Partycjonowanie to funkcja programu SQL Server często wdrażana w celu złagodzenia problemów związanych z zarządzaniem, zadaniami konserwacji lub blokowaniem i blokowaniem. Administracja dużymi tabelami może być łatwiejsza dzięki partycjonowaniu, a także może poprawić skalowalność i dostępność. Ponadto produktem ubocznym partycjonowania może być zwiększona wydajność zapytań. To nie jest gwarancja ani dane, i nie jest to główny powód wdrażania partycjonowania, ale jest to coś, co warto przejrzeć podczas partycjonowania dużej tabeli.
Tło
Krótko mówiąc, funkcja partycjonowania SQL Server jest dostępna tylko w wersjach Enterprise i Developer. Partycjonowanie może być zaimplementowane podczas wstępnego projektowania bazy danych lub może być wprowadzone po tym, jak tabela zawiera już dane. Zrozum, że zmiana istniejącej tabeli z danymi na tabelę podzieloną na partycje nie zawsze jest szybka i prosta, ale jest całkiem wykonalna przy dobrym planowaniu, a korzyści można szybko osiągnąć.
Tabela partycjonowana to taka, w której dane są dzielone na mniejsze struktury fizyczne na podstawie wartości określonej kolumny (nazywanej kolumną partycjonowania, która jest zdefiniowana w funkcji partycjonowania). Jeśli chcesz oddzielić dane według roku, możesz użyć kolumny o nazwie DateSold jako kolumny partycjonowania, a wszystkie dane za 2013 r. będą znajdować się w jednej strukturze, wszystkie dane za 2012 r. będą znajdować się w innej strukturze itd. Te oddzielne zestawy danych umożliwiają skoncentrowaną konserwację (można odbudować tylko partycję indeksu, a nie cały indeks) i pozwalają na szybkie dodawanie i usuwanie danych, ponieważ można je przygotować przed faktycznym dodaniem lub usunięciem z tabeli.
Konfiguracja
Aby zbadać różnice w wydajności zapytań dla tabeli partycjonowanej i niepartycjonowanej, utworzyłem dwie kopie tabeli Sales.SalesOrderHeader z bazy danych AdventureWorks2012. Tabela niepartycjonowana została utworzona tylko z indeksem klastrowym na SalesOrderID, tradycyjnym kluczu podstawowym tabeli. Druga tabela została podzielona na partycje według OrderDate, z OrderDate i SalesOrderID jako kluczem klastrowania i nie miała żadnych dodatkowych indeksów. Należy zauważyć, że przy podejmowaniu decyzji, której kolumny użyć do partycjonowania, należy wziąć pod uwagę wiele czynników. Partycjonowanie często, ale na pewno nie zawsze, wykorzystuje pole daty do określenia granic partycji. W związku z tym w tym przykładzie wybrano OrderDate, a przykładowe zapytania zostały użyte do symulacji typowej aktywności względem tabeli SalesOrderHeader. Instrukcje tworzenia i wypełniania obu tabel można pobrać tutaj.
Po utworzeniu tabel i dodaniu danych zweryfikowano istniejące indeksy, a następnie zaktualizowano statystyki za pomocą FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Ponadto obie tabele mają dokładnie taki sam rozkład danych i minimalną fragmentację.
Wydajność prostego zapytania
Przed dodaniem jakichkolwiek dodatkowych indeksów wykonano podstawowe zapytanie w obu tabelach w celu obliczenia sum uzyskanych przez sprzedawcę za zamówienia złożone w grudniu 2012 r.:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOSTATYSTYKI WYJŚCIE IO
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Big_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 2710440, odczyty fizyczne 2226, odczyty z wyprzedzeniem 2658769, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Part_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 248128, odczyty fizyczne 3, odczyty z wyprzedzeniem 245030, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.

Podsumowania według sprzedawcy za grudzień — tabela bez partycji
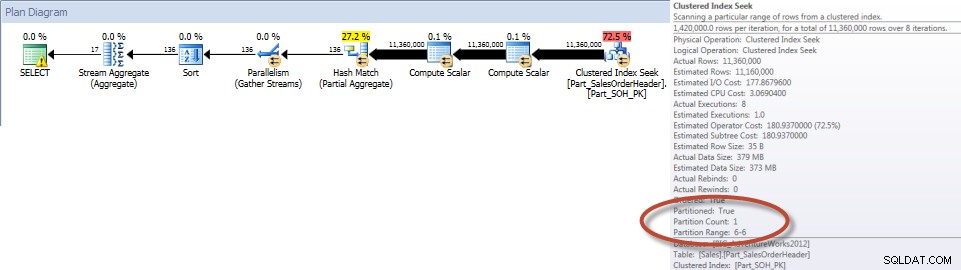
Podsumowania według sprzedawców za grudzień – podzielona tabela
Zgodnie z oczekiwaniami zapytanie dotyczące tabeli niepartycjonowanej musiało wykonać pełne skanowanie tabeli, ponieważ nie było indeksu, który mógłby je obsługiwać. W przeciwieństwie do tego zapytanie dotyczące tabeli partycjonowanej potrzebne było tylko do uzyskania dostępu do jednej partycji tabeli.
Szczerze mówiąc, gdyby było to zapytanie wielokrotnie wykonywane z różnymi zakresami dat, istniałby odpowiedni indeks nieklastrowany. Na przykład:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Po utworzeniu tego indeksu po ponownym wykonaniu zapytania statystyki we/wy spadają, a plan zmienia się na indeks nieklastrowany:
STATYSTYKI WYJŚCIE IO
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Big_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 42901, odczyty fizyczne 3, odczyty z wyprzedzeniem 42346, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty lobu z wyprzedzeniem 0.

Podsumowania według sprzedawcy za grudzień – NCI na stole niepartycjonowanym
W przypadku indeksu pomocniczego zapytanie dotyczące Sales.Big_SalesOrderHeader wymaga znacznie mniejszej liczby odczytów niż skanowanie indeksu klastrowanego względem Sales.Part_SalesOrderHeader, co nie jest nieoczekiwane, ponieważ indeks klastrowany jest znacznie szerszy. Jeśli utworzymy porównywalny indeks nieklastrowy dla Sales.Part_SalesOrderHeader, zobaczymy podobne liczby we/wy:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATYSTYKI WYJŚCIE IO
Tabela „Nagłówek zamówienia części_sprzedaży”. Liczba skanów 9, odczyty logiczne 42894, odczyty fizyczne 1, odczyty z wyprzedzeniem 42378, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty lobu z wyprzedzeniem 0.
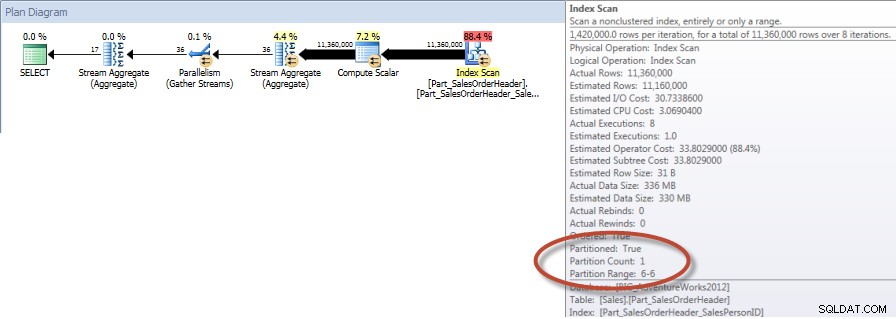
Podsumowania według sprzedawcy za grudzień – NCI na podzielonym stole z eliminacją
A jeśli spojrzymy na właściwości nieklastrowego skanowania indeksu, możemy sprawdzić, czy silnik uzyskał dostęp tylko do jednej partycji (6).
Jak stwierdzono pierwotnie, partycjonowanie nie jest zwykle implementowane w celu poprawy wydajności. W powyższym przykładzie zapytanie dotyczące tabeli partycjonowanej nie działa znacznie lepiej, o ile istnieje odpowiedni indeks nieklastrowany.
Wydajność zapytania ad hoc
Zapytanie o partycjonowaną tabelę może w niektórych przypadkach przewyższa to samo zapytanie względem tabeli niepartycjonowanej, na przykład gdy zapytanie musi używać indeksu klastrowego. Chociaż idealne jest, aby większość zapytań była obsługiwana przez indeksy nieklastrowe, niektóre systemy zezwalają na zapytania ad hoc od użytkowników, a inne mają zapytania, które mogą być uruchamiane tak rzadko, że nie gwarantują obsługi indeksów. W odniesieniu do tabeli SalesOrderHeader użytkownik może uruchomić następujące zapytanie, aby znaleźć zamówienia z grudnia 2012 r., które musiały zostać wysłane do końca roku, ale nie zostały wysłane, dla określonej grupy klientów i z sumą TotalDue większą niż 1000 USD:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOSTATYSTYKI WYJŚCIE IO
Tabela 'Big_SalesOrderHeader'. Liczba skanów 9, odczyty logiczne 2711220, odczyty fizyczne 8386, odczyty z wyprzedzeniem 2662400, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Part_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 248128, odczyty fizyczne 0, odczyty z wyprzedzeniem 243792, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty lobu z wyprzedzeniem 0.
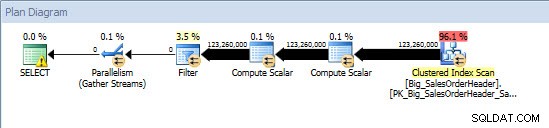
Zapytanie ad hoc — tabela niepartycjonowana
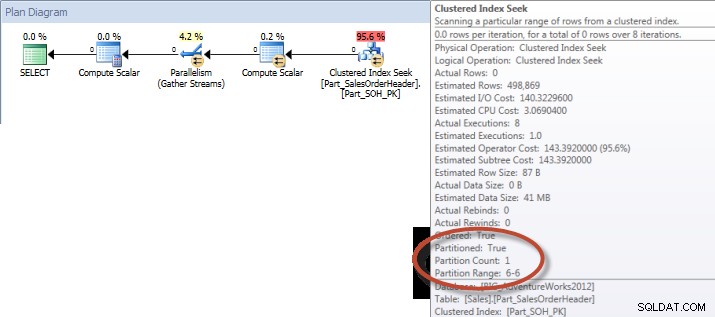
Zapytanie ad hoc – partycjonowana tabela
W przypadku tabeli niepartycjonowanej zapytanie wymagało pełnego skanowania względem indeksu klastrowanego, ale w odniesieniu do tabeli partycjonowanej zapytanie wykonało wyszukiwanie indeksu indeksu klastrowanego, ponieważ aparat używał eliminacji partycji i odczytywał tylko te dane, których absolutnie potrzebował. W tym przykładzie jest to znacząca różnica pod względem we/wy, a w zależności od sprzętu może to być dramatyczna różnica w czasie wykonywania. Zapytanie można zoptymalizować, dodając odpowiedni indeks, ale zazwyczaj nie jest możliwe indeksowanie dla każdego pojedynczy zapytanie. W szczególności w przypadku rozwiązań, które umożliwiają zapytania ad-hoc, można uczciwie powiedzieć, że nigdy nie wiadomo, co zrobią użytkownicy. Zapytanie może zostać uruchomione raz i nigdy więcej nie zostanie uruchomione, a tworzenie indeksu po fakcie jest daremne. Dlatego przy zmianie z tabeli niepartycjonowanej na tabelę partycjonowaną ważne jest, aby zastosować ten sam wysiłek i podejście, co zwykłe dostrajanie indeksu; chcesz sprawdzić, czy istnieją odpowiednie indeksy obsługujące większość zapytań.
Wyrównanie wydajności i indeksu
Dodatkowym czynnikiem, który należy wziąć pod uwagę podczas tworzenia indeksów dla tabeli partycjonowanej, jest to, czy wyrównać indeks, czy nie. Indeksy muszą być wyrównane z tabelą, jeśli planujesz przełączać dane do i z partycji. Tworzenie indeksu nieklastrowanego w tabeli partycjonowanej domyślnie tworzy indeks wyrównany, w którym kolumna partycjonowania jest dodawana jako kolumna dołączona do indeksu.
Indeks niewyrównany jest tworzony przez określenie innego schematu partycji lub innej grupy plików. Kolumna partycjonowania może być częścią indeksu jako kolumna klucza lub kolumna uwzględniona, ale jeśli schemat partycjonowania tabeli nie jest używany lub używana jest inna grupa plików, indeks nie zostanie wyrównany.
Wyrównany indeks jest podzielony na partycje, podobnie jak tabela — dane będą istnieć w oddzielnych strukturach — i dlatego może nastąpić eliminacja partycji. Niewyrównany indeks istnieje jako jedna struktura fizyczna i może nie zapewniać oczekiwanych korzyści dla zapytania, w zależności od predykatu. Rozważ zapytanie, które liczy sprzedaż według numeru konta, pogrupowane według miesiąca:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Jeśli nie jesteś zaznajomiony z partycjonowaniem, możesz utworzyć indeks podobny do tego, aby obsługiwać zapytanie (zauważ, że określona jest grupa plików PRIMARY):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Ten indeks nie jest wyrównany, mimo że zawiera OrderDate, ponieważ jest częścią klucza podstawowego. Kolumny są również uwzględniane, jeśli tworzymy indeks wyrównany, ale zwróć uwagę na różnicę w składni:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Możemy zweryfikować, jakie kolumny istnieją w indeksie za pomocą sp_helpindex Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex dla działu sprzedaży.Part_SalesOrderHeader
Kiedy uruchamiamy nasze zapytanie i zmuszamy je do użycia indeksu niewyrównanego, skanowany jest cały indeks. Mimo że OrderDate jest częścią indeksu, nie jest to wiodąca kolumna, więc silnik musi sprawdzić wartość OrderDate dla każdego AccountNumber, aby sprawdzić, czy przypada ona między 1 stycznia 2013 a 31 lipca 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATYSTYKI WYJŚCIE IO
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Part_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 786861, odczyty fizyczne 1, odczyty z wyprzedzeniem 770929, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
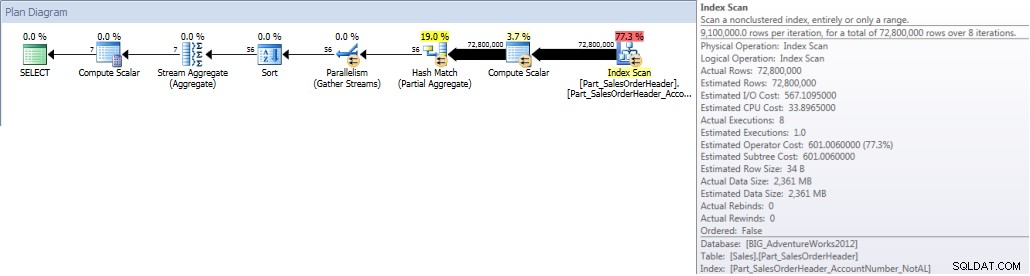
Suma konta według miesiąca (styczeń – lipiec 2013) Wyrównany NCI (wymuszony)
W przeciwieństwie do tego, gdy zapytanie jest wymuszane, aby użyć wyrównanego indeksu, można użyć eliminacji partycji i wymagana jest mniejsza liczba operacji we/wy, nawet jeśli OrderDate nie jest wiodącą kolumną w indeksie.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);STATYSTYKI WYJŚCIE IO
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Part_SalesOrderHeader”. Liczba skanów 9, odczyty logiczne 456258, odczyty fizyczne 16, odczyty z wyprzedzeniem 453241, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty lobu z wyprzedzeniem 0.
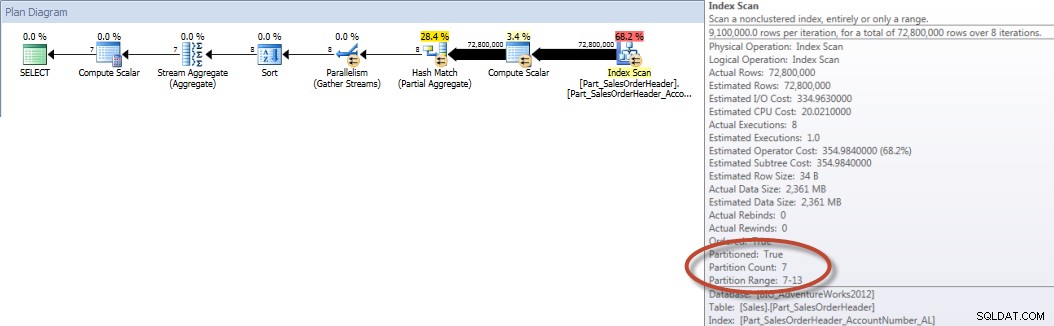
Suma konta według miesiąca (styczeń – lipiec 2013) przy użyciu wyrównanego NCI (wymuszone)
Podsumowanie
Decyzja o wdrożeniu partycjonowania wymaga należytego rozważenia i zaplanowania. Łatwość zarządzania, lepsza skalowalność i dostępność oraz zmniejszenie blokowania to typowe powody partycjonowania tabel. Poprawa wydajności zapytań nie jest powodem do stosowania partycjonowania, chociaż w niektórych przypadkach może to być korzystnym efektem ubocznym. Jeśli chodzi o wydajność, ważne jest, aby upewnić się, że plan implementacji obejmuje przegląd wydajności zapytań. Potwierdź, że Twoje indeksy nadal odpowiednio obsługują Twoje zapytania po tabela jest podzielona na partycje i sprawdź, czy zapytania korzystające z indeksów klastrowych i nieklastrowych korzystają z eliminacji partycji, jeśli ma to zastosowanie.