Kilka tygodni temu zespół SQLskills był w Tampie na naszym wydarzeniu Performance Tuning Immersion Event (IE2), a ja zajmowałem się planami bazowymi. Linie bazowe to temat bliski i bliski memu sercu, ponieważ są tak cenne z wielu powodów. Dwa z tych powodów, które zawsze przytaczam, niezależnie od tego, czy uczę, czy pracuję z klientami, to używanie linii bazowych do rozwiązywania problemów z wydajnością, a następnie wyznaczanie trendów w użyciu i dostarczanie szacunków dotyczących planowania wydajności. Ale są one również niezbędne podczas dostrajania wydajności lub testowania – niezależnie od tego, czy myślisz o istniejących wskaźnikach wydajności jako o wartości bazowej, czy nie.
Podczas modułu przejrzałem różne źródła danych, takie jak Performance Monitor, DMV oraz dane śledzenia lub XE, i pojawiło się pytanie związane z ładowaniem danych. W szczególności pytanie brzmiało, czy lepiej jest ładować dane do tabeli bez indeksów, a następnie tworzyć je po zakończeniu, w porównaniu z posiadaniem indeksów na miejscu podczas ładowania danych. Moja odpowiedź brzmiała:„Zazwyczaj tak”. Moje osobiste doświadczenie jest takie, że zawsze tak jest, ale nigdy nie wiadomo, na jakie zastrzeżenie lub jednorazowy scenariusz ktoś może natknąć się, gdy zmiana wydajności nie jest taka, jak oczekiwano, i tak jak w przypadku wszystkie pytania dotyczące skuteczności, nie masz pewności, dopóki ich nie przetestujesz. Dopóki nie ustalisz punktu odniesienia dla jednej metody, a następnie nie sprawdzisz, czy druga metoda jest lepsza od tego punktu odniesienia, to tylko zgadujesz. Pomyślałem, że fajnie byłoby przetestować w tym scenariuszu nie tylko po to, by udowodnić, co oczekuję, że jest prawdziwe, ale także po to, by pokazać, jakie metryki chciałbym zbadać, dlaczego i jak je przechwycić. Jeśli przeprowadzałeś już testy wydajności, to prawdopodobnie jest to przestarzałe. Jeśli jesteś nowy w tej praktyce, przejdę przez proces, który stosuję, aby pomóc Ci zacząć. Zdaj sobie sprawę, że istnieje wiele sposobów uzyskania odpowiedzi na pytanie „Która metoda jest lepsza?” Spodziewam się, że podejmiesz ten proces, dostosujesz go i z czasem uczynisz go swoim.
Co próbujesz udowodnić?
Pierwszym krokiem jest określenie, co dokładnie testujesz. W naszym przypadku jest to proste:czy szybciej załadować dane do pustej tabeli, a następnie dodać indeksy, czy też szybciej jest mieć indeksy w tabeli podczas ładowania danych? Ale, jeśli chcemy, możemy dodać tutaj pewną odmianę. Rozważ czas potrzebny do załadowania danych do sterty, a następnie utwórz indeksy klastrowane i nieklastrowane w porównaniu z czasem potrzebnym do załadowania danych do indeksu klastrowanego, a następnie utwórz indeksy nieklastrowane. Czy jest różnica w wydajności? Czy klucz klastrowania byłby czynnikiem? Spodziewam się, że ładowanie danych spowoduje fragmentację istniejących indeksów nieklastrowanych, więc być może chcę zobaczyć, jaki wpływ ma odbudowa indeksów po obciążeniu na całkowity czas trwania. Ważne jest, aby zakres tego kroku był jak najszerszy i bardzo dokładnie określił, co chcesz mierzyć, ponieważ to określi, jakie dane przechwycisz. W naszym przykładzie nasze cztery testy będą wyglądały następująco:
Test 1: Załaduj dane do sterty, utwórz indeks klastrowy, utwórz indeksy nieklastrowe
Test 2: Załaduj dane do indeksu klastrowego, utwórz indeksy nieklastrowane
Test 3: Utwórz indeks klastrowy i indeksy nieklastrowe, załaduj dane
Test 4: Utwórz indeks klastrowy i indeksy nieklastrowe, załaduj dane, odbuduj indeksy nieklastrowe
Co musisz wiedzieć?
W naszym scenariuszu naszym podstawowym pytaniem jest „która metoda jest najszybsza”? Dlatego chcemy mierzyć czas trwania i aby to zrobić, musimy uchwycić czas rozpoczęcia i czas zakończenia. Moglibyśmy tak zostawić, ale możemy chcieć zrozumieć, jak wygląda wykorzystanie zasobów dla każdej metody, a może chcemy poznać największą liczbę czekań, liczbę transakcji lub liczbę zakleszczeń. Najbardziej interesujące i istotne dane będą zależeć od porównywanych procesów. Przechwytywanie liczby transakcji nie jest tak interesujące dla naszego obciążenia danymi; ale dla zmiany kodu może być. Ponieważ tworzymy indeksy i je przebudowujemy, interesuje mnie ile IO generuje każda metoda. Chociaż ogólny czas trwania jest prawdopodobnie decydującym czynnikiem, spojrzenie na IO może być przydatne nie tylko do zrozumienia, która opcja generuje najwięcej IO, ale także do tego, czy przechowywanie bazy danych działa zgodnie z oczekiwaniami.
Gdzie są potrzebne dane?
Po ustaleniu, jakich danych potrzebujesz, zdecyduj, skąd zostaną one przechwycone. Interesuje nas czas trwania, dlatego chcemy rejestrować czas rozpoczęcia i zakończenia każdego testu ładowania danych. Jesteśmy również zainteresowani IO i możemy pobierać te dane z wielu lokalizacji – przychodzą mi na myśl liczniki Performance Monitor i DMV sys.dm_io_virtual_file_stats.
Zrozum, że możemy uzyskać te dane ręcznie. Zanim przeprowadzimy test, możemy wybrać przeciwko sys.dm_io_virtual_file_stats i zapisać bieżące wartości do pliku. Możemy zanotować godzinę, a następnie rozpocząć test. Po zakończeniu ponownie odnotowujemy czas, ponownie odpytujemy sys.dm_io_virtual_file_stats i obliczamy różnice między wartościami, aby zmierzyć IO.
Metodologia ta ma wiele wad, a mianowicie pozostawia znaczne pole do popełnienia błędu; co jeśli zapomnisz zanotować czas rozpoczęcia lub zapomnisz przechwycić statystyki pliku przed rozpoczęciem? O wiele lepszym rozwiązaniem jest zautomatyzowanie nie tylko wykonania skryptu, ale także przechwytywania danych. Na przykład możemy utworzyć tabelę, w której znajdują się informacje o naszym teście – opis tego, czym jest test, o której godzinie się rozpoczął i o której się zakończył. Możemy zawrzeć statystyki plików w tej samej tabeli. Jeśli zbieramy inne metryki, możemy je dodać do tabeli. Lub może być łatwiej utworzyć osobną tabelę dla każdego zestawu danych, które przechwytujemy. Na przykład, jeśli przechowujemy dane statystyk plików w innej tabeli, musimy nadać każdemu testowi unikalny identyfikator, abyśmy mogli dopasować nasz test do właściwych danych statystyk plików. Przechwytując statystyki plików, musimy przechwycić wartości dla naszej bazy danych przed rozpoczęciem, a następnie po, i obliczyć różnicę. Możemy następnie przechowywać te informacje we własnej tabeli, wraz z unikalnym identyfikatorem testu.
Przykładowe ćwiczenie
Na potrzeby tego testu utworzyłem pustą kopię tabeli Sales.SalesOrderHeader o nazwie Sales.Big_SalesOrderHeader i użyłem odmiany skryptu, którego użyłem w moim poście partycjonowania, aby załadować dane do tabeli w partiach po około 25 000 wierszy. Skrypt do ładowania danych można pobrać tutaj. Uruchomiłem go cztery razy dla każdej odmiany, a także zmieniłem całkowitą liczbę wstawionych wierszy. Do pierwszego zestawu testów wstawiłem 20 milionów wierszy, a do drugiego zestawu 60 milionów wierszy. Dane dotyczące czasu trwania nie są zaskakujące:
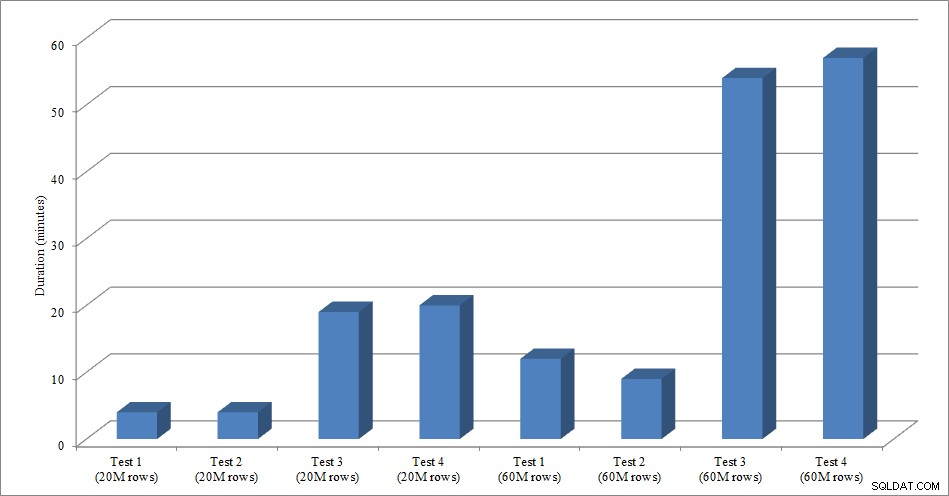
Czas ładowania danych
Ładowanie danych bez indeksów nieklastrowych jest znacznie szybsze niż ładowanie ich z już istniejącymi indeksami nieklastrowymi. Interesujące jest to, że dla obciążenia 20 milionów wierszy całkowity czas trwania był mniej więcej taki sam między testem 1 a testem 2, ale test 2 był szybszy przy ładowaniu 60 milionów wierszy. W naszym teście naszym kluczem klastrowania był SalesOrderID, który jest tożsamością i dlatego jest dobrym kluczem klastrowania dla naszego obciążenia, ponieważ rośnie. Gdybyśmy mieli klucz klastrowania, który był zamiast tego identyfikatorem GUID, czas ładowania może być dłuższy z powodu losowych wstawek i podziałów stron (kolejna odmiana, którą moglibyśmy przetestować).
Czy dane we/wy naśladują trend w danych dotyczących czasu trwania? Tak, z różnicami, gdy indeksy są już na miejscu lub nie, jeszcze bardziej przesadzone:
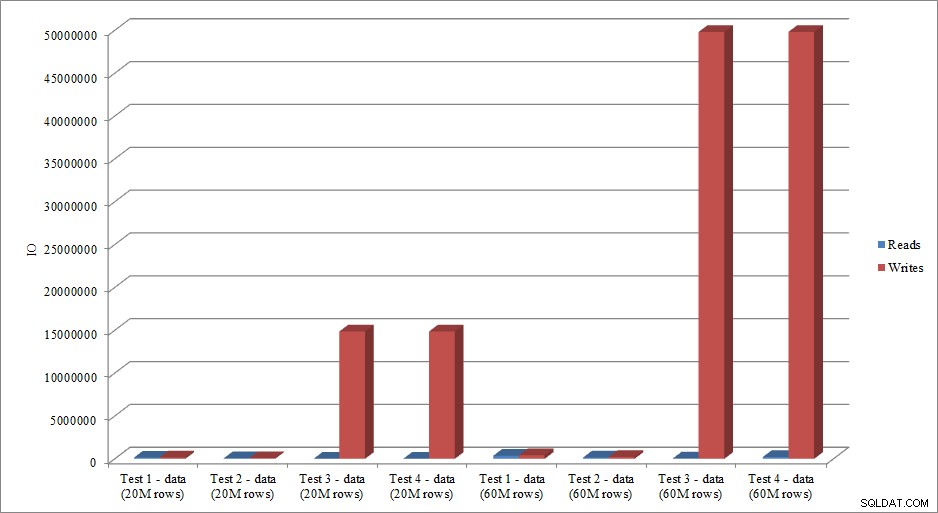
Wczytywanie i zapisywanie danych
Przedstawiona przeze mnie metoda testowania wydajności lub mierzenia zmian wydajności w oparciu o modyfikacje kodu, projektu itp. jest tylko jedną z opcji przechwytywania informacji podstawowych. W niektórych scenariuszach może to być przesada. Jeśli masz jedno zapytanie, które próbujesz dostroić, skonfigurowanie tego procesu do przechwytywania danych może zająć więcej czasu niż wprowadzenie poprawek w zapytaniu! Jeśli wykonałeś dowolną ilość dostrajania zapytań, prawdopodobnie masz zwyczaj przechwytywania danych STATISTICS IO i STATISTICS TIME wraz z planem zapytań, a następnie porównywania wyników podczas wprowadzania zmian. Robię to od lat, ale ostatnio odkryłem lepszy sposób… SQL Sentry Plan Explorer PRO. W rzeczywistości, po ukończeniu wszystkich opisanych powyżej testów obciążenia, przeszedłem i ponownie wykonałem testy przez PE i stwierdziłem, że mogę przechwycić potrzebne informacje bez konieczności konfigurowania tabel gromadzenia danych.
W Plan Explorer PRO masz możliwość uzyskania aktualnego planu – PE uruchomi zapytanie na wybranej instancji i bazie danych i zwróci plan. A wraz z nim otrzymujesz wszystkie inne świetne dane, które dostarcza PE (statystyki czasu, odczyty i zapisy, IO według tabeli), a także statystyki oczekiwania, co jest miłą korzyścią. Korzystając z naszego przykładu, zacząłem od pierwszego testu – tworzenie sterty, ładowanie danych, a następnie dodawanie indeksu klastrowego i indeksów nieklastrowanych – a następnie uruchomiłem opcję Pobierz rzeczywisty plan. Po zakończeniu zmodyfikowałem test skryptu 2, ponownie uruchomiłem opcję Pobierz aktualny plan. Powtórzyłem to dla trzeciego i czwartego testu, a kiedy skończyłem, miałem to:
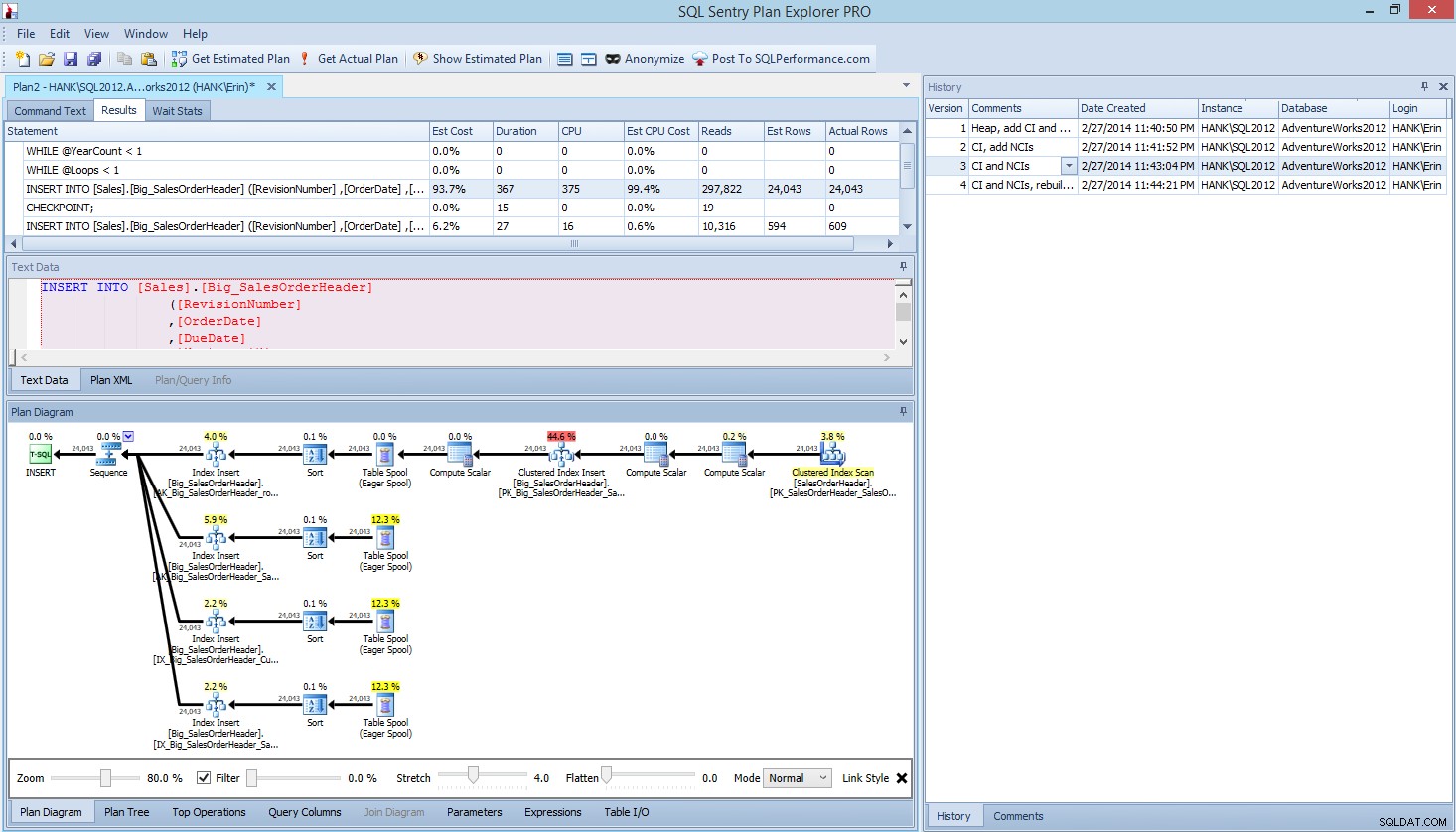
Widok Plan Explorer PRO po przeprowadzeniu 4 testów
Zwróć uwagę na okienko historii po prawej stronie? Za każdym razem, gdy modyfikowałem swój kod i odzyskiwałem rzeczywisty plan, zapisywał nowy zestaw informacji. Mam możliwość zapisania tych danych jako pliku .pesession, aby udostępnić je innemu członkowi mojego zespołu, lub wrócić później i przewijać różne testy oraz w razie potrzeby drążyć różne instrukcje w partii, przyglądając się różnym metrykom, takim jak jako czas trwania, CPU i IO. Na powyższym zrzucie ekranu podświetliłem INSERT z Testu 3, a plan zapytań pokazuje aktualizacje wszystkich czterech indeksów nieklastrowanych.
Podsumowanie
Podobnie jak w przypadku wielu zadań w programie SQL Server, istnieje wiele sposobów przechwytywania i przeglądania danych podczas wykonywania testów wydajności lub dostrajania. Im mniej ręcznego wysiłku musisz włożyć, tym lepiej, ponieważ masz więcej czasu na faktyczne wprowadzenie zmian, zrozumienie wpływu, a następnie przejście do następnego zadania. Niezależnie od tego, czy dostosujesz skrypt do przechwytywania danych, czy zlecisz to narzędzie innej firmy, opisane przeze mnie kroki są nadal ważne:
- Zdefiniuj, co chcesz poprawić
- Zakres swoich testów
- Określ, jakie dane można wykorzystać do pomiaru poprawy
- Zdecyduj, jak przechwytywać dane
- W miarę możliwości skonfiguruj zautomatyzowaną metodę testowania i przechwytywania
- Testuj, oceniaj i powtarzaj w razie potrzeby
Miłego testowania!