W zeszłym miesiącu rozmawiałem z wieloma klientami, którzy mieli problemy z niejawną konwersją po stronie kolumny związane z ich obciążeniami OLTP. W dwóch przypadkach skumulowany efekt niejawnych konwersji po stronie kolumny był podstawową przyczyną ogólnego problemu z wydajnością sprawdzanego programu SQL Server i niestety nie ma magicznego ustawienia ani opcji konfiguracji, które moglibyśmy poprawić, aby poprawić sytuację kiedy tak jest. Chociaż możemy zaoferować sugestie dotyczące naprawienia innych, mniej wiszących owoców, które mogą wpływać na ogólną wydajność, efekt niejawnych konwersji po stronie kolumny jest czymś, co wymaga albo zmiany projektu schematu, aby naprawić, albo zmiany kodu, aby zapobiec konwersja poboczna występująca całkowicie w stosunku do bieżącego schematu bazy danych.
Konwersje niejawne są wynikiem porównania przez aparat bazy danych wartości różnych typów danych podczas wykonywania zapytania. Listę możliwych niejawnych konwersji, które mogą wystąpić w aparacie bazy danych, można znaleźć w temacie Books Online Konwersja typu danych (aparat bazy danych). Konwersje niejawne zawsze występują na podstawie pierwszeństwa typu danych dla typów danych, które są porównywane podczas operacji. Kolejność pierwszeństwa typów danych można znaleźć w temacie Books Online Pierwszeństwo typów danych (język Transact-SQL). Niedawno pisałem na blogu o niejawnych konwersjach, które skutkują skanowaniem indeksu, i przedstawiłem wykresy, które można wykorzystać również do określenia najbardziej problematycznych niejawnych konwersji.
Konfiguracja testów
Aby zademonstrować obciążenie wydajności związane z niejawnymi konwersjami po stronie kolumny, które skutkują skanowaniem indeksu, przeprowadziłem szereg różnych testów względem bazy danych AdventureWorks2012 przy użyciu tabeli Sales.SalesOrderDetail do tworzenia tabel testowych i zestawów danych. Najczęstsza niejawna konwersja po stronie kolumny, którą widzę jako konsultant, występuje, gdy typ kolumny to char lub varchar, a kod aplikacji przekazuje parametr, który jest nchar lub nvarchar i filtruje w kolumnie char lub varchar. Aby zasymulować tego typu scenariusz, utworzyłem kopię tabeli SalesOrderDetail (o nazwie SalesOrderDetail_ASCII) i zmieniłem kolumnę CarrierTrackingNumber z nvarchar na varchar. Dodatkowo dodałem indeks nieklastrowy w kolumnie CarrierTrackingNumber do oryginalnej tabeli SalesOrderDetail, a także nowej tabeli SalesOrderDetail_ASCII.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO Nowa tabela SalesOrderDetail_ASCII ma 121 317 wierszy i ma rozmiar 17,5 MB i będzie używana do oceny narzutu małej tabeli. Utworzyłem również dziesięciokrotnie większą tabelę, używając zmodyfikowanej wersji skryptu Enlarging the AdventureWorks Sample Databases z mojego bloga, który zawiera 1 334 487 wierszy i ma rozmiar 190 MB. Serwerem testowym jest ta sama 4 vCPU VM z 4 GB RAM, z systemem Windows Server 2008 R2 i SQL Server 2012, z dodatkiem Service Pack 1 i aktualizacją zbiorczą 3, z której korzystałem w poprzednich artykułach, więc tabele zmieszczą się w całości w pamięci , eliminując obciążenie we/wy dysku, które nie ma wpływu na wykonywane testy.
Testowe obciążenie zostało wygenerowane przy użyciu serii skryptów programu PowerShell, które wybierają listę CarrierTrackingNumbers z tabeli SalesOrderDetail tworzącej ArrayList, a następnie losowo wybierają CarrierTrackingNumber z ArrayList, aby wykonać zapytanie do tabeli SalesOrderDetail_ASCII przy użyciu parametru varchar, a następnie parametru nvarchar, oraz następnie wykonać zapytanie do tabeli SalesOrderDetail przy użyciu parametru nvarchar, aby zapewnić porównanie, w którym zarówno kolumna, jak i parametr są nvarchar. Każdy z poszczególnych testów uruchamia instrukcję 10 000 razy, aby umożliwić pomiar ogólnych kosztów wydajności przy długotrwałym obciążeniu.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Drugi zestaw testów został uruchomiony w odniesieniu do tabel SalesOrderDetailEnlarged_ASCII i SalesOrderDetailEnlarged przy użyciu tej samej parametryzacji co pierwszy zestaw testów, aby pokazać różnicę narzutu w miarę wzrostu rozmiaru danych przechowywanych w tabeli. Ostateczny zestaw testów został również uruchomiony względem tabeli SalesOrderDetail przy użyciu kolumny ProductID jako kolumny filtru z typami parametrów int, bigint, a następnie smallint, aby zapewnić porównanie narzutu niejawnych konwersji, które nie powodują skanowania indeksu do porównania.
Uwaga:Wszystkie skrypty są dołączone do tego artykułu, aby umożliwić odtworzenie niejawnych testów konwersji w celu dalszej oceny i porównania.
Wyniki testu
Podczas każdego wykonania testu Monitor wydajności był konfigurowany do uruchamiania zestawu modułów zbierających dane, który zawierał liczniki Processor\% Processor Time i SQL Server:SQLStatisitics\Batch Requests/s w celu śledzenia obciążenia wydajności dla każdego z testów. Dodatkowo, zdarzenia rozszerzone zostały skonfigurowane do śledzenia zdarzenia rpc_completed, aby umożliwić śledzenie średniego czasu trwania, cpu_time i odczytów logicznych dla każdego z testów.
Small Table CarrierTrackingNumber Wyniki
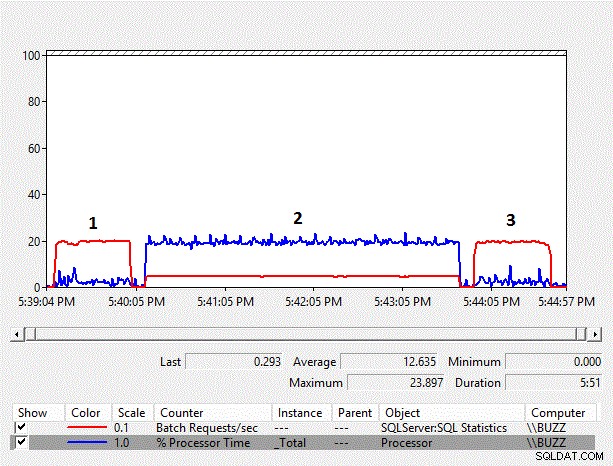
Rysunek 1 – Wykres liczników monitora wydajności
| TestID | Typ danych kolumny | Typ danych parametru | Śr. % czasu procesora | Śr. żądań zbiorczych/s | Czas trwania h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2,5 | 192,3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19,4 | 46,7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192,3 | 0:00:51 |
Tabela 2 – Średnie dane z Monitora wydajności
Na podstawie wyników widać, że niejawna konwersja po stronie kolumny z varchar na nvarchar i wynikowe skanowanie indeksu ma znaczący wpływ na wydajność obciążenia. Średni % czasu procesora dla testu niejawnej konwersji po stronie kolumny (TestID =2) jest prawie dziesięciokrotnie dłuższy niż w przypadku innych testów, w których nie wystąpiła niejawna konwersja po stronie kolumny, skutkująca skanowaniem indeksu. Ponadto średnia Żądań wsadowych na sekundę dla testu niejawnej konwersji po stronie kolumny wynosiła nieco poniżej 25% innych testów. Czas trwania testów, w których nie wystąpiły niejawne konwersje, trwał 51 sekund, mimo że dane były przechowywane jako nvarchar w teście nr 3 przy użyciu typu danych nvarchar, co wymagało dwukrotnie większej ilości miejsca do przechowywania. Jest to oczekiwane, ponieważ tabela jest nadal mniejsza niż pula buforów.
| TestID | Średni czas procesora (µs) | Średni czas trwania (µs) | Średnie logiczne_odczyty |
|---|---|---|---|
| 1 | 40,7 | 154,9 | 51,6 |
| 2 | 15 640,8 | 15 760,0 | 385,6 |
| 3 | 45,3 | 169,7 | 52,7 |
Tabela 3 – Średnie zdarzenia rozszerzone
Dane zebrane przez zdarzenie rpc_completed w zdarzeniach rozszerzonych pokazują, że średni czas_cpu, czas trwania i odczyty logiczne skojarzone z zapytaniami, które nie wykonują niejawnej konwersji po stronie kolumny, są w przybliżeniu równoważne, gdzie niejawna konwersja po stronie kolumny wiąże się ze znacznym obciążeniem procesora narzut, a także dłuższy średni czas trwania i znacznie więcej logicznych odczytów.
Wyniki w powiększeniu tabeli CarrierTrackingNumber
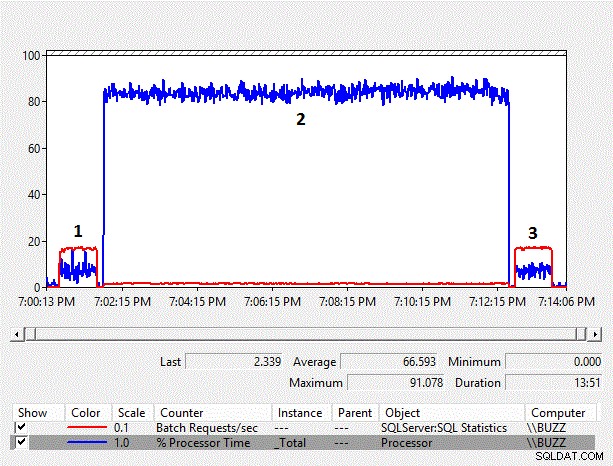
Rysunek 4 – Wykres liczników monitora wydajności
| TestID | Typ danych kolumny | Typ danych parametru | Śr. % czasu procesora | Śr. żądań zbiorczych/s | Czas trwania h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164.0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83,8 | 15,4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166,7 | 0:01:00 |
Tabela 5 – Średnie dane z Monitora wydajności
Wraz ze wzrostem rozmiaru danych zwiększa się również obciążenie wydajności niejawnej konwersji po stronie kolumny. Średni % czasu procesora dla testu niejawnej konwersji po stronie kolumny (TestID =2) jest znowu prawie dziesięciokrotnie dłuższy niż w innych testach, w których nie wystąpiła niejawna konwersja po stronie kolumny, skutkująca skanowaniem indeksu. Ponadto średnia Żądań wsadowych na sekundę dla testu niejawnej konwersji po stronie kolumny wynosiła nieco poniżej 10% innych testów. Czas trwania testów, w których nie wystąpiły niejawne konwersje, zajął jedną minutę, podczas gdy test niejawnej konwersji po stronie kolumny wymagał prawie jedenastu minut na wykonanie.
| TestID | Średni czas procesora (µs) | Średni czas trwania (µs) | Średnie logiczne_odczyty |
|---|---|---|---|
| 1 | 728,5 | 1036,5 | 569.6 |
| 2 | 214 174,6 | 59 519,1 | 4358,2 |
| 3 | 821,5 | 1032,4 | 553,5 |
Tabela 6 – Średnie zdarzenia rozszerzone
Wyniki zdarzeń rozszerzonych naprawdę zaczynają pokazywać obciążenie wydajności spowodowane przez niejawne konwersje po stronie kolumny dla obciążenia. Średni czas cpu_time na wykonanie przeskakuje do ponad 214 ms i jest ponad 200 razy dłuższy niż czas_cpu dla instrukcji, które nie mają niejawnych konwersji po stronie kolumny. Czas trwania jest również prawie 60 razy dłuższy niż w przypadku stwierdzeń, które nie zawierają niejawnych konwersji po stronie kolumny.
Podsumowanie
Wraz ze wzrostem rozmiaru danych obciążenie związane z niejawnymi konwersjami po stronie kolumny, które skutkują skanowaniem indeksu pod kątem obciążenia, również będzie rosło, a ważną rzeczą do zapamiętania jest to, że w pewnym momencie nie będzie żadnej ilości sprzętu będzie w stanie poradzić sobie z narzutem na wydajność. Konwersje niejawne są łatwe do uniknięcia, gdy istnieje dobry projekt schematu bazy danych, a programiści stosują dobre techniki kodowania aplikacji. W sytuacjach, w których praktyki kodowania aplikacji powodują parametryzację, która wykorzystuje parametryzację nvarchar, lepiej jest dopasować projekt schematu bazy danych do parametryzacji zapytania niż używać kolumn varchar w projekcie bazy danych i ponosić narzuty na wydajność z niejawnej konwersji po stronie kolumny.
Pobierz skrypty demonstracyjne:Implicit_Conversion_Tests.zip (5 KB)