Niedawno uruchomiliśmy nową witrynę pomocy technicznej, na której można zadawać pytania, przesyłać opinie o produktach lub prośby o nowe funkcje lub otwierać zgłoszenia do pomocy technicznej. Częścią tego celu było scentralizowanie wszystkich miejsc, w których udzielaliśmy pomocy społeczności. Obejmowało to witrynę Q&A SQLPerformance.com, w której Paul White, Hugo Kornelis i wielu innych pomagało w rozwiązywaniu najbardziej skomplikowanych pytań dotyczących dostrajania zapytań i planów wykonania, aż do lutego 2013 r. Mówię z mieszanymi uczuciami, że Witryna pytań i odpowiedzi została zamknięta.
Jest jednak plus. Te trudne pytania możesz teraz zadawać na nowym forum pomocy. Jeśli szukasz starej zawartości, cóż, nadal tam jest, ale wygląda trochę inaczej. Z różnych powodów, o których dzisiaj nie będę mówić, gdy zdecydowaliśmy się wyłączyć oryginalną witrynę z pytaniami i odpowiedziami, ostatecznie zdecydowaliśmy się po prostu hostować całą istniejącą zawartość na witrynie WordPress tylko do odczytu, zamiast przenosić ją na zaplecze nowej witryny.
Ten post nie dotyczy powodów tej decyzji.
Czułem się naprawdę źle z powodu tego, jak szybko witryna z odpowiedziami musiała przejść w tryb offline, zmienić DNS i przenieść zawartość. Ponieważ na stronie został zaimplementowany baner ostrzegawczy, ale AnswerHub tak naprawdę go nie uwidocznił, był to szok dla wielu użytkowników. Chciałem więc mieć pewność, że właściwie zachowałem jak najwięcej treści i chciałem, żeby było w porządku. Ten post jest tutaj, ponieważ pomyślałem, że byłoby ciekawie opowiedzieć o samym procesie, o tym, ile różnych elementów technologii było zaangażowanych w jego wykonanie, i pochwalić się rezultatem. Nie oczekuję, że ktokolwiek z was skorzysta z tego kompleksowego rozwiązania, ponieważ jest to stosunkowo niejasna ścieżka migracji, ale bardziej jako przykład powiązania kilku technologii w celu wykonania zadania. Służy również jako dobre przypomnienie dla mnie, że wiele rzeczy nie kończy się tak łatwo, jak się wydaje, zanim zaczniesz.
TL;DR jest to:poświęciłem sporo czasu i wysiłku, aby zarchiwizowana zawartość wyglądała dobrze, chociaż wciąż próbuję odzyskać kilka ostatnich postów, które pojawiły się pod koniec. Użyłem tych technologii:
- Perla
- Serwer SQL
- PowerShell
- Transmisja (FTP)
- HTML
- CSS
- C#
- PrzecenySharp
- phpMyAdmin
- MySQL
Stąd tytuł. Jeśli chcesz dużo krwawych szczegółów, oto one. Jeśli masz jakieś pytania lub uwagi, skontaktuj się lub skomentuj poniżej.
AnswerHub dostarczył plik zrzutu o wielkości 665 MB z bazy danych MySQL, która zawierała treść pytań i odpowiedzi. Każdy edytor, którego próbowałem, dławił się tym, więc najpierw musiałem podzielić go na plik na tabelę za pomocą tego poręcznego skryptu Perla od Jareda Cheneya. Tabele, których potrzebowałem, nazywały się network11_nodes (pytania, odpowiedzi i komentarze), network11_authoritables (użytkownicy) i network11_managed_files (wszystkie załączniki, w tym przesyłanie planu):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Teraz te nie były zbyt szybkie do załadowania w SSMS, ale przynajmniej tam mogłem użyć Ctrl +H aby zmienić (na przykład) to:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Do tego:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Następnie mogłem załadować dane do SQL Server, aby móc nimi manipulować. I uwierz mi, manipulowałem tym.
Następnie musiałem odzyskać wszystkie załączniki. Widzisz, plik zrzutu MySQL, który otrzymałem od dostawcy, zawierał gazillion INSERT oświadczenia, ale żaden z rzeczywistych plików planów przesłanych przez użytkowników — baza danych zawierała tylko względne ścieżki do plików. Użyłem T-SQL do zbudowania serii poleceń PowerShell, które wywołałyby Invoke-WebRequest pobrać wszystkie pliki i przechowywać je lokalnie (wiele sposobów na skórowanie tego kota, ale to było łatwe). Z tego:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
To dało ten zestaw poleceń (wraz z poleceniem wstępnym, aby rozwiązać ten problem z TLS); wszystko przebiegało dość szybko, ale nie polecam tego podejścia dla jakiejkolwiek kombinacji {ogromnego zestawu plików} i/lub {małej przepustowości}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Spowodowało to pobranie prawie wszystkich załączników, ale trzeba przyznać, że niektóre zostały pominięte z powodu błędów w starej witrynie, kiedy były początkowo przesyłane. Tak więc w nowej witrynie od czasu do czasu możesz zobaczyć odniesienie do załącznika, który nie istnieje.
Następnie użyłem Panic Transmit 5, aby przesłać plik temp do nowej witryny, a teraz, gdy zawartość zostanie przesłana, linki do /s/temp/1-proc.pesession będzie nadal działać.
Następnie przeszedłem na SSL. Aby zażądać certyfikatu w nowej witrynie WordPress, musieliśmy zaktualizować DNS dla answer.sqlperformance.com, aby wskazywał CNAME na naszym hoście WordPress, WPEngine. To było trochę jak kura i jajko — musieliśmy cierpieć z powodu przestojów w przypadku adresów URL https, które nie powiodły się w przypadku braku certyfikatu w nowej witrynie. To było w porządku, ponieważ certyfikat na starej witrynie wygasł, więc naprawdę nie byliśmy w gorszej sytuacji. Musiałem też z tym poczekać, dopóki nie ściągnę wszystkich plików ze starej witryny, ponieważ po przewróceniu DNS nie będzie sposobu, aby się do nich dostać, chyba że przez tylne drzwi.
Czekając na propagację DNS, zacząłem pracować nad logiką, aby wszystkie pytania, odpowiedzi i komentarze przełożyć na coś, co można wykorzystać w WordPressie. Nie tylko schematy tabel różniły się od WordPressa, ale także typy encji są zupełnie inne. Moją wizją było połączenie każdego pytania — oraz wszelkich odpowiedzi i/lub komentarzy — w jeden post.
Trudne jest to, że tabela węzłów zawiera po prostu wszystkie trzy typy zawartości w tej samej tabeli, z odniesieniami nadrzędnymi i oryginalnymi („głównymi”) rodzicami. Ich kod front-endowy prawdopodobnie używa pewnego rodzaju kursora do przechodzenia i wyświetlania zawartości w porządku hierarchicznym i chronologicznym. Nie miałbym tego luksusu w WordPressie, więc musiałem połączyć kod HTML jednym strzałem. Jako przykład, oto jak wyglądały dane:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Nie mogłem uporządkować według identyfikatora, typu lub rodzica, ponieważ czasami komentarz pojawiał się później przy wcześniejszej odpowiedzi, pierwsza odpowiedź nie zawsze była odpowiedzią zaakceptowaną i tak dalej. Chciałem to wyjście (gdzie ++ reprezentuje jeden poziom wcięcia):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Zacząłem pisać rekurencyjne CTE i
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Wyniki:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Geniusz. Sprawdziłem na miejscu kilkanaście innych i cieszyłem się, że przechodzę do następnego kroku. Podziękowałem Andy'emu obficie, kilka razy, ale powtórzę:Dzięki Andy!
Teraz, gdy mogłem zwrócić cały zestaw w kolejności, w jakiej mi się podobało, musiałem wykonać pewną manipulację danymi wyjściowymi, aby zastosować elementy HTML i nazwy klas, które pozwoliłyby mi w znaczący sposób oznaczyć pytania, odpowiedzi, komentarze i wcięcia. Ostatecznym celem były dane wyjściowe, które wyglądały tak (i pamiętaj, że jest to jeden z prostszych przypadków):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Nie będę przechodził przez absurdalną liczbę iteracji, przez które musiałem przejść, aby wylądować na wiarygodnej formie tego wyniku dla wszystkich ponad 5000 pozycji (co przełożyło się na prawie 1000 postów, gdy wszystko zostało sklejone). Ponadto musiałem wygenerować je w postaci WSTAW oświadczenia, które mogłem następnie wkleić do phpMyAdmin na stronie WordPress, co oznaczało trzymanie się ich dziwacznego diagramu składni. Oświadczenia te musiały zawierać inne dodatkowe informacje wymagane przez WordPress, ale nie obecne lub niedokładne w danych źródłowych (takie jak post_type ). A ta konsola administracyjna przedawniłaby się, biorąc pod uwagę zbyt dużo danych, więc musiałem podzielić ją na ~750 wstawek na raz. Oto procedura, z którą się skończyłem (tak naprawdę nie jest to nauka niczego konkretnego, tylko demonstracja, jak bardzo konieczna była manipulacja importowanymi danymi):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Dane wyjściowe nie są jeszcze kompletne i nie są jeszcze gotowe do wprowadzenia do WordPressa:
 Przykładowe dane wyjściowe (kliknij, aby powiększyć)
Przykładowe dane wyjściowe (kliknij, aby powiększyć)
Potrzebowałbym dodatkowej pomocy od C#, aby przekształcić rzeczywistą zawartość (w tym markdown) w HTML i CSS, które mógłbym lepiej kontrolować, i napisać dane wyjściowe (kilka INSERT oświadczenia, które zawierały garść kodu HTML) do plików na dysku, które mogłem otworzyć i wkleić do phpMyAdmin. W przypadku kodu HTML zwykły tekst + znaczniki, które zaczynały się tak:
WYBIERZ coś z dbo.sometable;
[1]:https://w innym miejscu
Musiałbym stać się tym:
Jest wpis na blogu , który o tym mówi, a także ten post .
WYBIERZ coś z dbo.sometable; Aby to osiągnąć, skorzystałem z MarkdownSharp, biblioteki open source pochodzącej ze Stack Overflow, która obsługuje większość konwersji markdown-to-HTML. To było dobrze dopasowane do moich potrzeb, ale nie idealne; Musiałbym jeszcze wykonać dalszą manipulację:
- MarkdownSharp nie zezwala na takie rzeczy jak
target=_blank, więc musiałbym sam je wstrzykiwać po przetworzeniu; - kod (wszystko poprzedzone czterema spacjami) dziedziczy opakowania
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Tak, to brzydka wiązka kodu, ale w końcu doprowadziło mnie do zestawu danych wyjściowych, które nie sprawiłyby, że phpMyAdmin wymiotował, a WordPress ładnie się prezentował (wystarczy). Po prostu wywołałem program C# wiele razy z różnymi zakresami parametrów:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Następnie otworzyłem każdy z plików, wkleiłem je do phpMyAdmin i wcisnąłem GO:
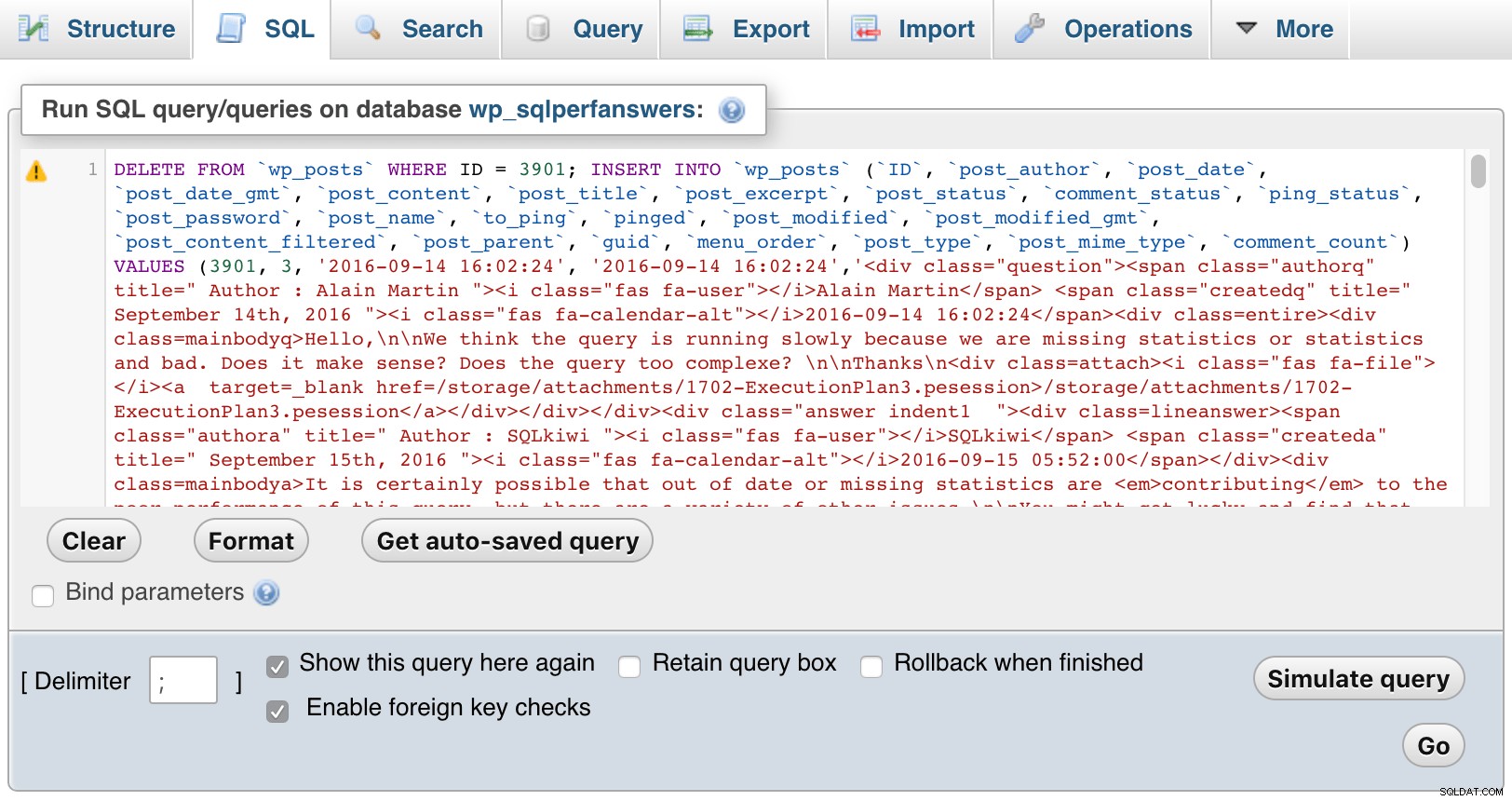 phpMyAdmin (kliknij, aby powiększyć)
phpMyAdmin (kliknij, aby powiększyć) Oczywiście musiałem dodać trochę CSS do WordPressa, aby pomóc rozróżniać pytania, komentarze i odpowiedzi, a także wcinać komentarze, aby wyświetlać odpowiedzi zarówno na pytania, jak i odpowiedzi, zagnieżdżać komentarze odpowiadające na komentarze i tak dalej. Oto jak wygląda fragment po przeanalizowaniu pytań z miesiąca:
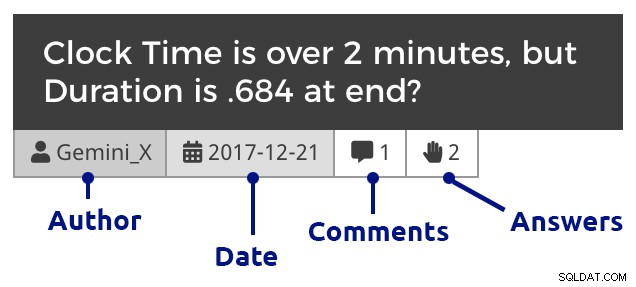 Kafelek pytania (kliknij, aby powiększyć)
Kafelek pytania (kliknij, aby powiększyć) A potem przykładowy post, pokazujący osadzone obrazy, wiele załączników, zagnieżdżone komentarze i odpowiedź:
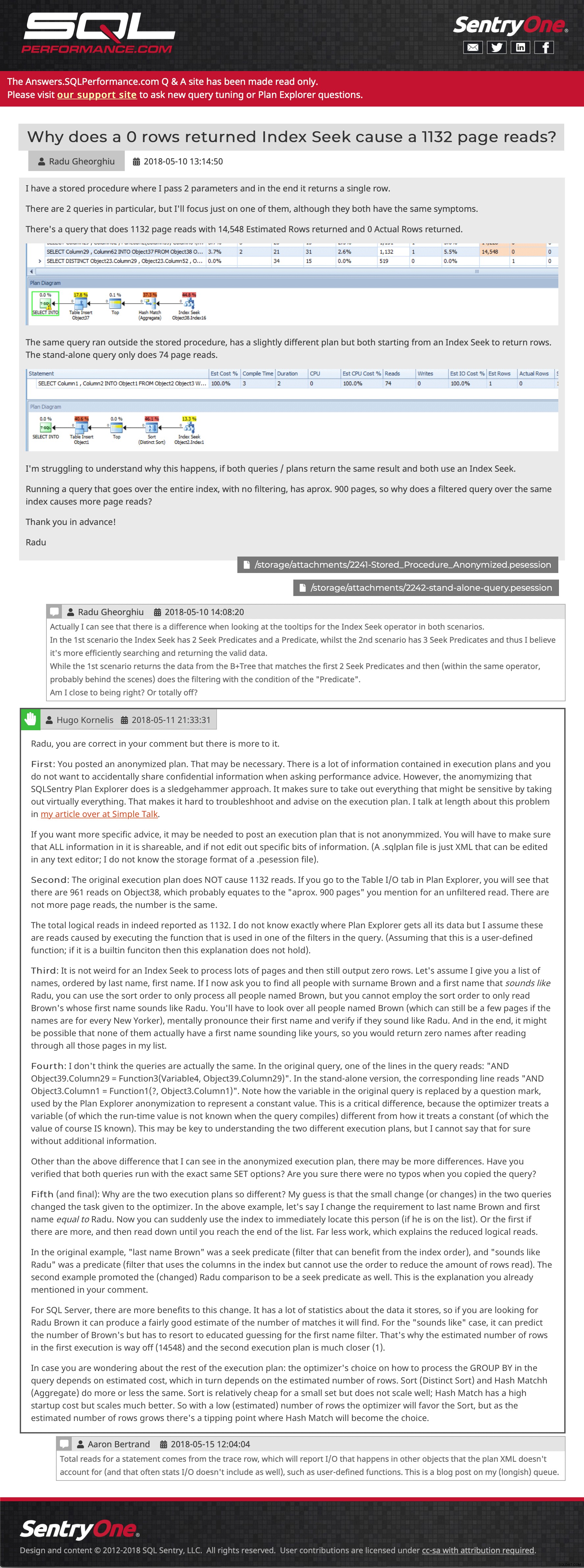 Przykładowe pytanie i odpowiedź (kliknij, aby tam przejść)
Przykładowe pytanie i odpowiedź (kliknij, aby tam przejść) Nadal próbuję odzyskać kilka postów, które zostały przesłane do witryny po wykonaniu ostatniej kopii zapasowej, ale zapraszam do przeglądania. Daj nam znać, jeśli zauważysz, że czegoś brakuje lub jest nie na miejscu, a nawet po prostu poinformuj nas, że treść nadal jest dla Ciebie przydatna. Mamy nadzieję, że ponownie wprowadzimy funkcję przesyłania planu z poziomu Eksploratora planów, ale będzie to wymagało trochę pracy z interfejsem API w nowej witrynie pomocy technicznej, więc nie mam dzisiaj dla Ciebie ETA.
- Odpowiedzi.SQLPerformance.com