W przypadku każdej nowej bazy danych utworzonej w SQL Server domyślną wartością opcji statystyki automatycznej aktualizacji jest włączona . Podejrzewam, że większość administratorów baz danych pozostawia tę opcję włączoną, ponieważ pozwala ona optymalizatorowi automatycznie aktualizować statystyki, gdy są one unieważniane, i ogólnie zaleca się pozostawienie jej włączonej. Statystyki są również aktualizowane podczas przebudowy indeksów i chociaż nierzadko zdarza się, że statystyki są dobrze zarządzane za pomocą opcji automatycznej aktualizacji statystyk i przebudowy indeksów, od czasu do czasu administrator danych może uznać za konieczne skonfigurowanie regularnego zadania aktualizacji statystyka lub zestaw statystyk.
Niestandardowe zarządzanie statystykami często wiąże się z poleceniem UPDATE STATISTICS, które wydaje się dość łagodne. Można go uruchomić dla wszystkich statystyk dla tabeli lub widoku indeksowanego lub dla określonej statystyki. Można użyć próbki domyślnej, można określić określoną częstotliwość próbkowania lub liczbę wierszy do próbkowania lub można użyć tej samej wartości próbki, która była używana wcześniej. Jeśli statystyki są aktualizowane dla tabeli lub widoku indeksowanego, możesz zaktualizować wszystkie statystyki, tylko statystyki indeksowania lub tylko statystyki kolumn. I na koniec możesz wyłączyć opcję automatycznej aktualizacji statystyk dla statystyki.
W przypadku większości administratorów baz danych najważniejszą kwestią może być kiedy aby uruchomić instrukcję UPDATE STATISTICS. Ale administratorzy baz danych decydują również, świadomie lub nie, o wielkości próbki do aktualizacji. Wybrana wielkość próbki może wpłynąć na wydajność aktualnej aktualizacji, a także na wydajność zapytań.
Zrozumienie wpływu wielkości próbki
Domyślny rozmiar próbki dla UPDATE STATISTICS pochodzi z nieliniowego algorytmu, a rozmiar próbki zmniejsza się wraz ze wzrostem rozmiaru tabeli, jak wykazał Joe Sack w swoim poście, Auto-Update Stats Default Sampling Test. W niektórych przypadkach wielkość próbki może nie być wystarczająco duża, aby uchwycić wystarczającą ilość interesujących informacji lub właściwa informacje dotyczące histogramu statystycznego, jak zauważył Conor Cunningham w swoim poście dotyczącym statystyk próbkowania. Jeśli próbka domyślna nie tworzy dobrego histogramu, administratorzy baz danych mogą wybrać aktualizację statystyk z wyższą częstotliwością próbkowania, aż do FULLSCAN (skanowanie wszystkich wierszy w tabeli lub widoku indeksowanym). Jak jednak Conor wspomniał w swoim poście, skanowanie większej liczby wierszy wiąże się z pewnymi kosztami, a DBA stoi przed wyzwaniem podjęcia decyzji, czy uruchomić FULLSCAN, aby spróbować stworzyć „najlepszy” możliwy histogram, czy próbkować mniejszy procent, aby zminimalizować wpływ na wydajność aktualizacja.
Aby spróbować zrozumieć, w którym momencie próbka zajmuje więcej czasu niż FULLSCAN, uruchomiłem następujące instrukcje w odniesieniu do kopii tabeli SalesOrderDetail, które zostały powiększone za pomocą skryptu Jonathana Kehayiasa:
| identyfikator wyciągu | Oświadczenie UPDATE STATISTICS |
|---|---|
| 1 | AKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPowiększone] Z FULLSCAN; |
| 2 | ZAKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPoszerzone]; |
| 3 | ZAKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPoszerzony] Z PRÓBKĄ 10 PROCENT; |
| 4 | ZAKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPowiększone] O PRÓBĘ 25 PROCENT; |
| 5 | ZAKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPowiększone] Z PRÓBKĄ 50 PROCENT; |
| 6 | ZAKTUALIZUJ STATYSTYKI [Sprzedaż].[SprzedażSzczegółyZamówieniaPowiększone] Z PRÓBĄ 75 PROCENT; |
Miałem trzy kopie tabeli SalesOrderDetailEnlarged o następujących cechach*:
| Liczba wierszy | Liczba stron | MAXDOP | Maksymalna pamięć | Pamięć | Maszyna |
|---|---|---|---|---|---|
| 23 899 449 | 363,284 | 4 | 8 GB | SSD_1 | Laptop |
| 607 312 902 | 7757200 | 16 | 54 GB | SSD_2 | Serwer testowy |
| 607 312 902 | 7757200 | 16 | 54 GB | 15 tys. | Serwer testowy |
*Dodatkowe szczegóły dotyczące sprzętu znajdują się na końcu tego posta.
Wszystkie kopie tabeli miały następujące statystyki, a żadna z trzech statystyk indeksu nie zawierała kolumn:
| Statystyka | Typ | Kolumny w kluczu |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Indeks | IDZamówieniaSprzedaży, IDSzczegółówZamówieniaSprzedaży |
| AK_SalesOrderDetailEnlarged_rowguid | Indeks | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Indeks | Identyfikator produktu |
| user_CarrierTrackingNumber | Kolumna | Numer śledzenia przewoźnika |
Powyższą instrukcję UPDATE STATISTICS uruchomiłem cztery razy w odniesieniu do tabeli SalesOrderDetailEnlarged na moim laptopie i dwa razy w odniesieniu do tabel SalesOrderDetailEnlarged na serwerze TestServer. Instrukcje były uruchamiane za każdym razem w losowej kolejności, a pamięć podręczna procedur i bufor były czyszczone przed każdą instrukcją aktualizacji. Czas trwania i użycie bazy danych tempdb dla każdego zestawu instrukcji (uśrednione) przedstawiono na poniższych wykresach:
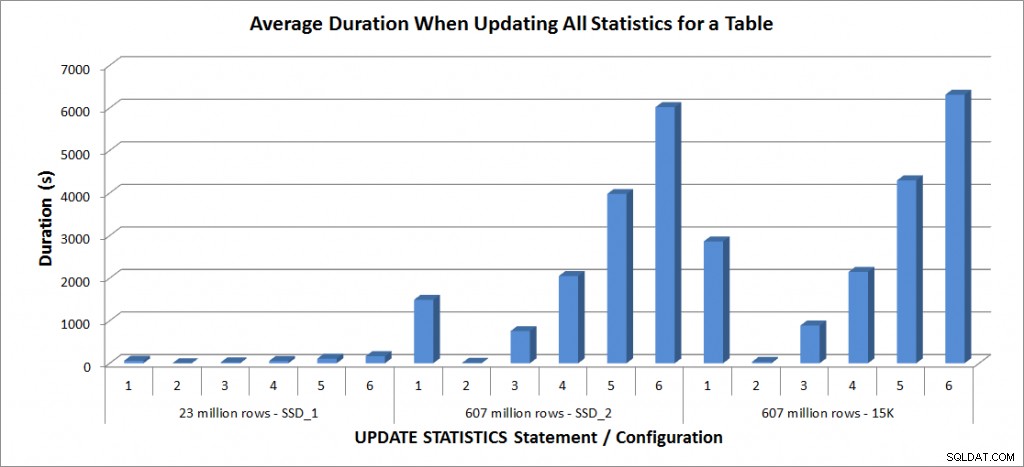
Średni czas trwania – zaktualizuj wszystkie statystyki dla SalesOrderDetailEnlarged
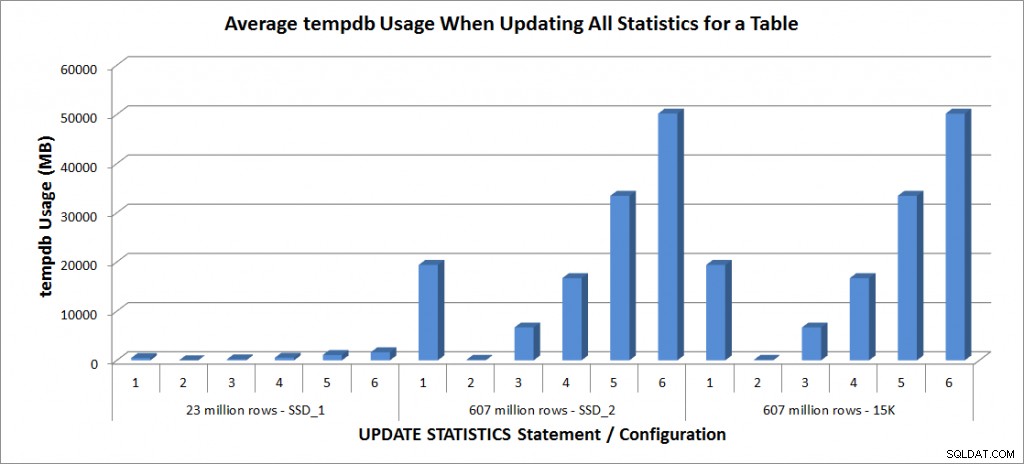
tempdb Użycie — zaktualizuj wszystkie statystyki dotyczące SalesOrderDetailEnlarged
Wszystkie czasy trwania dla tabeli 23 milionów wierszy były krótsze niż trzy minuty i zostały opisane bardziej szczegółowo w następnej sekcji. W przypadku tabeli na dyskach SSD_2 instrukcja FULLSCAN zajęła 1492 sekund (prawie 25 minut), a aktualizacja z 25% próbką zajęła 2051 sekund (ponad 34 minuty). W przeciwieństwie do tego, na dyskach 15K instrukcja FULLSCAN zajęła 2864 sekundy (ponad 47 minut), a aktualizacja z 25% próbką zajęła 2147 sekund (prawie 36 minut) – mniej niż czas FULLSCAN. Jednak aktualizacja z próbką 50% zajęła 4296 sekund (ponad 71 minut).
Użycie tempdb jest znacznie bardziej spójne, pokazując stały wzrost wraz ze wzrostem rozmiaru próbki i używając więcej miejsca tempdb niż FULLSCAN gdzieś między 25% a 50%. Godne uwagi jest to, że UPDATE STATISTICS robi użyj tempdb, o czym należy pamiętać podczas dopasowywania tempdb do środowiska SQL Server. Użycie Tempdb jest wymienione we wpisie UPDATE STATISTICS BOL:
AKTUALIZACJA STATYSTYK może używać tempdb do sortowania próbek wierszy w celu budowania statystyk”.
Efekt jest udokumentowany w poście Linchi Shea, Wpływ na wydajność:tempdb i statystyki aktualizacji. Jednak nie jest to coś, o czym zawsze wspomina się podczas dyskusji na temat rozmiaru tempdb. Jeśli masz duże tabele i przeprowadzasz aktualizacje za pomocą FULLSCAN lub wysokich wartości przykładowych, pamiętaj o użyciu tempdb.
Wydajność selektywnych aktualizacji
Następnie zdecydowałem się przetestować instrukcje UPDATE STATISTICS dla innych statystyk w tabeli, ale ograniczyłem testy do kopii tabeli zawierającej 23 miliony wierszy. Powyższe sześć odmian zestawienia UPDATE STATISTICS zostało powtórzonych cztery razy dla następujących indywidualnych statystyk, a następnie porównane z aktualizacją dla całej tabeli:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Wszystkie testy zostały przeprowadzone z wyżej wymienioną konfiguracją na moim laptopie, a wyniki są na poniższym wykresie:
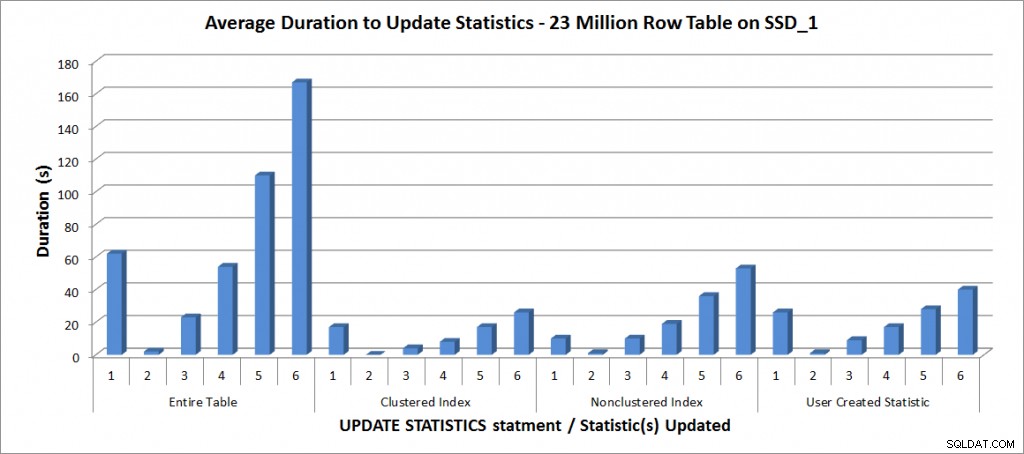
Średni czas trwania AKTUALIZACJI STATYSTYK – Wszystkie statystyki a wybrane
Zgodnie z oczekiwaniami aktualizacje poszczególnych statystyk zajęły mniej czasu niż aktualizowanie wszystkich statystyk w tabeli. Wartość, przy której próbkowana aktualizacja trwała dłużej niż zmieniała się FULLSCAN:
| Oświadczenie UPDATE | Czas trwania FULLSCAN (s) | Pierwsza AKTUALIZACJA, która trwała dłużej |
|---|---|---|
| Cała tabela | 62 | 50% – 110 sekund |
| Indeks klastrowy | 17 | 75% – 26 sekund |
| Indeks nieklastrowany | 10 | 25% – 19 sekund |
| Statystyka utworzona przez użytkowników | 26 | 50% – 28 sekund |
Wniosek
Na podstawie tych danych oraz danych FULLSCAN z 607 milionów tabel wierszy nie ma konkretnych punkt krytyczny, w którym próbkowana aktualizacja trwa dłużej niż FULLSCAN; ten punkt jest zależny od rozmiaru tabeli i dostępnych zasobów. Ale dane są nadal warte zachodu, ponieważ pokazują, że jest punkt, w którym przechwycenie wartości próbki może zająć więcej czasu niż FULLSCAN. Znowu sprowadza się do znajomości swoich danych. Ma to kluczowe znaczenie nie tylko dla zrozumienia, czy tabela wymaga niestandardowego zarządzania statystykami, ale także dla zrozumienia idealnej wielkości próbki, aby utworzyć użyteczny histogram, a także zoptymalizować wykorzystanie zasobów.
Specyfikacje
Specyfikacja laptopa:Dell M6500, 1 Intel i7 (2.13GHz 4 rdzenie i HT jest włączony, czyli 8 rdzeni logicznych), pamięć 32 GB, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), pliki bazy danych przechowywane na 265GB Samsung SSD PM810Specyfikacje serwera testowego:Dell R720, 2 Intel E5-2670 (włączone 2,6 GHz 8 rdzeni i HT, czyli 16 rdzeni logicznych na gniazdo), pamięć 64 GB, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), pliki bazy danych dla jeden stół znajduje się na dwóch kartach Fusion-io Duo MLC o pojemności 640 GB, pliki bazy danych dla drugiego stołu znajdują się na dziewięciu dyskach 15 tys. obr./min w macierzy RAID5