Podświetlanie trafień to funkcja, którą wiele osób chciałoby, aby funkcja wyszukiwania pełnotekstowego SQL Server była obsługiwana natywnie. Tutaj możesz zwrócić cały dokument (lub fragment) i wskazać słowa lub frazy, które pomogły dopasować ten dokument do wyszukiwania. Robienie tego w wydajny i dokładny sposób nie jest łatwym zadaniem, o czym przekonałem się z pierwszej ręki.
Jako przykład wyróżniania trafień:kiedy przeprowadzasz wyszukiwanie w Google lub Bing, otrzymujesz pogrubione słowa kluczowe zarówno w tytule, jak i fragmencie (kliknij dowolny obraz, aby powiększyć):

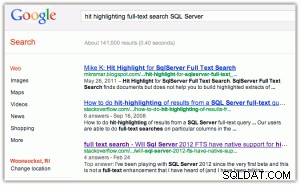
[Na marginesie uważam, że dwie rzeczy są tutaj zabawne:(1) że Bing faworyzuje właściwości Microsoftu o wiele bardziej niż Google, oraz (2) że Bing zawraca sobie głowę zwracaniem 2,2 miliona wyników, z których wiele jest prawdopodobnie nieistotnych.]
Te fragmenty są powszechnie nazywane „fragmentami” lub „podsumowaniami opartymi na zapytaniach”. Od jakiegoś czasu prosiliśmy o tę funkcjonalność w SQL Server, ale nie otrzymaliśmy jeszcze żadnych dobrych wieści od firmy Microsoft:
- Połącz #295100:podsumowania wyszukiwania pełnotekstowego (wyróżnianie trafień)
- Połącz #722324:Byłoby miło, gdyby wyszukiwanie pełnotekstowe SQL zapewniało obsługę fragmentów/podświetlania
Od czasu do czasu pojawia się również pytanie na Stack Overflow:
- Jak wyróżnić trafienia w wynikach zapytania pełnotekstowego SQL Server
- Czy Sql Server 2012 FTS będzie miał natywną obsługę podświetlania trafień?
Istnieje kilka rozwiązań częściowych. Ten skrypt autorstwa Mike'a Kramara, na przykład, utworzy fragment z wyróżnieniem trafienia, ale nie zastosuje tej samej logiki (takiej jak łamacze słów specyficzne dla języka) do samego dokumentu. Wykorzystuje również bezwzględną liczbę znaków, więc fragment może zaczynać się i kończyć częściowymi słowami (co zaraz zademonstruję). To ostatnie jest dość łatwe do naprawienia, ale innym problemem jest to, że ładuje cały dokument do pamięci, zamiast wykonywać jakiekolwiek przesyłanie strumieniowe. Podejrzewam, że w indeksach pełnotekstowych z dużymi rozmiarami dokumentów będzie to zauważalny spadek wydajności. Na razie skupię się na stosunkowo małym średnim rozmiarze dokumentu (35 KB).
Prosty przykład
Załóżmy więc, że mamy bardzo prostą tabelę ze zdefiniowanym indeksem pełnotekstowym:
CREATE FULLTEXT CATALOG [FTSDemo]; GO CREATE TABLE [dbo].[Document] ( [ID] INT IDENTITY(1001,1) NOT NULL, [Url] NVARCHAR(200) NOT NULL, [Date] DATE NOT NULL, [Title] NVARCHAR(200) NOT NULL, [Content] NVARCHAR(MAX) NOT NULL, CONSTRAINT PK_DOCUMENT PRIMARY KEY(ID) ); GO CREATE FULLTEXT INDEX ON [dbo].[Document] ( [Content] LANGUAGE [English], [Title] LANGUAGE [English] ) KEY INDEX [PK_Document] ON ([FTSDemo]);
Ta tabela jest wypełniona kilkoma dokumentami (w szczególności 7), takimi jak Deklaracja Niepodległości i przemówienie Nelsona Mandeli „Jestem gotów umrzeć”. Typowe wyszukiwanie pełnotekstowe w tej tabeli może wyglądać następująco:
SELECT d.Title, d.[Content] FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
Wynik zwraca 4 wiersze z 7:

Teraz używam funkcji UDF, takiej jak Mike Kramar:
SELECT d.Title, Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 80) FROM dbo.[Document] AS d INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t ON d.ID = t.[KEY] ORDER BY [RANK] DESC;
Wyniki pokazują, jak działa fragment:a <SPAN> tag jest wstrzykiwany przy pierwszym słowie kluczowym, a fragment jest wycinany na podstawie przesunięcia od tej pozycji (bez uwzględniania używania pełnych słów):

(Ponownie jest to coś, co można naprawić, ale chcę mieć pewność, że właściwie reprezentuję to, co jest teraz dostępne).
Pomyśl, wyróżnij
Eran Meyuchas z Interactive Thoughts opracował komponent, który rozwiązuje wiele z tych problemów. ThinkHighlight jest zaimplementowany jako zespół CLR z dwiema funkcjami o wartościach skalarnych CLR:
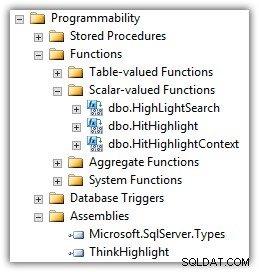
(Na liście funkcji zobaczysz także UDF Mike'a Kramara).
Teraz, bez wchodzenia we wszystkie szczegóły dotyczące instalacji i aktywacji zestawu w twoim systemie, oto jak powyższe zapytanie będzie reprezentowane przez ThinkHighlight:
SELECT d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC; Wyniki pokazują, w jaki sposób wyróżniane są najtrafniejsze słowa kluczowe, a fragment pochodzi z tego opartego na pełnych słowach i odstępie od wyróżnionego terminu:

Niektóre dodatkowe zalety, których nie przedstawiłem tutaj, to możliwość wyboru różnych strategii podsumowania, kontrolowanie prezentacji każdego słowa kluczowego (zamiast wszystkich) za pomocą unikalnego CSS, a także obsługa wielu języków, a nawet dokumentów w formacie binarnym (większość IFilters są obsługiwane).
Wyniki wydajności
Początkowo przetestowałem metryki środowiska uruchomieniowego dla trzech zapytań za pomocą programu SQL Sentry Plan Explorer w odniesieniu do 7-wierszowej tabeli. Wyniki były następujące:

Następnie chciałem zobaczyć, jak wypadliby w porównaniu na znacznie większym rozmiarze danych. Wstawiłem tabelę do siebie, aż dotarłem do 4000 wierszy, a następnie uruchomiłem następujące zapytanie:
SET STATISTICS TIME ON;
GO
SELECT /* FTS */ d.Title, d.[Content]
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* UDF */ d.Title,
Excerpt = dbo.HighLightSearch(d.[Content], N'states', 'font-weight:bold', 100)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY [RANK] DESC;
GO
SELECT /* ThinkHighlight */ d.Title,
Excerpt = dbo.HitHighlight(dbo.HitHighlightContext('Document', 'Content', N'states', -1),
'top-fragment', 100, d.ID)
FROM dbo.[Document] AS d
INNER JOIN CONTAINSTABLE(dbo.[Document], *, N'states') AS t
ON d.ID = t.[KEY]
ORDER BY t.[RANK] DESC;
GO
SET STATISTICS TIME OFF;
GO Monitorowałem również sys.dm_exec_memory_grants podczas działania zapytań, aby wychwycić wszelkie rozbieżności w przydziałach pamięci. Wyniki średnio z 10 przebiegów:
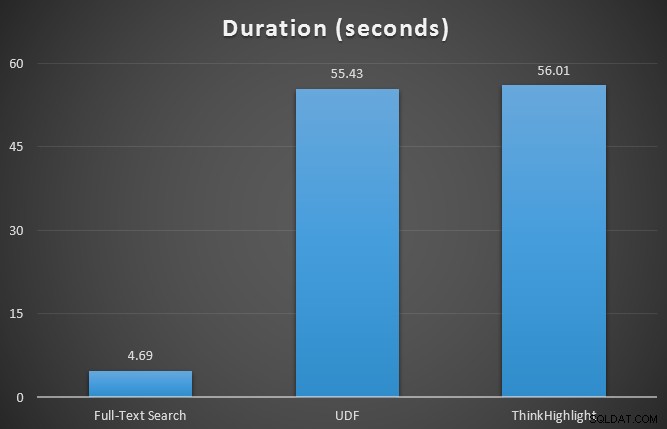
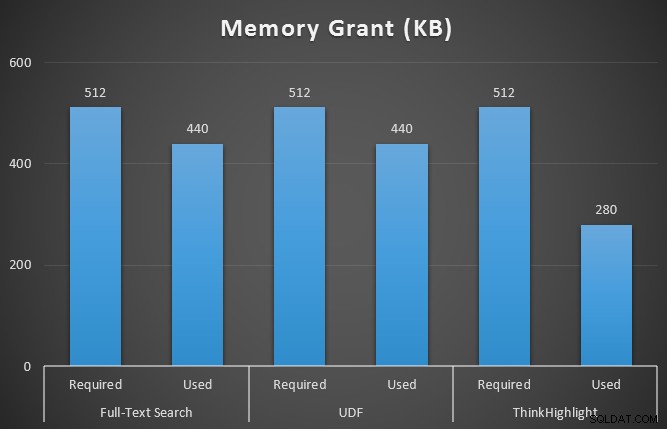
Podczas gdy obie opcje wyróżniania trafień wiążą się ze znaczną karą w przypadku braku podświetlania w ogóle, rozwiązanie ThinkHighlight – z bardziej elastycznymi opcjami – reprezentuje bardzo marginalny koszt przyrostowy pod względem czasu trwania (~1%), przy znacznie mniejszym zużyciu pamięci (36%) niż wariant UDF.
Wniosek
Nie powinno dziwić, że wyróżnianie trafień jest kosztowną operacją, a ze względu na złożoność tego, co ma być obsługiwane (pomyśl o wielu językach), istnieje bardzo niewiele rozwiązań. Myślę, że Mike Kramar wykonał świetną robotę, tworząc podstawowy UDF, który daje dobry sposób na rozwiązanie problemu, ale byłem mile zaskoczony, gdy znalazłem bardziej solidną ofertę komercyjną – i okazało się, że jest bardzo stabilny, nawet w wersji beta. Planuję przeprowadzić dokładniejsze testy z wykorzystaniem szerszego zakresu rozmiarów i typów dokumentów. W międzyczasie, jeśli wyróżnianie trafień jest częścią wymagań aplikacji, wypróbuj UDF Mike'a Kramara i rozważ użycie ThinkHighlight na jazdę próbną.



