Masz problemy z SQL UNION? Dzieje się tak, gdy wyniki, które połączyłeś, zatrzymają Twój SQL Server. Lub raport, który działał wcześniej, wyświetla okienko z czerwoną ikoną X. Wystąpił błąd „Zderzenie typu operandu” wskazujący na linię z UNION. Rozpoczyna się „ogień”. Brzmi znajomo?
Niezależnie od tego, czy korzystasz z SQL UNION od jakiegoś czasu, czy dopiero zaczynasz, ściągawka lub zwięzły zestaw notatek nie zaszkodzi. To właśnie dostaniesz dzisiaj w tym poście. Ta lista zawiera 10 przydatnych wskazówek zarówno dla początkujących, jak i weteranów. Będą również przykłady i zaawansowane dyskusje.

[sendpulse-form id=”11900″]
Ale zanim przejdziemy do pierwszego punktu, wyjaśnijmy warunki.
UNION jest jednym z operatorów zestawów w SQL, który łączy 2 lub więcej zestawów wyników. Może się przydać, gdy musisz połączyć nazwiska, miesięczne statystyki i więcej z różnych źródeł. Niezależnie od tego, czy używasz SQL Server, MySQL czy Oracle, cel, zachowanie i składnia będą bardzo podobne. Ale jak to działa?
1. Użyj programu SQL UNION, aby połączyć unikalne Rekordy
Używanie UNION do łączenia zestawów wyników usuwa duplikaty.
Dlaczego jest to ważne?
W większości przypadków nie chcesz wyników z duplikatami. Raport ze zduplikowanymi wierszami marnuje atrament i papier na wydruki. A to rozgniewa Twoich użytkowników.
Jak z niego korzystać
Łączysz wyniki instrukcji SELECT z UNION pomiędzy.
Zanim zaczniemy od przykładu, przygotujmy nasze przykładowe dane.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Będziemy korzystać z danych wygenerowanych przez powyższy kod do trzeciej wskazówki. Teraz, gdy jesteśmy gotowi, poniżej znajduje się przykład:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Mamy 3 kopie tych samych nazwisk klientów i spodziewamy się, że unikalne rekordy znikną. Zobacz wyniki:
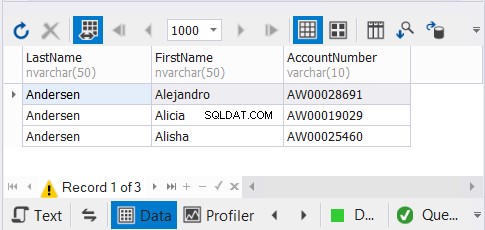
Rozwiązanie dbForge Studio dla SQL Server, którego używamy w naszych przykładach, pokazuje tylko 3 rekordy. Mogło to być 9. Stosując UNION, usunęliśmy duplikaty.
Jak to działa?
Diagram planu w dbForge Studio pokazuje, w jaki sposób SQL Server generuje wynik pokazany na rysunku 1. Spójrz:
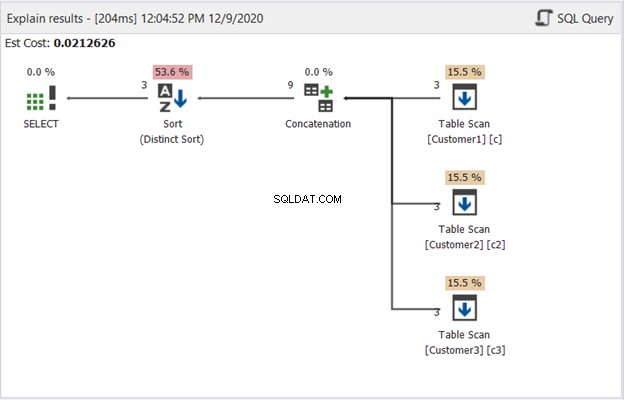
Aby zinterpretować rysunek 2, zacznij od prawej do lewej:
- Pobraliśmy 3 rekordy od każdego operatora skanowania tabeli. To są 3 instrukcje SELECT z powyższego przykładu. Każda linia wychodząca z niego pokazuje „3”, co oznacza 3 rekordy.
- Operator konkatenacji łączy wyniki. Linia wychodząca z niego pokazuje „9” – wynik 9 rekordów z połączenia wyników.
- Operator Distinct Sort zapewnia unikalne rekordy jako ostateczny wynik. Linia wychodząca z niego pokazuje „3”, co jest zgodne z liczbą rekordów na rysunku 1.
Powyższy diagram pokazuje, jak UNION jest przetwarzany przez SQL Server. Liczba i typ używanych operatorów może się różnić w zależności od zapytania i bazowego źródła danych. Podsumowując, UNIA działa w następujący sposób:
- Pobierz wyniki każdej instrukcji SELECT.
- Połącz wyniki z operatorem konkatenacji.
- Jeśli połączone wyniki nie są niepowtarzalne, SQL Server odfiltruje duplikaty.
Wszystkie udane przykłady z UNION postępują zgodnie z tymi podstawowymi krokami.
2. Użyj SQL UNION ALL do łączenia rekordów z duplikatami
Korzystanie z UNION ALL łączy zestawy wyników z dołączonymi duplikatami.
Dlaczego jest to ważne?
Możesz chcieć połączyć zestawy wyników, a następnie pobrać rekordy z duplikatami do późniejszego przetworzenia. To zadanie jest przydatne do czyszczenia danych.
Jak z niego korzystać
Łączysz wyniki instrukcji SELECT z UNION ALL pomiędzy. Spójrz na przykład:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Powyższy kod wyświetla 9 rekordów, jak pokazano na rysunku 3:
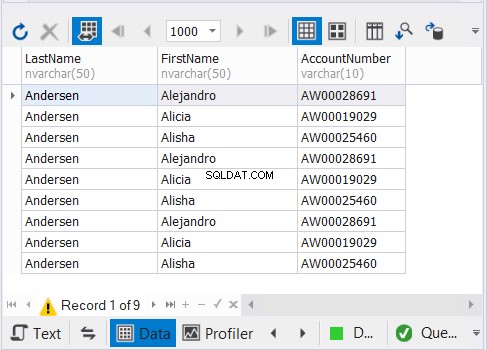
Jak to działa?
Tak jak poprzednio, używamy diagramu Plan, aby dowiedzieć się, jak to działa:
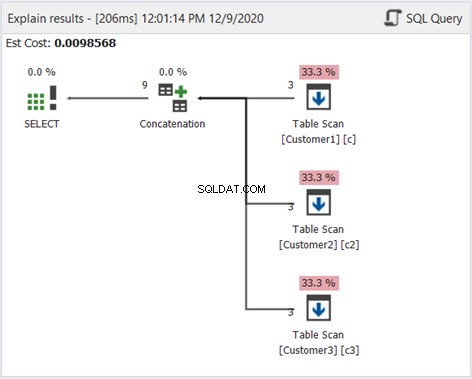
Z wyjątkiem Sort Distinct na rysunku 2, powyższy diagram jest taki sam. To pasuje, ponieważ nie chcemy odfiltrowywać duplikatów.
Powyższy schemat pokazuje, jak działa UNION ALL. Podsumowując, oto kroki, które wykona SQL Server:
- Pobierz wyniki każdej instrukcji SELECT.
- Następnie połącz wyniki z operatorem konkatenacji.
Udane przykłady z UNION ALL są zgodne z tym wzorcem.
3. Możesz mieszać SQL UNION i UNION ALL, ale grupować je w nawiasy
Możesz mieszać użycie UNION i UNION ALL w co najmniej trzech instrukcjach SELECT.
Jak z tego korzystać?
Łączysz wyniki instrukcji SELECT z UNION lub UNION ALL pomiędzy. Nawiasy grupują wyniki, które się łączą. Użyjmy tych samych danych w następnym przykładzie:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
Powyższy przykład łączy wyniki dwóch ostatnich instrukcji SELECT bez duplikatów. Następnie łączy to z wynikiem pierwszej instrukcji SELECT. Wynik przedstawiono na rysunku 5 poniżej:
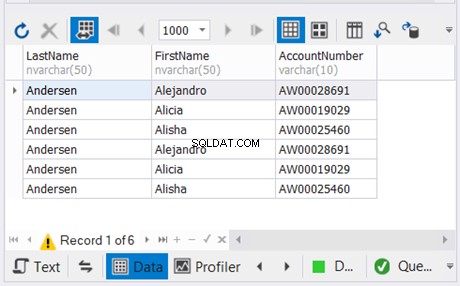
4. Kolumny każdej instrukcji SELECT powinny mieć zgodne typy danych
Kolumny w każdej instrukcji SELECT używającej UNION mogą mieć różne typy danych. Jest to dopuszczalne, o ile są one kompatybilne i pozwalają na niejawną konwersję. Ostateczny typ danych połączonych wyników użyje typu danych o najwyższym priorytecie. Również podstawą ostatecznego rozmiaru danych są dane o największym rozmiarze. W przypadku ciągów użyje danych z największą liczbą znaków.
Dlaczego jest to ważne?
Jeśli musisz wstawić wynik UNIONs do tabeli, ostateczny typ i rozmiar danych określi, czy pasuje do kolumny tabeli docelowej, czy nie. Jeśli nie, wystąpi błąd. Na przykład jedna z kolumn w UNION ma końcowy typ NVARCHAR(50). Jeśli kolumną tabeli docelowej jest VARCHAR(50), nie możesz wstawić jej do tabeli.
Jak to działa?
Nie ma lepszego sposobu na wyjaśnienie tego niż przykład:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
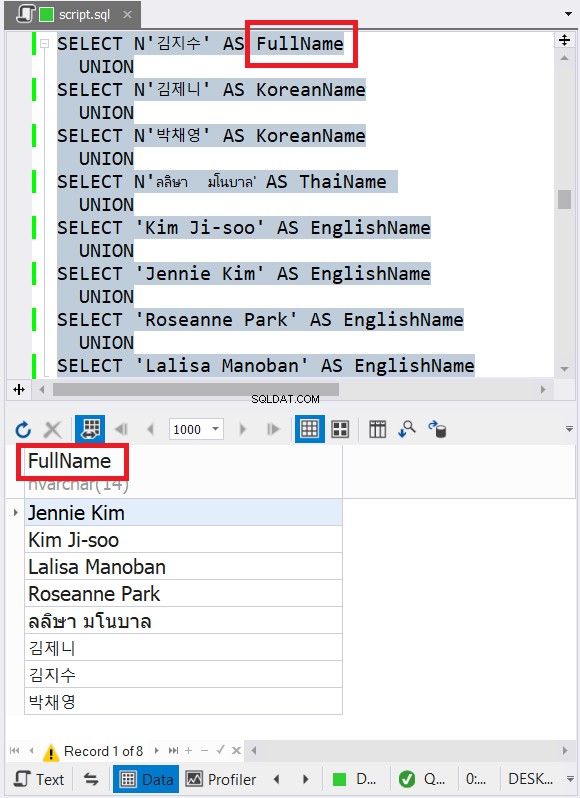
Powyższy przykład zawiera dane z nazwami znaków w języku angielskim, koreańskim i tajskim. Tajski i koreański to znaki Unicode. Znaki angielskie nie są. Jak myślisz, jaki będzie ostateczny typ i rozmiar danych? dbForge Studio pokazuje to w zestawie wyników:
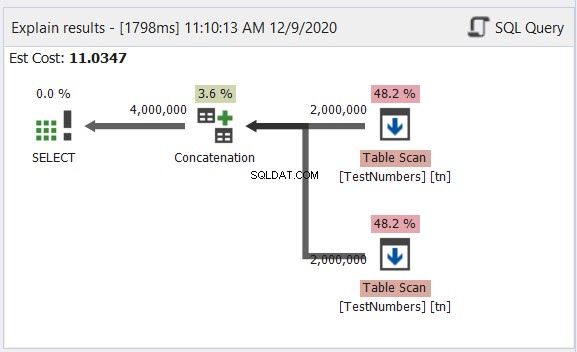
Czy zauważyłeś ostateczny typ danych na rysunku 6? Nie może to być VARCHAR z powodu znaków Unicode. Więc to musi być NVARCHAR. Tymczasem rozmiar nie może być mniejszy niż 14, ponieważ dane o największej liczbie znaków mają 14 znaków. Zobacz podpisy na czerwono na Rysunku 6. Dobrze jest uwzględnić typ i rozmiar danych w nagłówku kolumny w dbForge Studio.
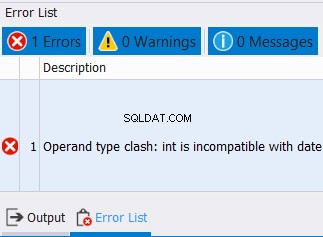
Dotyczy to nie tylko typów danych typu string. Dotyczy to również liczb i dat. Tymczasem, jeśli spróbujesz połączyć dane z niekompatybilnymi typami danych, wystąpi błąd. Zobacz przykład poniżej:
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Nie możemy łączyć dat i liczb całkowitych w jednej kolumnie. Więc spodziewaj się błędu takiego jak ten poniżej:
5. Nazwy kolumn w połączonych wynikach będą używać nazw kolumn z pierwszej instrukcji SELECT
Ten problem dotyczy poprzedniej wskazówki. Zwróć uwagę na nazwy kolumn w kodzie w Tip # 4. W każdej instrukcji SELECT występują różne nazwy kolumn. Jednak widzieliśmy ostatnią nazwę kolumny w połączonym wyniku na rysunku 6 wcześniej. Dlatego podstawą jest nazwa kolumny pierwszej instrukcji SELECT.
Dlaczego jest to ważne?
Może to być przydatne, gdy trzeba zrzucić wynik UNION do tabeli tymczasowej. Jeśli musisz odwoływać się do nazw kolumn w kolejnych stwierdzeniach, musisz mieć pewność co do nazw. Jeśli nie korzystasz z zaawansowanego edytora kodu z IntelliSense, czeka Cię kolejny błąd w kodzie T-SQL.
Jak to działa?
Zobacz Rysunek 8, aby uzyskać wyraźniejsze wyniki korzystania z dbForge Studio:
6. Dodaj ORDER BY w ostatniej instrukcji SELECT z SQL UNION, aby posortować wyniki
Musisz posortować połączone wyniki. W serii instrukcji SELECT z UNION pomiędzy nimi można to zrobić za pomocą klauzuli ORDER BY w ostatniej instrukcji SELECT.
Dlaczego jest to ważne?
Użytkownicy chcą sortować dane w aplikacjach, stronach internetowych, raportach, arkuszach kalkulacyjnych i nie tylko.
Jak z niego korzystać
Użyj ORDER BY w ostatniej instrukcji SELECT. Oto przykład:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
Powyższy przykład sprawia, że wygląda na to, że sortowanie odbywa się tylko w ostatniej instrukcji SELECT. Ale nie jest. Będzie działać dla łącznego wyniku. Będziesz miał kłopoty, jeśli umieścisz go w każdej instrukcji SELECT. Zobacz wynik:
Bez ORDER BY zestaw wyników będzie zawierał wszystkich pracowników PersonType najpierw następuje wszystkie Customer PersonType . Jednak rysunek 9 pokazuje, że nazwy stają się porządkiem sortowania połączonego wyniku.
Jeśli spróbujesz umieścić ORDER BY w każdej instrukcji SELECT do sortowania, oto co się stanie:
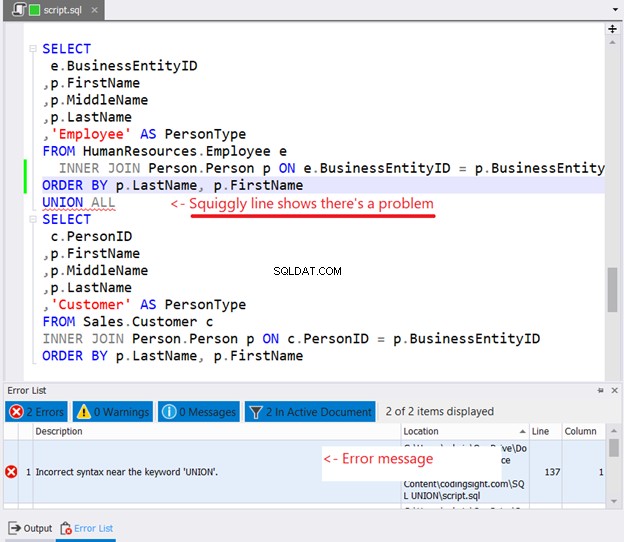
Czy widziałeś falistą linię na rysunku 10? To ostrzeżenie. Jeśli tego nie zauważyłeś i kontynuowałeś, w oknie Lista błędów dbForge Studio pojawi się błąd.
7. Klauzule WHERE i GROUP BY mogą być używane w każdej instrukcji SELECT z SQL UNION
Klauzula ORDER BY nie działa w każdej instrukcji SELECT z UNION pomiędzy. Jednak klauzule WHERE i GROUP BY działają.
Dlaczego jest to ważne?
Możesz chcieć połączyć wyniki różnych zapytań, które filtrują, zliczają lub podsumowują dane. Na przykład możesz to zrobić, aby uzyskać łączną liczbę zamówień sprzedaży ze stycznia 2012 r. i porównać ją ze styczniem 2013 r., styczniem 2014 r. itd.
Jak z niego korzystać
Umieść klauzule WHERE i/lub GROUP BY w każdej instrukcji SELECT. Sprawdź poniższy przykład:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Powyższy kod łączy liczbę styczniowych zamówień z trzech kolejnych lat. Teraz sprawdź wynik:
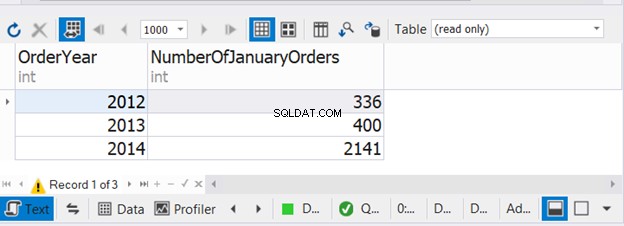
Ten przykład pokazuje, że możliwe jest użycie WHERE i GROUP BY w każdej z trzech instrukcji SELECT z UNION.
8. SELECT INTO Działa z SQL UNION
Kiedy musisz wstawić wyniki zapytania z SQL UNION do tabeli, możesz to zrobić za pomocą SELECT INTO.
Dlaczego jest to ważne?
Może się zdarzyć, że będziesz musiał umieścić wyniki zapytania z UNION w tabeli w celu dalszego przetwarzania.
Jak z niego korzystać
Umieść klauzulę INTO w pierwszej instrukcji SELECT. Oto przykład:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Pamiętaj, aby umieścić tylko jedną klauzulę INTO w pierwszej instrukcji SELECT.
Jak to działa
SQL Server jest zgodny ze wzorcem przetwarzania UNION. Następnie wstawia wynik do tabeli określonej w klauzuli INTO.
9. Odróżnij SQL UNION od SQL JOIN
Zarówno SQL UNION, jak i SQL JOIN łączą dane tabeli, ale różnica w składni i wynikach jest podobna do nocy i dnia.
Dlaczego jest to ważne?
Jeśli Twój raport lub jakiekolwiek wymaganie wymaga JOIN, ale zrobiłeś UNION, wynik będzie nieprawidłowy.
Jak używane są SQL UNION i SQL JOIN
To SQL UNION kontra JOIN. Jest to jedno z powiązanych zapytań i pytań, które nowicjusz zadaje w Google podczas poznawania SQL UNION. Oto tabela różnic:
| UNIA SQL | POŁĄCZENIE SQL | |
| Co jest połączone | Wiersze | Kolumny (przy użyciu klucza) |
| Liczba kolumn na tabelę | Takie same dla wszystkich stołów | Zmienna (zero do wszystkich kolumn/tabeli) |
We wszystkich projektach, z którymi byłem, przez większość czasu obowiązuje SQL JOIN. Miałem tylko kilka przypadków, w których używałem SQL UNION. Ale jak widzieliście do tej pory, SQL UNION nie jest bezużyteczny.
10. SQL UNION ALL jest szybszy niż UNION
Diagramy planu na Rysunku 2 i Rysunku 4 wcześniej sugerują, że UNION wymaga dodatkowego operatora, aby zapewnić unikalne wyniki. Dlatego UNION ALL jest szybszy.
Dlaczego jest to ważne?
Ty, Twoi użytkownicy, Twoi klienci, Twój szef, wszyscy pragniecie szybkich wyników. Wiedząc, że UNION ALL jest szybszy niż UNION, zastanawiasz się, co zrobić, jeśli potrzebujesz unikalnych połączonych wyników. Jest jedno rozwiązanie, jak zobaczysz później.
Wydajność SQL UNION ALL vs. UNION
Rysunek 2 i rysunek 4 już dały ci pomysł, który jest szybszy. Ale użyte próbki kodu są proste i mają niewielki zestaw wyników. Dodajmy więcej porównań z użyciem milionów rekordów, aby było to atrakcyjne.
Na początek przygotujmy dane:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
To 2 miliony rekordów. Mam nadzieję, że to wystarczająco przekonujące. Teraz przyjrzyjmy się kolejnym dwóm przykładom zapytań poniżej.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Przyjrzyjmy się procesom związanym z tymi zapytaniami, zaczynając od szybszego.
Analiza diagramu planu
Diagram na rysunku 12 wygląda typowo dla procesu UNION ALL. Jednak wynik to 4 miliony łącznych wyników. Zobacz strzałkę wychodzącą z operatora konkatenacji. Mimo to zazwyczaj dzieje się tak dlatego, że nie zajmuje się duplikatami.
Przyjrzyjmy się teraz diagramowi zapytania UNION na rysunku 13:
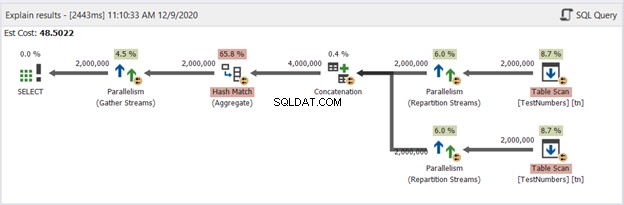
Ten już nie jest typowy. Plan staje się równoległym planem zapytań, aby poradzić sobie z usuwaniem duplikatów w czterech milionach wierszy. Plan zapytań równoległych oznacza, że SQL Server musi podzielić proces przez liczbę dostępnych rdzeni procesorów.
Zinterpretujmy to, zaczynając od właściwych operatorów idących w lewo:
- Ponieważ łączymy tabelę z samą sobą, SQL Server musi ją pobrać dwukrotnie. Zobacz dwa skany tabel z dwoma milionami rekordów każdy.
- Operatorzy strumienia podziału będą kontrolować dystrybucję każdego wiersza do następnego dostępnego wątku.
- Konkatenacja podwaja wynik do czterech milionów. To wciąż uwzględnia liczbę rdzeni procesora.
- Hash Match ma zastosowanie do usunięcia duplikatów. Jest to kosztowny proces z 65,8% kosztem operatora. W rezultacie odrzucono dwa miliony rekordów.
- Zbierz strumienie łączą wyniki wykonane w każdym rdzeniu procesora lub wątku w jeden.
To za dużo pracy, mimo że proces jest podzielony na wiele wątków. Dlatego dojdziesz do wniosku, że będzie działał wolniej. Ale co, jeśli istnieje rozwiązanie pozwalające uzyskać unikalne rekordy w UNION ALL, ale szybciej niż to?
Unikalne wyniki, ale szybsza naprawa dzięki UNION ALL – jak?
Nie każę ci czekać. Oto kod:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
To może być kiepskie rozwiązanie. Ale spójrz na diagram planu na rysunku 14:
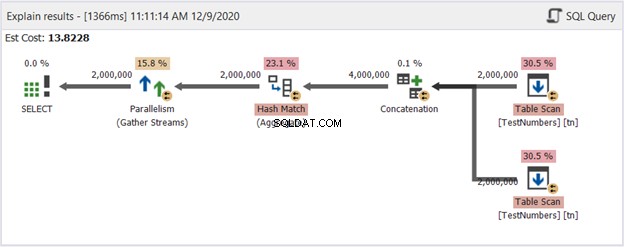
Więc co sprawiło, że było lepiej? Jeśli porównasz to z rysunkiem 13, zobaczysz, że operatory strumienia podziału zniknęły. Jednak nadal wykorzystuje wiele wątków, aby wykonać zadanie. Z drugiej strony oznacza to, że optymalizator zapytań uważa ten proces za prostszy do wykonania niż zapytanie przy użyciu UNION.
Czy możemy bezpiecznie dojść do wniosku, że powinniśmy unikać UNION i zamiast tego zastosować to podejście? Zupełnie nie! Zawsze sprawdzaj diagram planu wykonania! To zawsze zależy od tego, co chcesz, aby SQL Server Ci dał. Ten pokazuje tylko, że jeśli wpadniesz na barierę wydajności, musisz zmienić podejście do zapytań.
A co ze statystykami we/wy?
Nie możemy wykluczyć, ile zasobów potrzebuje SQL Server do przetworzenia naszych przykładów zapytań. Dlatego musimy również sprawdzić ich STATISTICS IO. Porównując trzy powyższe zapytania, poniżej otrzymujemy logiczne odczyty:
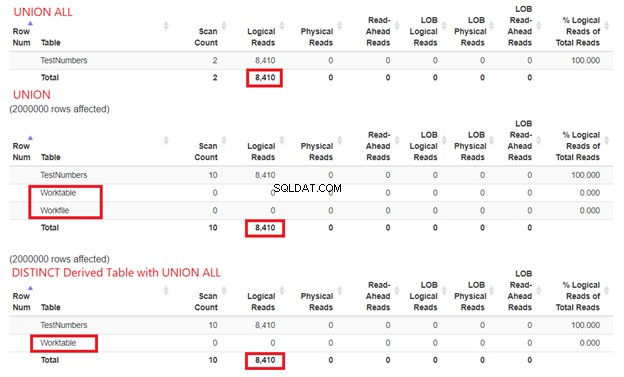
Z rysunku 15 nadal możemy wywnioskować, że UNION ALL jest szybszy niż UNION, chociaż odczyty logiczne są takie same. Obecność Stół roboczy i Plik roboczy pokazuje używając tempdb aby wykonać pracę. Tymczasem, gdy używamy SELECT DISTINCT z tabeli pochodnej z UNION ALL, tempdb zużycie jest mniejsze w porównaniu do UNION. To ponownie potwierdza, że nasza analiza z wcześniejszych diagramów planów jest prawidłowa.
A co ze statystykami czasu?
Chociaż upływający czas może się zmienić przy każdym wykonywaniu tych samych zapytań, może to dać nam pewne wyobrażenie i dodać więcej dowodów do naszej analizy. dbForge Studio wyświetla różnice czasowe trzech powyższych zapytań. To porównanie jest zgodne z poprzednią analizą, którą przeprowadziliśmy.
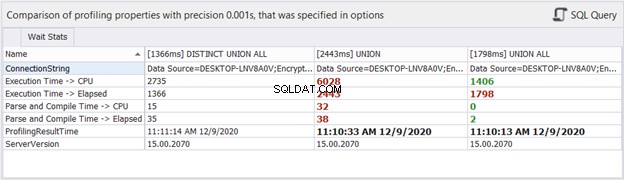
Wniosek
Omówiliśmy wiele informacji, aby zapewnić to, czego potrzebujesz do korzystania z SQL UNION i UNION ALL. Po przeczytaniu tego posta możesz nie pamiętać wszystkiego, więc pamiętaj, aby dodać tę stronę do zakładek.
Jeśli podoba Ci się post, udostępnij go w mediach społecznościowych.