ANY agregacja nie jest czymś, co możemy napisać bezpośrednio w Transact SQL. Jest to jedyna wewnętrzna funkcja używana przez optymalizator zapytań i silnik wykonywania.
Osobiście bardzo lubię ANY agregat, więc trochę rozczarowujące było, gdy dowiedziałem się, że jest zepsuty w dość fundamentalny sposób. Szczególny smak „zepsutego”, o którym tutaj mówię, to odmiana z błędnymi wynikami.
W tym poście przyjrzę się dwóm konkretnym miejscom, w których ANY często pojawia się agregacja, pokazuje problem z niewłaściwymi wynikami i sugeruje obejścia w razie potrzeby.
W tle na ANY zbiorczo, zobacz mój poprzedni post Plany nieudokumentowanych zapytań:DOWOLNE zagregowane.
1. Jeden wiersz na zapytania grupowe
To musi być jedno z najczęstszych codziennych wymagań dotyczących zapytań, z bardzo dobrze znanym rozwiązaniem. Prawdopodobnie piszesz tego rodzaju zapytania codziennie, automatycznie podążając za wzorcem, bez zastanowienia się nad tym.
Pomysł polega na numerowaniu wejściowego zestawu wierszy za pomocą ROW_NUMBER funkcja okna, podzielona według kolumny lub kolumn grupujących. To jest opakowane w wspólne wyrażenie tabelowe lub tabela pochodna i przefiltrowane do wierszy, w których obliczony numer wiersza jest równy jeden. Od ROW_NUMBER uruchamia się ponownie po jednym dla każdej grupy, co daje nam wymagany jeden wiersz na grupę.
Nie ma problemu z tym ogólnym wzorcem. Typ jednego wiersza na zapytanie grupowe, który podlega ANY zbiorczy problem to ten, w którym nie obchodzi nas, który konkretny wiersz jest zaznaczony z każdej grupy.
W takim przypadku nie jest jasne, która kolumna powinna być użyta w obowiązkowym ORDER BY klauzula ROW_NUMBER funkcja okna. W końcu wyraźnie nie obchodzi nas to który wiersz jest wybrany. Jednym z powszechnych rozwiązań jest ponowne użycie PARTITION BY kolumny w ORDER BY klauzula. Tutaj może wystąpić problem.
Przykład
Spójrzmy na przykład z wykorzystaniem zestawu danych zabawek:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Wymagane jest zwrócenie dowolnego pełnego wiersza danych z każdej grupy, gdzie przynależność do grupy jest określona przez wartość w kolumnie c1 .

Po ROW_NUMBER możemy napisać zapytanie podobne do poniższego (zwróć uwagę na ORDER BY klauzula ROW_NUMBER funkcja okna pasuje do PARTITION BY klauzula):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Jak przedstawiono, to zapytanie zostanie wykonane pomyślnie, z poprawnymi wynikami. Wyniki są technicznie niedeterministyczne ponieważ SQL Server może poprawnie zwrócić dowolny z wierszy w każdej grupie. Niemniej jednak, jeśli sam uruchomisz to zapytanie, prawdopodobnie zobaczysz ten sam wynik, co ja:
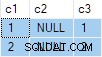
Plan wykonania zależy od używanej wersji SQL Server i nie zależy od poziomu zgodności bazy danych.
W przypadku SQL Server 2014 i wcześniejszych plan jest następujący:

W przypadku SQL Server 2016 lub nowszego zobaczysz:

Oba plany są bezpieczne, ale z różnych powodów. Odrębne sortowanie plan zawiera ANY zbiorcze, ale sortowanie odrębne implementacja operatora nie ujawnia błędu.
Bardziej złożony plan SQL Server 2016+ nie używa ANY w ogóle. Sortuj umieszcza wiersze w kolejności potrzebnej do operacji numerowania wierszy. Segment operator ustawia flagę na początku każdej nowej grupy. Projekt sekwencyjny oblicza numer wiersza. Wreszcie Filtr operator przekazuje tylko te wiersze, które mają obliczony numer wiersza jeden.
Błąd
Aby uzyskać nieprawidłowe wyniki dla tego zestawu danych, musimy używać programu SQL Server 2014 lub wcześniejszego oraz ANY agregaty muszą być zaimplementowane w Stream Aggregate lub gorliwy zagregowanie haszowania operator (Flow Distinct Hash Match Aggregate nie powoduje błędu).
Jednym ze sposobów zachęcenia optymalizatora do wybrania agregacji strumienia zamiast sortowania odrębnego jest dodanie klastrowego indeksu, aby zapewnić porządkowanie według kolumny c1 :
CREATE CLUSTERED INDEX c ON #Data (c1);
Po tej zmianie plan wykonania staje się:

ANY agregaty są widoczne w Właściwościach okno, gdy Stream Aggregate wybrany jest operator:

Wynik zapytania to:
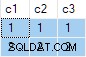
To jest niewłaściwe . SQL Server zwrócił wiersze, które nie istnieją w danych źródłowych. Nie ma wierszy źródłowych, w których c2 = 1 i c3 = 1 na przykład. Przypominamy, że dane źródłowe to:
Plan wykonania błędnie oblicza oddzielnie ANY agregaty dla c2 i c3 kolumny, ignorując wartości null. Każdy agregat niezależnie zwraca pierwszy niepusty napotkaną wartość, dając wynik, w którym wartości dla c2 i c3 pochodzą z różnych wierszy źródłowych . Nie tego wymagała oryginalna specyfikacja zapytania SQL.
Ten sam błędny wynik można uzyskać z lub bez indeks klastrowy przez dodanie OPTION (HASH GROUP) wskazówka, aby stworzyć plan za pomocą Eager Hash Aggregate zamiast Stream Aggregate .
Warunki
Ten problem może wystąpić tylko wtedy, gdy wiele ANY agregaty są obecne, a zagregowane dane zawierają wartości null. Jak już wspomniano, problem dotyczy tylko Stream Aggregate i chętni Agregacja haszująca operatorzy; Odrębne sortowanie i Flow Distinct nie mają wpływu.
SQL Server 2016 i nowsze starają się uniknąć wprowadzania wielu ANY agreguje dla dowolnego jednego wiersza na grupę wzorca zapytania numeracji wierszy, gdy kolumny źródłowe dopuszczają wartość null. W takim przypadku plan wykonania będzie zawierał Segment , Projekt sekwencyjny i Filtr operatorów zamiast agregatu. Ten kształt planu jest zawsze bezpieczny, ponieważ nie ma ANY używane są agregaty.
Powielanie błędu w SQL Server 2016+
Optymalizator SQL Server nie jest doskonały w wykrywaniu, kiedy kolumna pierwotnie ograniczona jako NOT NULL może nadal generować zerową wartość pośrednią poprzez manipulacje danymi.
Aby to odtworzyć, zaczniemy od tabeli, w której wszystkie kolumny są zadeklarowane jako NOT NULL :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Możemy tworzyć wartości null z tego zestawu danych na wiele sposobów, z których większość optymalizator może z powodzeniem wykryć, więc unikaj wprowadzania ANY agreguje podczas optymalizacji.
Poniżej pokazano jeden ze sposobów dodawania wartości zerowych, które prześlizgują się pod radarem:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; To zapytanie daje następujące dane wyjściowe:
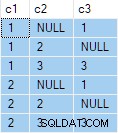
Następnym krokiem jest użycie tej specyfikacji zapytania jako danych źródłowych dla standardowego zapytania „dowolny jeden wiersz na grupę”:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; W dowolnej wersji SQL Server, który generuje następujący plan:
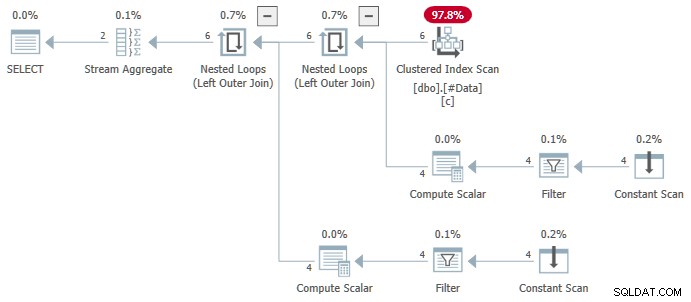
Agregacja strumienia zawiera wiele ANY agreguje, a wynik jest błędny . Żaden ze zwróconych wierszy nie pojawia się w zestawie danych źródłowych:
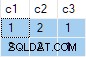
db<>fiddle online demo
Obejście
Jedynym w pełni niezawodnym obejściem, dopóki ten błąd nie zostanie naprawiony, jest uniknięcie wzorca, w którym ROW_NUMBER ma tę samą kolumnę w ORDER BY klauzula jak w PARTITION BY klauzula.
Kiedy nie obchodzi nas co z każdej grupy wybierany jest jeden wiersz, szkoda, że ORDER BY klauzula jest w ogóle potrzebna. Jednym ze sposobów na obejście problemu jest użycie stałej czasu wykonywania, takiej jak ORDER BY @@SPID w funkcji okna.
2. Aktualizacja niedeterministyczna
Problem z wieloma ANY agregacje na danych wejściowych dopuszczających wartość null nie są ograniczone do jednego wiersza na wzorzec zapytania grupy. Optymalizator zapytań może wprowadzić wewnętrzny ANY agregować w wielu okolicznościach. Jednym z takich przypadków jest aktualizacja niedeterministyczna.
niedeterministyczny aktualizacja to sytuacja, w której instrukcja nie gwarantuje, że każdy wiersz docelowy zostanie zaktualizowany co najwyżej raz. Innymi słowy, istnieje wiele wierszy źródłowych dla co najmniej jednego wiersza docelowego. Dokumentacja wyraźnie ostrzega przed tym:
Zachowaj ostrożność podczas określania klauzuli FROM, aby podać kryteria operacji aktualizacji.Wyniki instrukcji UPDATE są niezdefiniowane, jeśli instrukcja zawiera klauzulę FROM, która nie jest określona w taki sposób, że tylko jedna wartość jest dostępna dla każdego zaktualizowanego wystąpienia kolumny, czyli jest, jeśli instrukcja UPDATE nie jest deterministyczna.
Aby obsłużyć niedeterministyczną aktualizację, optymalizator grupuje wiersze według klucza (indeks lub RID) i stosuje ANY agregaty do pozostałych kolumn. Podstawowa idea polega na wybraniu jednego wiersza z wielu kandydatów i użyciu wartości z tego wiersza do przeprowadzenia aktualizacji. Istnieją oczywiste podobieństwa do poprzedniego ROW_NUMBER problem, więc nie jest niespodzianką, że dość łatwo jest zademonstrować nieprawidłową aktualizację.
W przeciwieństwie do poprzedniego problemu, SQL Server obecnie nie podejmuje żadnych specjalnych kroków aby uniknąć wielu ANY agreguje na kolumnach dopuszczających wartość null podczas wykonywania niedeterministycznej aktualizacji. Poniższe informacje odnoszą się zatem do wszystkich wersji SQL Server , w tym SQL Server 2019 CTP 3.0.
Przykład
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>fiddle online demo
Logicznie rzecz biorąc, ta aktualizacja powinna zawsze powodować błąd:tabela docelowa nie zezwala na wartości null w żadnej kolumnie. Niezależnie od tego, który pasujący wiersz zostanie wybrany z tabeli źródłowej, próba aktualizacji kolumny c2 lub c3 null musi wystąpią.
Niestety aktualizacja się powiodła, a ostateczny stan tabeli docelowej jest niezgodny z dostarczonymi danymi:
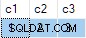
Zgłosiłem to jako błąd. Rozwiązaniem jest unikanie pisania niedeterministycznej UPDATE oświadczenia, więc ANY agregaty nie są potrzebne do rozwiązania niejednoznaczności.
Jak wspomniano, SQL Server może wprowadzić ANY agreguje w większej liczbie okoliczności niż w dwóch podanych tutaj przykładach. Jeśli tak się stanie, gdy zagregowana kolumna zawiera wartości null, istnieje możliwość uzyskania błędnych wyników.