Od dawna ustalono, że zmienne tabelowe z dużą liczbą wierszy mogą być problematyczne, ponieważ optymalizator zawsze widzi je jako mające jeden wiersz. Bez ponownej kompilacji po wypełnieniu zmiennej tabeli (ponieważ wcześniej jest ona pusta), nie ma kardynalności tabeli, a automatyczne ponowne kompilacje nie mają miejsca, ponieważ zmienne tabeli nie podlegają nawet progowi ponownej kompilacji. Plany są zatem oparte na liczności tabeli równej zero, a nie jeden, ale minimalna jest zwiększona do jednego, jak opisuje Paul White (@SQL_Kiwi) w tej odpowiedzi dba.stackexchange.
Sposób, w jaki zwykle możemy obejść ten problem, to dodanie OPTION (RECOMPILE) do zapytania odwołującego się do zmiennej tabeli, zmuszając optymalizator do sprawdzenia liczności zmiennej tabeli po jej wypełnieniu. Aby uniknąć konieczności ręcznego zmieniania każdego zapytania, aby dodać jawną wskazówkę dotyczącą ponownej kompilacji, wprowadzono nową flagę śledzenia (2453) w dodatku Service Pack 2 dla programu SQL Server 2012 i aktualizacji zbiorczej programu SQL Server 2014 nr 3:
- KB #2952444:NAPRAW:Słaba wydajność podczas używania zmiennych tabeli w SQL Server 2012 lub SQL Server 2014
Gdy flaga śledzenia 2453 jest aktywna, optymalizator może uzyskać dokładny obraz liczności tabeli po utworzeniu zmiennej tabeli. Może to być Dobra Rzecz™ dla wielu zapytań, ale prawdopodobnie nie wszystkich, i powinieneś być świadomy, jak to działa inaczej niż OPTION (RECOMPILE) . Przede wszystkim optymalizacja osadzania parametrów, o której mówi Paul White w tym poście, występuje w sekcji OPTION (RECOMPILE) , ale nie pod nową flagą śledzenia.
Prosty test
Mój początkowy test polegał po prostu na wypełnieniu zmiennej tabeli i wybraniu z niej; dało to zbyt znajomą szacunkową liczbę wierszy wynoszącą 1. Oto test, który przeprowadziłem (i dodałem wskazówkę dotyczącą ponownej kompilacji do porównania):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Korzystając z SQL Sentry Plan Explorer, możemy zobaczyć, że plan graficzny dla obu zapytań w tym przypadku jest identyczny, prawdopodobnie przynajmniej w części, ponieważ jest to dosłownie trywialny plan:

Graficzny plan prostego skanowania indeksu względem @t
Jednak szacunki nie są takie same. Mimo że flaga śledzenia jest włączona, nadal otrzymujemy szacunkową wartość 1 wychodzącą ze skanowania indeksu, jeśli nie użyjemy wskazówki dotyczącej ponownej kompilacji:
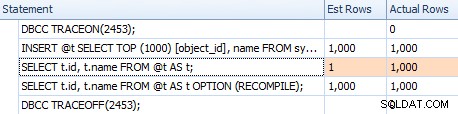
Porównywanie szacunków dla trywialnego planu w siatce wyciągów
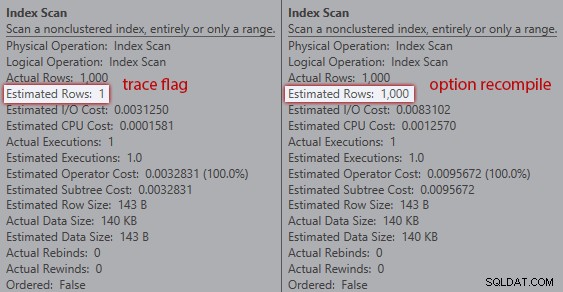
Porównywanie szacunków między flagą śledzenia (po lewej) a ponowną kompilacją (po prawej)
Jeśli kiedykolwiek byłeś przy mnie osobiście, prawdopodobnie możesz sobie wyobrazić twarz, którą zrobiłem w tym momencie. Myślałem na pewno, że albo artykuł KB zawiera zły numer flagi śledzenia, albo że potrzebuję innych włączonych ustawień, aby było naprawdę aktywne.
Benjamin Nevarez (@BenjaminNevarez) szybko zwrócił mi uwagę, że muszę przyjrzeć się bliżej artykułowi KB „Błędy, które zostały naprawione w dodatku Service Pack 2 dla SQL Server 2012”. Chociaż ukryli tekst za ukrytym punktorem w sekcji Highlights> Relational Engine, artykuł z listą poprawek nieco lepiej opisuje zachowanie flagi śledzenia niż artykuł oryginalny (podkreślenie moje):
Jeśli zmienna tabeli połączona jest z innymi tabelami w programie SQL Server może to skutkować niską wydajnością z powodu niewydajnego wyboru planu kwerend, ponieważ program SQL Server nie obsługuje statystyk ani nie śledzi liczby wierszy w zmiennej tabeli podczas kompilowania planu kwerend.Tak więc z tego opisu wynika, że flaga śledzenia ma na celu rozwiązanie problemu tylko wtedy, gdy zmienna tabeli uczestniczy w łączeniu. (Dlaczego to rozróżnienie nie zostało wprowadzone w oryginalnym artykule, nie mam pojęcia.) Ale działa to również, jeśli sprawimy, że zapytania będą wykonywać trochę więcej pracy – powyższe zapytanie jest uważane za trywialne przez optymalizator, a flaga śledzenia nie w takim przypadku nawet nie próbowałem nic zrobić. Ale zadziała, jeśli zostanie przeprowadzona optymalizacja oparta na kosztach, nawet bez łączenia; flaga śledzenia po prostu nie ma wpływu na trywialne plany. Oto przykład nietrywialnego planu, który nie obejmuje dołączania:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Ten plan nie jest już trywialny; optymalizacja jest oznaczona jako pełna. Większość kosztów jest przenoszona na operatora sortującego:
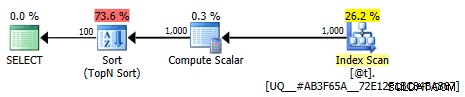
Mniej trywialny plan graficzny
Szacunki są zgodne dla obu zapytań (tym razem zachowam wskazówki dotyczące narzędzi, ale zapewniam, że są takie same):

Siatka instrukcji dla mniej trywialnych planów z podpowiedzią rekompilacji i bez niej
Wygląda więc na to, że artykuł z bazy wiedzy nie jest dokładny — udało mi się wymusić zachowanie oczekiwanej flagi śledzenia bez wprowadzania sprzężenia. Ale chcę to również przetestować za pomocą sprzężenia.
Lepszy test
Weźmy ten prosty przykład, z flagą śledzenia i bez niej:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
Bez flagi śledzenia optymalizator szacuje, że jeden wiersz będzie pochodził ze skanowania indeksu względem zmiennej tabeli. Jednak po włączeniu flagi śledzenia otrzymuje 1000 wierszy od razu:
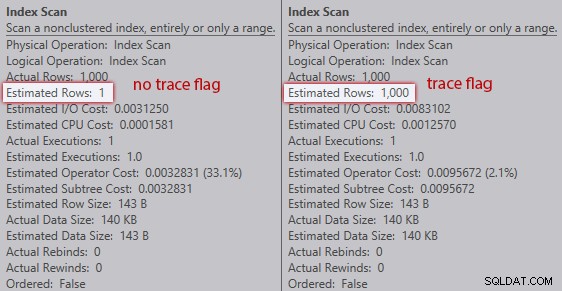
Porównanie oszacowań skanowania indeksu (brak flagi śledzenia po lewej stronie, flaga śledzenia po prawej)
Na tym różnice się nie kończą. Jeśli przyjrzymy się bliżej, zauważymy, że optymalizator podjął różne decyzje, a wszystkie wynikają z tych lepszych szacunków:
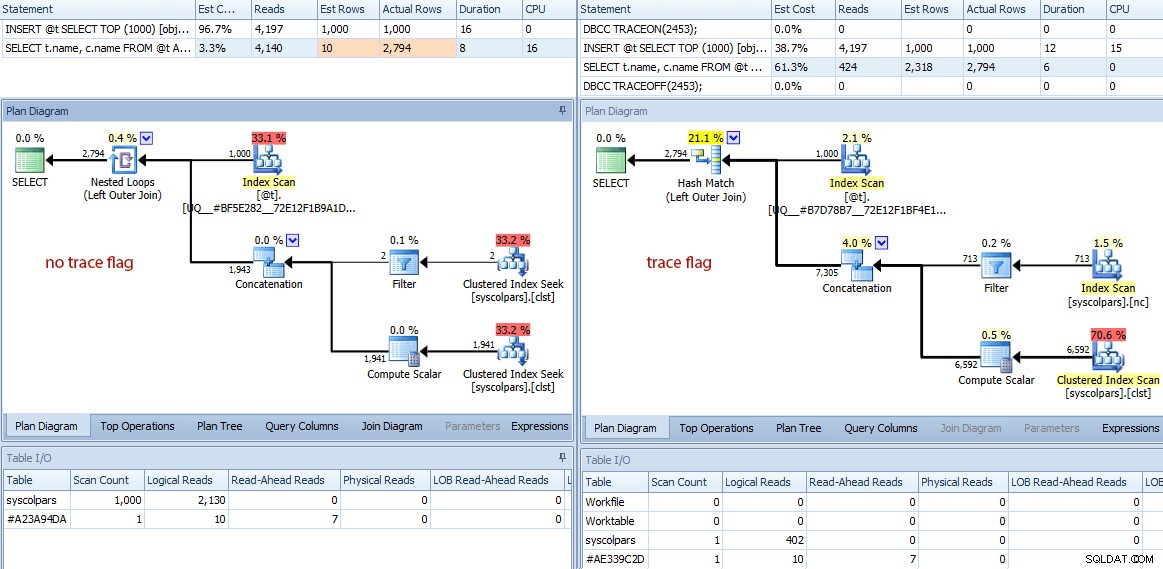
Porównanie planów (brak flagi śledzenia po lewej stronie, flaga śledzenia po prawej)
Krótkie podsumowanie różnic:
- Kwerenda bez flagi śledzenia wykonała 4140 operacji odczytu, podczas gdy zapytanie z poprawionym oszacowaniem wykonało tylko 424 (około 90% redukcji).
- Optymalizator oszacował, że całe zapytanie zwróci 10 wierszy bez flagi śledzenia i znacznie dokładniejsze 2318 wierszy przy użyciu flagi śledzenia.
- Bez flagi śledzenia optymalizator zdecydował się wykonać łączenie zagnieżdżonych pętli (co ma sens, gdy jedno z danych wejściowych jest oszacowane jako bardzo małe). Doprowadziło to do tego, że operator konkatenacji i oba wyszukiwania indeksu wykonały się 1000 razy, w przeciwieństwie do dopasowania skrótu wybranego pod flagą śledzenia, gdzie operator konkatenacji i oba skany zostały wykonane tylko raz.
- Karta Table I/O pokazuje również 1000 skanów (skanowanie zakresu zamaskowane jako szukanie indeksu) i znacznie wyższy logiczny licznik odczytów z
syscolpars(tabela systemowa zasys.all_columns). - Chociaż nie wpłynęło to znacząco na czas trwania (24 milisekundy w porównaniu do 18 milisekund), prawdopodobnie możesz sobie wyobrazić, jaki wpływ te inne różnice mogą mieć na poważniejsze zapytanie.
- Jeśli przełączymy diagram na szacunkowe koszty, możemy zobaczyć, jak bardzo zmienna tabeli może oszukać optymalizator bez flagi śledzenia:
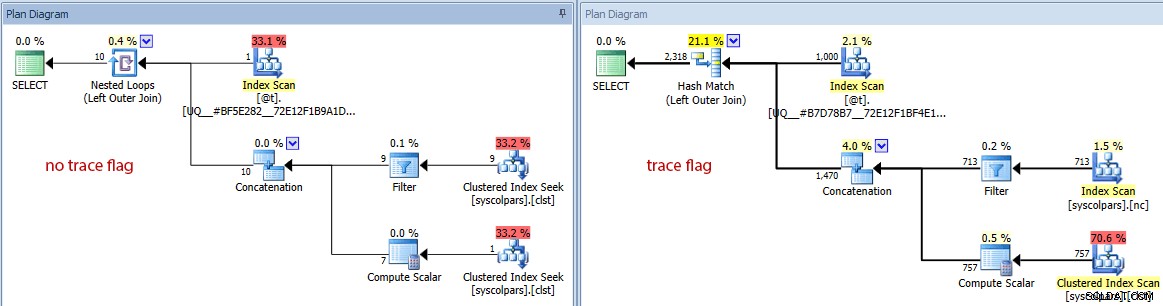
Porównywanie szacowanej liczby wierszy (brak flagi śledzenia po lewej stronie, śledzenie flaga po prawej)
To jasne i nie szokujące, że optymalizator lepiej radzi sobie z wyborem właściwego planu, gdy ma dokładny obraz zaangażowanej kardynalności. Ale jakim kosztem?
Rekompilacja i obciążenie
Kiedy używamy OPTION (RECOMPILE) z powyższą partią, bez włączonej flagi śledzenia, otrzymujemy następujący plan – który jest prawie identyczny z planem z flagą śledzenia (jedyną zauważalną różnicą jest to, że szacowane wiersze to 2316 zamiast 2318):
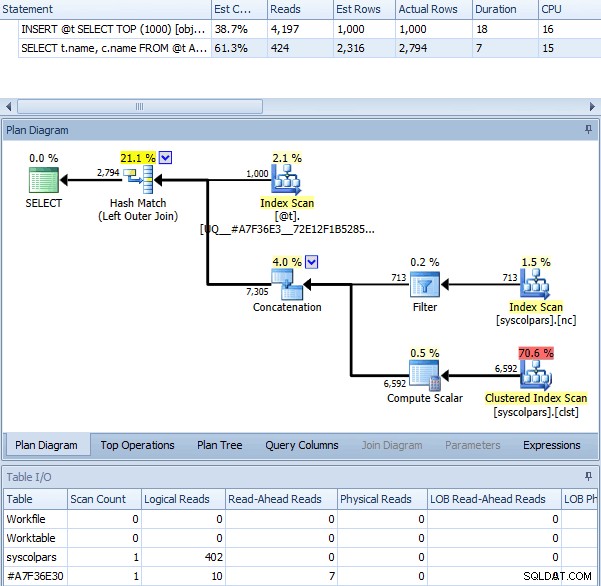
To samo zapytanie z OPTION (RECOMPILE)
Tak więc może to prowadzić do przekonania, że flaga śledzenia osiąga podobne wyniki, wywołując za każdym razem ponowną kompilację. Możemy to zbadać za pomocą bardzo prostej sesji Extended Events:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Uruchomiłem następujący zestaw partii, które wykonały 20 zapytań z (a) brakiem opcji rekompilacji lub flagi śledzenia, (b) opcją rekompilacji i (c) flagą śledzenia na poziomie sesji.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Następnie spojrzałem na dane wydarzenia:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Wyniki pokazują, że w ramach standardowego zapytania nie nastąpiła ponowna kompilacja, instrukcja odwołująca się do zmiennej tabeli została ponownie skompilowana raz pod flagą śledzenia i, jak można się spodziewać, za każdym razem z RECOMPILE opcja:
| sql_text | recompile_count |
|---|---|
| /* ponowna kompilacja */ DECLARE @t TABLE (i INT … | 20 |
| /* flaga śledzenia */ DBCC TRACEON(2453); ZADEKLARUJ @t… | 1 |
Wyniki zapytania o dane XEvents
Następnie wyłączyłem sesję Extended Events, a następnie zmieniłem partię, aby mierzyć w skali. Zasadniczo kod mierzy 1000 iteracji tworzenia i wypełniania zmiennej tabeli, a następnie wybiera jej wyniki do tabeli #temp (jeden sposób na pominięcie danych wyjściowych tak wielu jednorazowych zestawów wyników), przy użyciu każdej z trzech metod.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Uruchomiłem tę partię 10 razy i wziąłem średnie; byli:
| Metoda | Średni czas trwania (milisekundy) |
|---|---|
| Domyślne | 23 148,4 |
| Ponowna kompilacja | 29 959,3 |
| Flaga śledzenia | 22 100,7 |
Średni czas trwania 1000 iteracji
W takim przypadku uzyskiwanie prawidłowych oszacowań za każdym razem przy użyciu wskazówki dotyczącej ponownej kompilacji było znacznie wolniejsze niż zachowanie domyślne, ale użycie flagi śledzenia było nieco szybsze. Ma to sens, ponieważ – podczas gdy obie metody korygują domyślne zachowanie polegające na użyciu fałszywego oszacowania (i w rezultacie uzyskują zły plan), ponowna kompilacja pobiera zasoby, a gdy nie dają lub nie mogą zapewnić bardziej wydajnego planu, mają tendencję do przyczyniają się do całkowitego czasu trwania partii.
Wydaje się proste, ale poczekaj…
Powyższy test jest nieco – i celowo – wadliwy. Wstawiamy tę samą liczbę wierszy (1000) do zmiennej tabeli za każdym razem . Co się stanie, jeśli początkowa populacja zmiennej tabeli różni się dla różnych partii? Na pewno zobaczymy wtedy rekompilacje, nawet pod flagą śledzenia, prawda? Czas na kolejny test. Skonfigurujmy nieco inną sesję Extended Events, tylko z inną nazwą pliku docelowego (aby nie pomylić żadnych danych z drugiej sesji):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Teraz przyjrzyjmy się tej partii, konfigurując liczbę wierszy dla każdej iteracji, które znacznie się różnią. Uruchomimy to trzy razy, usuwając odpowiednie komentarze, dzięki czemu mamy jedną partię bez flagi śledzenia lub jawną rekompilację, jedną partię z flagą śledzenia i jedną partię z OPTION (RECOMPILE) (posiadanie dokładnego komentarza na początku ułatwia identyfikację tych partii w miejscach takich jak wyjście zdarzeń rozszerzonych):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Uruchomiłem te partie w Management Studio, otworzyłem je pojedynczo w Eksploratorze planów i przefiltrowałem drzewo instrukcji tylko na SELECT zapytanie. Możemy zobaczyć różne zachowanie w trzech partiach, patrząc na szacunkowe i rzeczywiste wiersze:

Porównanie trzech partii, patrząc na wiersze szacunkowe i rzeczywiste
W siatce po prawej stronie wyraźnie widać, gdzie nie doszło do ponownej kompilacji pod flagą śledzenia
Możemy sprawdzić dane XEvents, aby zobaczyć, co faktycznie się stało z rekompilacjami:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Wyniki:
| sql_text | recompile_count |
|---|---|
| /* ponowna kompilacja */ DECLARE @i INT =1; PODCZAS… | 6 |
| /* flaga śledzenia */ DECLARE @i INT =1; PODCZAS… | 4 |
Wyniki zapytania o dane XEvents
Bardzo interesujące! Pod flagą śledzenia *czynimy* ponowne kompilacje, ale tylko wtedy, gdy wartość parametru środowiska uruchomieniowego znacznie różni się od wartości z pamięci podręcznej. Gdy wartość środowiska wykonawczego jest inna, ale nie za bardzo, nie otrzymujemy ponownej kompilacji i używane są te same szacunki. Jest więc jasne, że flaga śledzenia wprowadza próg ponownej kompilacji do zmiennych tabeli i potwierdziłem (poprzez oddzielny test), że używa on tego samego algorytmu, co ten opisany dla tabel #temp w tym „starożytnym”, ale wciąż istotnym artykule. Udowodnię to w kolejnym poście.
Ponownie przetestujemy wydajność, uruchamiając wsad 1000 razy (z wyłączoną sesją zdarzeń rozszerzonych) i mierząc czas trwania:
| Metoda | Średni czas trwania (milisekundy) |
|---|---|
| Domyślne | 101 285,4 |
| Ponowna kompilacja | 111423,3 |
| Flaga śledzenia | 110 318,2 |
Średni czas trwania 1000 iteracji
W tym konkretnym scenariuszu tracimy około 10% wydajności, wymuszając ponowną kompilację za każdym razem lub używając flagi śledzenia. Nie jestem do końca pewien, jak rozkładała się delta:czy plany były oparte na lepszych szacunkach znacząco lepszy? Czy ponowna kompilacja zrównoważyła jakikolwiek wzrost wydajności o tyle? ? Nie chcę poświęcać temu zbyt wiele czasu i był to trywialny przykład, ale pokazuje, że zabawa sposobem, w jaki działa optymalizator, może być nieprzewidywalną sprawą. Czasami może być lepiej z domyślnym zachowaniem kardynalności =1, wiedząc, że nigdy nie spowodujesz niepotrzebnych rekompilacji. Flaga śledzenia może mieć sens, jeśli masz zapytania, w których wielokrotnie wypełniasz zmienne tabeli tym samym zestawem danych (powiedzmy, tabela wyszukiwania kodu pocztowego) lub zawsze używasz 50 lub 1000 wierszy (powiedzmy, wypełnianie zmienna tabeli do wykorzystania w paginacji). W każdym razie z pewnością powinieneś przetestować wpływ, jaki ma to na każde obciążenie, w którym planujesz wprowadzić flagę śledzenia lub jawną ponowną kompilację.
TVP i typy tabel
Byłem też ciekaw, jak wpłynie to na typy stołów i czy zobaczymy jakąkolwiek poprawę kardynalności dla TVP, gdzie występuje ten sam objaw. Stworzyłem więc prosty typ tabeli, który naśladuje używaną do tej pory zmienną table:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Następnie wziąłem powyższą partię i po prostu zastąpiłem DECLARE @t TABLE(id INT PRIMARY KEY); z DECLARE @t dbo.t; – wszystko inne pozostało dokładnie takie samo. Uruchomiłem te same trzy partie i oto, co zobaczyłem:

Porównywanie wartości szacunkowych i rzeczywistych między zachowaniem domyślnym, ponowną kompilacją opcji i flagą śledzenia 2453
A więc tak, wydaje się, że flaga śledzenia działa dokładnie w ten sam sposób w przypadku TVP – ponowna kompilacja generuje nowe oszacowania dla optymalizatora, gdy liczba wierszy przekracza próg rekompilacji i jest pomijana, gdy liczba wierszy jest „wystarczająco bliska”.
Plusy, minusy i zastrzeżenia
Jedną z zalet flagi śledzenia jest to, że możesz uniknąć niektórych ponownie kompiluje i nadal widzi kardynalność tabeli – o ile oczekujesz, że liczba wierszy w zmiennej tabeli będzie stabilna lub nie zaobserwujesz znaczących odchyleń planu ze względu na zmienną kardynalność. Innym jest to, że możesz włączyć go globalnie lub na poziomie sesji i nie musisz wprowadzać wskazówek dotyczących ponownej kompilacji do wszystkich zapytań. I wreszcie, przynajmniej w przypadku, gdy liczność zmiennej tabeli była stabilna, właściwe oszacowanie prowadziło do lepszej wydajności niż domyślna, a także lepszej wydajności niż przy użyciu opcji rekompilacji – wszystkie te kompilacje z pewnością mogą się sumować.
Oczywiście są też pewne wady. Jeden, o którym wspomniałem powyżej, jest w porównaniu do OPTION (RECOMPILE) tracisz pewne optymalizacje, takie jak osadzanie parametrów. Innym jest to, że flaga śledzenia nie będzie miała oczekiwanego wpływu na trywialne plany. Po drodze odkryłem, że używając QUERYTRACEON wskazówka, aby wymusić flagę śledzenia na poziomie zapytania nie działa – o ile wiem, flaga śledzenia musi być na miejscu, gdy zmienna tabeli lub TVP jest tworzona i/lub wypełniana, aby optymalizator widział kardynalność powyżej 1.
Należy pamiętać, że uruchomienie flagi śledzenia globalnie wprowadza możliwość regresji planu zapytania do dowolnego zapytania dotyczącego zmiennej tabeli (dlatego ta funkcja została wprowadzona pod flagą śledzenia), więc należy przetestować całe obciążenie bez względu na to, jak używasz flagi śledzenia. Ponadto, gdy testujesz to zachowanie, zrób to w bazie danych użytkowników; niektóre optymalizacje i uproszczenia, których zwykle oczekujesz, po prostu nie mają miejsca, gdy kontekst jest ustawiony na tempdb, więc każde zaobserwowane tam zachowanie może nie pozostać spójne po przeniesieniu kodu i ustawień do bazy danych użytkownika.
Wniosek
Jeśli używasz zmiennych tabeli lub wartości TVP z dużą, ale stosunkowo spójną liczbą wierszy, może okazać się korzystne włączenie tej flagi śledzenia dla niektórych partii lub procedur w celu uzyskania dokładnej kardynalności tabeli bez ręcznego wymuszania ponownej kompilacji poszczególnych zapytań. Możesz również użyć flagi śledzenia na poziomie wystąpienia, co będzie miało wpływ na wszystkie zapytania. Ale tak jak w przypadku każdej zmiany, w obu przypadkach będziesz musiał być ostrożny w testowaniu wydajności całego obciążenia, jawnie wypatrując wszelkich regresji i upewniając się, że chcesz zachować zachowanie flagi śledzenia, ponieważ możesz zaufać stabilności zmiennej tabeli liczba wierszy.
Cieszę się, że flaga śledzenia została dodana do SQL Server 2014, ale byłoby lepiej, gdyby stało się to zachowaniem domyślnym. Nie chodzi o to, że używanie dużych zmiennych tabel w porównaniu z dużymi tabelami #temp ma jakąś znaczącą przewagę, ale byłoby miło widzieć większą parzystość między tymi dwoma tymczasowymi typami struktur, które można by dyktować na wyższym poziomie. Im więcej mamy parzystości, tym mniej ludzie muszą zastanawiać się nad tym, którego powinni użyć (a przynajmniej mają mniej kryteriów do rozważenia przy wyborze). Martin Smith ma świetne pytania i odpowiedzi na temat dba.stackexchange, które prawdopodobnie są teraz uaktualniane:Jaka jest różnica między tabelą tymczasową a zmienną tabeli w SQL Server?
Ważna uwaga
Jeśli zamierzasz zainstalować dodatek Service Pack 2 dla programu SQL Server 2012 (niezależnie od tego, czy ma korzystać z tej flagi śledzenia), zapoznaj się również z moim postem na temat regresji w SQL Server 2012 i 2014, która może – w rzadkich przypadkach – wprowadzić potencjalna utrata lub uszkodzenie danych podczas odbudowy indeksu online. Dostępne są zbiorcze aktualizacje dla SQL Server 2012 SP1 i SP2, a także dla SQL Server 2014. Nie będzie poprawki dla gałęzi 2012 RTM.
Dalsze testy
Mam na liście inne rzeczy do przetestowania. Po pierwsze, chciałbym sprawdzić, czy ta flaga śledzenia ma jakikolwiek wpływ na typy tabel w pamięci w programie SQL Server 2014. Zamierzam również udowodnić ponad wszelką wątpliwość, że flaga śledzenia 2453 używa tego samego progu rekompilacji dla tabeli zmienne i TVP, tak jak w przypadku tabel #temp.