Pisałem wcześniej o właściwości Rzeczywiste odczytanie wierszy. Informuje, ile wierszy jest faktycznie odczytywanych przez wyszukiwanie indeksu, dzięki czemu można zobaczyć, jak selektywny jest predykat wyszukiwania w porównaniu z selektywnością predykatu wyszukiwania i predykatu rezydualnego łącznie.
Ale spójrzmy, co tak naprawdę dzieje się w operatorze Seek. Ponieważ nie jestem przekonany, że „Rzeczywiste przeczytanie wierszy” jest koniecznie dokładnym opisem tego, co się dzieje.
Chcę przyjrzeć się przykładowi, który wysyła zapytania o adresy określonych typów adresów dla klienta, ale ta zasada może z łatwością zastosować się do wielu innych sytuacji, jeśli kształt zapytania pasuje, na przykład wyszukiwanie atrybutów w tabeli par klucz-wartość, na przykład.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Wiem, że nie pokazałem Ci nic na temat metadanych – wrócę do tego za chwilę. Zastanówmy się nad tym zapytaniem i jakiego rodzaju indeksem chcielibyśmy dla niego mieć.
Po pierwsze, dokładnie znamy identyfikator klienta. Takie dopasowanie równości generalnie czyni go doskonałym kandydatem do pierwszej kolumny w indeksie. Gdybyśmy mieli indeks w tej kolumnie, moglibyśmy zagłębić się w adresy tego klienta – powiedziałbym więc, że to bezpieczne założenie.
Następną rzeczą do rozważenia jest filtr na AddressTypeID. Dodanie drugiej kolumny do kluczy naszego indeksu jest jak najbardziej rozsądne, więc zróbmy to. Nasz indeks jest teraz włączony (CustomerID, AddressTypeID). I dodajmy też FullAddress, abyśmy nie musieli wykonywać żadnych wyszukiwań, aby ukończyć obraz.
I myślę, że skończyliśmy. Powinniśmy być w stanie bezpiecznie założyć, że idealny indeks dla tego zapytania to:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Moglibyśmy potencjalnie zadeklarować to jako unikalny indeks – przyjrzymy się wpływowi tego później.
Stwórzmy więc tabelę (korzystam z tempdb, ponieważ nie potrzebuję jej, aby trwała poza tym postem na blogu) i przetestujmy to.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
Nie interesują mnie ograniczenia klucza obcego ani inne kolumny. Interesuje mnie tylko mój Idealny Indeks. Więc stwórz to też, jeśli jeszcze tego nie zrobiłeś.
Mój plan wydaje się całkiem doskonały.
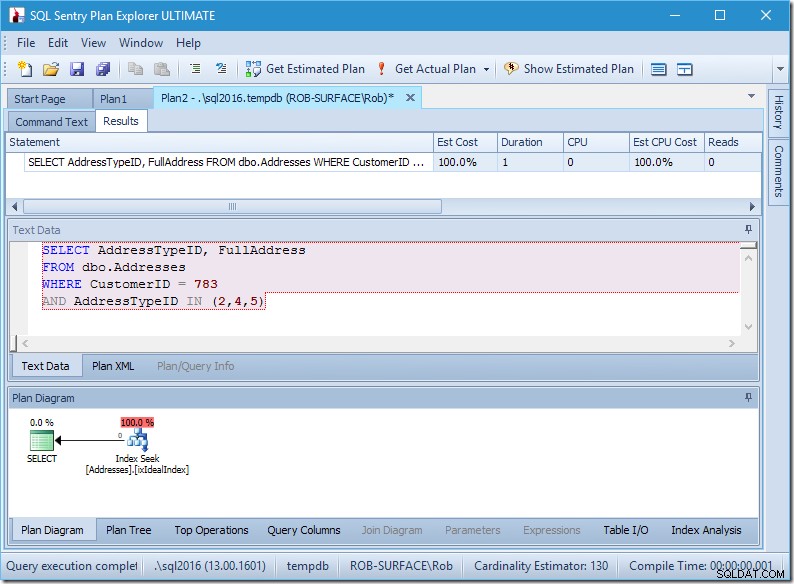
Mam wyszukiwanie indeksu i to wszystko.
To prawda, że nie ma danych, więc nie ma odczytów, procesora i działa dość szybko. Gdyby tylko wszystkie zapytania mogły być dostrojone tak dobrze, jak to.
Zobaczmy, co się dzieje nieco bliżej, przyglądając się właściwościom Seek.
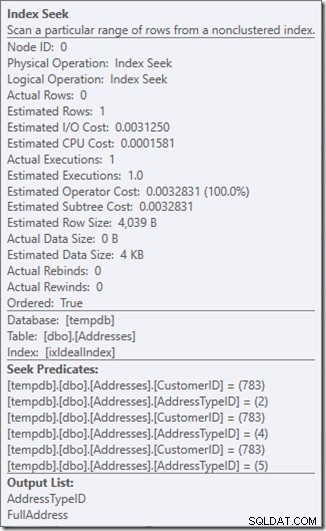
Widzimy Predykaty Seek. Jest sześć. Trzy o CustomerID i trzy o AddressTypeID. W rzeczywistości mamy tutaj trzy zestawy predykatów wyszukiwania, wskazujące na trzy operacje wyszukiwania w ramach jednego operatora Seek. Pierwsze wyszukiwanie szuka Customer 783 i AddressType 2. Drugie szuka 783 i 4, a ostatnie 783 i 5. Nasz operator Seek pojawił się raz, ale były w nim trzy wyszukiwania.
Nie mamy nawet danych, ale możemy zobaczyć, jak będzie używany nasz indeks.
Wstawmy trochę fikcyjnych danych, abyśmy mogli przyjrzeć się wpływowi tego. Zamierzam umieścić adresy dla typów od 1 do 6. Każdy klient (ponad 2000, w oparciu o rozmiar master..spt_values ) będzie miał adres typu 1. Może to jest adres główny. Pozwalam, aby 80% miało adres typu 2, 60% adres typu 3 i tak dalej, do 20% dla typu 5. Wiersz 783 otrzyma adresy typu 1, 2, 3 i 4, ale nie 5. Wolałbym raczej skorzystać z wartości losowych, ale chcę się upewnić, że przykłady są na tej samej stronie.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Przyjrzyjmy się teraz naszemu zapytaniu z danymi. Wychodzą dwa rzędy. To tak jak wcześniej, ale teraz widzimy dwa wiersze wychodzące z operatora Seek i widzimy sześć odczytów (w prawym górnym rogu).
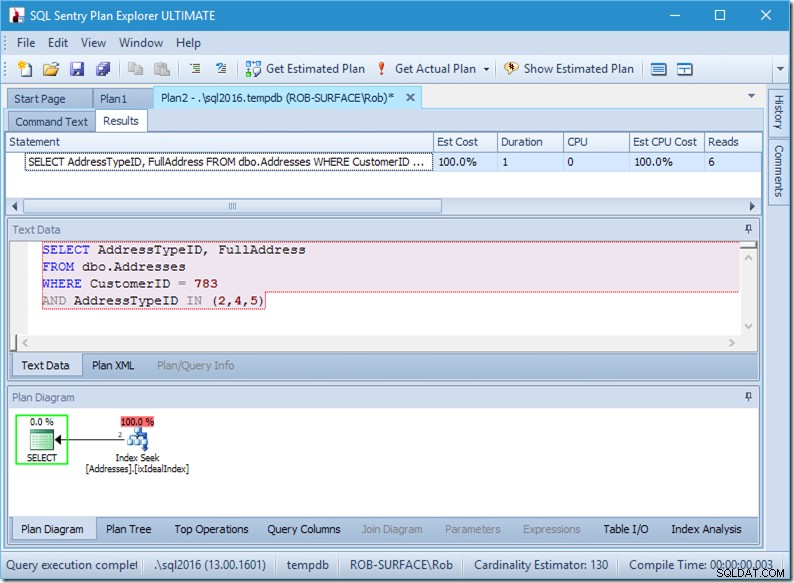
Sześć odczytów ma dla mnie sens. Mamy mały stolik, a indeks mieści się tylko na dwóch poziomach. Wykonujemy trzy wyszukiwania (w ramach naszego jednego operatora), więc silnik odczytuje stronę główną, dowiadując się, do której strony przejść i czytając ją, i robiąc to trzy razy.
Gdybyśmy szukali tylko dwóch identyfikatorów AddressTypeID, zobaczylibyśmy tylko 4 odczyty (w tym przypadku wyprowadzany jest jeden wiersz). Świetnie.
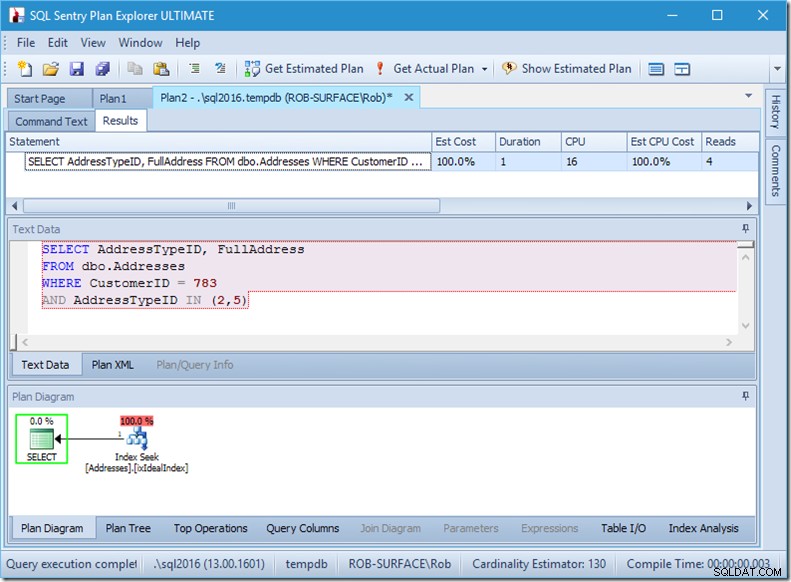
A gdybyśmy szukali 8 typów adresów, zobaczylibyśmy 16.
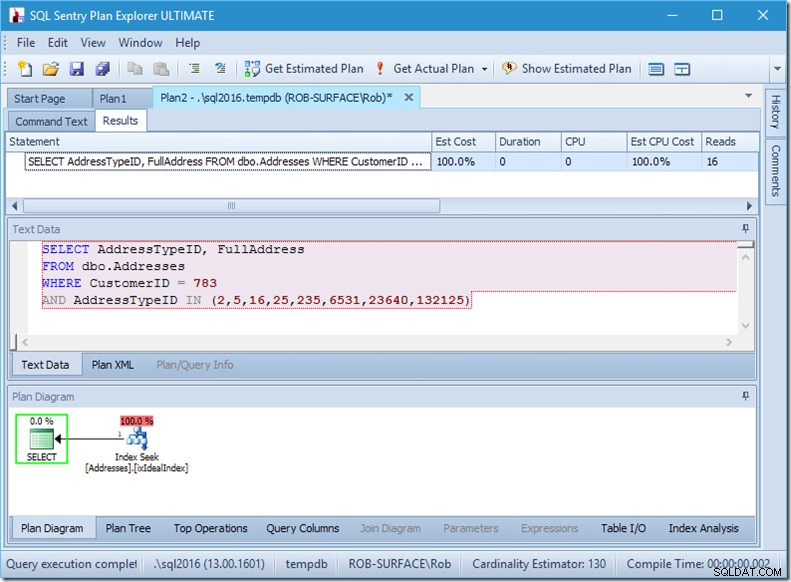
Jednak każdy z nich pokazuje, że rzeczywisty odczyt wierszy dokładnie pasuje do rzeczywistych wierszy. Żadnych nieefektywności!
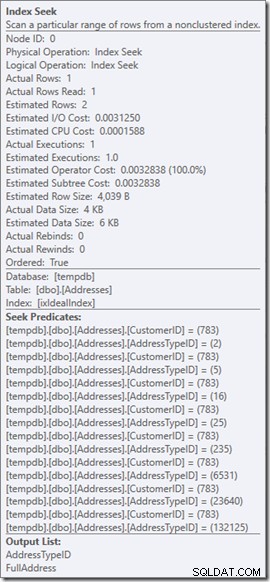
Wróćmy do naszego pierwotnego zapytania, poszukaj typów adresów 2, 4 i 5 (które zwracają 2 wiersze) i zastanówmy się, co dzieje się wewnątrz wyszukiwania.
Zakładam, że silnik zapytań wykonał już pracę, aby ustalić, że wyszukiwanie indeksu jest właściwą operacją i że ma pod ręką numer strony głównego indeksu.
W tym momencie ładuje tę stronę do pamięci, jeśli jeszcze jej tam nie ma. To pierwszy odczyt, który jest liczony w wykonaniu poszukiwania. Następnie lokalizuje numer strony dla wiersza, którego szuka, i odczytuje tę stronę. To drugi odczyt.
Ale często pomijamy ten bit „lokalizuje numer strony”.
Używając DBCC IND(2, N'dbo.Address', 2); (pierwsze 2 to identyfikator bazy danych, ponieważ używam tempdb; drugi 2 to identyfikator indeksu ixIdealIndex ), mogę odkryć, że 712 w pliku 1 to strona z najwyższym IndexLevel. Na poniższym zrzucie ekranu widzę, że strona 668 to IndexLevel 0, czyli strona główna.

Więc teraz mogę użyć DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); aby zobaczyć zawartość strony 712. Na moim komputerze otrzymuję 84 wiersze z powrotem i mogę stwierdzić, że CustomerID 783 będzie na stronie 1004 pliku 5.
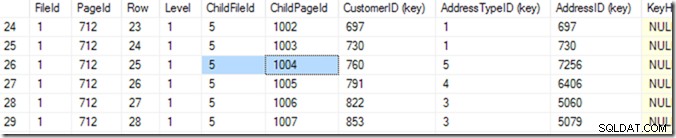
Ale wiem o tym, przewijając moją listę, aż zobaczę tę, której chcę. Zacząłem od przewinięcia trochę w dół, a następnie wróciłem w górę, aż znalazłem żądany wiersz. Komputer nazywa to wyszukiwaniem binarnym i jest nieco bardziej precyzyjne niż ja. Szuka wiersza, w którym kombinacja (CustomerID, AddressTypeID) jest mniejsza niż ta, której szukam, a następna strona jest większa lub taka sama. Mówię „taki sam”, ponieważ mogą być dwa takie same, rozłożone na dwóch stronach. Wie, że na tej stronie są 84 wiersze (od 0 do 83) danych (czyta je w nagłówku strony), więc zacznie od sprawdzenia wiersza 41. Stamtąd wie, w której połowie szukać, i (w w tym przykładzie), odczyta wiersz 20. Jeszcze kilka odczytów (co daje w sumie 6 lub 7)* i wie, że wiersz 25 (proszę spójrz na kolumnę o nazwie „Row” dla tej wartości, a nie na numer wiersza podany przez SSMS ) jest za mały, ale wiersz 26 jest za duży – więc 25 jest odpowiedzią!
*W wyszukiwaniu binarnym wyszukiwanie może być nieznacznie szybsze, jeśli ma szczęście, gdy podzieli blok na dwie części, jeśli nie ma środkowego przedziału, i w zależności od tego, czy środkowy przedział można wyeliminować, czy nie.
Teraz może przejść do strony 1004 w pliku 5. Użyjmy DBCC PAGE na tej stronie.
Ten daje mi 94 rzędy. Wykonuje kolejne wyszukiwanie binarne, aby znaleźć początek zakresu, którego szuka. Aby to znaleźć, musi przejrzeć 6 lub 7 wierszy.
„Początek zakresu?” Słyszę, jak pytasz. Ale szukamy typu 2 adresu klienta 783.
Zgadza się, ale nie zadeklarowaliśmy tego indeksu jako unikalnego. Więc mogą być dwa. Jeśli jest unikatowe, search może wykonać wyszukiwanie singletonowe i może natknąć się na nie podczas wyszukiwania binarnego, ale w tym przypadku musi zakończyć wyszukiwanie binarne, aby znaleźć pierwszy wiersz z zakresu. W tym przypadku jest to wiersz 71.
Ale na tym nie poprzestajemy. Teraz musimy sprawdzić, czy naprawdę istnieje drugi! Odczytuje również wiersz 72 i stwierdza, że para CustomerID+AddressTypeiD jest rzeczywiście zbyt duża i wyszukiwanie zostało zakończone.
I dzieje się to trzy razy. Za trzecim razem nie znajduje wiersza dla klienta 783 i typu adresu 5, ale nie wie o tym z wyprzedzeniem i nadal musi dokończyć wyszukiwanie.
Tak więc wiersze, które faktycznie są odczytywane przez te trzy wyszukiwania (aby znaleźć dwa wiersze do wyjścia) to znacznie więcej niż zwracana liczba. Jest około 7 na poziomie indeksu 1 i około 7 więcej na poziomie liścia tylko po to, aby znaleźć początek zakresu. Następnie odczytuje wiersz, na którym nam zależy, a następnie wiersz po nim. To brzmi dla mnie bardziej jak 16 i robi to trzy razy, tworząc około 48 rzędów.
Ale Actual Rows Read nie dotyczy liczby faktycznie odczytanych wierszy, ale liczby wierszy zwróconych przez predykat Seek, które są testowane względem predykatu rezydualnego. I w tym przypadku tylko 2 rzędy zostają znalezione przez 3 wyszukiwania.
Być może myślisz w tym momencie, że jest tu pewna doza nieskuteczności. Drugie wyszukiwanie również przeczytałoby stronę 712, sprawdziło tam te same 6 lub 7 wierszy, a następnie przeczytało stronę 1004 i przeszukało ją… podobnie jak trzecie wyszukiwanie.
Więc może lepiej byłoby uzyskać to w jednym poszukiwaniu, czytając strony 712 i 1004 tylko raz. W końcu, gdybym robił to z systemem papierowym, szukałbym klienta 783, a następnie przeskanował wszystkie typy adresów. Ponieważ wiem, że klient nie ma wielu adresów. To moja przewaga nad silnikiem bazy danych. Silnik bazy danych dzięki swoim statystykom wie, że wyszukiwanie będzie najlepsze, ale nie wie, że wyszukiwanie powinno zejść tylko o jeden poziom w dół, kiedy może stwierdzić, że ma to, co wydaje się być indeksem idealnym.
Jeśli zmienię zapytanie, aby pobrać zakres typów adresów, od 2 do 5, uzyskam prawie takie zachowanie, jakiego chcę:
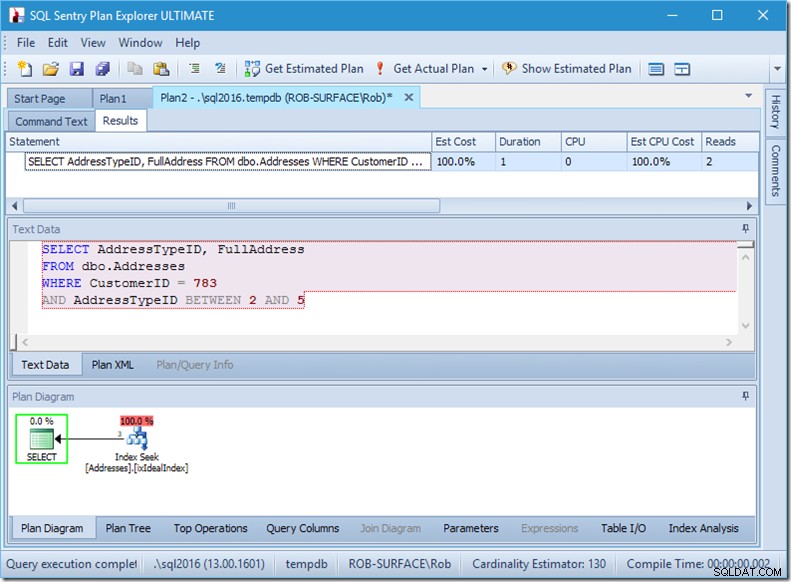
Spójrz – liczba odczytów spadła do 2 i wiem, które to strony…
…ale moje wyniki są błędne. Ponieważ chcę tylko adresów typu 2, 4 i 5, a nie 3. Muszę powiedzieć, że nie ma 3, ale muszę uważać, jak to robię. Spójrz na kolejne dwa przykłady.
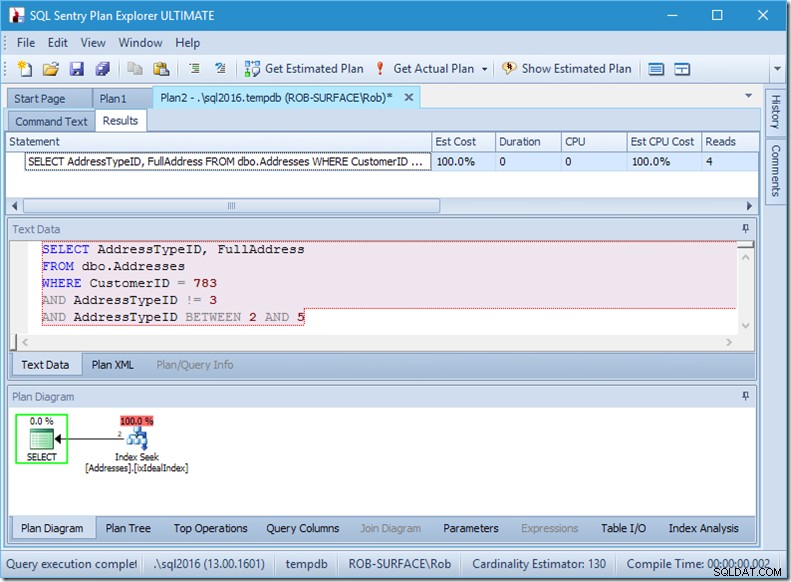
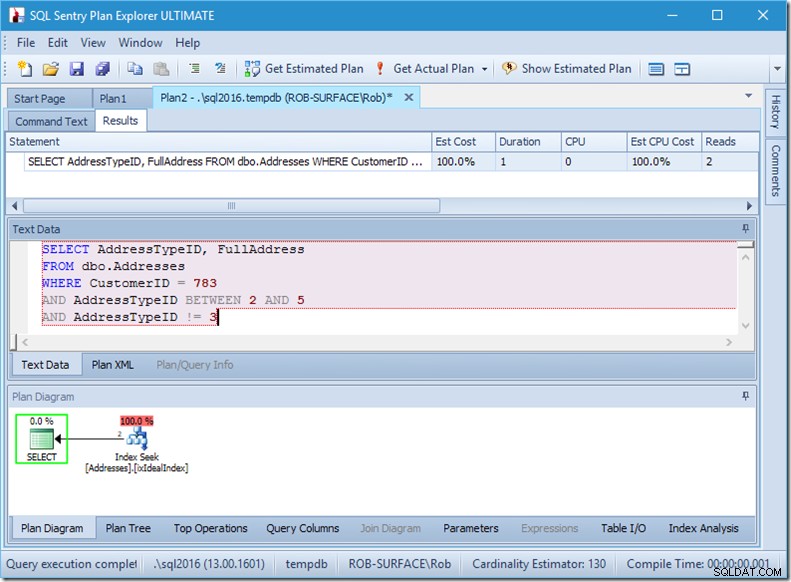
Zapewniam, że kolejność predykatów nie ma znaczenia, ale tutaj wyraźnie ma to znaczenie. Jeśli umieścimy „nie 3” jako pierwsze, wykona dwa wyszukiwania (4 odczyty), ale jeśli umieścimy „nie 3” jako drugie, wykona jedno wyszukiwanie (2 odczyty).
Problem polega na tym, że AddressTypeID !=3 zostaje przekonwertowany na (AddressTypeID> 3 OR AddressTypeID <3), który jest następnie postrzegany jako dwa bardzo przydatne predykaty wyszukiwania.
Dlatego wolę używać predykatu nieargable, aby powiedzieć, że chcę tylko typów adresów 2, 4 i 5. I mogę to zrobić, modyfikując AddressTypeID w pewien sposób, na przykład dodając do niego zero.
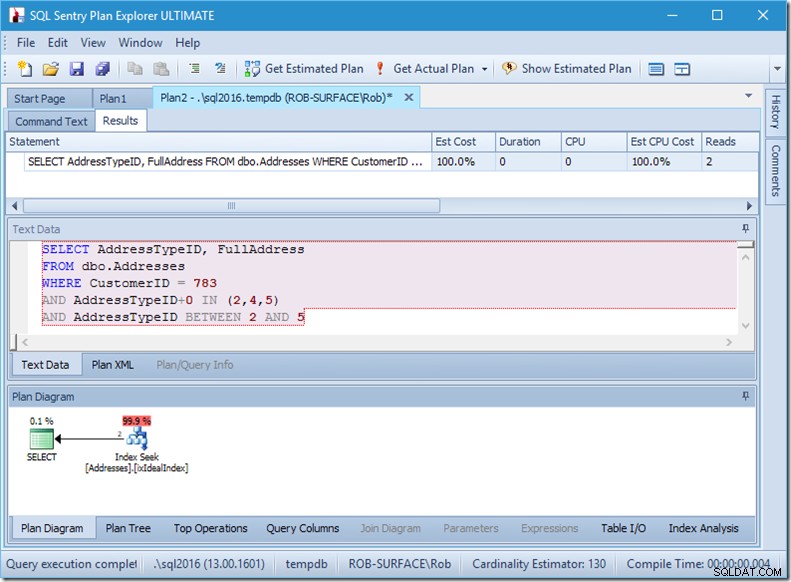
Teraz mam ładne i wąskie skanowanie zakresu w ramach jednego wyszukiwania i nadal upewniam się, że moje zapytanie zwraca tylko żądane wiersze.
Och, ale ta właściwość Rzeczywiste odczytywanie wierszy? Jest to teraz wyższa wartość niż właściwość Actual Rows, ponieważ predykat wyszukiwania znajduje typ adresu 3, który predykat rezydualny odrzuca.
Zamieniłem trzy wyszukiwania doskonałe na jedno wyszukiwanie niedoskonałe, które naprawiam za pomocą predykatu rezydualnego.
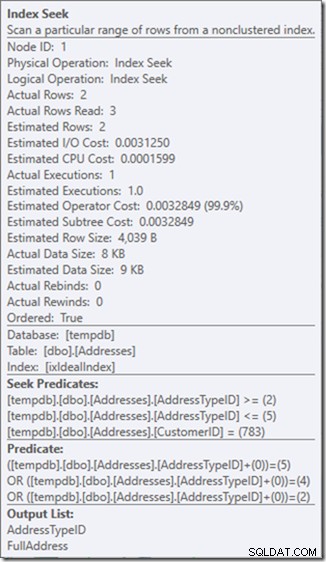
A dla mnie czasami jest to cena, którą warto zapłacić, dając mi plan zapytań, z którego jestem znacznie szczęśliwszy. Nie jest znacząco tańszy, mimo że ma tylko jedną trzecią odczytów (ponieważ byłyby tylko dwa fizyczne odczyty), ale kiedy myślę o pracy, którą wykonuje, czuję się znacznie bardziej komfortowo z tym, o co go pytam w ten sposób.