W moim poprzednim poście mówiłem o sposobach generowania sekwencji ciągłych liczb od 1 do 1000. Teraz chciałbym omówić kolejne poziomy skali:generowanie zestawów po 50 000 i 1 000 000 liczb.
Generowanie zestawu 50 000 liczb
Rozpoczynając tę serię, byłem naprawdę ciekawy, jak różne podejścia będą skalować się do większych zestawów liczb. Na dole byłem trochę przerażony, gdy stwierdziłem, że to moje ulubione podejście – użycie sys.all_objects – nie była najskuteczniejszą metodą. Ale w jaki sposób te różne techniki skalują się do 50 000 wierszy?
Tabela liczb
Ponieważ utworzyliśmy już tabelę liczb z 1 000 000 wierszy, to zapytanie pozostaje praktycznie identyczne:
SELECT TOP (50000) n FROM dbo.Numbers ORDER BY n;
Plan:
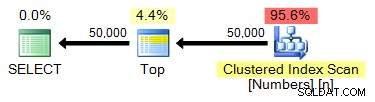
spt_values
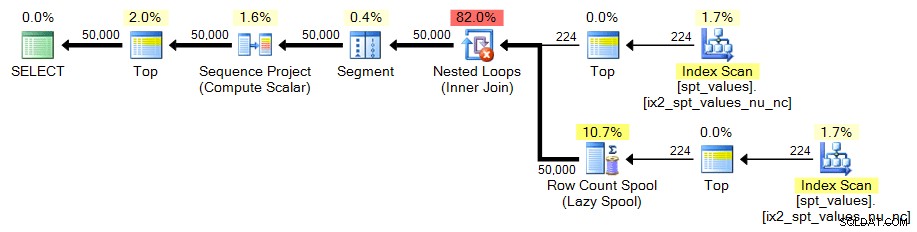
Ponieważ w spt_values jest tylko ~ 2500 wierszy , musimy być trochę bardziej kreatywni, jeśli chcemy użyć go jako źródła naszego generatora zestawów. Jednym ze sposobów symulowania większej tabeli jest CROSS JOIN to przeciwko sobie. Gdybyśmy zrobili to na surowo, skończylibyśmy z ~2500 wierszami do kwadratu (ponad 6 milionów). Potrzebujemy tylko 50 000 rzędów, potrzebujemy około 224 rzędów do kwadratu. Możemy to zrobić:
;WITH x AS ( SELECT TOP (224) number FROM [master]..spt_values ) SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Zwróć uwagę, że jest to równoważne, ale bardziej zwięzłe niż ta odmiana:
SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.number) FROM (SELECT TOP (224) number FROM [master]..spt_values) AS x CROSS JOIN (SELECT TOP (224) number FROM [master]..spt_values) AS y ORDER BY n;
W obu przypadkach plan wygląda tak:
sys.all_objects
Podobnie jak spt_values , sys.all_objects samo w sobie nie do końca spełnia nasze wymagania dotyczące 50 000 wierszy, więc będziemy musieli wykonać podobne CROSS JOIN .
;;WITH x AS ( SELECT TOP (224) [object_id] FROM sys.all_objects ) SELECT TOP (50000) n = ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:

Skumulowane CTE
Musimy tylko dokonać niewielkiej korekty naszych skumulowanych CTE, aby uzyskać dokładnie 50 000 wierszy:
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e2 CROSS JOIN e2 AS b), -- 100*100
e4(n) AS (SELECT 1 FROM e3 CROSS JOIN (SELECT TOP 5 n FROM e1) AS b) -- 5*10000
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n; Plan:

Rekursywne CTE
Jeszcze mniej istotna zmiana jest wymagana, aby uzyskać 50 000 wierszy z naszego rekurencyjnego CTE:zmień WHERE klauzulę na 50 000 i zmień MAXRECURSION opcja na zero.
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 50000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 0); Plan:
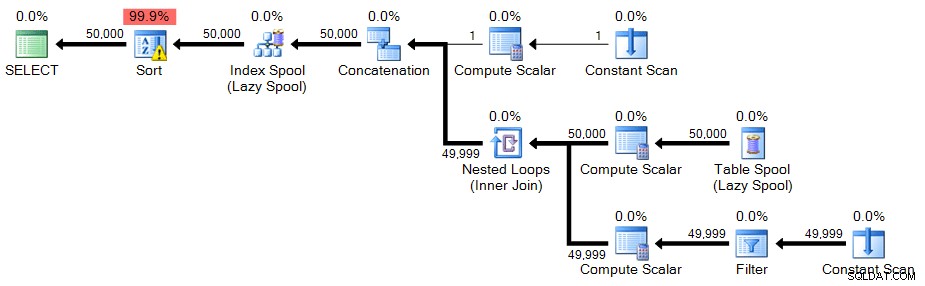
W tym przypadku pojawia się ikona ostrzegawcza – jak się okazuje, w moim systemie rodzaj musiała się rozlać do tempdb. Możesz nie zobaczyć wycieku w systemie, ale powinno to być ostrzeżeniem o zasobach wymaganych do tej techniki.
Wydajność
Podobnie jak w przypadku ostatniego zestawu testów, porównamy każdą technikę, w tym tabelę Numbers z zimną i ciepłą pamięcią podręczną, zarówno skompresowaną, jak i nieskompresowaną:
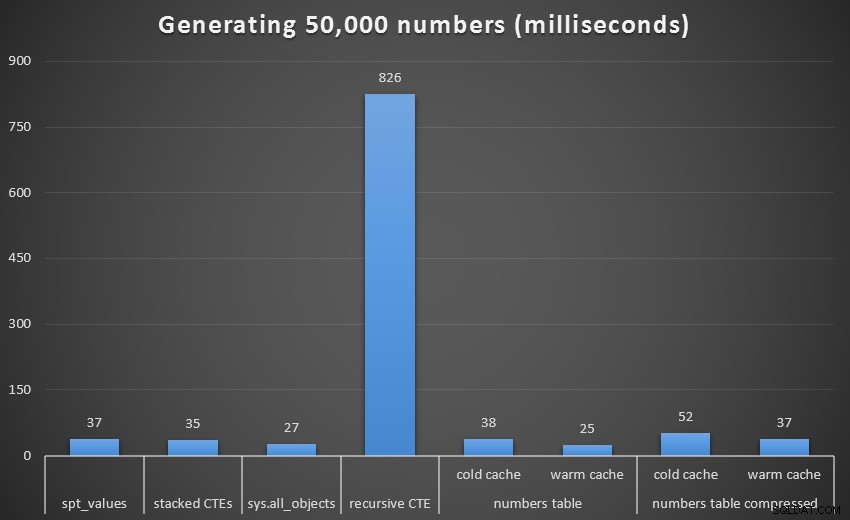
Uruchom w milisekundach, aby wygenerować 50 000 ciągłych liczb
Aby uzyskać lepszy obraz, usuńmy rekurencyjne CTE, które w tym teście było całkowitym psem i które zniekształca wyniki:
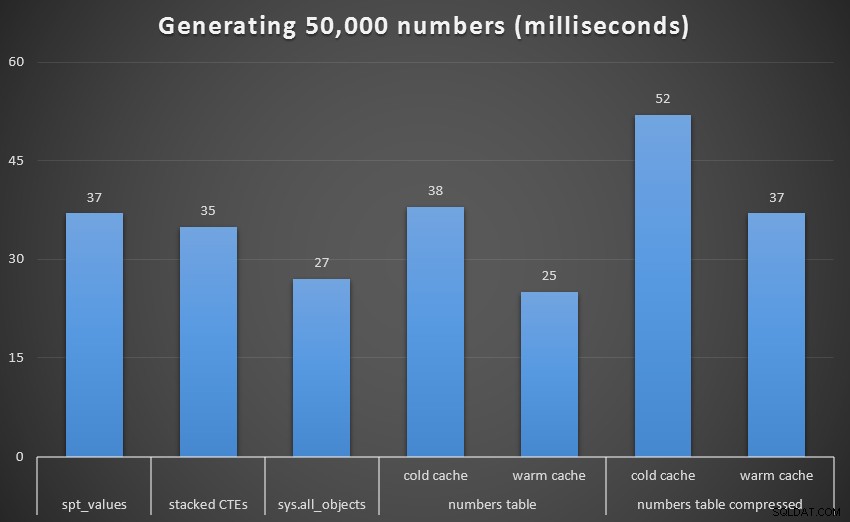
Uruchom w milisekundach, aby wygenerować 50 000 ciągłych liczb (z wyłączeniem rekurencyjnych CTE)
Przy 1000 wierszach różnica między skompresowanymi a nieskompresowanymi była marginalna, ponieważ zapytanie musiało odczytać odpowiednio tylko 8 i 9 stron. Przy 50 000 wierszy luka nieco się powiększa:74 strony w porównaniu do 113. Jednak całkowity koszt dekompresji danych wydaje się przewyższać oszczędności we/wy. Tak więc, mająca 50 000 wierszy, nieskompresowana tabela liczb wydaje się być najskuteczniejszą metodą wyprowadzania ciągłego zestawu – choć, trzeba przyznać, przewaga jest marginalna.
Generowanie zestawu 1 000 000 liczb
Chociaż nie wyobrażam sobie zbyt wielu przypadków użycia, w których potrzebny byłby tak duży ciągły zestaw liczb, chciałem go uwzględnić dla kompletności, a także ponieważ dokonałem kilku interesujących obserwacji w tej skali.
Tabela liczb
Żadnych niespodzianek, nasze zapytanie brzmi teraz:
SELECT TOP 1000000 n FROM dbo.Numbers ORDER BY n;
TOP nie jest bezwzględnie konieczne, ale dzieje się tak tylko dlatego, że wiemy, że nasza tabela liczb i pożądany wynik mają tę samą liczbę wierszy. Plan jest nadal dość podobny do poprzednich testów:
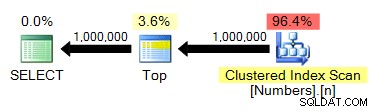
spt_values
Aby uzyskać CROSS JOIN co daje 1 000 000 wierszy, musimy wziąć 1000 wierszy do kwadratu:
;WITH x AS ( SELECT TOP (1000) number FROM [master]..spt_values ) SELECT n = ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:
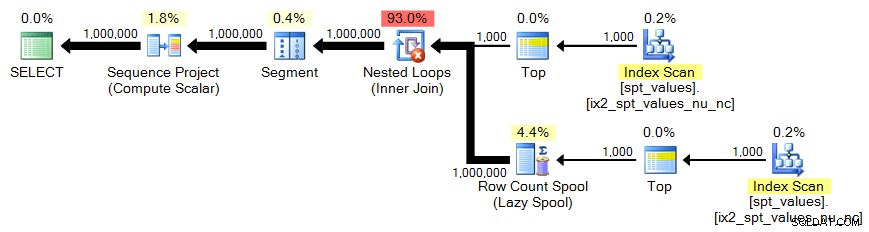
sys.all_objects
Ponownie potrzebujemy iloczynu krzyżowego 1000 wierszy:
;WITH x AS ( SELECT TOP (1000) [object_id] FROM sys.all_objects ) SELECT n = ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:

Skumulowane CTE
W przypadku skumulowanego CTE potrzebujemy tylko nieco innej kombinacji CROSS JOIN s, aby dostać się do 1 000 000 wierszy:
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2 AS b), -- 10*100
e4(n) AS (SELECT 1 FROM e3 CROSS JOIN e3 AS b) -- 1000*1000
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e4 ORDER BY n; Plan:

Przy tym rozmiarze wiersza widać, że skumulowane rozwiązanie CTE działa równolegle. Uruchomiłem więc również wersję z MAXDOP 1 aby uzyskać podobny kształt planu jak poprzednio i sprawdzić, czy równoległość naprawdę pomaga:

Rekursywny CTE
Rekursywne CTE ponownie ma tylko niewielką zmianę; tylko WHERE klauzula musi ulec zmianie:
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 0); Plan:
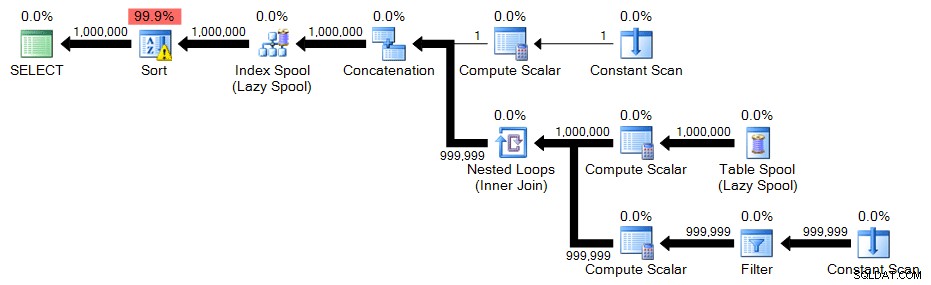
Wydajność
Po raz kolejny widzimy, że wydajność rekurencyjnego CTE jest fatalna:
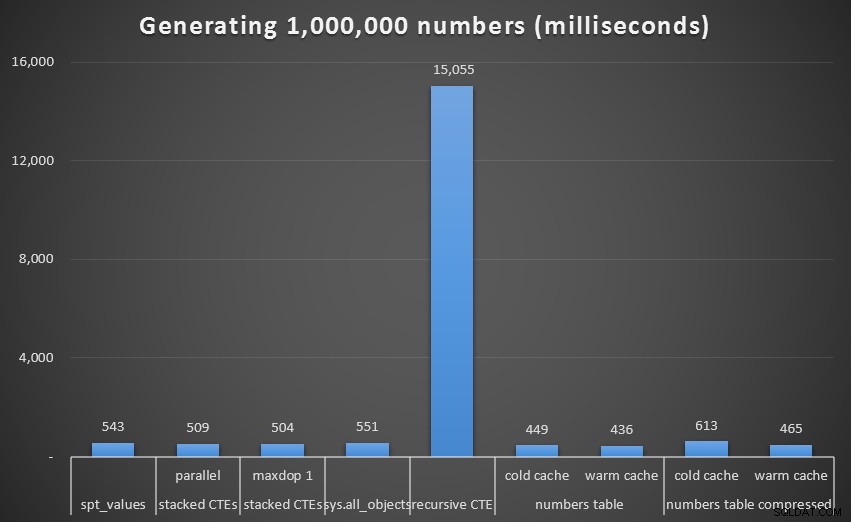
Uruchom w milisekundach, aby wygenerować 1 000 000 ciągłych liczb
Usuwając tę wartość odstającą z wykresu, uzyskujemy lepszy obraz wydajności:
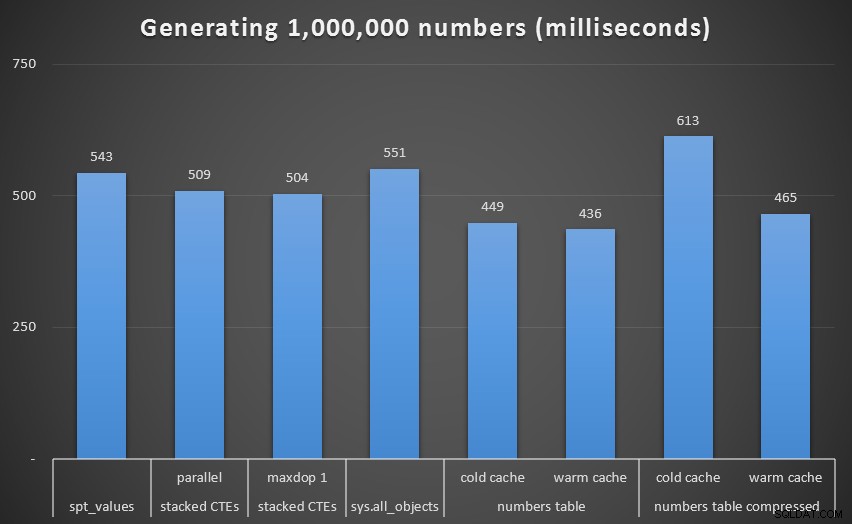
Czas uruchomieniowy w milisekundach w celu wygenerowania 1 000 000 ciągłych liczb (z wyłączeniem rekurencyjnych CTE)
Podczas gdy ponownie widzimy nieskompresowaną tabelę liczb (przynajmniej z ciepłą pamięcią podręczną) jako zwycięzcę, różnica nawet w tej skali nie jest aż tak znacząca.
Ciąg dalszy…
Teraz, gdy dokładnie zbadaliśmy kilka podejść do generowania sekwencji liczb, przejdziemy do dat. W ostatnim poście z tej serii omówimy konstrukcję zakresu dat jako zestawu, w tym użycie tabeli kalendarza oraz kilka przypadków użycia, w których może to być przydatne.
[ Część 1 | Część 2 | Część 3 ]
Dodatek:Liczby wierszy
Być może nie próbujesz wygenerować dokładnej liczby wierszy; możesz zamiast tego po prostu chcieć prostego sposobu generowania wielu wierszy. Poniżej znajduje się lista kombinacji widoków katalogu, które dadzą Ci różne liczby wierszy, jeśli po prostu SELECT bez WHERE klauzula. Pamiętaj, że te liczby będą zależeć od tego, czy jesteś w RTM, czy w dodatku Service Pack (ponieważ niektóre obiekty systemowe są dodawane lub modyfikowane), a także od tego, czy masz pustą bazę danych.
| Źródło | Liczba wierszy | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2508 | 2515 | 2519 |
| master..spt_values POŁĄCZENIE KRZYŻOWE master..spt_values | 6 290 064 | 6 325 225 | 6 345 361 |
| sys.all_objects | 1990 | 2089 | 2165 |
| sys.all_columns | 5157 | 7276 | 8,560 |
| sys.all_objects POŁĄCZENIE KRZYŻOWE sys.all_objects | 3960100 | 4363 921 | 4687225 |
| sys.all_objects POŁĄCZENIE KRZYŻOWE sys.all_columns | 10 262 430 | 15 199 564 | 18 532 400 |
| sys.all_columns POŁĄCZENIE KRZYŻOWE sys.all_columns | 26 594 649 | 52 940 176 | 73 273 600 |
Tabela 1:Liczby wierszy dla różnych zapytań o widok katalogu