prawie zawsze taniej jest przeskanować wszystkie kolumny, w których jakakolwiek wartość mogła ulec zmianie, niż sprawdzać każdą kolumnę osobno. W przyszłym poście zbadam, czy ten scenariusz jest równoległy dla kolumn LOB.