Powiedzmy, że chcesz znaleźć wszystkich pacjentów, którzy nigdy nie otrzymali szczepionki przeciw grypie. Lub w AdventureWorks2012 , podobne pytanie może brzmieć:„pokaż wszystkich klientów, którzy nigdy nie złożyli zamówienia”. Wyrażone za pomocą NOT IN , zbyt często widuję wzorzec, który wyglądałby mniej więcej tak (używam powiększonych tabel nagłówków i szczegółów z tego skryptu autorstwa Jonathana Kehayiasa (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Kiedy widzę ten wzór, wzdrygam się. Ale nie ze względu na wydajność – w końcu tworzy wystarczająco przyzwoity plan w tym przypadku:
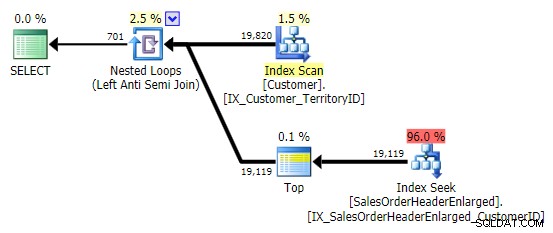
Główny problem polega na tym, że wyniki mogą być zaskakujące, jeśli kolumna docelowa jest zgodna z wartością NULL (SQL Server przetwarza to jako lewe sprzężenie anty semi, ale nie może wiarygodnie stwierdzić, czy wartość NULL po prawej stronie jest równa – czy nie równa – odnośnik po lewej stronie). Ponadto optymalizacja może zachowywać się inaczej, jeśli kolumna jest dopuszczalna NULL, nawet jeśli w rzeczywistości nie zawiera żadnych wartości NULL (Gail Shaw mówił o tym w 2010 r.).
W tym przypadku kolumna docelowa nie dopuszcza wartości null, ale chciałem wspomnieć o potencjalnych problemach z NOT IN – Mogę dokładniej zbadać te kwestie w przyszłym poście.
TL;DR wersja
Zamiast NOT IN , użyj skorelowanego NOT EXISTS dla tego wzorca zapytania. Zawsze. Inne metody mogą konkurować z nim pod względem wydajności, gdy wszystkie inne zmienne są takie same, ale wszystkie inne metody wprowadzają albo problemy z wydajnością, albo inne wyzwania.
Alternatywne
Więc jakie inne sposoby możemy napisać to zapytanie?
ZASTOSOWANIE ZEWNĘTRZNE
Jednym ze sposobów wyrażenia tego wyniku jest użycie skorelowanego OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logicznie rzecz biorąc, jest to również lewe anti semi join, ale w powstałym planie brakuje lewego operatora anti semi join i wydaje się, że jest on nieco droższy niż NOT IN równowartość. Dzieje się tak, ponieważ nie jest to już lewe sprzężenie anty-semi; w rzeczywistości jest przetwarzany w inny sposób:zewnętrzne sprzężenie wprowadza wszystkie pasujące i niepasujące wiersze, a *następnie* stosowany jest filtr w celu wyeliminowania dopasowań:
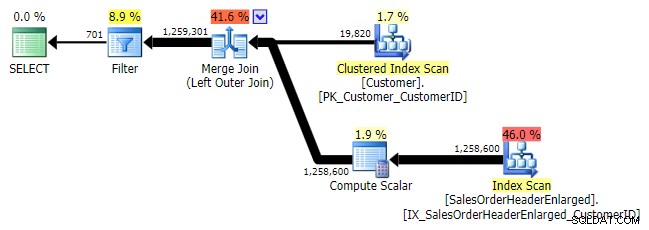
LEWO ZEWNĘTRZNE POŁĄCZENIE
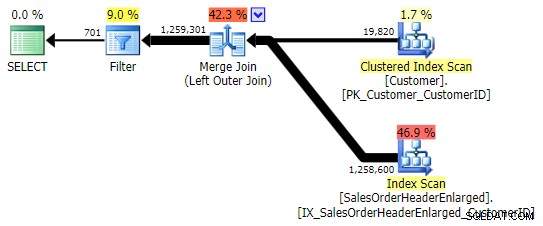
Bardziej typową alternatywą jest LEFT OUTER JOIN gdzie prawa strona to NULL . W takim przypadku zapytanie będzie wyglądało następująco:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
To zwraca te same wyniki; jednak, podobnie jak OUTER APPLY, wykorzystuje tę samą technikę łączenia wszystkich rzędów, a dopiero potem eliminowania dopasowań:
Musisz jednak uważać na to, którą kolumnę sprawdzasz pod kątem NULL . W tym przypadku CustomerID jest logicznym wyborem, ponieważ jest to kolumna łącząca; zdarza się również, że jest indeksowany. Mogłem wybrać SalesOrderID , który jest kluczem klastrowania, więc znajduje się również w indeksie CustomerID . Ale mogłem wybrać inną kolumnę, której nie ma (lub która później zostanie usunięta) z indeksu używanego do łączenia, co prowadzi do innego planu. Lub nawet kolumna dopuszczalna NULL, prowadząca do niepoprawnych (lub przynajmniej nieoczekiwanych) wyników, ponieważ nie ma sposobu na rozróżnienie między wierszem, który nie istnieje, a wierszem, który istnieje, ale gdzie ta kolumna ma wartość NULL . I może nie być oczywiste dla czytelnika/programisty/narzędzia do rozwiązywania problemów, że tak właśnie jest. Dlatego też przetestuję te trzy WHERE klauzule:
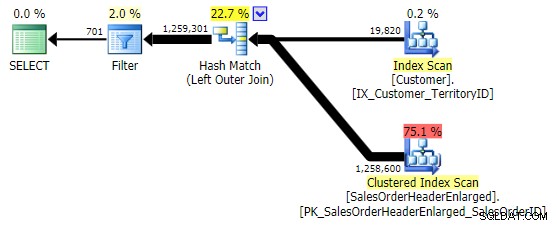
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
Pierwsza odmiana daje taki sam plan jak powyżej. Pozostałe dwa wybierają łączenie haszujące zamiast łączenia scalającego i węższy indeks w Customer tabeli, mimo że zapytanie ostatecznie kończy odczytanie dokładnie tej samej liczby stron i ilości danych. Jednak podczas gdy h.SubTotal zmiana daje prawidłowe wyniki:
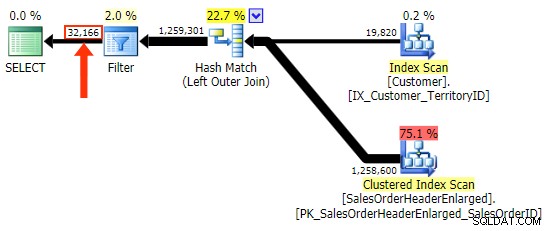
h.Comment odmiana nie, ponieważ zawiera wszystkie wiersze, w których h.Comment IS NULL , a także wszystkie wiersze, które nie istniały dla żadnego klienta. Podkreśliłem subtelną różnicę w liczbie wierszy w danych wyjściowych po zastosowaniu filtra:
Oprócz konieczności zachowania ostrożności przy wyborze kolumn w filtrze, inny problem, który mam z LEFT OUTER JOIN formularz jest taki, że nie jest samodokumentujący, w taki sam sposób jak sprzężenie wewnętrzne w "starym stylu" postaci FROM dbo.table_a, dbo.table_b WHERE ... nie jest samodokumentacją. Rozumiem przez to, że łatwo zapomnieć o kryteriach łączenia, gdy są one umieszczane w WHERE lub pomieszać go z innymi kryteriami filtrowania. Zdaję sobie sprawę, że to dość subiektywne, ale tak jest.
Z WYJĄTKIEM
Jeśli interesuje nas tylko kolumna join (która z definicji znajduje się w obu tabelach), możemy użyć EXCEPT – alternatywa, która wydaje się nie pojawiać zbyt często w tych rozmowach (prawdopodobnie dlatego, że – zwykle – trzeba rozszerzyć zapytanie, aby uwzględnić kolumny, których nie porównujesz):
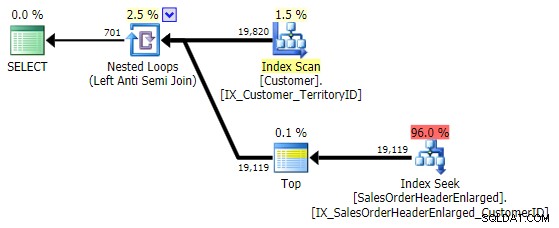
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
To daje dokładnie ten sam plan, co NOT IN odmiana powyżej:
Należy pamiętać, że EXCEPT zawiera niejawny DISTINCT – więc jeśli masz przypadki, w których chcesz, aby wiele wierszy miało tę samą wartość w tabeli „po lewej”, ten formularz wyeliminuje te duplikaty. Nie jest to problem w tym konkretnym przypadku, tylko coś, o czym należy pamiętać – tak jak UNION kontra UNION ALL .
NIE ISTNIEJE
Moje preferencje dla tego wzorca to zdecydowanie NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(I tak, używam SELECT 1 zamiast SELECT * … nie ze względu na wydajność, ponieważ SQL Server nie dba o to, jakich kolumn używasz w EXISTS i optymalizuje je, ale po prostu w celu wyjaśnienia intencji:przypomina mi to, że to "podzapytanie" w rzeczywistości nie zwraca żadnych danych.)
Jego wydajność jest podobna do NOT IN i EXCEPT , i tworzy identyczny plan, ale nie jest podatny na potencjalne problemy spowodowane przez wartości NULL lub duplikaty:
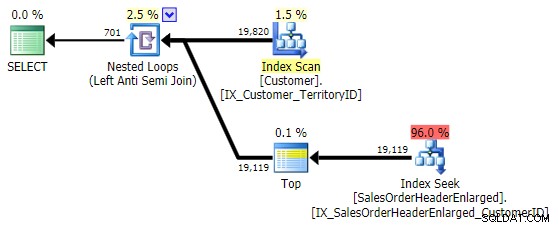
Testy wydajności
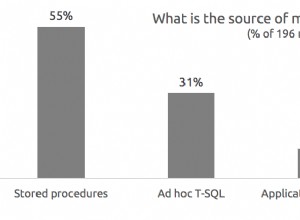
Przeprowadziłem wiele testów, zarówno z zimną, jak i ciepłą pamięcią podręczną, aby potwierdzić, że moje wieloletnie wyobrażenie o NOT EXISTS bycie właściwym wyborem pozostało prawdą. Typowe wyjście wyglądało tak:
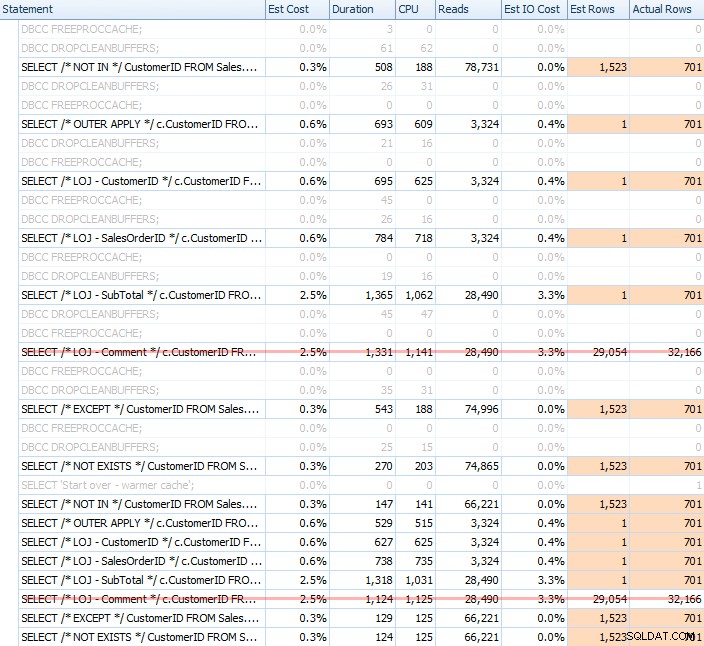
Wyjmę błędny wynik z miksu, pokazując średnią wydajność 20 przebiegów na wykresie (uwzględniłem go tylko po to, aby pokazać, jak błędne są wyniki) i wykonałem zapytania w różnej kolejności w testach, aby się upewnić że jedno zapytanie nie korzystało konsekwentnie z pracy poprzedniego zapytania. Koncentrując się na czasie trwania, oto wyniki:
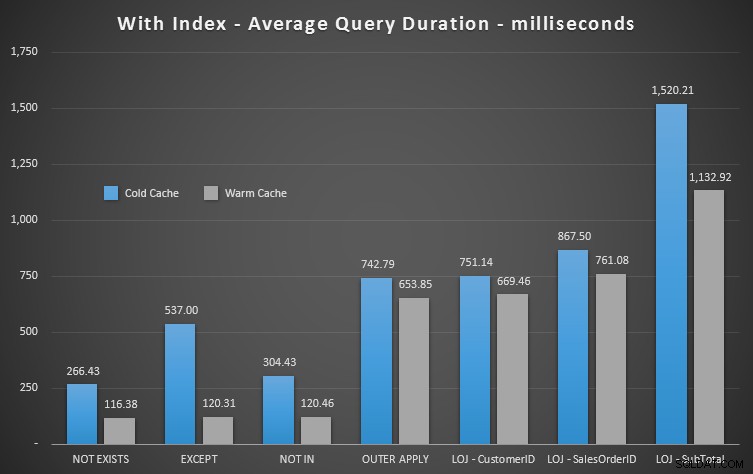
Jeśli spojrzymy na czas trwania i zignorujemy odczyty, zwycięzcą jest NIE ISTNIEJE, ale niewiele. OPRÓCZ i NIE NIE są daleko w tyle, ale znowu musisz spojrzeć nie tylko na wydajność, aby określić, czy te opcje są prawidłowe, i przetestować w swoim scenariuszu.
Co, jeśli nie ma indeksu pomocniczego?
Powyższe zapytania korzystają oczywiście z indeksu Sales.SalesOrderHeaderEnlarged.CustomerID . Jak zmienią się te wyniki, jeśli zrezygnujemy z tego indeksu? Po upuszczeniu indeksu ponownie przeprowadziłem ten sam zestaw testów:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Tym razem różnice w wydajności pomiędzy różnymi metodami były znacznie mniejsze. Najpierw pokażę plany dla każdej metody (z których większość, nic dziwnego, wskazuje na przydatność brakującego indeksu, który właśnie porzuciliśmy). Następnie pokażę nowy wykres przedstawiający profil wydajności zarówno z zimną i ciepłą pamięcią podręczną.
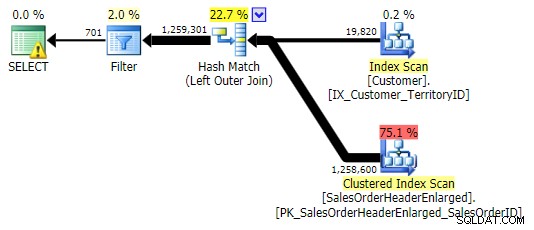
NIE W, Z WYJĄTKIEM, NIE ISTNIEJE (wszystkie trzy były identyczne)
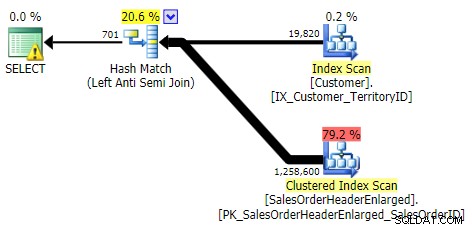
ZASTOSOWANIE ZEWNĘTRZNE
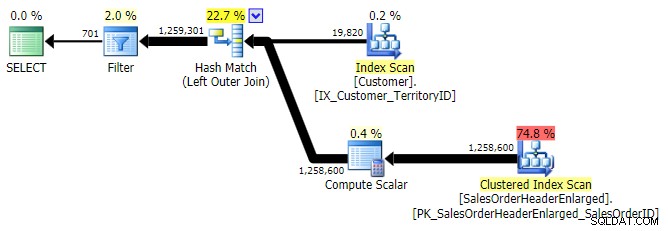
LEWE ZŁĄCZENIE ZEWNĘTRZNE (wszystkie trzy były identyczne z wyjątkiem liczby rzędów)
Wyniki wydajności
Gdy spojrzymy na te nowe wyniki, od razu widzimy, jak przydatny jest ten indeks. We wszystkich przypadkach oprócz lewego sprzężenia zewnętrznego, które i tak wychodzi poza indeks, wyniki są wyraźnie gorsze, gdy porzuciliśmy indeks:
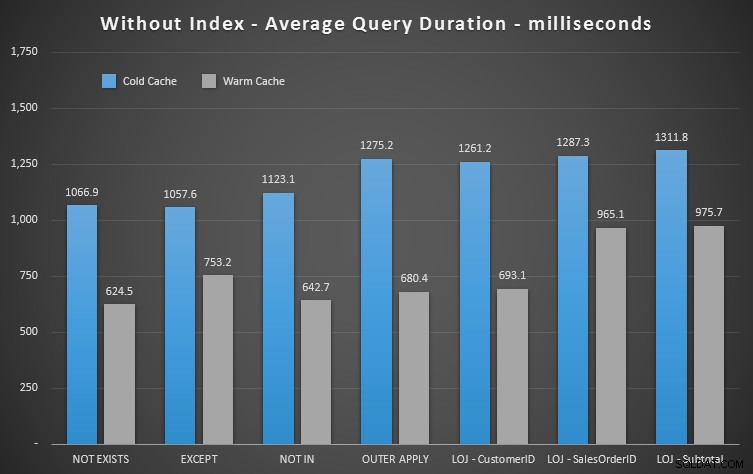
Widzimy więc, że chociaż wpływ jest mniej zauważalny, NOT EXISTS nadal jest Twoim marginalnym zwycięzcą pod względem czasu trwania. A w sytuacjach, w których inne podejścia są podatne na zmienność schematu, jest to również najbezpieczniejszy wybór.
Wniosek
To był tylko bardzo długi sposób powiedzenia ci, że dla wzorca znajdowania wszystkich wierszy w tabeli A, gdzie jakiś warunek nie istnieje w tabeli B, NOT EXISTS zazwyczaj będzie najlepszym wyborem. Ale, jak zawsze, musisz przetestować te wzorce we własnym środowisku, korzystając ze swojego schematu, danych i sprzętu oraz zmieszać z własnymi obciążeniami.