W moim poprzednim poście z tej serii pokazałem, że nie wszystkie scenariusze zapytań mogą korzystać z technologii OLTP w pamięci. W rzeczywistości używanie Hekaton w niektórych przypadkach może mieć szkodliwy wpływ na wydajność (kliknij, aby powiększyć):

Profil monitora wydajności podczas wykonywania procedury składowanej
Jednak w tym scenariuszu mogłem ułożyć talię przeciwko Hekatonowi na dwa sposoby:
- Utworzony przeze mnie typ tabeli zoptymalizowany pod kątem pamięci miał liczbę wiader 256, ale do porównania przekazałem do 2000 wartości. W nowszym poście na blogu zespołu SQL Server wyjaśnili, że przewymiarowanie liczby zasobników jest lepsze niż jej niedomiar – coś, o czym ogólnie wiedziałem, ale nie zdawałem sobie sprawy, że ma to również znaczący wpływ na zmienne tabeli:Zachowaj należy pamiętać, że dla indeksu mieszającego wartość bucket_count powinna wynosić około 1-2X liczby oczekiwanych unikalnych kluczy indeksowych. Przewymiarowanie jest zwykle lepsze niż niedowymiarowanie:jeśli czasami wstawiasz tylko 2 wartości do zmiennych, ale czasami wstawiasz do 1000 wartości, zwykle lepiej jest określić
BUCKET_COUNT=1000.Nie omawiają wyraźnie rzeczywistego powodu tego i jestem pewien, że istnieje wiele technicznych szczegółów, w które moglibyśmy się zagłębić, ale wytyczne wydają się być za duże.
- Klucz podstawowy był indeksem mieszającym w dwóch kolumnach, podczas gdy parametr wyceniany w tabeli próbował dopasować wartości tylko w jednej z tych kolumn. Po prostu oznaczało to, że nie można użyć indeksu skrótu. Tony Rogerson wyjaśnia to nieco bardziej szczegółowo w niedawnym poście na blogu:Hash jest generowany we wszystkich kolumnach zawartych w indeksie, musisz również określić wszystkie kolumny w indeksie mieszającym w wyrażeniu sprawdzającym równość, w przeciwnym razie nie można użyć indeksu .
Nie pokazywałem tego wcześniej, ale zauważ, że plan dotyczący tabeli zoptymalizowanej pod kątem pamięci z dwukolumnowym indeksem mieszającym faktycznie wykonuje skanowanie tabeli, a nie wyszukiwanie indeksu, którego można by oczekiwać względem nieklastrowanego indeksu mieszającego (ponieważ wiodący kolumna była
SalesOrderID):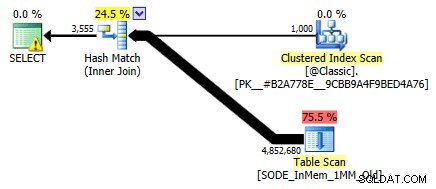
Plan zapytań obejmujący tabelę w pamięci z dwiema kolumnami indeks skrótuMówiąc dokładniej, w indeksie haszującym, wiodąca kolumna nie oznacza samego wzgórza fasoli; hash jest nadal dopasowywany we wszystkich kolumnach, więc w ogóle nie działa jak tradycyjny indeks B-drzewa (w przypadku tradycyjnego indeksu predykat obejmujący tylko wiodącą kolumnę może być nadal bardzo przydatny w eliminowaniu wierszy).
Co robić?
Cóż, najpierw utworzyłem dodatkowy indeks skrótu tylko dla SalesOrderID kolumna. Przykład jednej takiej tabeli z milionem wiader:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); Pamiętaj, że nasze typy stołów są skonfigurowane w ten sposób:
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
Po wypełnieniu nowych tabel danymi i utworzeniu nowej procedury składowanej w celu odwoływania się do nowych tabel, otrzymany plan poprawnie pokazuje wyszukiwanie indeksu względem jednokolumnowego indeksu mieszającego:

Ulepszony plan przy użyciu jednokolumnowego indeksu skrótu
Ale co to tak naprawdę oznacza dla wydajności? Przeprowadziłem ponownie ten sam zestaw testów – zapytania do tej tabeli z liczbą wiader 16K, 131K i 1MM; używanie zarówno klasycznych, jak i in-memory TVP o wartościach 100, 1000 i 2000; aw przypadku TVP w pamięci, przy użyciu zarówno tradycyjnej procedury składowanej, jak i natywnie skompilowanej procedury składowanej. Oto jak wyglądała wydajność dla 10 000 iteracji na kombinację:

Profil wydajności dla 10 000 iteracji względem jednokolumnowego indeksu skrótu, za pomocą 256-wiaderkowego TVP
Możesz pomyśleć, hej, ten profil wydajności nie wygląda tak dobrze; wręcz przeciwnie, jest znacznie lepszy niż mój poprzedni test w zeszłym miesiącu. Pokazuje tylko, że liczba zasobników dla tabeli może mieć ogromny wpływ na zdolność SQL Server do efektywnego korzystania z indeksu mieszającego. W tym przypadku użycie liczby wiader 16K wyraźnie nie jest optymalne dla żadnego z tych przypadków i pogarsza się wykładniczo wraz ze wzrostem liczby wartości w TVP.
Teraz pamiętaj, że liczba wiader TVP wynosiła 256. Więc co by się stało, gdybym ją zwiększył, zgodnie z wytycznymi Microsoftu? Stworzyłem drugi typ stołu z bardziej odpowiednim rozmiarem wiadra. Ponieważ testowałem wartości 100, 1000 i 2000, użyłem następnej potęgi 2 do obliczenia liczby wiader (2048):
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
Stworzyłem do tego procedury pomocnicze i ponownie przeprowadziłem tę samą baterię testów. Oto profile wydajności obok siebie:

Porównanie profilu wydajności z 256 i 2048 segmentami TVP
Zmiana liczby wiader dla typu tabeli nie miała takiego wpływu, jakiego bym się spodziewał, biorąc pod uwagę oświadczenie Microsoftu dotyczące rozmiaru. To naprawdę nie przyniosło żadnego pozytywnego efektu; w rzeczywistości w niektórych scenariuszach było trochę gorzej. Ale ogólnie profile wydajności są pod każdym względem takie same.
Ogromny efekt przyniosło jednak utworzenie *właściwego* indeksu skrótu do obsługi wzorca zapytania. Byłem wdzięczny, że udało mi się wykazać, że – pomimo moich wcześniejszych testów, które wskazywały inaczej – in-memory table i in-memory TVP mogą pokonać starą szkołę, aby osiągnąć to samo. Weźmy po prostu najbardziej ekstremalny przypadek z mojego poprzedniego przykładu, kiedy tabela miała tylko dwukolumnowy indeks haszujący:

Profil wydajności dla 10 iteracji z dwukolumnowym indeksem skrótu
Pasek po prawej stronie pokazuje czas trwania zaledwie 10 iteracji natywnej procedury składowanej dopasowującej się do nieodpowiedniego indeksu skrótu — czasy zapytania wynoszą od 735 do 1601 milisekund. Teraz jednak, przy odpowiednim indeksie skrótu, te same zapytania są wykonywane w znacznie mniejszym zakresie – od 0,076 milisekundy do 51,55 milisekundy. Jeśli pominiemy najgorszy przypadek (liczy się 16 tys. wiader), rozbieżność jest jeszcze bardziej wyraźna. We wszystkich przypadkach jest to co najmniej dwa razy bardziej wydajne (przynajmniej pod względem czasu trwania) niż każda metoda, bez naiwnie skompilowanej procedury składowanej, w stosunku do tej samej tabeli zoptymalizowanej pod kątem pamięci; i setki razy lepsze niż którekolwiek z podejść do naszej starej tabeli zoptymalizowanej pod kątem pamięci z jedynym, dwukolumnowym indeksem skrótu.
Wniosek
Mam nadzieję, że wykazałem, że należy zachować dużą ostrożność podczas implementacji dowolnego typu tabel zoptymalizowanych pod kątem pamięci, i że w wielu przypadkach używanie samego TVP zoptymalizowanego pod kątem pamięci może nie przynieść największego przyrostu wydajności. Będziesz chciał rozważyć użycie natywnie skompilowanych procedur składowanych, aby uzyskać jak najwięcej korzyści za wydane pieniądze, a aby jak najlepiej skalować, naprawdę będziesz chciał zwracać uwagę na liczbę zasobników dla indeksów skrótu w tabelach zoptymalizowanych pod kątem pamięci (ale być może nie tyle uwagi poświęcasz typom tabel zoptymalizowanych pod kątem pamięci).
Aby uzyskać więcej informacji na temat technologii OLTP w pamięci, możesz zapoznać się z tymi zasobami:
- Blog zespołu SQL Server (Tag:Hekaton i Tag:In-Memory OLTP – czy nazwy kodowe nie są zabawne?)
- Bob Boba Beauchemina
- Blog Klausa Aschenbrennera



