Wprowadzenie
Od czasu ich wprowadzenia w SQL Server 2005, funkcje okien takie jak ROW_NUMBER i RANK okazały się niezwykle przydatne w rozwiązywaniu wielu typowych problemów T-SQL. Próbując uogólnić takie rozwiązania, projektanci baz danych często starają się włączyć je do widoków w celu promowania enkapsulacji i ponownego wykorzystania kodu. Niestety ograniczenia w optymalizatorze zapytań SQL Server często oznaczają, że widoki zawierające funkcje okien nie działają tak dobrze, jak oczekiwano. Ten post przedstawia ilustracyjny przykład problemu, szczegółowo opisuje przyczyny i zawiera szereg obejść.
Ten problem może również wystąpić w tabelach pochodnych, typowych wyrażeniach tabelowych i funkcjach wbudowanych, ale widzę go najczęściej w widokach, ponieważ są one celowo napisane jako bardziej ogólne.
Funkcje okien
Funkcje okien wyróżniają się obecnością OVER() klauzula i występują w trzech odmianach:
- Funkcje okna rankingowego
ROW_NUMBERRANKDENSE_RANKNTILE
- Agregacja funkcji okna
MIN,MAX,AVG,SUMCOUNT,COUNT_BIGCHECKSUM_AGGSTDEV,STDEVP,VAR,VARP
- Funkcje okna analitycznego
LAG,LEADFIRST_VALUE,LAST_VALUEPERCENT_RANK,PERCENTILE_CONT,PERCENTILE_DISC,CUME_DIST
Funkcje rankingu i okna agregacji zostały wprowadzone w SQL Server 2005 i znacznie rozszerzone w SQL Server 2012. Funkcje okna analitycznego są nowością w SQL Server 2012.
Wszystkie wymienione powyżej funkcje okna są podatne na ograniczenia optymalizatora opisane w tym artykule.
Przykład
Korzystając z przykładowej bazy danych AdventureWorks, aktualnym zadaniem jest napisanie zapytania zwracającego wszystkie transakcje produktu nr 878, które miały miejsce w ostatnim dostępnym dniu. Istnieje wiele sposobów wyrażenia tego wymagania w T-SQL, ale my zdecydujemy się napisać zapytanie, które używa funkcji okienkowania. Pierwszym krokiem jest znalezienie rekordów transakcji dla produktu nr 878 i uszeregowanie ich w kolejności dat malejąco:
SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( ORDER BY th.TransactionDate DESC)FROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY rnk;
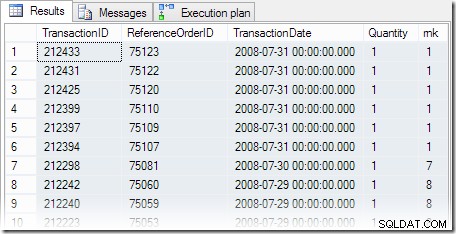

Wyniki zapytania są zgodne z oczekiwaniami, a sześć transakcji miało miejsce w ostatnim dostępnym terminie. Plan wykonania zawiera trójkąt ostrzegawczy, ostrzegający nas o braku indeksu:

Jak zwykle w przypadku braku sugestii dotyczących indeksu, należy pamiętać, że rekomendacja nie jest wynikiem dokładnej analizy zapytania – jest to raczej wskazówka, że musimy się zastanowić, w jaki sposób to zapytanie uzyskuje dostęp do potrzebnych danych.
Sugerowany indeks byłby z pewnością bardziej wydajny niż pełne skanowanie tabeli, ponieważ umożliwiłby indeksowanie do konkretnego produktu, który nas interesuje. Indeks obejmowałby również wszystkie potrzebne kolumny, ale nie uniknąłby sortowania (o TransactionDate malejąco). Idealny indeks dla tego zapytania umożliwiłby wyszukanie ProductID , zwróć wybrane rekordy w odwrotnej kolejności TransactionDate zamówienia i zakryj pozostałe zwrócone kolumny:
UTWÓRZ INDEKS NIESKLASTRAROWANY ixON Production.TransactionHistory (ProductID, TransactionDate DESC)INCLUDE (ReferenceOrderID, Quantity);
Mając taki indeks, plan wykonania jest znacznie bardziej wydajny. Skanowanie indeksu klastrowego zostało zastąpione przeszukiwaniem zakresu, a sortowanie jawne nie jest już konieczne:

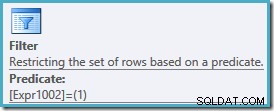
Ostatnim krokiem dla tego zapytania jest ograniczenie wyników tylko do tych wierszy, które mają 1. pozycję. Nie możemy filtrować bezpośrednio w WHERE klauzuli naszego zapytania, ponieważ funkcje okna mogą pojawić się tylko w SELECT i ORDER BY klauzule.
Możemy obejść to ograniczenie za pomocą tabeli pochodnej, wspólnego wyrażenia tabelowego, funkcji lub widoku. Przy tej okazji użyjemy wspólnego wyrażenia tabelowego (aka widoku wbudowanego):
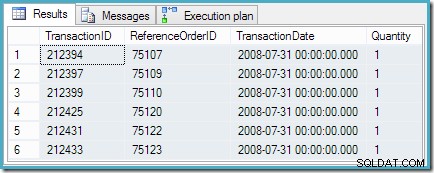
Z RankedTransactions AS( SELECT th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER (ORDER BY th.TransactionDate DESC) FROM Production.TransactionHistory AS th WHERE th.ProductID =878 )SELECT ID transakcji, ID zamówienia referencyjnego, data transakcji, ilośćFROM ranking transakcjiWHERE rnk =1;
Plan wykonania jest taki sam jak poprzednio, z dodatkowym filtrem zwracającym tylko wiersze w rankingu nr 1:

Zapytanie zwraca sześć oczekiwanych wierszy o równych pozycjach:
Uogólnianie zapytania
Okazuje się, że nasze zapytanie jest bardzo przydatne, więc zapada decyzja o jego uogólnieniu i przechowywaniu definicji w widoku. Aby to zadziałało dla dowolnego produktu, musimy zrobić dwie rzeczy:zwrócić ProductID z widoku i podziel funkcję rankingową według produktu:
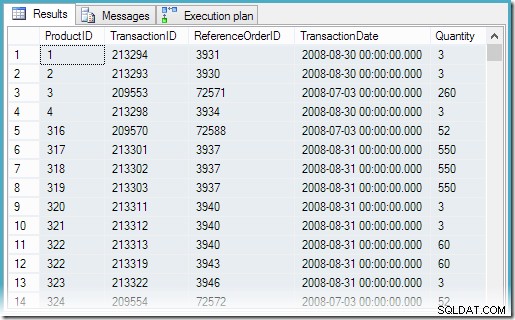
CREATE VIEW dbo.MostRecentTransactionsPerProductZ POWIĄZANIEM SCHEMATUASSELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.QuantityFROM ( SELECT th.ProductID, th.TransactionID, th.ReferenceOrderID.Transaction, th. rnk =RANK() OVER ( PARTITION BY th.ProductID ORDER BY th.TransactionDate DESC) Z Production.TransactionHistory AS th) AS sq1WHERE sq1.rnk =1;
Wybranie wszystkich wierszy z widoku skutkuje następującym planem wykonania i poprawnymi wynikami:

Teraz możemy znaleźć najnowsze transakcje dla produktu 878 za pomocą znacznie prostszego zapytania w widoku:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;
Oczekujemy, że plan wykonania dla tego nowego zapytania będzie dokładnie taki sam, jak przed utworzeniem widoku. Optymalizator zapytań powinien być w stanie wypchnąć filtr określony w WHERE klauzulę w dół do widoku, co skutkuje wyszukiwaniem indeksu.
W tym momencie musimy się jednak zatrzymać i trochę pomyśleć. Optymalizator zapytań może generować tylko plany wykonania, które gwarantują te same wyniki, co specyfikacja zapytania logicznego — czy bezpiecznie jest wypchnąć nasze WHERE do widoku?
Plan wykonania SQL Server 2005

Spojrzenie na właściwości filtra w tym planie pokazuje, że stosuje się dwa predykaty:
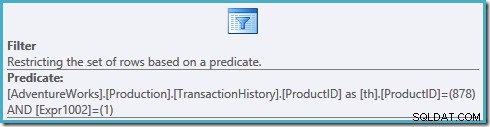
ProductID = 878 predykat nie został przesunięty w dół do widoku, w wyniku czego powstał plan, który skanuje nasz indeks, klasyfikując każdy wiersz w tabeli przed filtrowaniem pod kątem produktu nr 878 i wierszy z rankingiem nr 1.
Optymalizator zapytań SQL Server 2005 nie może wypchnąć odpowiednich predykatów poza funkcję okna w niższym zakresie zapytania (widok, wspólne wyrażenie tabelowe, funkcja wbudowana lub tabela pochodna). To ograniczenie dotyczy wszystkich wersji SQL Server 2005.
Plan wykonania SQL Server 2008+
To jest plan wykonania tego samego zapytania w SQL Server 2008 lub nowszym:

ProductID predykat został pomyślnie wypchnięty poza operatory rankingu, zastępując skanowanie indeksu efektywnym wyszukiwaniem indeksu.
Optymalizator zapytań 2008 zawiera nową regułę upraszczania SelOnSeqPrj (wybierz w projekcie sekwencji), który jest w stanie wypchnąć bezpieczne predykaty z zakresu zewnętrznego, przeszłe funkcje okna. Aby stworzyć mniej wydajny plan dla tego zapytania w SQL Server 2008 lub nowszym, musimy tymczasowo wyłączyć tę funkcję optymalizatora zapytań:
SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878OPTION (QUERYRULEOFF SelOnSeqPrj);

Niestety, SelOnSeqPrj reguła uproszczenia działa tylko kiedy predykat dokonuje porównania ze stałą . Z tego powodu następujące zapytanie generuje suboptymalny plan w SQL Server 2008 i nowszych wersjach:
DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;

Problem może nadal występować nawet wtedy, gdy predykat używa stałej wartości. SQL Server może zdecydować o automatycznej parametryzacji trywialnych zapytań (takich, dla których istnieje oczywisty najlepszy plan). Jeśli automatyczna parametryzacja się powiedzie, optymalizator widzi parametr zamiast stałej, a SelOnSeqPrj reguła nie jest stosowana.
W przypadku zapytań, w których nie podjęto próby automatycznej parametryzacji (lub w przypadku stwierdzenia, że jest to niebezpieczne), optymalizacja może się nie powieść, jeśli opcja bazy danych dla FORCED PARAMETERIZATION jest włączony. Nasze zapytanie testowe (ze stałą wartością 878) nie jest bezpieczne dla automatycznej parametryzacji, ale ustawienie wymuszonej parametryzacji zastępuje to, co skutkuje nieefektywnym planem:
ALTER DATABASE AdventureWorksSET PARAMETERIZATION FORCED;GOSELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =878;GOALTERPPARAMETER BASE;
Obejście SQL Server 2008+
Aby umożliwić optymalizatorowi „zobaczenie” stałej wartości zapytania, które odwołuje się do zmiennej lokalnej lub parametru, możemy dodać
OPTION (RECOMPILE)wskazówka dotycząca zapytania:DECLARE @ProductID INT =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductIDOPTION (RECOMPILE);Uwaga: Plan wykonania przed wykonaniem („szacowany”) nadal pokazuje skanowanie indeksu, ponieważ wartość zmiennej nie jest jeszcze ustawiona. Gdy zapytanie jest wykonane , jednak plan wykonania pokazuje pożądany plan wyszukiwania indeksu:
SelOnSeqPrjreguła nie istnieje w SQL Server 2005, więcOPTION (RECOMPILE)nie mogę tam pomóc. Jeśli się zastanawiasz,OPTION (RECOMPILE)obejście skutkuje wyszukiwaniem, nawet jeśli opcja bazy danych dla wymuszonej parametryzacji jest włączona.Wszystkie wersje obejścia nr 1
W niektórych przypadkach można zastąpić problematyczny widok, wspólne wyrażenie tabelowe lub tabelę pochodną sparametryzowaną funkcją z wartościami tabelarycznymi w wierszu:
CREATE FUNCTION dbo.MostRecentTransactionsForProduct( @ProductID integer) ZWRACA TABELĘ Z SCHEMATEM ASRETURN SELECT sq1.ProductID, sq1.TransactionID, sq1.ReferenceOrderID, sq1.TransactionDate, sq1.Quantity FROM ( SELECT th.TransactionID, th. ReferenceOrderID, th.TransactionDate, th.Quantity, rnk =RANK() OVER ( PARTITION BY th.ProductID ORDER BY th.TransactionDate DESC) FROM Production.TransactionHistory AS th WHERE th.ProductID =@ProductID ) AS sq1 WHERE sq1.rnk =1;Ta funkcja jawnie umieszcza
ProductIDpredykat w tym samym zakresie co funkcja okna, unikając ograniczenia optymalizatora. Napisane w celu użycia funkcji wbudowanej, nasze przykładowe zapytanie ma postać:SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsForProduct(878) AS mrt;Daje to żądany plan wyszukiwania indeksu we wszystkich wersjach SQL Server obsługujących funkcje okna. To obejście tworzy wyszukiwanie nawet tam, gdzie predykat odwołuje się do parametru lub zmiennej lokalnej —
OPTION (RECOMPILE)nie jest wymagane.PARTITION BY klauzuli i nie zwracać już ProductIDkolumna. Pozostawiłem definicję taką samą, jak widok, który zastąpiła, aby wyraźniej zilustrować przyczynę różnic w planie wykonania.Obejście dla wszystkich wersji #2
Drugie obejście dotyczy tylko rankingowych funkcji okna, które są filtrowane w celu zwrócenia wierszy ponumerowanych lub sklasyfikowanych jako #1 (przy użyciu
ROW_NUMBER,RANKlubDENSE_RANK). Jest to jednak bardzo powszechne zastosowanie, dlatego warto o nim wspomnieć.Dodatkową korzyścią jest to, że to obejście może stworzyć plany, które są jeszcze bardziej wydajne niż poprzednio widziane plany poszukiwania indeksu. Przypominamy, że poprzedni najlepszy plan wyglądał tak:
Ten plan wykonania zajmuje 1918 wierszy, mimo że ostatecznie zwraca tylko 6 . Możemy ulepszyć ten plan wykonania, używając funkcji okna w
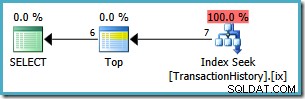
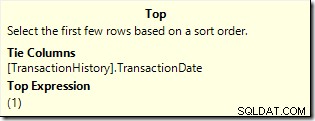
ORDER BYklauzula zamiast rankingu wierszy, a następnie filtrowania według pozycji nr 1:WYBIERZ TOP (1) Z POWIĄZANIAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY RANK() OVER ( ORDER BY th.TransactionDate DESC);
To zapytanie ładnie ilustruje użycie funkcji okna w
ORDER BYale możemy zrobić jeszcze lepiej, całkowicie eliminując funkcję okna:WYBIERZ TOP (1) Z POWIĄZANIAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.QuantityFROM Production.TransactionHistory AS thWHERE th.ProductID =878ORDER BY th.TransactionDate DESC;
Ten plan odczytuje tylko 7 wierszy z tabeli, aby zwrócić ten sam 6-wierszowy zestaw wyników. Dlaczego 7 rzędów? Operator Top działa w
WITH TIEStryb:
Kontynuuje żądanie jednego wiersza naraz ze swojego poddrzewa, aż do zmiany TransactionDate. Siódmy wiersz jest wymagany, aby Top miał pewność, że żadne wiersze o równej wartości się nie zakwalifikują.
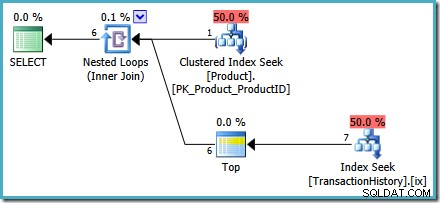
Możemy rozszerzyć logikę powyższego zapytania, aby zastąpić definicję problematycznego widoku:
ALTER VIEW dbo.NajbardziejOstatnietransakcjeNaProduktZ SCHEMATEMASSELECT p.IDProduktu,Load1.Identyfikator Transakcji,Load1.ReferenceOrderID,Load1.Data transakcji,Load1.IlośćFROM – Lista identyfikatorów produktów (SELECT ProductID FROM Production.Product) AS pCROSS APPLY( – Ranga zwrotu #1 wyniki dla każdego identyfikatora produktu WYBIERZ GÓRĘ (1) Z WIĘZAMI th.TransactionID, th.ReferenceOrderID, th.TransactionDate, th.Ilość FROM Production.TransactionHistory AS th GDZIE th.ProductID =p.ProductID ORDER BY th.TransactionDate DESC) AS w rankingu 1;Widok używa teraz
CROSS APPLYaby połączyć wyniki naszego zoptymalizowanegoORDER BYzapytanie dla każdego produktu. Nasze zapytanie testowe pozostaje niezmienione:DECLARE @ProductID liczba całkowita;SET @ProductID =878; SELECT mrt.ProductID, mrt.TransactionID, mrt.ReferenceOrderID, mrt.TransactionDate, mrt.QuantityFROM dbo.MostRecentTransactionsPerProduct AS mrt WHERE mrt.ProductID =@ProductID;Zarówno plany przed, jak i po realizacji pokazują wyszukiwanie indeksu bez potrzeby
OPTION (RECOMPILE)wskazówka zapytania. Poniżej znajduje się plan powykonawczy („rzeczywisty”):
Jeśli widok używał
ROW_NUMBERzamiastRANK, widok zastępujący po prostu pominąłbyWITH TIESklauzula naTOP (1). Nowy widok może być oczywiście napisany jako sparametryzowana wbudowana funkcja z wartościami tabelarycznymi.Można argumentować, że pierwotny plan wyszukiwania indeksu z
rnk = 1predykat można również zoptymalizować do testowania tylko 7 wierszy. W końcu optymalizator powinien wiedzieć, że rankingi są tworzone przez operatora Sequence Project w ścisłej kolejności rosnącej, więc wykonanie może zakończyć się, gdy tylko pojawi się wiersz z pozycją większą niż jeden. Jednak obecnie optymalizator nie zawiera tej logiki.Ostateczne myśli
Ludzie często są rozczarowani wydajnością widoków zawierających funkcje okien. Powód często może być związany z ograniczeniem optymalizatora opisanym w tym poście (lub być może dlatego, że projektant widoku nie zauważył, że predykaty zastosowane do widoku muszą pojawić się w
PARTITION BYklauzula bezpiecznego dociskania).Chcę podkreślić, że to ograniczenie dotyczy nie tylko widoków, ani nie ogranicza się do
ROW_NUMBER,RANKiDENSE_RANK. Powinieneś być świadomy tego ograniczenia podczas używania dowolnej funkcji zOVERklauzuli w widoku, wspólnym wyrażeniu tabelowym, tabeli pochodnej lub wbudowanej funkcji z wartościami w tabeli.Użytkownicy SQL Server 2005, którzy napotykają ten problem, stają przed wyborem przepisania widoku jako sparametryzowanej wbudowanej funkcji z wartościami tabelarycznymi lub użycia funkcji
APPLYtechnika (jeśli dotyczy).Użytkownicy SQL Server 2008 mają dodatkową opcję korzystania z
OPTION (RECOMPILE)wskazówka zapytania, jeśli problem można rozwiązać, umożliwiając optymalizatorowi wyświetlenie stałej zamiast odwołania do zmiennej lub parametru. Pamiętaj jednak, aby sprawdzić plany powykonawcze, korzystając z tej wskazówki:plan przedrealizacyjny nie może generalnie pokazywać optymalnego planu.