Wiele produkcyjnego kodu T-SQL jest pisane z niejawnym założeniem, że dane bazowe nie ulegną zmianie podczas wykonywania. Jak widzieliśmy w poprzednim artykule z tej serii, jest to niebezpieczne założenie, ponieważ wpisy danych i indeksu mogą poruszać się pod nami, nawet podczas wykonywania pojedynczej instrukcji.
Tam, gdzie programista T-SQL zdaje sobie sprawę z rodzajów problemów z poprawnością i integralnością danych, które mogą powstać w wyniku współbieżnych modyfikacji danych przez inne procesy, najczęściej oferowanym rozwiązaniem jest uwzględnienie podatnych instrukcji w transakcji. Nie jest jasne, w jaki sposób ten sam rodzaj rozumowania zostałby zastosowany w przypadku pojedynczej instrukcji, która jest już domyślnie owinięta w transakcję z automatycznym zatwierdzaniem.
Pomijając to na chwilę, pomysł ochrony ważnego obszaru kodu T-SQL za pomocą transakcji wydaje się być oparty na niezrozumieniu zabezpieczeń oferowanych przez właściwości transakcji ACID. Ważnym elementem tego akronimu dla obecnej dyskusji jest Izolacja własność. Pomysł polega na tym, że użycie transakcji automatycznie zapewnia całkowitą izolację od skutków innych jednoczesnych działań.
Prawda jest taka, że transakcje poniżej SERIALIZABLE podawaj tylko stopień izolacji, która zależy od aktualnie obowiązującego poziomu izolacji transakcji. Aby zrozumieć, co to wszystko oznacza dla naszego codziennego T Praktyki kodowania SQL, najpierw przyjrzymy się szczegółowo możliwemu do serializacji poziomowi izolacji.
Izolacja z możliwością serializacji
Serializable to najbardziej odizolowany ze standardowych poziomów izolacji transakcji. Jest to również domyślne poziom izolacji określony przez standard SQL, choć SQL Server (jak większość komercyjnych systemów bazodanowych) różni się pod tym względem od standardu. Domyślny poziom izolacji w SQL Server to odczyt zatwierdzony, niższy poziom izolacji, który omówimy w dalszej części serii.
Definicja serializowalnego poziomu izolacji w standardzie SQL-92 zawiera następujący tekst (podkreślenie moje):
Wykonanie możliwe do serializacji jest zdefiniowane jako wykonanie operacji równoczesnego wykonywania transakcji SQL, które daje ten sam efekt, co niektóre wykonanie seryjne tych samych transakcji SQL. Wykonywanie szeregowe to takie, w którym każda transakcja SQL jest wykonywana do końca przed rozpoczęciem następnej transakcji SQL.
Należy tutaj dokonać ważnego rozróżnienia między naprawdę serializowanymi wykonanie (gdzie każda transakcja faktycznie przebiega wyłącznie do zakończenia przed rozpoczęciem następnej) i możliwa do serializacji izolacja, gdzie transakcje muszą mieć tylko takie same skutki jak gdyby były wykonywane seryjnie (w nieokreślonej kolejności).
Innymi słowy, prawdziwy system baz danych może fizycznie nachodzić wykonanie transakcji serializowalnych w czasie (tym samym zwiększając współbieżność), o ile efekty tych transakcji nadal odpowiadają jakiejś możliwej kolejności seryjnej egzekucji. Innymi słowy, transakcje możliwe do serializacji są potencjalnie możliwe do serializacji zamiast być faktycznie serializowanym .
Transakcje, które można serializować logicznie
Odłóżcie na chwilę na bok wszystkie kwestie fizyczne (takie jak blokowanie) i pomyślcie tylko o logicznym przetwarzaniu dwóch równoległych transakcji, które można serializować.
Rozważ tabelę zawierającą dużą liczbę wierszy, z których pięć spełnia jakiś interesujący predykat zapytania. Transakcja możliwa do serializacji T1 zaczyna liczyć liczbę wierszy w tabeli, które pasują do tego predykatu. Jakiś czas po T1 rozpoczyna się, ale przed zatwierdzeniem, druga możliwa do serializacji transakcja T2 zaczyna. Transakcja T2 dodaje do tabeli cztery nowe wiersze, które również spełniają predykat zapytania, i zatwierdza. Poniższy diagram pokazuje kolejność wydarzeń w czasie:

Pytanie brzmi:ile wierszy powinno być w zapytaniu w serializowalnej transakcji T1 liczyć? Pamiętaj, że myślimy tutaj wyłącznie o wymaganiach logicznych, więc unikaj myślenia o tym, które blokady mogą zostać zajęte i tak dalej.
Te dwie transakcje fizycznie pokrywają się w czasie, co jest w porządku. Izolacja możliwa do serializacji wymaga jedynie, aby wyniki tych dwóch transakcji odpowiadały możliwemu wykonaniu szeregowemu. Istnieją oczywiście dwie możliwości logicznego szeregowego harmonogramu transakcji T1 i T2 :
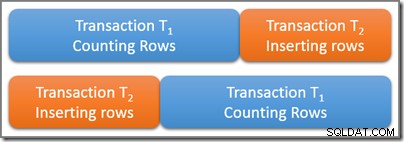
Korzystanie z pierwszego możliwego harmonogramu szeregowego (T1 następnie T2 ) T1 zliczając zapytanie wyświetli pięć wierszy , ponieważ druga transakcja nie rozpocznie się, dopóki pierwsza się nie zakończy. Używając drugiego możliwego harmonogramu logicznego, T1 zapytanie zliczy dziewięć wierszy , ponieważ czterowierszowe wstawianie zostało logicznie zakończone przed rozpoczęciem zliczania transakcji.
Obie odpowiedzi są logicznie poprawne w przypadku serializacji izolacji. Ponadto nie jest możliwa żadna inna odpowiedź (więc transakcja T1 na przykład nie mógł policzyć siedmiu rzędów). To, który z dwóch możliwych wyników jest faktycznie obserwowany, zależy od precyzyjnego harmonogramu i liczby szczegółów implementacji specyficznych dla używanego silnika bazy danych.
Zauważ, że nie wnioskujemy, że transakcje są w jakiś sposób przesunięte w czasie. Fizyczne wykonanie może się nakładać, jak pokazano na pierwszym diagramie, o ile silnik bazy danych zapewnia, że wyniki odzwierciedlają to, co by się stało, gdyby zostały wykonane w jednej z dwóch możliwych sekwencji szeregowych.
Serializacja i zjawisko współbieżności
Oprócz serializacji logicznej standard SQL wspomina również, że transakcja działająca na możliwym do serializacji poziomie izolacji nie może doświadczać pewnych zjawisk współbieżności. Nie może czytać niezatwierdzonych danych (żadnych brudnych odczytów ); a po odczytaniu danych powtórzenie tej samej operacji musi zwrócić dokładnie ten sam zestaw danych (powtarzalne odczyty bez fantomów ).
Norma mówi, że te zjawiska współbieżności są wykluczone na możliwym do serializacji poziomie izolacji jako bezpośrednia konsekwencja wymagania, aby transakcja była logicznie serializowana. Innymi słowy, wymaganie dotyczące serializacji jest sam w sobie wystarczające aby uniknąć brudnego odczytu, niepowtarzalnego odczytu i zjawiska fantomowej współbieżności. Natomiast unikanie samych trzech zjawisk współbieżności jest niewystarczające aby zagwarantować możliwość serializacji, jak wkrótce zobaczymy.
Transakcje, które można serializować, intuicyjnie unikają wszystkich zjawisk związanych ze współbieżnością, ponieważ muszą działać tak, jakby były wykonywane w całkowitej izolacji. W tym sensie poziom izolacji transakcji podlegających serializacji odpowiada powszechnym oczekiwaniom programistów T-SQL.
Implementacje z możliwością serializacji
Zdarza się, że SQL Server używa implementacji blokowania na serializowanym poziomie izolacji, w którym fizyczne blokady są pozyskiwane i utrzymywane do końca transakcji (stąd przestarzała wskazówka tabeli HOLDLOCK jako synonim SERIALIZABLE ).
Ta strategia nie wystarcza do zapewnienia technicznej gwarancji pełnej serializacji, ponieważ nowe lub zmienione dane mogą pojawić się w zakresie wierszy wcześniej przetworzonych przez transakcję. To zjawisko współbieżności jest znane jako fantom i może skutkować efektami, które nie miałyby miejsca w żadnym harmonogramie seryjnym.
Aby zapewnić ochronę przed zjawiskiem fantomowej współbieżności, blokady pobierane przez SQL Server na poziomie izolacji możliwej do serializacji mogą również obejmować blokowanie zakresu kluczy aby zapobiec pojawianiu się nowych lub zmienionych wierszy między wcześniej zbadanymi wartościami klucza indeksu. Blokady zakresu nie są zawsze nabyte w ramach serializowanego poziomu izolacji; wszystko, co możemy ogólnie powiedzieć, to to, że SQL Server zawsze uzyskuje wystarczającą liczbę blokad, aby spełnić logiczne wymagania serializowanego poziomu izolacji. W rzeczywistości implementacje blokujące dość często uzyskują więcej i bardziej rygorystycznych blokad, niż jest to naprawdę potrzebne do zagwarantowania serializacji, ale robię dygresję.
Blokowanie to tylko jedna z możliwych fizycznych implementacji serializowanego poziomu izolacji. Powinniśmy uważać, aby mentalnie oddzielić określone zachowania implementacji blokowania SQL Server od logicznej definicji serializacji.
Jako przykład alternatywnej strategii fizycznej, zobacz implementację PostgreSQL z serializowalną izolacją migawek, chociaż jest to tylko jedna alternatywa. Każda inna fizyczna implementacja ma oczywiście swoje mocne i słabe strony. Na marginesie, zauważ, że Oracle nadal nie zapewnia w pełni zgodnej implementacji serializowanego poziomu izolacji. Ma poziom izolacji nazwany można serializować, ale nie gwarantuje to, że transakcje będą wykonywane zgodnie z pewnym możliwym harmonogramem szeregowym. Zamiast tego Oracle zapewnia izolację migawek gdy żądana jest możliwość serializacji, w podobny sposób jak PostgreSQL przed izolacją migawek do serializacji (SSI ) został wdrożony.
Izolacja migawki nie zapobiega anomaliom współbieżności, takim jak pochylenie zapisu, co nie jest możliwe w przypadku prawdziwie serializowanej izolacji. Jeśli jesteś zainteresowany, możesz znaleźć przykłady skosu zapisu i innych efektów współbieżności dozwolonych przez izolację migawki pod linkiem SSI powyżej. W dalszej części serii omówimy również implementację poziomu izolacji migawki w SQL Server.
Widok z punktu w czasie?
Jednym z powodów, dla których poświęciłem czas na omawianie różnic między logiczną serializacją a fizycznie serializowanym wykonaniem, jest to, że w inny sposób łatwo jest wywnioskować gwarancje, które w rzeczywistości mogą nie istnieć. Na przykład, jeśli myślisz o transakcjach podlegających serializacji jako faktycznie wykonując jedną po drugiej, możesz wywnioskować, że transakcja możliwa do serializacji będzie koniecznie widzieć bazę danych taką, jaka istniała na początku transakcji, zapewniając widok z punktu w czasie.
W rzeczywistości jest to szczegół dotyczący implementacji. Przypomnij sobie poprzedni przykład, gdzie możliwa do serializacji transakcja T1 może legalnie liczyć pięć lub dziewięć rzędów. Jeśli zostanie zwrócona liczba dziewięciu, pierwsza transakcja wyraźnie pokazuje wiersze, które nie istniały w momencie rozpoczęcia transakcji. Ten wynik jest możliwy w SQL Server, ale nie w PostgreSQL SSI, chociaż obie implementacje są zgodne z logicznymi zachowaniami określonymi dla serializowanego poziomu izolacji.
W SQL Server transakcje serializowane niekoniecznie widzą dane w postaci, w jakiej istniały na początku transakcji. Raczej szczegóły implementacji programu SQL Server oznaczają, że transakcja, którą można serializować, widzi najnowsze zatwierdzone dane od momentu pierwszego zablokowania dostępu do danych. Ponadto gwarantujemy, że zestaw ostatnio zatwierdzonych danych, które zostaną ostatecznie odczytane, nie zmieni swojego członkostwa przed zakończeniem transakcji.
Następnym razem
Kolejna część tej serii bada poziom izolacji powtarzalnego odczytu, który zapewnia słabsze gwarancje izolacji transakcji niż możliwość serializacji.
[ Zobacz indeks dla całej serii ]