możliwość serializacji poziom izolacji zapewnia pełną ochronę od efektów współbieżności, które mogą zagrażać integralności danych i prowadzić do nieprawidłowych wyników zapytań. Korzystanie z serializowanej izolacji oznacza, że jeśli transakcja, która daje prawidłowe wyniki bez jednoczesnej aktywności, będzie nadal działać poprawnie podczas konkurowania z dowolną kombinacją jednoczesnych transakcji.
To bardzo potężna gwarancja i taki, który prawdopodobnie odpowiada intuicyjnym oczekiwaniom izolacji transakcji wielu programistów T-SQL (chociaż w rzeczywistości stosunkowo niewielu z nich rutynowo używa serializowanej izolacji w środowisku produkcyjnym).
Standard SQL definiuje trzy dodatkowe poziomy izolacji, które oferują znacznie słabszy ACID gwarantuje izolację niż możliwość serializacji, w zamian za potencjalnie wyższą współbieżność i mniej potencjalnych skutków ubocznych, takich jak blokowanie, zakleszczenie i przerywanie czasu zatwierdzania.
W przeciwieństwie do serializowanej izolacji, inne poziomy izolacji są definiowane wyłącznie w kategoriach określonych zjawisk współbieżności, które można zaobserwować. Następny najsilniejszy ze standardowych poziomów izolacji po serializacji nosi nazwę odczyt powtarzalny . Standard SQL określa, że transakcje na tym poziomie pozwalają na pojedyncze zjawisko współbieżności znane jako fantom .
Tak jak wcześniej widzieliśmy ważne różnice między powszechnym, intuicyjnym znaczeniem właściwości transakcyjnych ACID a rzeczywistością, zjawisko fantomu obejmuje szerszy zakres zachowań, niż jest to często doceniane.
Ten post z serii analizuje faktyczne gwarancje zapewniane przez powtarzalne czytanie poziom izolacji i pokazuje niektóre z zachowań związanych z fantomami, które można napotkać. Aby zilustrować kilka punktów, odwołamy się do następującego prostego przykładowego zapytania, w którym prostym zadaniem jest policzenie całkowitej liczby wierszy w tabeli:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Powtarzalny odczyt
Jedną z dziwnych rzeczy w przypadku powtarzalnego poziomu izolacji odczytu jest to, że nie faktycznie gwarantuje, że odczyty są powtarzalne , przynajmniej w jednym powszechnie rozumianym sensie. To kolejny przykład, w którym samo intuicyjne znaczenie może być mylące. Dwukrotne wykonanie tego samego zapytania w ramach tej samej powtarzalnej transakcji odczytu może rzeczywiście zwrócić różne wyniki.
Ponadto implementacja odczytu powtarzalnego w SQL Server oznacza, że pojedynczy odczyt zestawu danych może pominąć niektóre wiersze to logicznie powinno być uwzględnione w wyniku zapytania. Chociaż niewątpliwie jest to specyficzne dla implementacji, to zachowanie jest w pełni zgodne z definicją powtarzalnego odczytu zawartą w standardzie SQL.
Ostatnią rzeczą, którą chcę szybko zauważyć przed zagłębieniem się w szczegóły, jest to, że powtarzalny odczyt w SQL Server nie zapewnić widok danych z określonego punktu w czasie.
Niepowtarzalne odczyty
Poziom izolacji powtarzalnego odczytu daje gwarancję, że dane nie ulegną zmianie przez cały czas trwania transakcji po jej przeczytaniu po raz pierwszy.
Definicja ta zawiera kilka subtelności. Po pierwsze, pozwala na zmianę danych po transakcja rozpoczyna się, ale zanim dane są pierwsze dostępny. Po drugie, nie ma gwarancji, że transakcja faktycznie napotka wszystkie dane, które logicznie kwalifikują. Wkrótce zobaczymy przykłady obu.
Jest jeszcze jedna kwestia wstępna, którą musimy szybko zejść z drogi, związana z przykładowym zapytaniem, którego będziemy używać. Szczerze mówiąc, semantyka tego zapytania jest nieco rozmyta. Ryzykując, że zabrzmi to nieco filozoficznie, co to oznacza policzyć liczbę wierszy w tabeli? Czy wynik powinien odzwierciedlać stan tabeli, jaki był w określonym momencie? Czy ten moment powinien być początkiem lub końcem transakcji, czy czymś innym?
Może się to wydawać nieco skomplikowane, ale pytanie jest prawidłowe w każdej bazie danych, która obsługuje współbieżne odczyty i modyfikacje danych. Wykonanie naszego przykładowego zapytania może zająć dowolnie długi czas (biorąc pod uwagę na przykład wystarczająco dużą tabelę lub ograniczenia zasobów), więc współbieżne zmiany są nie tylko możliwe, ale mogą być nieuniknione .
Fundamentalną kwestią jest tutaj możliwość wystąpienia zjawiska współbieżności zwanego fantomem w standardzie SQL. Podczas gdy liczymy wiersze w tabeli, inna równoczesna transakcja może wstawić nowe wiersze w miejscu, które już sprawdziliśmy, lub zmień wiersz, którego jeszcze nie sprawdziliśmy w taki sposób, że przesuwa się w miejsce, które już szukaliśmy. Ludzie często myślą o fantomach jako o rzędach, które mogą magicznie pojawić się podczas drugiego czytania, w osobnym stwierdzeniu, ale efekty mogą być znacznie bardziej subtelne.
Przykład współbieżnego wstawiania
Ten pierwszy przykład pokazuje, jak współbieżne wstawki mogą generować niepowtarzalne odczytać i/lub spowodować pominięcie wierszy. Wyobraź sobie, że nasza tabela testowa początkowo zawiera pięć wierszy z wartościami pokazanymi poniżej:

Ustawiamy teraz poziom izolacji na odczyt powtarzalny, rozpoczynamy transakcję i uruchamiamy nasze zapytanie zliczające. Jak można się spodziewać, wynik to pięć . Jak dotąd nie ma wielkiej tajemnicy.
Nadal wykonywane w ramach tej samej powtarzalnej transakcji odczytu , ponownie uruchamiamy zapytanie zliczające, ale tym razem, gdy druga równoczesna transakcja wstawia nowe wiersze do tej samej tabeli. Poniższy diagram pokazuje sekwencję zdarzeń, przy czym druga transakcja dodaje wiersze o wartościach 2 i 6 (możesz zauważyć, że te wartości były widoczne przez ich brak tuż powyżej):
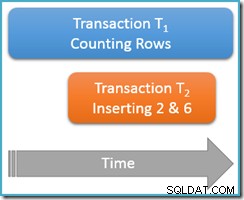
Jeśli nasze zapytanie zliczające działało w możliwym do serializacji poziom izolacji, gwarantowane byłoby policzenie albo pięć lub siedem wierszy (zobacz poprzedni artykuł z tej serii, jeśli potrzebujesz odświeżenia, dlaczego tak się dzieje). Jak działa bieganie w mniej odizolowanym powtarzalny poziom odczytu wpływa na rzeczy?
Cóż, powtarzalna lektura izolacja gwarantuje, że przy drugim uruchomieniu kwerendy zliczającej zostaną wyświetlone wszystkie wcześniej odczytane wiersze i będą one w takim samym stanie jak poprzednio. Haczyk polega na tym, że powtarzalna izolacja odczytu nie mówi nic o tym, jak transakcja powinna traktować nowe wiersze (fantomy).
Wyobraź sobie, że nasza transakcja polegająca na liczeniu wierszy (T1 ) ma fizyczną strategię wykonywania, w której wiersze są przeszukiwane w rosnącej kolejności indeksu. Jest to częsty przypadek, na przykład gdy silnik wykonawczy wykorzystuje skanowanie indeksu b-drzewa w kolejności do przodu. Teraz zaraz po transakcji T1 zlicza wiersze 1 i 3 w kolejności rosnącej, transakcja T2 może zakraść się, wstawić nowe wiersze 2 i 6, a następnie zatwierdzić transakcję.
Chociaż w tym momencie myślimy przede wszystkim o zachowaniach logicznych, powinienem wspomnieć, że w implementacji blokowania powtarzalnego odczytu SQL Server nie ma nic w celu zapobiegania transakcja T2 od robienia tego. Wspólne blokady podjęte przez transakcję T1 we wcześniej odczytanych wierszach zapobiegają zmianie tych wierszy, ale nie zapobiegają nowym wierszom przed wstawieniem do zakresu wartości testowanych przez nasze zapytanie zliczające (w przeciwieństwie do blokad zakresu kluczy w blokowaniu serializowanej izolacji).
W każdym razie, po zatwierdzeniu dwóch nowych wierszy, transakcja T1 kontynuuje wyszukiwanie w porządku rosnącym, ostatecznie napotykając wiersze 4, 5, 6 i 7. Zauważ, że T1 widzi nowy wiersz 6 w tym scenariuszu, ale nie nowy wiersz 2 (ze względu na uporządkowane wyszukiwanie i jego pozycję w momencie wstawienia).
W rezultacie powtarzalny odczyt zliczanie raportów zapytań, że tabela zawiera sześć wierszy (wartości 1, 3, 4, 5, 6 i 7). Ten wynik jest niezgodny z poprzednim wynikiem pięciu wierszy uzyskane w ramach tej samej transakcji . Drugi odczyt liczył fantomowy rząd 6, ale pominął fantomowy rząd 2. To tyle, jeśli chodzi o intuicyjne znaczenie powtarzalnego odczytu!
Przykład współbieżnej aktualizacji
Podobna sytuacja może wystąpić przy jednoczesnej aktualizacji zamiast wkładki. Wyobraź sobie, że nasza tabela testowa została zresetowana tak, aby zawierała te same pięć wierszy, co poprzednio:

Tym razem zapytanie zliczające uruchomimy tylko raz na powtarzalnej lekturze poziom izolacji, podczas gdy druga równoczesna transakcja aktualizuje wiersz o wartości 5, aby miał wartość 2:
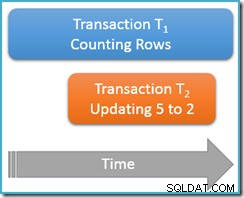
Transakcja T1 ponownie rozpoczyna liczenie rzędów (w kolejności rosnącej) napotykając najpierw rzędy 1 i 3. Teraz transakcja T2 wślizguje się, zmienia wartość wiersza 5 na 2 i zatwierdza:

Pokazałem zaktualizowany wiersz w tej samej pozycji co poprzednio, aby zmiana była jasna, ale indeks b-drzewa, który skanujemy, utrzymuje dane w logicznej kolejności, więc rzeczywisty obraz jest bliższy temu:

Chodzi o to, że transakcja T1 jednocześnie skanuje tę samą strukturę w kolejności do przodu, obecnie znajduje się tuż za wpis dla wartości 3. Zapytanie zliczające kontynuuje skanowanie do przodu od tego punktu, znajdując wiersze 4 i 7 (ale nie wiersz 5 oczywiście).
Podsumowując, w tym scenariuszu zapytanie zliczające wyświetliło wiersze 1, 3, 4 i 7. Zgłasza liczbę czterech wierszy – co jest dziwne, ponieważ wydaje się, że tabela zawierała pięć wierszy przez cały czas!
Drugie uruchomienie zapytania zliczającego w ramach tej samej powtarzalnej transakcji odczytu spowoduje zgłoszenie pięć rzędy, z podobnych powodów jak poprzednio. Na koniec, jeśli się zastanawiasz, jednoczesne usuwanie nie daje możliwości anomalii opartej na fantomach w przypadku powtarzalnej izolacji odczytu.
Ostateczne myśli
W obu poprzednich przykładach użyto skanów struktury indeksu w porządku rosnącym, aby przedstawić prosty widok rodzaju efektów, jakie fantomy mogą mieć na odczyt powtarzalny zapytanie. Ważne jest, aby zrozumieć, że te ilustracje nie opierają się w żaden istotny sposób na kierunku skanowania lub fakcie, że zastosowano indeks b-drzewa. Proszę nie tworzą pogląd, że zamówione skany są w jakiś sposób odpowiedzialne i dlatego należy ich unikać!
Te same efekty współbieżności można zaobserwować przy skanowaniu w porządku malejącym struktury indeksu lub w wielu innych scenariuszach fizycznego dostępu do danych. Ogólnie rzecz biorąc, zjawiska fantomowe są wyraźnie dozwolone (choć nie są wymagane) przez standard SQL dla transakcji na powtarzalnym poziomie izolacji odczytu.
Nie wszystkie transakcje wymagają pełnej gwarancji izolacji zapewnianej przez izolację z możliwością serializacji i niewiele systemów mogłoby tolerować skutki uboczne, gdyby tak było. Niemniej jednak opłaca się dobrze rozumieć, które dokładnie gwarantują różne poziomy izolacji.
Następnym razem
W następnej części tej serii omówiono jeszcze słabsze gwarancje izolacji oferowane przez domyślny poziom izolacji SQL Server, przeczytaj zatwierdzone .
[ Zobacz indeks dla całej serii ]