Zbyt często widzę ludzi narzekających na to, jak ich dziennik transakcji przejął ich dysk twardy. Wiele razy okazuje się, że wykonywali dużą operację usuwania, taką jak czyszczenie lub archiwizowanie danych, w jednej dużej transakcji.
Chciałem przeprowadzić kilka testów, aby pokazać wpływ, zarówno na czas trwania, jak i dziennik transakcji, wykonywania tej samej operacji na danych w porcjach w porównaniu z pojedynczą transakcją. Utworzyłem bazę danych i wypełniłem ją dużą tabelą SalesOrderDetailEnlarged ,
Po wypełnieniu tabeli wykonałem kopię zapasową bazy danych, dziennika i uruchomiłem DBCC SHRINKFILE (nie strzelaj do mnie), aby wpływ na plik dziennika mógł zostać ustalony na podstawie linii bazowej (dobrze wiedząc, że te operacje *spowodują* wzrost dziennika transakcji).
Celowo użyłem dysku mechanicznego, a nie SSD. Chociaż możemy zacząć dostrzegać bardziej popularny trend przechodzenia na dyski SSD, nie wydarzyło się to jeszcze na wystarczająco dużą skalę; w wielu przypadkach jest to nadal zbyt zaporowe, jeśli chodzi o duże urządzenia pamięci masowej.
Testy
Następnie musiałem określić, co chcę przetestować, aby uzyskać jak największy wpływ. Ponieważ wczoraj byłem zaangażowany w dyskusję ze współpracownikiem na temat usuwania danych porcjami, wybrałem usuwanie. A ponieważ indeks klastrowy w tej tabeli znajduje się pod adresem SalesOrderID , nie chciałem tego używać – byłoby to zbyt łatwe (i bardzo rzadko pasowałoby do sposobu, w jaki usuwa się usuwanie w prawdziwym życiu). Więc zamiast tego zdecydowałem się na serię ProductID wartości, które zapewniłyby, że trafiłbym na dużą liczbę stron i wymagałby dużo logowania. Określiłem, które produkty usunąć, na podstawie następującego zapytania:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Dało to następujące wyniki:
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Spowoduje to usunięcie 456 960 wierszy (około 10% tabeli), rozłożonych na wiele zamówień. W tym kontekście nie jest to realistyczna modyfikacja, ponieważ spowoduje to bałagan ze wstępnie obliczonymi sumami zamówień, a tak naprawdę nie można usunąć produktu z zamówienia, które zostało już wysłane. Ale korzystanie z bazy danych, którą wszyscy znamy i kochamy, jest analogiczne do, powiedzmy, usuwania użytkownika ze strony forum, a także usuwania wszystkich jego wiadomości – prawdziwy scenariusz, który widziałem na wolności.
Tak więc jednym testem byłoby wykonanie następującego, jednorazowego usunięcia:
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Wiem, że będzie to wymagało ogromnego skanowania i pochłonie ogromne straty w dzienniku transakcji. O to właśnie chodzi. :-)
Kiedy to było uruchomione, ułożyłem inny skrypt, który wykona to usuwanie porcjami:25 000, 50 000, 75 000 i 100 000 wierszy na raz. Każda porcja zostanie zatwierdzona w osobnej transakcji (tak, że jeśli musisz zatrzymać skrypt, możesz, a wszystkie poprzednie porcje zostaną już zatwierdzone, zamiast zaczynać od nowa) i, w zależności od modelu odzyskiwania, będą przestrzegane przez CHECKPOINT lub BACKUP LOG aby zminimalizować bieżący wpływ na dziennik transakcji. (Będę też testował bez tych operacji.) Będzie to wyglądało mniej więcej tak (nie będę zawracał sobie głowy obsługą błędów i innymi drobiazgami w tym teście, ale nie powinieneś być tak niefrasobliwy):
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Oczywiście po każdym teście przywracałem oryginalną kopię zapasową bazy danych WITH REPLACE, RECOVERY , ustaw odpowiednio model odzyskiwania i uruchom następny test.
Wyniki
Wynik pierwszego testu wcale nie był zaskakujący. Aby wykonać usunięcie w jednej instrukcji, zajęło to 42 sekundy w całości i 43 sekundy w prostych. W obu przypadkach spowodowało to wzrost dziennika do 579 MB.
Kolejny zestaw testów miał dla mnie kilka niespodzianek. Jednym z nich jest to, że chociaż te metody chunkingu znacznie zmniejszyły wpływ na plik dziennika, tylko kilka kombinacji było zbliżonych w czasie i żadna nie była tak naprawdę szybsza. Innym jest to, że generalnie chunking w pełnym odzyskiwaniu (bez wykonywania kopii zapasowej dziennika między krokami) działał lepiej niż równoważne operacje w prostym odzyskiwaniu. Oto wyniki dotyczące czasu trwania i wpływu na dzienniki:
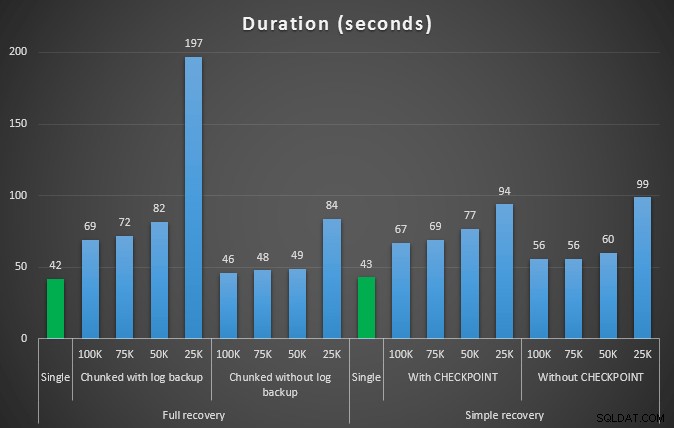
Czas trwania w sekundach różnych operacji usuwania usuwających 457 tys. wierszy
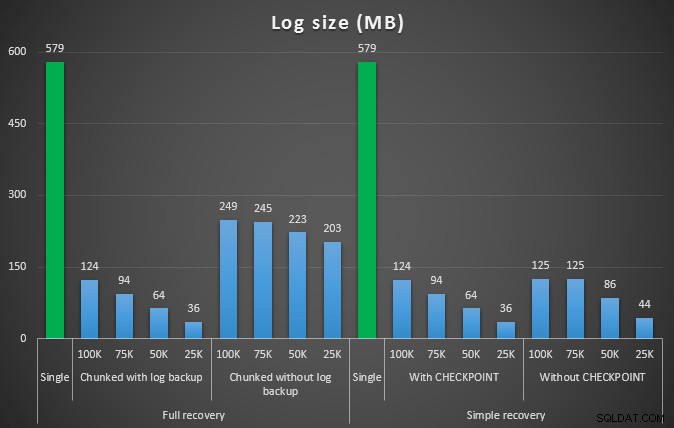
Rozmiar dziennika w MB po różnych operacjach usuwania usuwających 457 tys. wierszy
Ponownie, ogólnie rzecz biorąc, chociaż rozmiar dziennika jest znacznie zmniejszony, czas trwania jest zwiększony. Możesz użyć tego typu skali, aby określić, czy ważniejsze jest zmniejszenie wpływu na miejsce na dysku, czy też zminimalizowanie ilości spędzanego czasu. W przypadku niewielkiego czasu trwania (a w końcu większość tych procesów działa w tle), możesz uzyskać znaczne oszczędności (do 94% w tych testach) w wykorzystaniu przestrzeni dziennika.
Zwróć uwagę, że nie próbowałem żadnego z tych testów z włączoną kompresją (prawdopodobnie przyszły test!) i pozostawiłem ustawienia automatycznego powiększania dziennika na fatalne wartości domyślne (10%) – częściowo z lenistwa, a częściowo dlatego, że wiele środowisk tam zachowało to okropne ustawienie.
A jeśli mam więcej danych?
Następnie pomyślałem, że powinienem przetestować to na nieco większej bazie danych. Stworzyłem więc kolejną bazę danych i utworzyłem nową, większą kopię dbo.SalesOrderDetailEnlarged . Prawdę mówiąc, mniej więcej dziesięć razy większy. Tym razem zamiast klucza podstawowego w SalesOrderID, SalesorderDetailID , właśnie uczyniłem go indeksem klastrowym (aby umożliwić duplikaty) i wypełniłem go w ten sposób:
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); Ze względu na ograniczenia miejsca na dysku musiałem na potrzeby tego testu zdjąć maszynę wirtualną mojego laptopa (i wybrałem 40-rdzeniową skrzynkę ze 128 GB pamięci RAM, która akurat siedziała prawie bezczynnie :-)) i nadal w żadnym wypadku nie był to szybki proces. Wypełnianie tabeli i tworzenie indeksów zajęło ~24 minuty.
Tabela ma 48,5 miliona wierszy i zajmuje 7,9 GB na dysku (4,9 GB na dane i 2,9 GB na indeks).
Tym razem moje zapytanie w celu określenia dobrego zestawu kandydata ProductID wartości do usunięcia:
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Uzyskano następujące wyniki:
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Więc usuniemy 4455360 wierszy, czyli nieco poniżej 10% tabeli. Zgodnie z podobnym wzorcem do powyższego testu, usuniemy wszystko za jednym zamachem, a następnie w kawałkach po 500 000, 250 000 i 100 000 wierszy.
Wyniki:
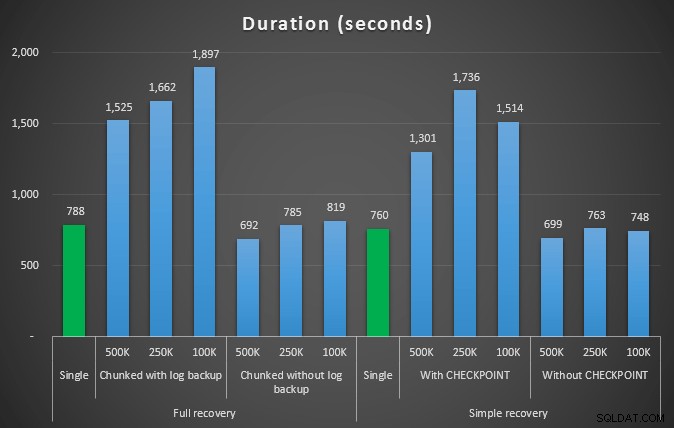 Czas (w sekundach) różnych operacji usuwania usuwających 4,5 mln wierszy
Czas (w sekundach) różnych operacji usuwania usuwających 4,5 mln wierszy
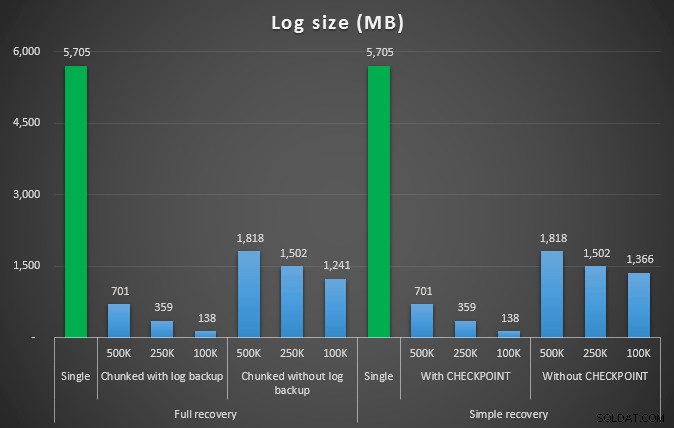 Rozmiar dziennika w MB po różnych operacjach usuwania usuwających 4,5 mln wierszy
Rozmiar dziennika w MB po różnych operacjach usuwania usuwających 4,5 mln wierszy
Tak więc znowu widzimy znaczne zmniejszenie rozmiaru pliku dziennika (ponad 97% w przypadkach z najmniejszym rozmiarem porcji 100 KB); jednak w tej skali widzimy kilka przypadków, w których usuwamy również w krótszym czasie, nawet przy wszystkich zdarzeniach autogrowu, które musiały mieć miejsce. To brzmi dla mnie bardzo jak wygrana-wygrana!
Tym razem z większym logiem
Teraz byłem ciekaw, jak te różne usunięcia można porównać z plikiem dziennika o wstępnie ustalonym rozmiarze, aby pomieścić tak duże operacje. Pozostając przy naszej większej bazie danych, wstępnie rozszerzyłem plik dziennika do 6 GB, wykonałem kopię zapasową, a następnie ponownie przeprowadziłem testy:
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Wyniki, porównując czas trwania ze stałym plikiem dziennika z przypadkiem, w którym plik musiał stale rosnąć automatycznie:
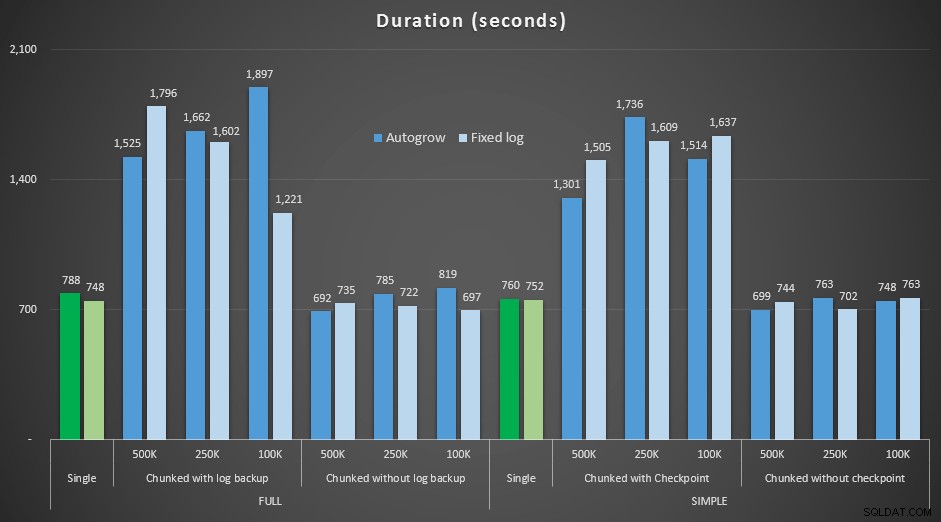
Czas trwania (w sekundach) różnych operacji usuwania usuwających 4,5 mln wierszy , porównując stały rozmiar dziennika i automatyczny wzrost
Ponownie widzimy, że metody, które usuwają porcje w partiach i *nie* wykonują kopii zapasowej dziennika lub punktu kontrolnego po każdym kroku, rywalizują z równoważną pojedynczą operacją pod względem czasu trwania. W rzeczywistości zobacz, że większość faktycznie działa w krótszym czasie, z dodatkową premią, że inne transakcje będą mogły wejść i wyjść między krokami. Co jest dobre, chyba że chcesz, aby ta operacja usuwania blokowała wszystkie niepowiązane transakcje.
Wniosek
Jasne jest, że nie ma jednej, poprawnej odpowiedzi na ten problem – istnieje wiele nieodłącznych zmiennych „to zależy”. Znalezienie magicznej liczby może wymagać trochę eksperymentów, ponieważ będzie zachowana równowaga między kosztami ogólnymi potrzebnymi do utworzenia kopii zapasowej dziennika a ilością pracy i czasu, którą można zaoszczędzić przy różnych rozmiarach porcji. Ale jeśli planujesz usunąć lub zarchiwizować dużą liczbę wierszy, jest całkiem prawdopodobne, że ogólnie rzecz biorąc, lepiej wyjdzie ci, przeprowadzając zmiany w porcjach, a nie w jednej, ogromnej transakcji – nawet jeśli liczby czasu trwania wydają się że mniej atrakcyjna operacja. Nie chodzi tylko o czas trwania – jeśli nie masz wystarczająco wstępnie przydzielonego pliku logu i nie masz miejsca, aby pomieścić tak ogromną transakcję, prawdopodobnie znacznie lepiej jest zminimalizować wzrost pliku logu kosztem czasu trwania, w takim przypadku zignoruj powyższe wykresy czasu trwania i zwróć uwagę na wykresy rozmiaru dziennika.
Jeśli możesz sobie pozwolić na miejsce, nadal możesz chcieć, ale nie musisz, odpowiednio dostosować rozmiar dziennika transakcji. W zależności od scenariusza, czasami użycie domyślnych ustawień autogrowu kończyło się w moich testach nieco szybciej niż używanie stałego pliku dziennika z dużą ilością miejsca. Ponadto może być trudno odgadnąć dokładnie, ile będziesz potrzebować, aby pomieścić dużą transakcję, której jeszcze nie uruchomiłeś. Jeśli nie możesz przetestować realistycznego scenariusza, postaraj się jak najlepiej wyobrazić sobie najgorszy scenariusz – a następnie, dla bezpieczeństwa, podwój go. Kimberly Tripp (blog | @KimberlyLTripp) ma świetną radę w tym poście:8 kroków do lepszej przepustowości dziennika transakcji – w tym kontekście spójrz na punkt #6. Niezależnie od tego, w jaki sposób zdecydujesz się obliczyć wymagania dotyczące miejsca na kłody, jeśli i tak będziesz potrzebować miejsca, lepiej zagospodaruj je w kontrolowany sposób z dużym wyprzedzeniem, niż zatrzymuj procesy biznesowe, gdy czekają na automatyczny wzrost ( nieważne wielokrotne!).
Innym bardzo ważnym aspektem tego, którego nie mierzyłem wyraźnie, jest wpływ na współbieżność – kilka krótszych transakcji będzie teoretycznie miało mniejszy wpływ na operacje równoległe. Chociaż pojedyncze usunięcie zajęło nieco mniej czasu niż dłuższe operacje wsadowe, utrzymywało wszystkie swoje blokady przez cały czas, podczas gdy operacje podzielone na fragmenty pozwalały innym transakcjom znajdującym się w kolejce wkraść się między każdą transakcją. W przyszłym poście postaram się przyjrzeć bliżej temu wpływowi (mam też plany na inną głębszą analizę).