W 2012 roku napisałem tutaj post na blogu, w którym przedstawiłem podejścia do obliczania mediany. W tym poście zajmowałem się bardzo prostym przypadkiem:chcieliśmy znaleźć medianę kolumny w całej tabeli. Od tego czasu wielokrotnie mi wspominano, że bardziej praktycznym wymogiem jest obliczenie mediany podzielonej na partycje . Podobnie jak w przypadku podstawowym, istnieje wiele sposobów rozwiązania tego problemu w różnych wersjach SQL Server; nic dziwnego, że niektóre działają znacznie lepiej niż inne.
W poprzednim przykładzie mieliśmy tylko ogólne kolumny id i val. Uczyńmy to bardziej realistycznym i powiedzmy, że mamy sprzedawców i liczbę sprzedaży, które dokonali w pewnym okresie. Aby przetestować nasze zapytania, utwórzmy najpierw prostą stertę z 17 wierszami i sprawdźmy, czy wszystkie dają oczekiwane wyniki (Sprzedaż 1 ma medianę 7,5, a Sprzedawca 2 ma medianę 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Oto zapytania, które będziemy testować (z dużo większą ilością danych!) względem powyższej sterty, a także z indeksami pomocniczymi. Odrzuciłem kilka zapytań z poprzedniego testu, które albo w ogóle się nie skalowały, albo nie były zbyt dobrze mapowane na partycjonowane mediany (mianowicie 2000_B, który używał tabeli #temp i 2005_A, który używał przeciwnego wiersza liczby). Dodałem jednak kilka ciekawych pomysłów z niedawnego artykułu autorstwa Dwaina Camps (@DwainCSQL), który powstał na podstawie mojego poprzedniego postu.
SQL Server 2000+
Jedyną metodą z poprzedniego podejścia, która działała wystarczająco dobrze na SQL Server 2000, aby uwzględnić ją nawet w tym teście, było podejście „min jednej połowy, maksimum drugiej”:
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Szczerze próbowałem naśladować wersję tabeli #temp, której użyłem w prostszym przykładzie, ale w ogóle nie skalowała się dobrze. W 20 lub 200 rzędach działało dobrze; w 2000 roku zajęło to prawie minutę; na 1 000 000 zrezygnowałem po godzinie. Zamieściłem to tutaj dla potomności (kliknij, aby odkryć).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Wykorzystuje to dwie różne funkcje okienkowania, aby uzyskać sekwencję i ogólną liczbę kwot przypadających na sprzedawcę.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
To pochodzi z artykułu Dwaina Campsa, który robi to samo, co powyżej, w nieco bardziej rozbudowany sposób. To zasadniczo przestawia interesujące wiersze w każdej grupie.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Było to oparte na sugestii Adama Machanica w komentarzach do mojego poprzedniego postu, a także wzmocnione przez Dwaina w jego artykule powyżej.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Jest to podobne do „2005+1” powyżej, ale zamiast używać COUNT(*) OVER() aby uzyskać liczby, wykonuje samosprzężenie z izolowanym agregatem w tabeli pochodnej.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Był to bardzo interesujący wkład od innego MVP SQL Server Petera „Peso” Larssona (@SwePeso) w komentarzach do artykułu Dwaina; używa CROSS APPLY i nowy OFFSET / FETCH funkcjonalność w jeszcze bardziej interesujący i zaskakujący sposób niż rozwiązanie Itzika do prostszego obliczania mediany.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Wreszcie mamy nową PERCENTILE_CONT() funkcja wprowadzona w SQL Server 2012.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; Prawdziwe testy
Aby przetestować wydajność powyższych zapytań, zbudujemy znacznie bardziej rozbudowaną tabelę. Będziemy mieć 100 unikalnych sprzedawców, każdy z 10 000 wartościami sprzedaży, co daje łącznie 1 000 000 wierszy. Zamierzamy również uruchomić każde zapytanie względem sterty bez zmian, z dodanym indeksem nieklastrowym na (SalesPerson, Amount) i z indeksem klastrowym w tych samych kolumnach. Oto konfiguracja:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
A oto wyniki powyższych zapytań, względem sterty, indeksu nieklastrowego i indeksu klastrowego:
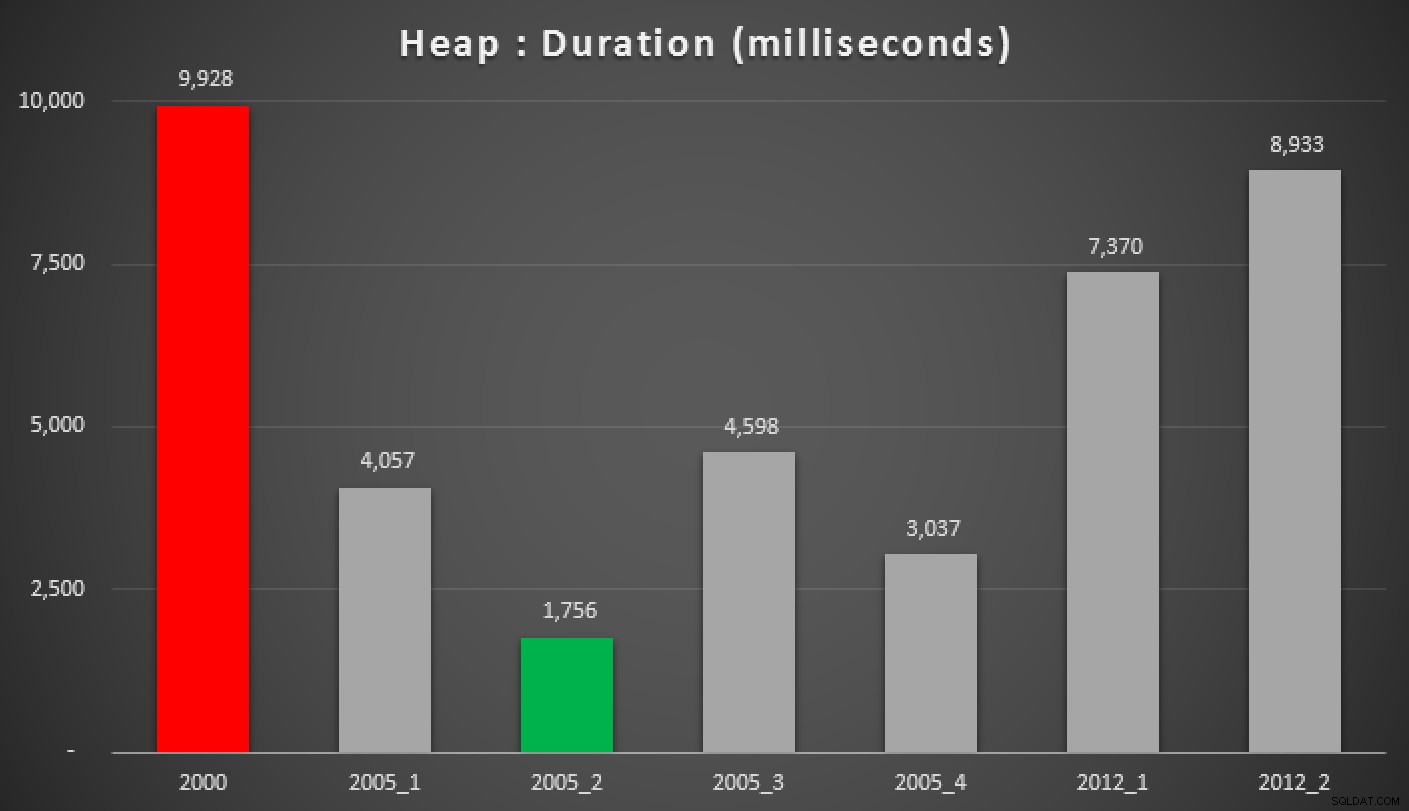
Czas trwania w milisekundach różnych zgrupowanych podejść do mediany (w stosunku do stos)
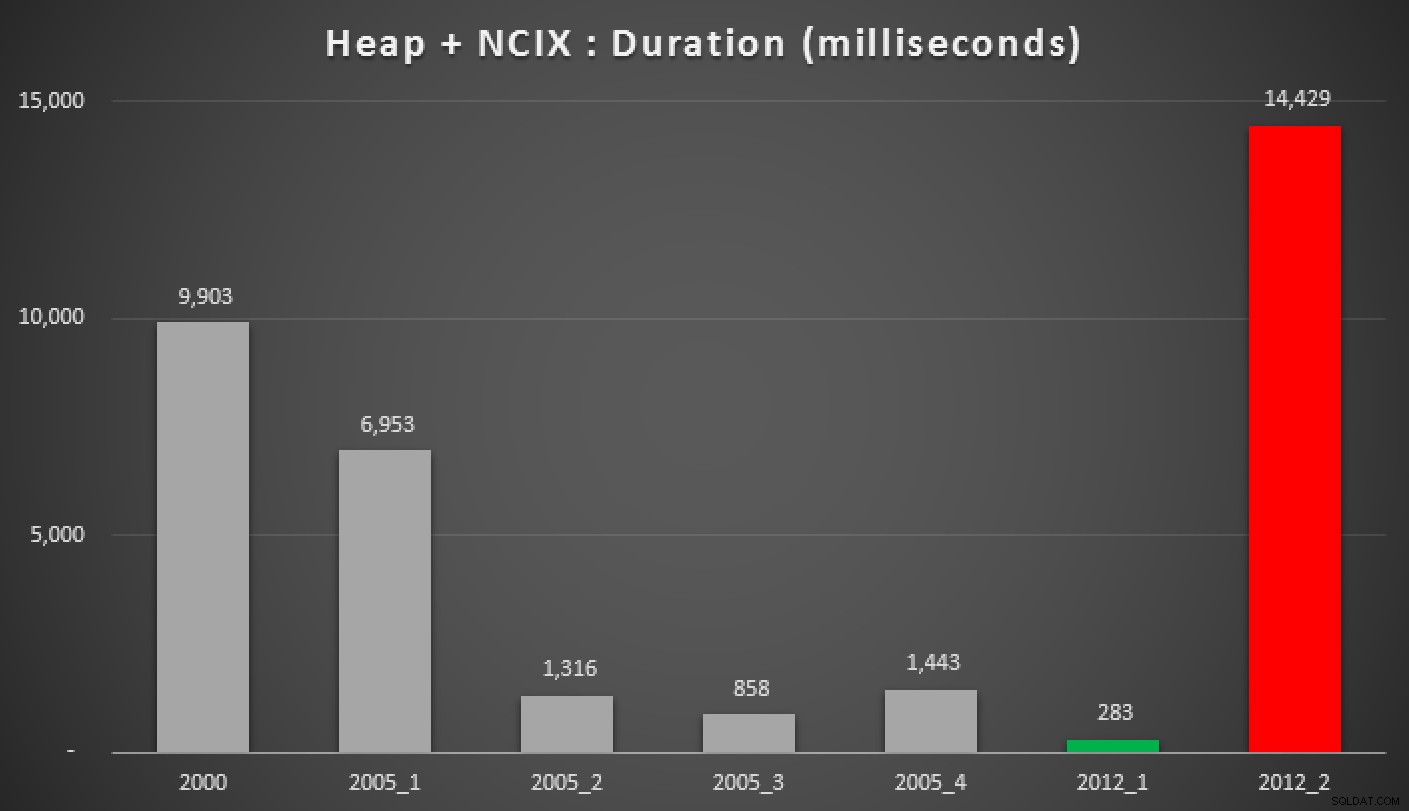
Czas trwania w milisekundach różnych zgrupowanych podejść do mediany (w stosunku do stos z indeksem nieklastrowym)
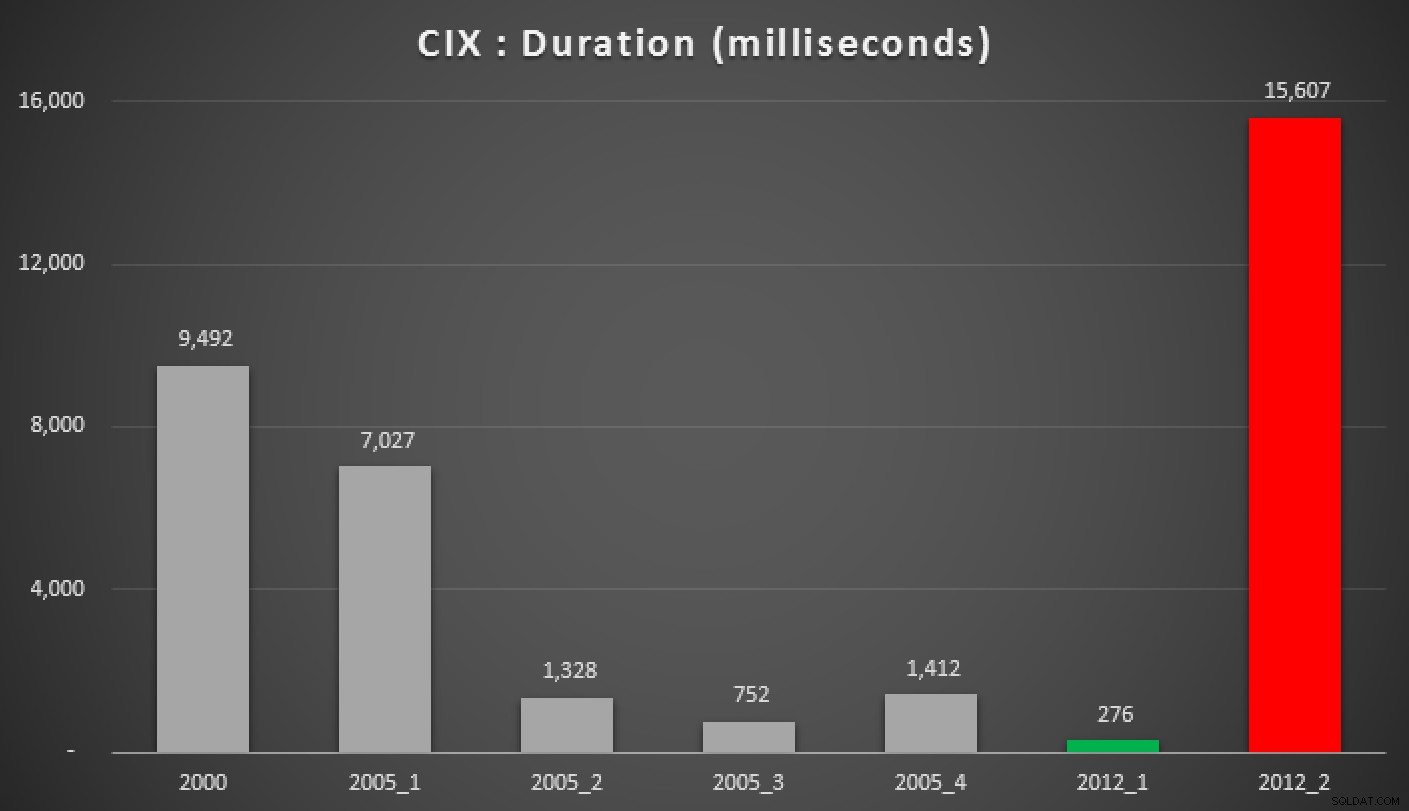
Czas trwania w milisekundach różnych zgrupowanych podejść do mediany (w stosunku do indeks klastrowy)
A co z Hekatonem?
Oczywiście byłem ciekaw, czy ta nowa funkcja w SQL Server 2014 może pomóc w którymkolwiek z tych zapytań. Utworzyłem więc bazę danych In-Memory, dwie wersje tabeli Sales In-Memory (jedna z indeksem skrótu na (SalesPerson, Amount) , a drugi po prostu (SalesPerson) ) i ponownie przeprowadziłem te same testy:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Wyniki:
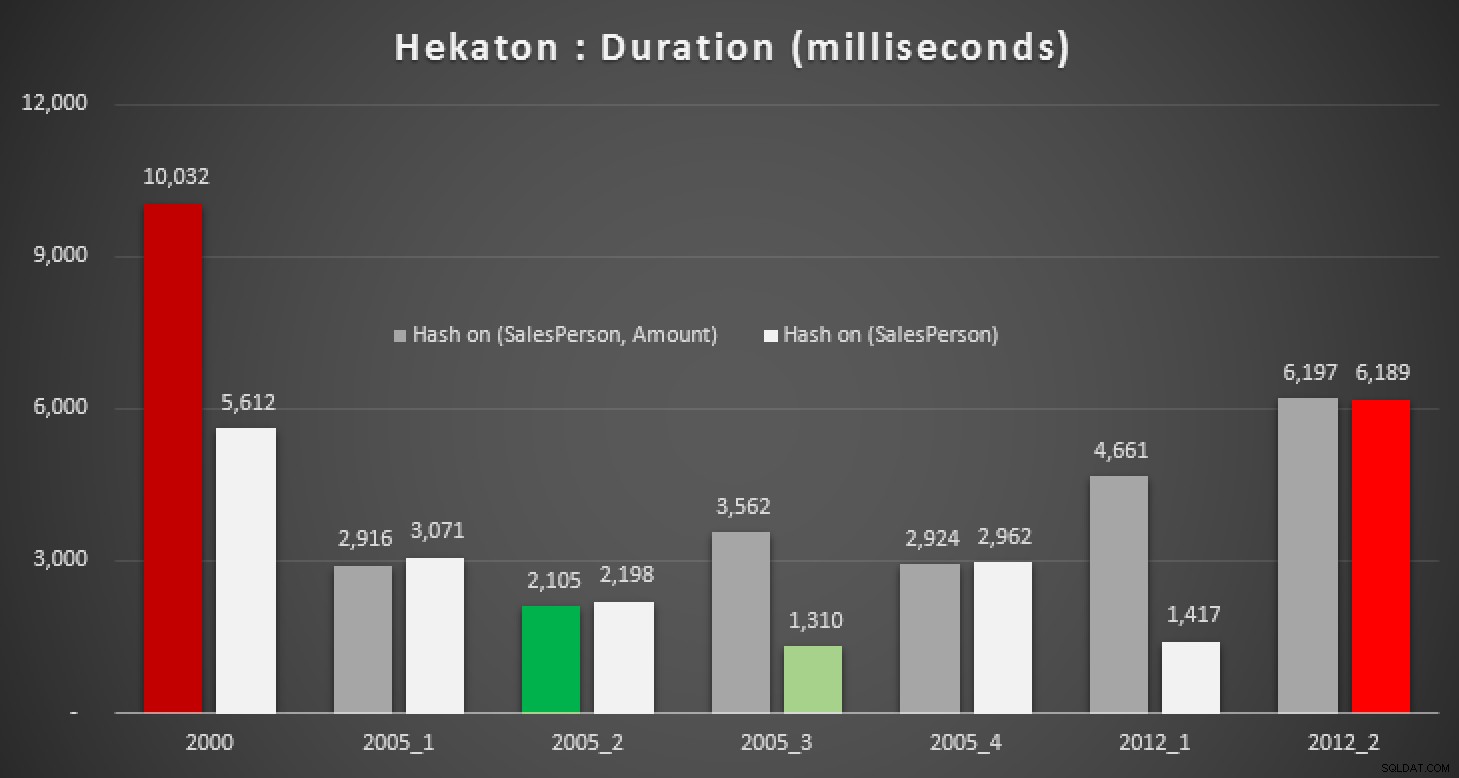
Czas trwania w milisekundach dla różnych obliczeń mediany w pamięci stoły
Nawet przy prawidłowym indeksie mieszającym nie widzimy znaczących ulepszeń w stosunku do tradycyjnej tabeli. Co więcej, próba rozwiązania problemu mediany za pomocą natywnie skompilowanej procedury składowanej nie będzie łatwym zadaniem, ponieważ wiele konstrukcji językowych użytych powyżej jest niepoprawnych (kilka z nich też mnie zaskoczyło). Próba skompilowania wszystkich powyższych odmian zapytań spowodowała tę paradę błędów; niektóre wystąpiły wielokrotnie w ramach każdej procedury, a nawet po usunięciu duplikatów jest to nadal trochę komiczne:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000Opcja „DISTINCT” nie jest obsługiwana z natywnie skompilowanymi procedurami składowanymi.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2000
Podzapytania ( zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Poziom 16, Stan 48, Procedura GroupedMedian_2000
Opcja „PERCENT” nie jest obsługiwana w przypadku natywnie skompilowanych procedur składowanych.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_1
Podzapytania (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Level 16, State 91 , Procedura GroupedMedian_2005_1
Funkcja agregująca „NUMER WIERSZY” nie jest obsługiwana z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Poziom 16, Stan 56, Procedura GroupedMedian_2005_1
Operator „IN” nie jest obsługiwany z natywnie skompilowane procedury składowane.
Msg 12310, Poziom 16, stan 36, procedura GroupedMedian_2005_2
Common Table Expressions (CTE) nie są obsługiwane z natywnie kompilowanymi procedurami składowanymi.
Msg 12309, Level 16, State 35, Procedure GroupedMedian_2005_2
Wyciągi formularza INSERT…VALUES…, które wstawiają wiele wierszy, nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, poziom 16, stan 53, procedura GroupedMedian_2005_2
Operator „ZASTOSUJ” nie jest obsługiwany w przypadku natywnie skompilowanych procedur składowanych.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_2
Podzapytania (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_2
Funkcja agregująca „ROW_NUMBER” nie jest obsługiwana z natywnie kompilowanymi procedurami składowanymi.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Wspólne wyrażenia tabeli (CTE) są nieobsługiwane z natywnie skompilowanymi składowanymi procedur.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_3
Podzapytania (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Level 16, State 91 , Procedura GroupedMedian_2005_3
Funkcja agregująca 'NUMER WIERSZ' nie jest obsługiwana z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Poziom 16, Stan 53, Procedura GroupedMedian_2005_3
Operator 'ZASTOSUJ' nie jest obsługiwany z natywnie skompilowane procedury składowane.
Msg 12311, poziom 16, stan 37, procedura GroupedMedian_2005_4
Podkwerendy (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane w przypadku natywnie skompilowanych procedur składowanych.
Msg 10794, poziom 16, stan 91, procedura GroupedMedian_2005_4
Funkcja agregująca „ROW_NUMBER” nie jest obsługiwana z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_4
Operator „IN” nie jest obsługiwany przez natywnie skompilowany magazyn ed procedur.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Podzapytania (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Poziom 16, stan 38, procedura GroupedMedian_2012_1
Operator „OFFSET” nie jest obsługiwany z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2012_1
Operator „APPLY” nie jest obsługiwany z natywnie skompilowanymi procedurami składowanymi.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_2
Podzapytania (zapytania zagnieżdżone w innym zapytaniu) nie są obsługiwane z natywnie skompilowanymi procedurami składowanymi.
Msg 10794, poziom 16, stan 90, procedura GroupedMedian_2012_2
Funkcja agregująca „PERCENTILE_CONT” nie jest obsługiwana w przypadku natywnie skompilowanych procedur składowanych.
Jak napisano obecnie, żadne z tych zapytań nie mogło zostać przeniesione do natywnie skompilowanej procedury składowanej. Być może coś, na co warto zwrócić uwagę, aby znaleźć kolejny post.
Wniosek
Odrzucenie wyników Hekaton, a gdy obecny jest indeks pomocniczy, zapytanie Petera Larssona („2012+ 1”) przy użyciu OFFSET/FETCH okazał się dalekim zwycięzcą w tych testach. Chociaż jest to nieco bardziej złożone niż równoważne zapytanie w testach niepartycjonowanych, jest to zgodne z wynikami, które zaobserwowałem ostatnio.
W tych samych przypadkach 2000 MIN/MAX podejście i 2012 PERCENTILE_CONT() wyszły jak prawdziwe psy; znowu, tak jak moje poprzednie testy w prostszym przypadku.
Jeśli nie korzystasz jeszcze z SQL Server 2012, następną najlepszą opcją jest „2005+ 3” (jeśli masz indeks pomocniczy) lub „2005+ 2”, jeśli masz do czynienia ze stertą. Przepraszam, że musiałem wymyślić dla nich nowy schemat nazewnictwa, głównie po to, aby uniknąć pomyłek z metodami w moim poprzednim poście.
Oczywiście są to moje wyniki w odniesieniu do bardzo konkretnego schematu i zestawu danych – podobnie jak w przypadku wszystkich zaleceń, należy przetestować te podejścia w odniesieniu do własnego schematu i danych, ponieważ inne czynniki mogą wpływać na różne wyniki.
Jeszcze jedna uwaga
Oprócz słabej wydajności i braku obsługi w natywnie skompilowanych procedurach składowanych, jeszcze jeden problem związany z PERCENTILE_CONT() jest to, że nie można go używać w starszych trybach zgodności. Jeśli spróbujesz, pojawi się ten błąd:
Funkcja PERCENTILE_CONT nie jest dozwolona w bieżącym trybie zgodności. Jest to dozwolone tylko w trybie 110 lub wyższym.