Odczyt popełniony jest drugi najsłabszy z czterech poziomów izolacji zdefiniowanych przez standard SQL. Niemniej jednak jest to domyślny poziom izolacji dla wielu aparatów baz danych, w tym SQL Server. Ten post z serii o poziomach izolacji i właściwościach ACID transakcji przygląda się logicznym i fizycznym gwarancjom faktycznie zapewnianym przez przeczytaną popełnioną izolację.
Gwarancje logiczne
Standard SQL wymaga, aby transakcja działająca w trybie odczytu zatwierdzonej izolacji odczytywała tylko zatwierdzona dane. Wyraża to wymaganie, zabraniając zjawiska współbieżności zwanego brudnym odczytem. Brudny odczyt ma miejsce, gdy transakcja odczytuje dane, które zostały zapisane przez inną transakcję, przed zakończeniem tej drugiej transakcji. Innym sposobem wyrażenia tego jest stwierdzenie, że nieprawidłowy odczyt występuje, gdy transakcja odczytuje niezatwierdzone dane.
Standard wspomina również, że transakcja działająca w trybie odczytu zatwierdzonej izolacji może napotkać zjawisko współbieżności znane jako niepowtarzalne odczyty i fantomy . Chociaż wiele książek wyjaśnia te zjawiska w kontekście transakcji, które mogą zobaczyć zmienione lub nowe elementy danych, jeśli dane zostaną następnie ponownie odczytane, to wyjaśnienie może wzmocnić błędne przekonanie że zjawisko współbieżności może wystąpić tylko w jawnej transakcji zawierającej wiele instrukcji. Tak nie jest. Pojedyncze stwierdzenie bez wyraźnej transakcji jest tak samo podatny na niepowtarzalne zjawiska odczytu i zjawiska fantomowe, jak zobaczymy wkrótce.
To prawie wszystko, co standard ma do powiedzenia na temat popełnionej izolacji. Na pierwszy rzut oka czytanie tylko zatwierdzonych danych wydaje się całkiem dobrą gwarancją rozsądnego zachowania, ale jak zwykle diabeł tkwi w szczegółach. Gdy tylko zaczniesz szukać potencjalnych luk w tej definicji zbyt łatwo jest znaleźć przypadki, w których nasze odczytane zatwierdzone transakcje mogą nie dawać oczekiwanych wyników. Ponownie omówimy je bardziej szczegółowo za chwilę lub dwie.
Różne implementacje fizyczne
Istnieją co najmniej dwie rzeczy, które oznaczają, że obserwowane zachowanie odczytu zatwierdzonego poziomu izolacji może być zupełnie inne w różnych aparatach baz danych. Po pierwsze, standardowe wymaganie SQL dotyczące odczytu tylko zatwierdzonych danych nie koniecznie oznaczać, że zatwierdzone dane odczytane przez transakcję będą najnowszymi popełnione dane.
Silnik bazy danych może odczytać zadeklarowaną wersję wiersza z dowolnego punktu w przeszłości i nadal są zgodne ze standardową definicją SQL. Kilka popularnych produktów bazodanowych implementuje w ten sposób izolację popełnioną do odczytu. Wyniki zapytania uzyskane w ramach tej implementacji odczytu zatwierdzonej izolacji mogą być arbitralnie nieaktualne , w porównaniu z bieżącym zatwierdzonym stanem bazy danych. Omówimy ten temat, ponieważ dotyczy on SQL Server w następnym poście z tej serii.
Drugą rzeczą, na którą chcę zwrócić uwagę, jest to, że standardowa definicja SQL nie uniemożliwić określonej implementacji zapewnienie dodatkowej ochrony przed efektem współbieżności poza zapobieganiem brudnym odczytom . Standard określa jedynie, że brudne odczyty są niedozwolone, nie wymaga, aby inne zjawiska współbieżności były dozwolone na dowolnym poziomie izolacji.
Aby wyjaśnić ten drugi punkt, zgodny ze standardami silnik bazy danych może zaimplementować wszystkie poziomy izolacji przy użyciu możliwości serializacji zachowanie, jeśli tak wybierze. Niektóre główne komercyjne silniki baz danych zapewniają również implementację zatwierdzonego odczytu, która wykracza daleko poza zwykłe zapobieganie brudnym odczytom (chociaż żaden nie posuwa się tak daleko, jak zapewnienie pełnej izolacji w ACID sens tego słowa).
Oprócz tego w przypadku kilku popularnych produktów przeczytaj zaangażowany izolacja jest najniższa dostępny poziom izolacji; ich implementacje odczytu niezaangażowanego izolacja jest dokładnie taka sama, jak popełnione czytanie. Jest to dozwolone przez standard, ale tego rodzaju różnice zwiększają złożoność i tak już trudnego zadania migracji kodu z jednej platformy na drugą. Mówiąc o zachowaniach na poziomie izolacji, zwykle ważne jest, aby określić również konkretną platformę.
O ile mi wiadomo, SQL Server jest wyjątkowy wśród głównych komercyjnych silników baz danych pod względem zapewniania dwóch implementacje odczytanego poziomu izolacji popełnionej, z których każdy ma bardzo różne zachowania fizyczne. Ten post dotyczy pierwszego z nich, blokowania przeczytaj popełnione.
Zatwierdzono odczyt blokady serwera SQL
Jeśli opcja bazy danych READ_COMMITTED_SNAPSHOT jest OFF , SQL Server używa blokowania implementacja odczytu zatwierdzonego poziomu izolacji, w którym współdzielone blokady są podejmowane, aby uniemożliwić współbieżną transakcję równoczesną modyfikację danych, ponieważ modyfikacja wymagałaby blokady na wyłączność, która nie jest zgodna z współużytkowaną blokadą.
Kluczową różnicą między zatwierdzeniem blokowania odczytu SQL Server a blokowaniem odczytu powtarzalnego (co powoduje również blokadę współdzieloną podczas odczytu danych) jest to, że odczyt zatwierdzony zwalnia blokadę współdzieloną tak szybko, jak to możliwe , podczas gdy powtarzalny odczyt utrzymuje te blokady do końca otaczającej transakcji.
Gdy popełnione blokowanie odczytu uzyskuje blokady z dokładnością wiersza, współdzielona blokada pobrana w wierszu jest zwalniana gdy wspólna blokada zostanie nałożona na następny wiersz . Przy szczegółowości strony udostępniona blokada strony jest zwalniana po odczytaniu pierwszego wiersza na następnej stronie i tak dalej. O ile z zapytaniem nie zostanie dostarczona wskazówka dotycząca poziomu szczegółowości, aparat bazy danych decyduje, od jakiego poziomu szczegółowości rozpocząć. Pamiętaj, że podpowiedzi dotyczące szczegółowości są traktowane przez silnik tylko jako sugestie, więc początkowo może zostać zastosowana mniej szczegółowa blokada niż żądana. Blokady mogą być również eskalowane podczas wykonywania z poziomu wiersza lub strony na poziom partycji lub tabeli, w zależności od konfiguracji systemu.
Ważną kwestią jest to, że wspólne blokady są zwykle utrzymywane tylko przez bardzo krótki czas podczas wykonywania oświadczenia. Aby wyraźnie rozwiązać jedno powszechne błędne przekonanie, blokowanie odczytu popełnione nie przytrzymaj wspólne blokady do końca wyciągu.
Blokowanie odczytanych zachowań popełnionych
Krótkoterminowe blokady współdzielone używane przez implementację blokady odczytu SQL Server zapewniają bardzo niewiele gwarancji powszechnie oczekiwanych od transakcji bazy danych przez programistów T-SQL. W szczególności, instrukcja działająca pod blokadą odczyt popełniona izolacja:
- Może napotkać ten sam wiersz wiele razy;
- Czy może całkowicie pominąć niektóre wiersze; i
- Czy nie zapewnić widok z punktu w czasie danych
Ta lista może wydawać się bardziej opisem dziwnych zachowań, które możesz bardziej kojarzyć z użyciem NOLOCK podpowiedzi, ale wszystkie te rzeczy naprawdę mogą i zdarzają się podczas korzystania z popełnionej izolacji z blokowaniem odczytu.
Przykład
Rozważ proste zadanie zliczania wierszy w tabeli przy użyciu oczywistej kwerendy jednoinstrukcyjnej. W przypadku blokowania odczytu zatwierdzonej izolacji z granulacją blokowania wierszy, nasze zapytanie przyjmie wspólną blokadę w pierwszym wierszu, odczyta ją, zwolni udostępnioną blokadę, przejdzie do następnego wiersza i tak dalej, aż osiągnie koniec struktury, którą czyta. Na potrzeby tego przykładu załóżmy, że nasze zapytanie odczytuje indeks b-drzewa w rosnącej kolejności kluczy (chociaż równie dobrze może użyć kolejności malejącej lub dowolnej innej strategii).
Ponieważ tylko jeden wiersz jest zablokowana na udziałach w dowolnym momencie, jasne jest, że współbieżne transakcje mogą modyfikować odblokowane wiersze w indeksie, przez który przechodzi nasze zapytanie. Jeśli te współbieżne modyfikacje zmienią wartości kluczy indeksu, spowodują przesuwanie wierszy w strukturze indeksu. Mając to na uwadze, poniższy diagram ilustruje dwa problematyczne scenariusze, które mogą wystąpić:
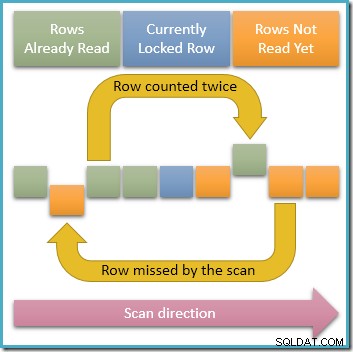
Górna strzałka pokazuje wiersz, który już policzyliśmy, mający jednocześnie zmodyfikowany klucz indeksu, dzięki czemu wiersz przesuwa się przed bieżącą pozycją skanowania w indeksie, co oznacza, że wiersz zostanie policzony dwukrotnie . Druga strzałka pokazuje wiersz, którego nasz skan jeszcze nie napotkał, przesuwający się za pozycją skanowania, co oznacza, że wiersz nie zostanie policzony w ogóle.
Nie widok z punktu w czasie
W poprzedniej sekcji pokazano, w jaki sposób blokowanie popełnionego odczytu może całkowicie pominąć dane lub policzyć ten sam element wiele razy (więcej niż dwa razy, jeśli mamy pecha). Trzeci punkt na liście nieoczekiwanych zachowań stwierdzał, że popełnione blokowanie odczytu również nie zapewnia widoku danych z określonego punktu w czasie.
Rozumowanie stojące za tym stwierdzeniem powinno być teraz łatwe do zrozumienia. Na przykład nasze zapytanie zliczające mogło łatwo odczytać dane, które zostały wprowadzone przez równoczesne transakcje po tym, jak nasze zapytanie zaczęło się wykonywać. Podobnie dane, które widzi nasze zapytanie, mogą być modyfikowane przez współbieżną aktywność po rozpoczęciu zapytania i przed jego zakończeniem. Wreszcie, dane, które przeczytaliśmy i policzyliśmy, mogą zostać usunięte przez jednoczesną transakcję przed zakończeniem naszego zapytania.
Jasne jest, że dane widziane przez instrukcję lub transakcję uruchomioną w ramach blokady odczytu zatwierdzonej izolacji nie odpowiadają żadnemu pojedynczemu stanowi bazy danych w dowolnym punkcie w czasie . Dane, które napotykamy, mogą pochodzić z różnych punktów w czasie, a jedynym wspólnym czynnikiem jest to, że każdy element reprezentował ostatnią zatwierdzoną wartość tych danych w momencie ich odczytania (chociaż od tego czasu mogło się zmienić lub zniknąć).
Jak poważne są te problemy?
To wszystko może wydawać się dość dziwnym stanem rzeczy, jeśli jesteś przyzwyczajony do myślenia o swoich zapytaniach jednoinstrukcyjnych i jawnych transakcjach jako logicznie wykonywanych natychmiast lub jako działających na pojedynczym zatwierdzonym stanie bazy danych w określonym punkcie w czasie podczas korzystania z domyślny poziom izolacji programu SQL Server. Z pewnością nie pasuje to dobrze do koncepcji izolacji w sensie KWASU.
Biorąc pod uwagę widoczną słabość gwarancji zapewnianych przez blokowanie popełnionej izolacji odczytu, możesz zacząć się zastanawiać, jak jakiekolwiek Twojego produkcyjnego kodu T-SQL kiedykolwiek działał poprawnie! Oczywiście możemy zaakceptować fakt, że użycie poziomu izolacji niższego niż możliwy do serializacji oznacza rezygnację z pełnej izolacji transakcji ACID w zamian za inne potencjalne korzyści, ale jak poważne mogą być te problemy w praktyce?
Brakujące i podwójnie liczone wiersze
Te dwa pierwsze problemy zasadniczo polegają na jednoczesnej zmianie kluczy w strukturze indeksu, którą aktualnie skanujemy. Pamiętaj, że skanowanie tutaj obejmuje część indeksu szukania częściowego zakresu skanowania , a także znane nieograniczone skanowanie indeksów lub tabel.
Jeśli (zakres) skanujemy strukturę indeksu, której klucze nie są zwykle modyfikowane przez żadne współbieżne działania, te dwie pierwsze kwestie nie powinny stanowić większego praktycznego problemu. Trudno jednak być tego pewnym, ponieważ plany zapytań mogą się zmieniać, aby korzystać z innej metody dostępu, a nowy przeszukiwany indeks może zawierać niestabilne klucze.
Musimy również pamiętać, że wiele zapytań produkcyjnych tak naprawdę potrzebuje tylko przybliżonego lub jak najlepiej odpowiedzieć na niektóre rodzaje pytań. Fakt, że niektórych wierszy brakuje lub są liczone podwójnie, może nie mieć większego znaczenia w szerszym schemacie rzeczy. W systemie z wieloma współbieżnymi zmianami może być nawet trudno mieć pewność, że wynik był niedokładne, biorąc pod uwagę, że dane zmieniają się tak często. W takiej sytuacji z grubsza poprawna odpowiedź może być wystarczająco dobra dla potrzeb konsumenta danych.
Brak widoku punktu w czasie
Trzecia kwestia (kwestia tak zwanego „spójnego” punktu widzenia danych w czasie) również sprowadza się do tego samego rodzaju rozważań. Do celów raportowania, gdzie niespójności mają tendencję do powodowania niezręcznych pytań ze strony odbiorców danych, często preferowany jest widok migawki. W innych przypadkach rodzaj niespójności wynikających z braku punktu w czasie widoku danych może być tolerowany.
Kłopotliwe scenariusze
Istnieje również wiele przypadków, w których wymienione obawy będą być ważne. Na przykład, jeśli piszesz kod, który wymusza zasady biznesowe w T-SQL należy uważać, aby wybrać poziom izolacji (lub podjąć inne odpowiednie działania), aby zagwarantować poprawność. Wiele reguł biznesowych można wymusić za pomocą kluczy obcych lub ograniczeń, w których zawiłości związane z wyborem poziomu izolacji są obsługiwane automatycznie przez silnik bazy danych. Ogólna zasada:korzystanie z wbudowanego zestawu deklaratywnej integralności funkcje są lepsze niż budowanie własnych reguł w T-SQL.
Istnieje inna szeroka klasa zapytań, które nie do końca wymuszają regułę biznesową per se , ale które mimo to mogą mieć niefortunne konsekwencje, gdy są uruchamiane na domyślnym poziomie izolacji odczytu popełnionego blokowania. Te scenariusze nie zawsze są tak oczywiste, jak często przytaczane przykłady przelewania pieniędzy między rachunkami bankowymi lub zapewnienie, że saldo na wielu połączonych kontach nigdy nie spadnie poniżej zera. Rozważmy na przykład następujące zapytanie, które identyfikuje zaległe faktury jako dane wejściowe do jakiegoś procesu, który wysyła listy przypominające o surowym brzmieniu:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Najwyraźniej nie chcielibyśmy wysyłać listu do kogoś, kto w pełni zapłacił fakturę w ratach, po prostu dlatego, że jednoczesna aktywność bazy danych w momencie uruchomienia naszego zapytania oznaczała, że obliczyliśmy nieprawidłową sumę otrzymanych płatności. Rzeczywiste zapytania w rzeczywistych systemach produkcyjnych są oczywiście często znacznie bardziej złożone niż prosty przykład powyżej.
Aby zakończyć na dzisiaj, spójrz na następujące zapytanie i sprawdź, czy możesz zauważyć, ile jest możliwości wystąpienia czegoś niezamierzonego, jeśli kilka takich zapytań jest uruchamianych jednocześnie na poziomie izolacji zatwierdzonej do odczytu blokującego (być może podczas innych niepowiązanych transakcji modyfikują również tabelę Przypadki):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Gdy zaczniesz szukać wszystkich drobnych sposobów, w jakie zapytanie może się nie powieść na tym poziomie izolacji, zatrzymanie może być trudne. Należy pamiętać o zastrzeżeniach zauważonych wcześniej, dotyczących rzeczywistej potrzeby uzyskania całkowicie izolowanych i dokładnych wyników w określonym czasie. Dobrze jest mieć zapytania, które zwracają wystarczająco dobre wyniki, o ile jesteś świadomy kompromisów, jakich dokonujesz przy użyciu zatwierdzonego odczytu.
Następnym razem
W następnej części tej serii przyjrzymy się drugiej fizycznej implementacji odczytu zatwierdzonej izolacji dostępnej w SQL Server, odczytu zatwierdzonej izolacji migawki.
[ Zobacz indeks dla całej serii ]