Kiedy rozpoczynamy projekt hurtowni danych, pierwszą rzeczą, którą robimy, jest zdefiniowanie tabel wymiarowych. Tabele wymiarowe to ciekawe elementy, ramy, wokół których budujemy nasze pomiary. Występują w wielu kształtach i rozmiarach. W tym artykule przyjrzymy się bliżej każdemu typowi tabeli wymiarowej.
Tabele wymiarowe zapewniają kontekst dla procesów biznesowych, które chcemy mierzyć. Mówią nam wszystko, co musimy wiedzieć o wydarzeniu. Ponieważ nadają one sens pomiarom (tj. tabelom faktów) systemu hurtowni danych (DWH), spędzamy więcej czasu na ich zdefiniowaniu i identyfikacji niż na jakimkolwiek innym aspekcie projektu. Tabele faktów definiuj pomiary; tabele wymiarowe dają kontekst. (Aby dowiedzieć się więcej o tabelach faktów, zapoznaj się z tymi postami na temat hurtowni danych, schematu gwiaździstego, schematu płatka śniegu i faktów dotyczących tabel faktów).
Główną cechą tabel wymiarów jest ich wiele atrybutów . Atrybuty to kolumny, które podsumowujemy, filtrujemy lub agregujemy. Mają niską kardynalność i są zwykle tekstowe i czasowe. Tabele wymiarowe mają jeden klucz podstawowy oparty na podstawowym kluczu biznesowym lub klucz zastępczy . Ten klucz podstawowy jest podstawą do łączenia tabeli wymiarów z jedną lub większą liczbą tabel faktów.
W porównaniu z tabelami faktów, tabele wymiarów są małe, łatwe do przechowywania i mają niewielki wpływ na wydajność.
Przyjrzyjmy się teraz niektórym tabelom wymiarów, które można napotkać w środowisku hurtowni danych.
Wspólna tabela wymiarów:zgodny wymiar
Zaczniemy od podstawowego typu:dopasowanego wymiaru. Zawierają one wiele atrybutów, które mogą być adresowane w kilku tabelach źródłowych, ale które odnoszą się do tej samej domeny (klient, umowa, umowa itp.) Zgodne wymiary są używane z wieloma faktami i powinny być unikalne dla wartości ziarna/domeny w hurtowni danych.
Przykład:
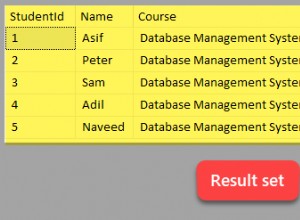
Spójrzmy na typową tabelę wymiarową, DIM_CUSTOMER .
Definiujemy:
id– Klucz podstawowy tabeli wymiarów.cust_natural_key– Naturalny klucz dla klienta.first_name– Imię klienta.last_name– Nazwisko klienta.address_residence– Adres zamieszkania klienta.date_of_birth– Data urodzenia klienta.marital_status– Czy klient jest żonaty? Zdefiniowane jako Y (tak) lub N (nie).gender– Płeć klienta, M (mężczyzna) lub F (kobieta).
Atrybuty tabeli wymiarów zależą od potrzeb biznesowych. Możemy rozszerzyć ten typ tabeli, aby pomieścić informacje specyficzne dla branży (data niewykonania zobowiązania, aktywność itp.)
Powoli zmieniające się tabele wymiarów
W miarę upływu czasu wymiary mogą zmieniać swoje wartości. W kolejnych akapitach przyjrzymy się wymiarom sklasyfikowanym według tego, jak przechowują (lub nie przechowują) danych historycznych.
Załóżmy, że masz wymiar klienta. Niektóre atrybuty prawdopodobnie zmienią się w ciągu życia klienta – np. numer telefonu, adres, stan cywilny itp. Ten typ tabeli jest tym, co Ralph Kimball nazywa powoli zmieniającym się wymiarem lub SCD.
SCD występuje w wielu typach; osiem z nich jest dość powszechnych. Spośród nich najczęściej zobaczysz typy od 0 do 4; typy 5, 6 i 7 to hybrydy pierwszych pięciu. (Uwaga:schemat numeracji tych SCD zaczyna się od 0 zamiast 1.)
Hybrydowe dyski SCD zapewniają większą elastyczność i lepszą wydajność, ale kosztem prostoty. Używamy tych typów tabel, gdy musimy przeprowadzić analizę analityczną bieżącego dane z niektórymi historycznymi rozważania.
SCD typ 0:jednokrotne wypełnienie
To najbardziej podstawowy typ tabeli wymiarów:wypełniasz ją raz i nigdy wypełnij go ponownie. Potraktuj to jako dane referencyjne. Typowym tego przykładem jest wymiar daty. Nie musimy wypełniać tego wymiaru przy każdym obciążeniu DWH. Tabela wymiarów nie zmienia się w czasie. Nie możesz uzyskać więcej dat ani zmienić dat.
Tabela faktów łączy się z oryginalnymi atrybutami wymiaru.
Przykład
Spójrzmy na wymiar czasu:
Struktura jest dość prosta:
id– Klucz zastępczytime_date– Aktualna datatime_day– Dzień miesiącatime_week– Tydzień w rokutime_month– Miesiąc za roktime_year– Liczbowe przedstawienie roku
SCD typ 1:przepisywanie danych
Jak sama nazwa wskazuje, przepisujemy ten typ tabeli wymiarowej przy każdym obciążeniu DWH. Nie musimy przechowywać ich historii, ale spodziewamy się, że nastąpią pewne zmiany.
Różnica między SCD typu 0 a typem 1 nie znajduje się w strukturze tabeli. Ma to związek z odświeżeniem danych. Nigdy nie odświeżasz danych w typie 0, ale czasami robisz to w typie 1.
Tablica wielokrotnego zapisu to najprostszy sposób obsługi zmian (usuwanie/wstawianie), ale dodaje niewielką wartość biznesową. Po zdefiniowaniu takiej tabeli wymiarów trudno jest zainstalować śledzenie historyczne.
Tabela faktów łączy się z bieżącymi atrybutami wymiaru.
Przykład
Przyjrzyjmy się wymiarowi konta:
Jego struktura jest następująca:
id– klucz zastępczy tabeliaccount_name– Nazwa kontaaccount_type– Kategoria kontaaccount_activity– Oznacza różne rodzaje aktywności
Jeśli spojrzymy na dane przed zmianą, zobaczymy to:
W przypadku zmiany typu konta dane zostaną po prostu nadpisane:
SCD typ 2:śledzenie atrybutów historycznych według wierszy
Jest to najczęstsza forma śledzenia historycznego w systemie DWH. Tabele SCD typu 2 dodają nowe wiersze dla każdej historycznej zmiany atrybutów wymiarowych pomiędzy Ładunki DWH . W tym typie definiujemy klucz podstawowy jako klucz zastępczy, ponieważ klucz biznesowy będzie miał wiele reprezentacji w czasie. Kiedy zmieniają się wiersze zawierające zmianę danych, definiujemy nową wartość klucza zastępczego, która odpowiada wartości w tabeli faktów. Musimy dodać co najmniej dwie kolumny, valid_from i valid_to , aby w ten sposób przechowywać historię.
Tabela faktów łączy się z historycznymi atrybutami wymiaru za pomocą klucza zastępczego. Agregacja odbywa się przy użyciu klucza naturalnego .
Przykład
Spójrzmy na poprzednią tabelę wymiarów klienta, teraz rozszerzoną o dwie kolumny dat:
Spójrzmy na dane:
Wskazówki do rozważenia:
- Jak możemy oflagować bieżący wiersz,
valid_to? (Zazwyczaj 31.12.9999 lub NULL .) - Jak możemy oflagować pierwszy wiersz,
valid_from? (Zazwyczaj 01.01.1900 lub data pierwszego wstawienia). - Czy definiujesz wiersz zawierający czy wykluczający? (Powyżej używamy inkluzywnego
valid_fromi ekskluzywnyvalid_to).
SCD typ 3:śledzenie atrybutów historycznych według kolumny
Podobnie jak w przypadku SCD typu 2, ten typ dodaje coś do reprezentowania wartości historycznych. W tym przypadku jednak dodajemy nowe kolumny. Reprezentują one wartość atrybutu wiersza wymiaru przed jego zmianą. Zwykle zachowujemy tylko poprzednią wersję atrybutu.
Uwaga:ten SCD jest rzadko używany.
Tabela faktów łączy się z bieżącymi i wcześniejszymi atrybutami wymiaru.
Przykład
Przyjrzyjmy się wymiarowi klienta, tym razem z poprzednim adresem zamieszkania:
W tym przykładzie dodaliśmy nową kolumnę, previous_address_residence , reprezentujący stary adres klienta. Jeśli spojrzymy na nasz początkowy przykład, dane w tej tabeli wyglądają tak:
Wszystkie informacje historyczne, z wyjątkiem poprzedniego adresu klienta, zostaną utracone.
SCD typ 4:dodawanie miniwymiaru
Ten typ wymiaru nie jest oparty na zmianach strukturalnych (Typ 3) lub wartości (Typ 2). Opiera się raczej na zmianach projektowych w modelu. Jeśli nasza tabela wymiarowa zawiera bardzo niestabilne dane – tj. dane, które często się zmieniają – rozmiar tabeli wymiarowej znacznie by wzrósł.
Aby to złagodzić, wyodrębniamy zmienne atrybuty do miniwymiaru . Te miniwymiary można następnie zagregować do poziomu istotnego dla biznesu. Jednak ta agregacja nie mylić z agregacją faktów . Przykład wyjaśni to.
Tabela faktów łączy się z historycznymi atrybutami wymiaru.
Przykład
Spójrzmy na przykład z prostej giełdy danych finansowych. Załóżmy, że musisz śledzić, jak spóźniają się niektórzy klienci z płatnościami. Nazwijmy ten atrybut dniami przeterminowania lub DPD. Gdybyśmy mieli codziennie śledzić DPD w wymiarze typu 2, rozmiar tabeli wkrótce eksplodowałby poza możliwe do opanowania granice. Wyodrębniamy więc atrybut i znajdujemy istotne z biznesowego punktu widzenia okresy DPD – powiedzmy według 30-dniowych przyrostów (0-30 DPD, 30-60 DPD, 60-90 DPD itd.)
Możemy wziąć inne atrybuty o wysokiej zmienności, takie jak wiek, i stworzyć dla nich okresy istotne dla biznesu (np. 20-30 lat, 30-40 lat itp.)
Jeśli spojrzymy na dane w miniwymiarze klienta, otrzymalibyśmy coś takiego:
Atrybuty to:
id– Zastępczy klucz podstawowyDPD_period– Dni przeterminowanychDEM_period– Okres demograficzny
Prosty schemat gwiazdy wyglądałby tak:
Zauważ, że aby przeprowadzić jakąkolwiek analizę atrybutów z obu tabel, musielibyśmy połączyć je przez tabelę faktów.
SCD typ 5:tworzenie miniwymiaru z rozszerzeniem wielokrotnego zapisu
Jest to pierwsza z naszych hybrydowych konstrukcji tabel wymiarowych. W SCD typu 5 dodajemy aktualną wersję danych mini-wymiarowych do tabeli wymiarów. Musimy pamiętać, że dodamy tylko bieżące reprezentacja mini-wymiaru do wymiaru głównego.
Uzupełniamy to rozszerzenie mini-wymiarowe z każdym ładunkiem (SCD typu 1 „wielokrotnego zapisu”).
Chociaż historyzacja tego rozszerzenia może bardzo dobrze prowadzić do problemów z rozmiarem, już je złagodziliśmy za pomocą tabeli mini-wymiarów.
Używamy tej techniki, gdy chcemy wykonywać analizy bezpośrednio w tabelach wymiarów.
Przykład
Rozszerzając poprzedni przykład o aktualny miniwymiar, otrzymujemy:
dim_mini_customer_current tabela zawiera najnowsze wartości atrybutów, które odpowiadają dim_customer stół. Teraz możemy wykonywać analizy specyficzne dla klienta bez przechodzenia przez tabelę faktów (co jest bardzo powolne).
Tabela faktów łączy się z historycznymi atrybutami wymiaru.
Typ 6:Typ 2 (wiersz historyczny) wymiar z atrybutem wielokrotnego zapisu
To bardzo powszechna konstrukcja wymiarowa. Dodajemy atrybut, który przechowuje jedną rzecz, zwykle ostatnią znaną wartość, którą przepisujemy przy każdym ładowaniu. Dzięki temu możemy pogrupować wszystkie fakty według ich aktualnej wartości, podczas gdy atrybut historyczny wyświetla dane tak, jak w momencie, gdy miały miejsce zdarzenia.
Tabela faktów łączy się z wartościami wymiarów w momencie zdarzenia z dodatkowymi bieżącymi wartościami wymiarów.
Przykład
Rozwińmy poprzednią tabelę klientów o current_address_residence kolumna.
Teraz mamy atrybut, który zaktualizujemy do aktualnej wartości, używając klucza naturalnego (cust_natural_key ).
Typ 7:Typ 2 (wiersz historyczny) Wymiary z aktualnym lustrem
Tego typu możemy użyć tylko wtedy, gdy w wymiarze tabeli występuje klucz naturalny. Klucz nie może się zmieniać podczas życia jednostki.
Pomysł jest prosty:do schematu płatka śniegu dodajemy aktualną reprezentację tabeli wymiarowej. Następnie wstawiamy naturalny klucz nowego wymiaru do tabeli faktów. (Zastępczy klucz wymiaru historycznego jest nadal obecny.)
Tabela faktów łączy się z wartościami wymiarów w momencie zdarzenia i bieżącymi wartościami wymiarów.
Przykład
Przyjrzyjmy się naszemu gwiezdnemu schematowi kont klientów. Dodajemy nowy wymiar, dim_current_customer , do tabeli faktów. Ta tabela jest połączona z tabelą faktów za pomocą naturalnego klucza, cust_natural_key .
Ta konstrukcja umożliwia nam wykonywanie zapytań analitycznych na schemacie gwiazdy z bieżącymi i historycznymi wartościami atrybutów klienta.
Wymiary domeny
Wymiar domeny to prosta forma tabeli wymiarów. Zawiera informacje o domenie podstawowego pomiaru atrybutu wymiarowego. Te tabele przechowują różne kody i wartości objaśniające.
Przykład
Prostym przykładem może być tabela walut.
W tej tabeli przechowujemy opisowe informacje o różnych jednostkach pieniężnych.
Moim zdaniem najlepszym wykorzystaniem wymiaru domeny jest dokumentacja wartości danych, które znajdujemy w systemie DWH.
Wymiary śmieci
Transakcyjne systemy źródłowe generują wiele wskaźników i flag. Te atrybuty można uznać za dane kategoryczne, ale nie są one istotne z punktu widzenia biznesu ani nie wymagają wyjaśnień. Wszystkie te wskaźniki i flagi możemy umieścić w jednowymiarowej tabeli zwanej wymiarem śmieci . Wymiar śmieci jest alternatywą dla używania wymiarów zdegenerowanych. Jeśli nie chcemy obciążać tabeli faktów wieloma zdegenerowanymi wymiarami, tworzymy jeden niepotrzebny wymiar.
Należy zauważyć, że nie wypełniamy wszystkich możliwych kombinacji wskaźników i flag. Wypełniamy tylko te, które istnieją w systemie źródłowym.
Przykład
Tabele wymiarów to szkielety świata hurtowni danych:wokół nich zbudowane jest wszystko. Nie są tak duże jak tabele faktów, ale ich struktura może być bardziej złożona.
Możesz zestawić wiele typów tabel wymiarów, nawet poza tymi, które właśnie omówiliśmy. A co z Twoją firmą i branżą? Jeśli połączyłeś typy tabel wymiarowych w coś nowego, powiedz nam o tym!