Widoki indeksowane można tworzyć w dowolnej wersji SQL Server, ale istnieje szereg zachowań, o których należy pamiętać, jeśli chcesz je w pełni wykorzystać.
Automatyczne statystyki wymagają podpowiedzi NOEXPAND
SQL Server może automatycznie tworzyć statystyki, aby pomóc w szacowaniu kardynalności i podejmowaniu decyzji opartych na kosztach podczas optymalizacji zapytań. Ta funkcja działa z widokami indeksowanymi oraz tabelami podstawowymi, ale tylko wtedy, gdy widok jest jawnie nazwany w zapytaniu i NOEXPAND wskazówka jest określona. (Z każdym indeksem w widoku zawsze jest powiązany obiekt statystyki, jest to automatyczne generowanie i utrzymywanie statystyk niezwiązanych z indeksem, o którym tutaj mówimy.)
Jeśli jesteś przyzwyczajony do pracy z wersjami SQL Server innymi niż Enterprise, być może nigdy wcześniej nie zauważyłeś tego zachowania. Młodsze wersje SQL Server wymagają NOEXPAND wskazówka, aby utworzyć plan kwerend, który uzyskuje dostęp do indeksowanego widoku. Kiedy NOEXPAND jest określone, automatyczne statystyki są tworzone na widokach indeksowanych dokładnie tak, jak to ma miejsce w przypadku zwykłych tabel.
Przykład – edycja standardowa z NOEXPAND
Korzystając z SQL Server 2012 Standard Edition i przykładowej bazy danych Adventure Works, najpierw tworzymy widok, który łączy dwie tabele sprzedaży i oblicza całkowitą ilość zamówienia na klienta i produkt:
UTWÓRZ WIDOK dbo.ZamówieniaKlientaZ SCHEMATEM ASSELECT SOH.IDKlienta, SOD.IDProduktu,IlośćZamówienia =SUMA(SOD.IlośćZamówienia), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail AS SODJOIN Sales.SalesOrderHeader SODSalesOrder SOHder AS SODOrder .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
Aby ten widok obsługiwał statystyki, musimy go zmaterializować, dodając unikalny indeks klastrowy. Połączenie identyfikatora klienta i identyfikatora produktu gwarantuje, że będzie unikalne w widoku (z definicji), więc użyjemy go jako klucza. Moglibyśmy określić dwie kolumny w indeksie w obie strony, ale zakładając, że oczekujemy, że więcej zapytań będzie filtrowanych według produktu, jako wiodącą kolumnę ustawiamy Identyfikator produktu. Ta akcja tworzy również statystyki indeksu z histogramem zbudowanym na podstawie wartości identyfikatora produktu.
UTWÓRZ NIEPOWTARZALNY SKLASTROWANY INDEKS cuq NA dbo.CustomerOrders (ProductID, CustomerID);
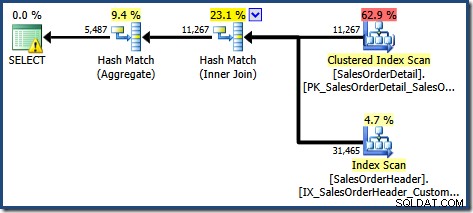
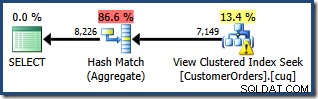
Zostaliśmy teraz poproszeni o napisanie zapytania, które pokazuje całkowitą ilość zamówień na klienta, dla określonej gamy produktów. Spodziewamy się, że plan wykonania z wykorzystaniem widoku indeksowanego będzie skuteczną strategią, ponieważ pozwoli uniknąć złączenia i operuje na danych, które są już częściowo zagregowane. Ponieważ używamy SQL Server Standard Edition, musimy jawnie określić widok i użyć NOEXPAND wskazówka, aby utworzyć plan zapytania, który uzyskuje dostęp do zindeksowanego widoku:
SELECT CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)GDZIE CO.ProductID BETWEEN 711 AND 718GROUP BY CO.CustomerID;
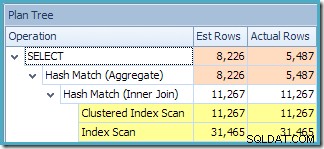
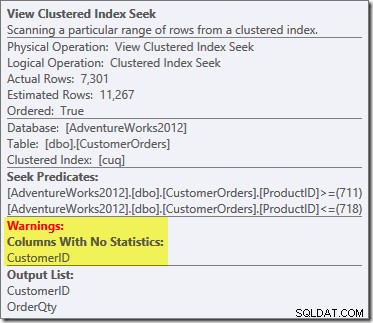
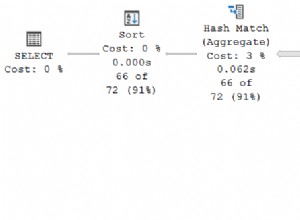
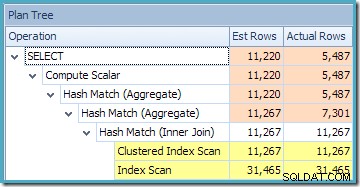
Utworzony plan wykonania pokazuje wyszukiwanie w zindeksowanym widoku w celu znalezienia wierszy dla interesujących produktów, a następnie agregację w celu obliczenia całkowitej ilości na klienta:
Widok drzewa planów programu SQL Sentry Plan Explorer pokazuje, że oszacowanie kardynalności jest dokładnie poprawne dla wyszukiwania widoku indeksowanego i bardzo dobre dla wyniku agregacji:
W ramach procesu kompilacji i optymalizacji dla tego zapytania SQL Server utworzył dodatkowy obiekt statystyk w kolumnie Customer ID indeksowanego widoku. Ta statystyka jest budowana, ponieważ oczekiwana liczba i rozkład identyfikatorów klientów może mieć znaczenie, na przykład przy wyborze strategii agregacji. Możemy zobaczyć nowe statystyki za pomocą Management Studio Object Explorer:
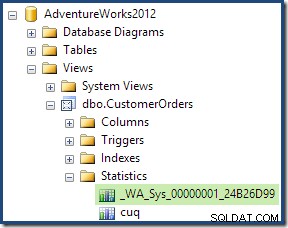
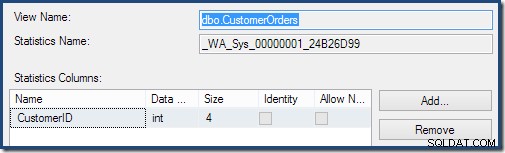
Dwukrotne kliknięcie obiektu statystyk potwierdza, że został on utworzony z kolumny Identyfikator klienta w widoku (nie w tabeli bazowej):
Widoki indeksowane mogą poprawić szacowanie liczebności
Nadal korzystając z wersji Standard Edition, teraz usuwamy i odtwarzamy zindeksowany widok (co również usuwa statystyki widoku) i ponownie wykonujemy zapytanie, tym razem z NOEXPAND wskazówka skomentowana:
SELECT CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)GDZIE CO.ProductID POMIĘDZY 711 A 718GROUP BY CO.CustomerID;
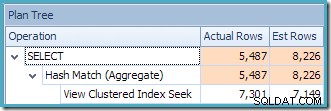
Zgodnie z oczekiwaniami podczas korzystania z wersji standardowej bez NOEXPAND , wynikowy plan zapytania działa na tabelach podstawowych, a nie bezpośrednio na widoku:

Trójkąt ostrzegawczy na operatorze głównym w powyższym planie ostrzega nas o potencjalnie przydatnym indeksie w tabeli Szczegóły zamówienia sprzedaży, co nie jest ważne dla naszych obecnych celów. Ta kompilacja nie tworzy żadnych statystyk dotyczących indeksowanego widoku. Jedyną statystyką w widoku po kompilacji zapytania jest ta powiązana z indeksem klastrowym:
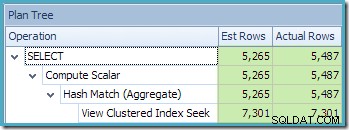
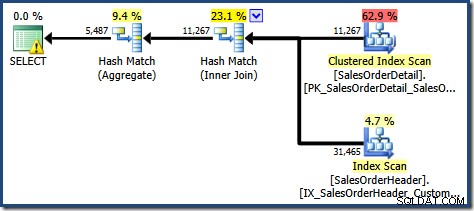
Widok drzewa planu dla zapytania pokazuje, że szacowanie liczności jest poprawne dla dwóch skanów tabeli i złączenia, ale nieco gorsze dla innych operatorów planu:
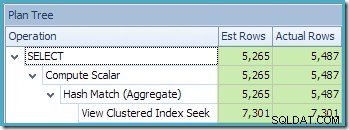
Używanie indeksowanego widoku z NOEXPAND wskazówka zaowocowała dokładniejszymi szacunkami dla naszego zapytania testowego, ponieważ lepszej jakości informacje były dostępne ze statystyk dotyczących widoku – w szczególności statystyk powiązanych z indeksem widoku.
Zgodnie z ogólną zasadą, dokładność informacji statystycznych spada dość szybko w miarę ich przechodzenia i jest modyfikowana przez operatory planu zapytań. Proste sprzężenia często nie są pod tym względem złe, ale informacja o wyniku agregacji często nie jest lepsza niż świadome przypuszczenie. Zapewnienie optymalizatorowi zapytań dokładniejszych informacji przy użyciu statystyk dotyczących widoków indeksowanych może być użyteczną techniką zwiększania jakości i niezawodności planu.
Widok bez NOEXPAND może dać gorszy plan
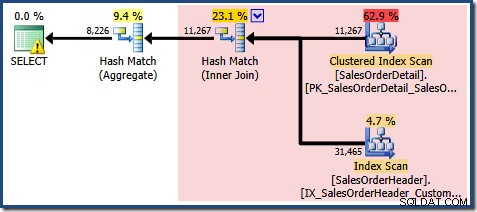
Plan zapytań pokazany powyżej (wersja standardowa, bez NOEXPAND ) jest w rzeczywistości mniej optymalna, niż gdybyśmy sami napisali zapytanie w tabelach podstawowych, zamiast pozwolić optymalizatorowi zapytań na rozszerzenie widoku. Poniższe zapytanie wyraża to samo wymaganie logiczne, ale nie odnosi się do widoku:
SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID BETWEEN 711 AND 718GROUP BY SOH.CustomerID;
To zapytanie generuje następujący plan wykonania:
Ten plan zawiera o jedną operację agregacji mniej niż wcześniej. Gdy zastosowano rozszerzenie widoku, optymalizator zapytań niestety nie był w stanie usunąć nadmiarowej operacji agregacji, co skutkowało mniej wydajnym planem wykonania. Ostateczne oszacowanie kardynalności dla nowego zapytania jest również nieco lepsze niż w przypadku odwołania do zindeksowanego widoku bez NOEXPAND :
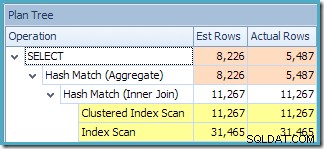
Niemniej jednak najlepsze oszacowania to nadal te, które powstają podczas odwoływania się do indeksowanego widoku za pomocą NOEXPAND (powtórzone poniżej dla wygody):
Edycja Enterprise i dopasowanie widoku
W przypadku wystąpienia Enterprise Edition optymalizator zapytań może być w stanie użyć widoku indeksowanego, nawet jeśli zapytanie nie wymienia jawnie widoku. Jeśli optymalizator jest w stanie dopasować część drzewa zapytania do widoku indeksowanego, może to zrobić na podstawie oszacowania kosztów korzystania z widoku lub nie. Logika dopasowywania widoków jest dość sprytna, ale ma ograniczenia, które w praktyce można łatwo znaleźć. Nawet w przypadku pomyślnego dopasowania widoków optymalizator może zostać wprowadzony w błąd przez niedokładne oszacowanie kosztów.
Wskazówka do zapytania EXPAND VIEWS
Zaczynając od rzadszych możliwości, mogą wystąpić sytuacje, w których zapytanie odwołuje się do widoku indeksowanego, ale lepszy plan można uzyskać, uzyskując dostęp do tabel podstawowych. W takich okolicznościach wskazówka dotycząca zapytania EXPAND VIEWS można użyć:
SELECT CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CWHERE CO.ProductID BETWEEN 711 I 718GROUP BY CO.CustomerIDOPTION (ROZWIŃ WIDOKI);
W wersji Enterprise to zapytanie generuje ten sam plan, co w wersji Standard Edition, gdy NOEXPAND wskazówka została pominięta (w tym nadmiarowa operacja agregacji):

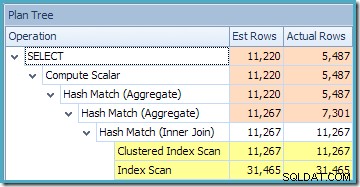
Na marginesie, EXPAND VIEWS podpowiedź jest moim zdaniem kiepsko nazwana. SQL Server zawsze rozszerza definicje widoków w zapytaniu, chyba że NOEXPAND wskazówka jest określona. EXPAND VIEWS wskazówka wyłącza reguły w optymalizatorze, które mogą dopasować części rozwiniętego drzewa z powrotem do widoków indeksowanych. W przypadku braku jakiejkolwiek wskazówki SQL Server najpierw rozszerza widok do definicji tabeli bazowej, a następnie rozważa dopasowanie z powrotem do widoków indeksowanych. Lepsza nazwa dla EXPAND VIEWS wskazówka mogła być DISABLE INDEXED VIEW MATCHING , ponieważ to właśnie robi.
EXPAND VIEWS wskazówka jest prawdopodobnie najczęściej używana, aby zapobiec dopasowaniu zapytania dotyczącego tabel bazowych do indeksowanego widoku:
SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID POMIĘDZY GRUPAMI 711 A 718 WEDŁUG WIDOKÓW SOH.IDOPCJA KLIENTA (EXP)>Wskazówka dotycząca zapytania skutkuje tym samym planem wykonania i oszacowaniami, które były widoczne, gdy używaliśmy wersji Standard Edition i tym samym zapytaniem zawierającym tylko tabelę podstawową:
Dopasowywanie widoków korporacyjnych i statystyki
Nawet w wersji Enterprise Edition statystyki widoku bez indeksu są nadal tworzone tylko wtedy, gdy
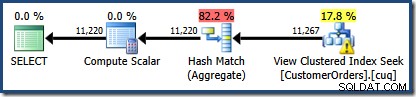
NOEXPANDpodpowiedź jest używana. Aby było to absolutnie jasne, funkcja dopasowywania widoków tylko dla przedsiębiorstw nigdy nie powoduje tworzenia ani aktualizowania statystyk widoków. To nieintuicyjne zachowanie warto trochę zbadać, ponieważ może mieć zaskakujące skutki uboczne.Teraz wykonujemy nasze podstawowe zapytanie względem widoku w instancji Enterprise Edition, bez żadnych wskazówek:
SELECT CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CWHERE CO.ProductID BETWEEN 711 AND 718GROUP BY CO.CustomerID;
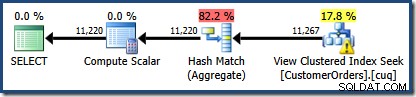
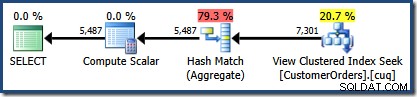
Nowością jest trójkąt ostrzegawczy w polu View Clustered Index Seek. Etykietka pokazuje szczegóły:
Nie użyliśmy
NOEXPANDwskazówka, więc statystyki dotyczące kolumny Customer ID indeksowanego widoku nie były tworzone automatycznie. W tym uproszczonym przykładzie statystyki dotyczące identyfikatora klienta nie są tak naprawdę ważne, ale nie zawsze tak będzie.Ciekawe szacunki liczebności
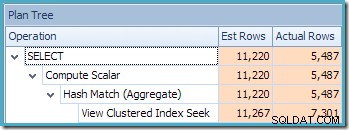
Drugą interesującą rzeczą jest to, że oszacowania kardynalności wydają się gorsze niż jakikolwiek inny przypadek, z jakim mieliśmy do czynienia do tej pory, w tym przykłady w wersji Standard Edition.
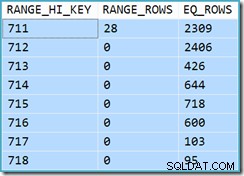
Początkowo trudno jest stwierdzić, skąd wzięły się oszacowania kardynalności dla wyszukiwania indeksowego widoku klastrowego (11 267). Oczekujemy, że oszacowanie będzie oparte na informacjach z histogramu identyfikatora produktu ze statystyk powiązanych z indeksem klastrowym widoku. Odpowiednia część tego histogramu jest pokazana poniżej:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') Z HISTOGRAMEM;
Biorąc pod uwagę, że tabela nie została zmodyfikowana od czasu utworzenia statystyk, oczekujemy, że oszacowanie będzie prostą sumą RANGE_ROWS i EQ_ROWS dla wartości identyfikatora produktu z zakresu od 711 do 718 (zwróć uwagę, że oszacowanie powinno wykluczać 28 RANGE_ROWS pokazanych względem wpisu 711 ponieważ te wiersze istnieją poniżej wartości klucza 711). Suma pokazanych EQ_ROWS wynosi 7301. Jest to dokładnie liczba wierszy faktycznie zwróconych przez widok – skąd więc wzięło się oszacowanie 11 267?
Odpowiedź tkwi w sposobie, w jaki obecnie działa dopasowywanie widoków. W naszym zapytaniu nie określono parametru
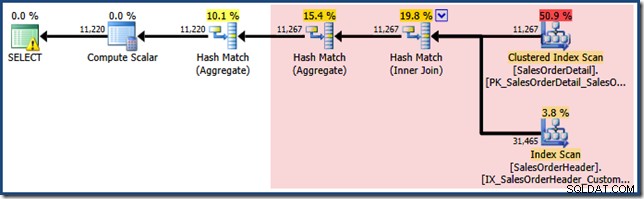
NOEXPANDwskazówka, więc początkowe oszacowania kardynalności są oparte na drzewie zapytań rozszerzonych o widok. Najłatwiej to zobaczyć, ponownie przyglądając się szacunkowemu planowi dla tego samego zapytania za pomocąEXPAND VIEWSokreślono:
Zacieniony na czerwono obszar reprezentuje część drzewa, która jest zastępowana przez działanie dopasowujące widok. Kardynalność wyjściowa z tego obszaru wynosi 11267. Niezacieniona część z oszacowaniem 11 220 nie ma wpływu na dopasowanie widoków. To są dokładnie te szacunki, które chcieliśmy wyjaśnić:
Dopasowywanie widoków po prostu zastąpiło zacieniony na czerwono obszar logicznie równoważnym wyszukiwaniem w zindeksowanym widoku. Nie wykorzystał informacji statystycznych z widoku do ponownego obliczenia oszacowania kardynalności.
Do pewnego stopnia możesz prawdopodobnie docenić, dlaczego może to działać w ten sposób:ogólnie rzecz biorąc, nie ma powodu, aby oczekiwać, że oszacowanie obliczone na podstawie jednego zestawu informacji statystycznych jest lepsze od drugiego. Można założyć, że zindeksowane statystyki widoku są bardziej dokładne w tym miejscu w porównaniu ze statystykami uzyskanymi po połączeniu w zacienionym na czerwono obszarze, ale może być trudne uogólnienie tego lub prawidłowe obliczenie, jak szybko różne źródła informacje statystyczne mogą stać się nieaktualne, gdy podstawowe dane ulegną zmianie.
Można również argumentować, że gdybyśmy byli tak pewni, że informacje o zindeksowanym widoku są lepsze, użylibyśmy
NOEXPANDwskazówka.Jeszcze bardziej ciekawe szacunki dotyczące liczebności
Jeszcze ciekawsza sytuacja pojawia się w wersji Enterprise Edition, jeśli piszemy zapytanie w tabelach podstawowych i polegamy na automatycznym dopasowywaniu widoków:
SELECT SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID BETWEEN 711 AND 718GROUP BY SOH.CustomerID;
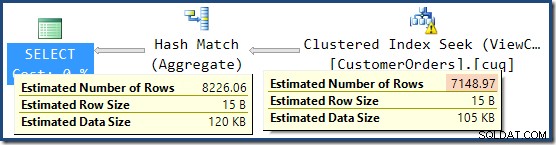
Ostrzeżenie o braku statystyk jest takie samo jak wcześniej i ma to samo wyjaśnienie. Bardziej interesującą cechą jest to, że mamy teraz niższe oszacowanie liczby wierszy wygenerowanych przez funkcję View Clustered Index Seek (7149) i zwiększone oszacowanie liczby wierszy zwracanych z agregacji (8226).
Aby podkreślić ten punkt, ten plan zapytania wydaje się opierać na pomyśle, że 7149 wierszy źródłowych można zagregować w celu uzyskania 8226 wierszy!
Część wyjaśnienia jest taka sama jak poprzednio.
EXPAND VIEWSplan zapytania, pokazujący czerwony region, który zostanie zastąpiony przez dopasowanie widoku, jest pokazany poniżej:
To wyjaśnia, skąd pochodzi ostateczne oszacowanie 8226, ale co z szacunkami 7149 wierszy? Zgodnie z logiką widzianą wcześniej, wydaje się, że widok powinien pokazywać szacunkową liczbę 11 267 wierszy?
Odpowiedź brzmi, że oszacowanie 7149 jest zgadywaniem. Tak naprawdę. Indeksowany widok zawiera łącznie 79 433 wierszy. Procent magicznego przypuszczenia dla predykatu ID produktu BETWEEN wynosi 9% – co daje 0,09 * 79433 =7148,97 wierszy. Plan zapytań SSMS pokazuje, że to obliczenie jest dokładnie poprawne, nawet przed zaokrągleniem:
W tej sytuacji wydaje się, że optymalizator programu SQL Server wolał zgadywanie oparte na liczności zindeksowanego widoku nad oszacowaną licznością po połączeniu z zastąpionego poddrzewa. Ciekawy.
Podsumowanie
Korzystanie z
NOEXPANDwskazówka gwarantuje, że widok indeksowany będzie używany w ostatecznym planie kwerendy i umożliwia automatyczne tworzenie, konserwację i używanie statystyk nieindeksowych przez optymalizator kwerend. Korzystanie zNOEXPANDzapewnia również, że początkowe szacunki liczności są oparte na zindeksowanych informacjach o widoku, a nie na podstawie tabel podstawowych.Jeśli
NOEXPANDnie jest określony, odwołania widoków są zawsze zastępowane ich definicjami tabel bazowych przed rozpoczęciem kompilacji zapytania (a zatem przed wstępnym oszacowaniem liczności). Tylko w jednostkach SKU Enterprise widoki indeksowane mogą zostać zastąpione z powrotem w drzewie zapytań później w procesie optymalizacji.
EXPAND VIEWSwskazówka dotycząca zapytania uniemożliwia optymalizatorowi wykonanie dopasowywania widoków indeksowanych w wersji Enterprise Edition. Ma to zastosowanie niezależnie od tego, czy zapytanie pierwotnie odwoływało się do indeksowanego widoku, czy nie. Podczas dopasowywania widoków istniejąca szacunkowa kardynalność może w pewnych okolicznościach zostać zastąpiona domysłem.Statystyki pokazane jako brakujące w zindeksowanym widoku mogą być tworzone ręcznie, ale optymalizator generalnie nie będzie ich używał do zapytań, które nie używają
NOEXPANDwskazówka.Korzystanie z widoków indeksowanych może poprawić szacowanie kardynalności, szczególnie jeśli widok zawiera sprzężenia lub agregacje. Zapytania mają największą szansę na skorzystanie z dokładniejszych statystyk wyświetleń, jeśli
NOEXPANDjest określony.