Bycie odpowiedzialnym za wydajność SQL Server może być trudnym zadaniem. Jest wiele obszarów, które musimy monitorować i rozumieć. Oczekuje się również, że będziemy w stanie być na bieżąco z tymi wszystkimi wskaźnikami i przez cały czas wiedzieć, co dzieje się na naszych serwerach. Lubię pytać administratorów baz danych, jaka jest pierwsza rzecz, o której myślą, gdy słyszą frazę „dostrajanie SQL Server”; przytłaczającą odpowiedzią, jaką otrzymuję, jest „dostrajanie zapytań”. Zgadzam się, że dostrajanie zapytań jest bardzo ważne i jest niekończącym się zadaniem, przed którym stoimy, ponieważ obciążenia ciągle się zmieniają.
Istnieje jednak wiele innych aspektów, które należy wziąć pod uwagę, myśląc o wydajności SQL Server. Istnieje wiele ustawień na poziomie instancji, systemu operacyjnego i bazy danych, które należy poprawić z wartości domyślnych. Bycie konsultantem pozwala mi pracować w wielu różnych branżach i mieć kontakt z wszelkiego rodzaju problemami z wydajnością. Pracując z nowym klientem staram się zawsze wykonać audyt stanu serwera, aby wiedzieć z czym mam do czynienia. Podczas przeprowadzania tych audytów jedną z rzeczy, które wielokrotnie odkryłem, były nadmierne opóźnienia odczytu i zapisu na dyskach, na których znajdują się dane i pliki dziennika SQL Server.
Opóźnienie odczytu/zapisu
Aby wyświetlić opóźnienia dysku w programie SQL Server, możesz szybko i łatwo wysłać zapytanie do DMV sys.dm_io_virtual_file_stats . Ten DMV akceptuje dwa parametry:database_id i identyfikator_pliku . Niesamowite jest to, że możesz przekazać NULL jako obie wartości i zwracają opóźnienia dla wszystkich plików dla wszystkich baz danych. Kolumny wyjściowe obejmują:
- identyfikator bazy danych
- identyfikator_pliku
- przykład_ms
- liczba_odczytań
- liczba_przeczytanych_bajtów
- io_stall_read_ms
- liczba_zapisów
- liczba_bajtów_zapisanych
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- uchwyt_pliku
Jak widać z listy kolumn, istnieją naprawdę przydatne informacje, które ten DMV pobiera, jednak po prostu uruchamiając SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); niewiele pomaga, chyba że zapamiętałeś swoje identyfikatory database_id i potrafisz policzyć w głowie.
Kiedy pytam o statystyki plików, używam zapytania z postu na blogu Paula Randala „Jak zbadać opóźnienia podsystemu IO z poziomu SQL Server”. Ten skrypt ułatwia odczytywanie nazw kolumn, zawiera dysk, na którym znajduje się plik, nazwę bazy danych i ścieżkę do pliku.
Wysyłając zapytanie do tego DMV, możesz łatwo określić, gdzie znajdują się punkty aktywne we/wy dla Twoich plików. Możesz zobaczyć, gdzie są największe opóźnienia zapisu i odczytu i które bazy danych są winowajcami. Wiedza o tym pozwoli Ci zacząć przyglądać się możliwościom dostrajania tych konkretnych baz danych. Może to obejmować dostrajanie indeksu, sprawdzanie, czy pula buforów jest pod obciążeniem pamięci, prawdopodobnie przeniesienie bazy danych do szybszej części podsystemu we/wy lub ewentualnie partycjonowanie bazy danych i rozłożenie grup plików na inne jednostki LUN.
Uruchamiasz zapytanie i zwraca ono wiele wartości w ms dla opóźnienia — które wartości są w porządku, a które są złe?
Jakie wartości są dobre, a jakie złe?
Jeśli zapytasz SQLskills, powiemy Ci coś w stylu:
- Doskonały:<1ms
- Bardzo dobrze:<5ms
- Dobry:5 – 10 ms
- Zły:10 – 20 ms
- Źle:20 – 100 ms
- Naprawdę źle:100 – 500 ms
- OMG!:> 500ms
Jeśli przeprowadzisz wyszukiwanie w Bing, znajdziesz artykuły firmy Microsoft zawierające zalecenia podobne do:
- Dobrze:<10 ms
- W porządku:10 – 20 ms
- Źle:20 – 50 ms
- Poważnie źle:> 50 ms
Jak widać, są pewne niewielkie różnice w liczbach, ale konsensus jest taki, że wszystko powyżej 20 ms może być uważane za kłopotliwe. Mając to na uwadze, Twoje średnie opóźnienie zapisu może wynosić 20 ms i jest to w 100% akceptowalne dla Twojej organizacji i to jest w porządku. Musisz znać ogólne opóźnienia we/wy dla swojego systemu, aby wiedzieć, co jest normalne, gdy coś się psuje.
Moje opóźnienia odczytu/zapisu są złe, co mam zrobić?
Jeśli zauważysz, że opóźnienia odczytu i zapisu na Twoim serwerze są złe, istnieje kilka miejsc, w których możesz zacząć szukać problemów. To nie jest pełna lista, ale wskazówki, od czego zacząć.
- Przeanalizuj swoje obciążenie pracą. Czy Twoja strategia indeksowania jest prawidłowa? Brak odpowiednich indeksów spowoduje, że z dysku zostanie odczytanych znacznie więcej danych. Skanuje zamiast szuka.
- Czy Twoje statystyki są aktualne? Złe statystyki mogą utrudniać wybór planów wykonania.
- Czy masz problemy z podsłuchiwaniem parametrów, które powodują słabe plany wykonania?
- Czy pula buforów jest pod presją pamięci, na przykład z nadętej pamięci podręcznej planu?
- Masz problemy z siecią? Czy twoja sieć SAN działa poprawnie? Poproś inżyniera pamięci masowej o sprawdzenie ścieżki i sieci.
- Przenieś punkty aktywne do różnych macierzy pamięci masowej. W niektórych przypadkach może to być pojedyncza baza danych lub tylko kilka baz danych, które powodują wszystkie problemy. Wyizolowanie ich na inny zestaw dysków lub szybszy dysk wysokiej klasy, taki jak SSD, może być najlepszym logicznym rozwiązaniem.
- Czy możesz podzielić bazę danych na partycje, aby przenieść kłopotliwe tabele na inny dysk, aby rozłożyć obciążenie?
Statystyki oczekiwania
Podobnie jak monitorowanie statystyk plików, monitorowanie statystyk oczekiwania może wiele powiedzieć o wąskich gardłach w Twoim środowisku. Mamy szczęście, że mamy kolejny niesamowity DMV (sys.dm_os_wait_stats ), że możemy wykonać zapytanie, które pobierze wszystkie dostępne informacje o czekaniu zebrane od ostatniego restartu lub od ostatniego zresetowania waitów; są też oczekiwania związane z wydajnością dysku. Ten DMV zwróci ważne informacje, w tym:
- wait_type
- waiting_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Wysyłanie zapytań do tego DMV na moim komputerze z programem SQL Server 2014 zwróciło 771 typów oczekiwania. SQL Server zawsze na coś czeka, ale jest wiele oczekiwań, którymi nie powinniśmy się martwić. Z tego powodu korzystam z innego zapytania od Paula Randala; jego post na blogu „Poczekaj statystyki lub powiedz mi, gdzie boli” ma doskonały skrypt, który wyklucza kilka czekań, na których tak naprawdę nie zależy. Paul wymienia również wiele typowych problematycznych oczekiwań, a także oferuje wskazówki dotyczące typowego czekania.
Dlaczego statystyki oczekiwania są ważne?
Monitorowanie długiego czasu oczekiwania na określone zdarzenia poinformuje Cię, kiedy występują problemy. Potrzebujesz punktu odniesienia, aby wiedzieć, co jest normalne i kiedy rzeczy przekraczają próg lub poziom bólu. Jeśli masz naprawdę wysoki PAGEIOLATCH_XX wtedy wiesz, że SQL Server musi czekać na odczytanie strony danych z dysku. Może to być dysk, pamięć, zmiana obciążenia lub szereg innych problemów.
Niedawny klient, z którym pracowałem, widział bardzo nietypowe zachowanie. Kiedy połączyłem się z serwerem bazy danych i mogłem obserwować serwer pod obciążeniem, natychmiast zacząłem sprawdzać statystyki plików, statystyki oczekiwania, wykorzystanie pamięci, użycie tempdb itp. Jedną rzeczą, która natychmiast się wyróżniała, był WRITELOG będąc najbardziej rozpowszechnionym czekaniem. Wiem, że to oczekiwanie ma związek z opróżnianiem dziennika na dysk i przypomniało mi serię Paula o przycinaniu tłuszczu dziennika transakcji. Wysoki WRITELOG oczekiwania można zwykle rozpoznać po dużych opóźnieniach zapisu w pliku dziennika transakcji. Użyłem więc skryptu statystyk plików, aby przejrzeć opóźnienia odczytu i zapisu na dysku. Byłem wtedy w stanie zobaczyć duże opóźnienie zapisu w pliku danych, ale nie w moim pliku dziennika. Patrząc na WRITELOG to było długie oczekiwanie, ale czas oczekiwania w ms był wyjątkowo niski. Jednak coś w drugim poście z serii Paula wciąż tkwiło w mojej głowie. Powinienem przyjrzeć się ustawieniom automatycznego wzrostu bazy danych, aby wykluczyć „Śmierć tysiąca cięć”. Patrząc na właściwości bazy danych, zauważyłem, że plik danych został ustawiony na automatyczny wzrost o 1MB, a dziennik transakcji ustawiony na automatyczny wzrost o 10%. Oba pliki miały prawie 0 niewykorzystanego miejsca. Podzieliłem się z klientem tym, co znalazłem i jak to zabijało ich wydajność. Szybko wprowadziliśmy odpowiednią zmianę i testy poszły naprzód, nawiasem mówiąc, znacznie lepiej. Niestety to nie jedyny raz, kiedy spotykam się z tym dokładnie problemem. Innym razem baza danych miała rozmiar 66 GB, wzrosła tam o 1 MB.
Przechwytywanie danych
Wielu specjalistów ds. danych stworzyło procesy do regularnego przechwytywania plików i oczekiwania na statystyki do analizy. Ponieważ statystyki oczekiwania kumulują się, warto je uchwycić i porównać delty między różnymi porami dnia lub przed i po uruchomieniu niektórych procesów. Nie jest to zbyt skomplikowane i dostępnych jest wiele postów na blogu, w których ludzie dzielą się tym, jak to osiągnęli. Ważną częścią jest mierzenie tych danych, aby można było je monitorować. Skąd możesz dzisiaj wiedzieć, że na serwerze bazy danych jest lepiej lub gorzej, chyba że znasz dane z wczoraj?
Jak SQL Sentry może pomóc?
Cieszę się, że zapytałeś! SQL Sentry Performance Advisor zapewnia opóźnienia i oczekiwania na pierwszym planie pulpitu nawigacyjnego. Wszelkie anomalie są łatwe do zauważenia; możesz przejść do trybu historycznego i zobaczyć poprzedni trend i porównać go również z poprzednimi okresami. To może okazać się bezcenne przy analizie tych „co się stało?” chwile. Każdy otrzymał taki telefon:„Wczoraj około godziny 15:00 system po prostu zawiesił się, czy możesz nam powiedzieć, co się stało?” Um, jasne, pozwól, że uruchomię Profiler i cofnę się w czasie. Jeśli masz narzędzie do monitorowania, takie jak Performance Advisor, będziesz mieć te historyczne informacje na wyciągnięcie ręki.
Oprócz wykresów i wykresów na desce rozdzielczej masz możliwość korzystania z wbudowanych alertów dotyczących warunków, takich jak wysokie oczekiwania na dysku, wysokie zliczenia VLF, wysoki poziom procesora, niska oczekiwana długość życia strony i wiele innych. Masz również możliwość tworzenia własnych niestandardowych warunków i możesz uczyć się na przykładach w witrynie SQL Sentry lub za pośrednictwem Condition Exchange (Aaron Bertrand pisał o tym na blogu). Poruszyłem stronę ostrzegania w moim ostatnim artykule na temat alertów agenta SQL Server.
Na karcie Przestrzeń dyskowa w Performance Advisor bardzo łatwo jest zobaczyć takie rzeczy, jak ustawienia autowzrostu i wysokie liczby VLF. Powinieneś wiedzieć, ale jeśli nie, automatyczny wzrost o 1 MB lub 10% nie jest najlepszym ustawieniem. Jeśli widzisz te wartości (doradca ds. wydajności podświetla je za Ciebie), możesz szybko zanotować i zaplanować czas na wprowadzenie odpowiednich korekt. Uwielbiam też sposób, w jaki wyświetla Total VLF; zbyt wiele VLF może być bardzo problematyczne. Powinieneś przeczytać post Kimberly „Dziennik transakcji VLF – za dużo czy za mało?” jeśli jeszcze tego nie zrobiłeś.
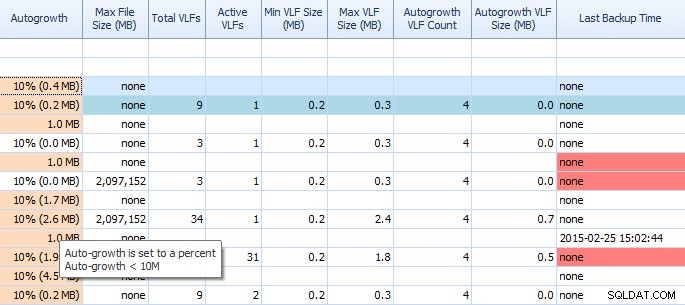 Częściowa siatka na karcie Miejsce na dysku Performance Advisor
Częściowa siatka na karcie Miejsce na dysku Performance Advisor
Innym sposobem, w jaki Performance Advisor może pomóc, jest jego opatentowany moduł Disk Activity. Tutaj widać, że tempdb na F:doświadcza znacznego opóźnienia zapisu; możesz to stwierdzić po grubych czerwonych liniach pod grafiką dysku. Możesz również zauważyć, że F:jest jedyną literą dysku, której dysk jest reprezentowany na czerwono; jest to wizualna wskazówka, że dysk ma źle wyrównaną partycję, co może przyczynić się do problemów we/wy.
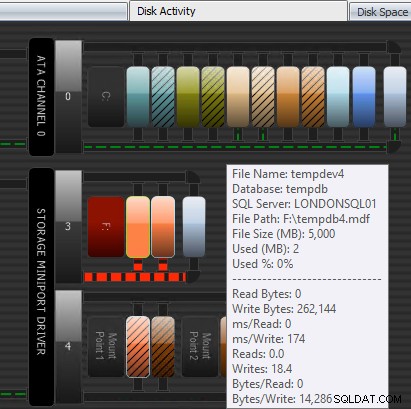 Moduł aktywności dyskowej Doradca wydajności
Moduł aktywności dyskowej Doradca wydajności
I możesz skorelować te informacje w tabelach poniżej – problemy są również tam wyróżnione i spójrz na ms/Write kolumna:
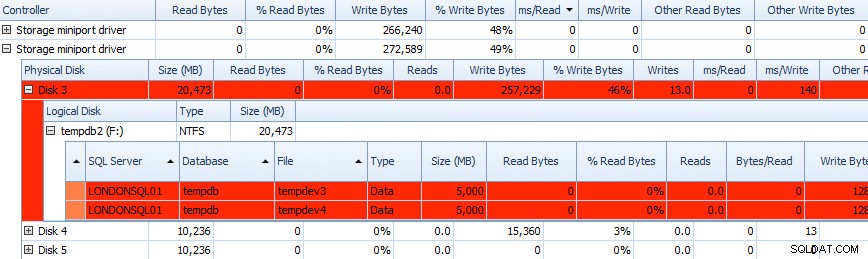 Częściowa siatka danych dotyczących aktywności dysku w programie Performance Advisor
Częściowa siatka danych dotyczących aktywności dysku w programie Performance Advisor
Możesz również spojrzeć na te informacje z mocą wsteczną; jeśli ktoś narzeka na dostrzeżone wąskie gardło dysku wczoraj po południu lub w zeszły wtorek, możesz po prostu wrócić za pomocą selektorów dat na pasku narzędzi i zobaczyć średnią przepustowość i opóźnienie dla dowolnego zakresu. Więcej informacji na temat modułu Aktywność dysku znajdziesz w Podręczniku użytkownika.
Performance Advisor ma również wiele wbudowanych raportów w kategoriach Wydajność, Blokowanie, Top SQL, Miejsce na dysku/plikach i Zakleszczenia. Poniższy obrazek pokazuje, jak dostać się do raportów Przestrzeń na dysku/plikach. Posiadanie raportów zaledwie kilka kliknięć myszą jest bardzo cenne, aby móc natychmiast zajrzeć i zobaczyć, co dzieje się (lub działo) na twoim serwerze.
 Raporty doradcy wydajności
Raporty doradcy wydajności
Podsumowanie
Ważnym wnioskiem z tego posta jest poznanie swoich wskaźników wydajności. Powszechnym stwierdzeniem wśród specjalistów od danych jest to, że dysk jest naszym wąskim gardłem nr 1. Znajomość statystyk plików na serwerze znacznie pomoże w zrozumieniu problemów na serwerze. W połączeniu ze statystykami plików, statystyki oczekiwania są również doskonałym miejscem do przeglądania. Wiele osób, w tym ja, zaczyna tam. Posiadanie narzędzia takiego jak SQL Sentry Performance Advisor może drastycznie pomóc w rozwiązywaniu i znajdowaniu problemów z wydajnością, zanim staną się zbyt problematyczne; jeśli jednak nie masz takiego narzędzia, zapoznaj się z sys.dm_os_wait_stats i sys.dm_io_virtual_file_stats będzie ci dobrze służyć do rozpoczęcia strojenia serwera.