W moim ostatnim poście ("Koleś, kto jest właścicielem tej tabeli #temp?") zasugerowałem, że w SQL Server 2012 i nowszych możesz użyć Extended Events do monitorowania tworzenia tabel #temp. Umożliwiłoby to skorelowanie określonych obiektów zajmujących dużo miejsca w tempdb z sesją, która je utworzyła (na przykład, aby określić, czy sesja może zostać zabita w celu zwolnienia miejsca). To, czego nie omawiałem, to narzut związany z tym śledzeniem — oczekujemy, że zdarzenia rozszerzone będą lżejsze niż śledzenie, ale żadne monitorowanie nie jest całkowicie bezpłatne.
Ponieważ większość ludzi pozostawia włączone domyślne śledzenie, zostawimy to na swoim miejscu. Przetestujemy obie sterty za pomocą SELECT INTO (których domyślny ślad nie będzie zbierał) i indeksów klastrowych (co będzie), a my zmierzymy czas samej partii jako linii bazowej, a następnie ponownie uruchomimy partię z uruchomioną sesją zdarzeń rozszerzonych. Przetestujemy również zarówno SQL Server 2012, jak i SQL Server 2014. Sama partia jest dość prosta:
WŁĄCZ NR; SELECT SYSDATETIME();GO — uruchom tę część tylko dla partii sterty:SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id];DROP TABLE #foo; -- uruchom tę część tylko dla partii CIX:CREATE TABLE #bar(id INT PRIMARY KEY);INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id];DROP TABLE #bar; GO 100000 WYBIERZ SYSDATETIME();
Oba wystąpienia mają tempdb skonfigurowane z czterema plikami danych i włączonymi TF 1117 i TF 1118 w maszynie wirtualnej z czterema procesorami, 16 GB pamięci i tylko dyskiem SSD. Celowo utworzyłem małe tabele #temp, aby wzmocnić każdy zaobserwowany wpływ na samą partię (który zostałby zagłuszony, gdyby tworzenie tabel #temp zajęło dużo czasu lub spowodowało nadmierne zdarzenia autowzrostu).
Uruchomiłem te partie w każdym scenariuszu, a oto wyniki, zmierzone w czasie trwania partii w sekundach:
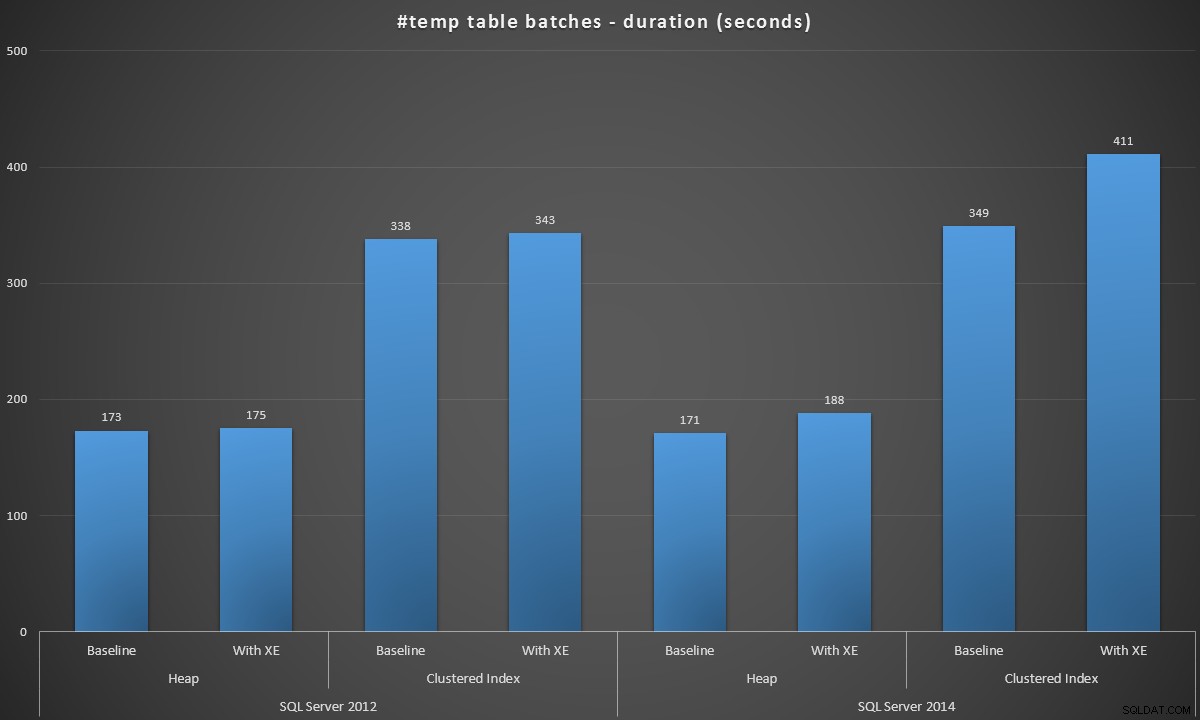
Czas utworzenia 100 000 #temp tabel w sekundach
Wyrażając dane nieco inaczej, jeśli podzielimy 100 000 przez czas trwania, możemy pokazać liczbę tabel #temp, które możemy utworzyć na sekundę w każdym scenariuszu (czytaj:przepustowość). Oto te wyniki:
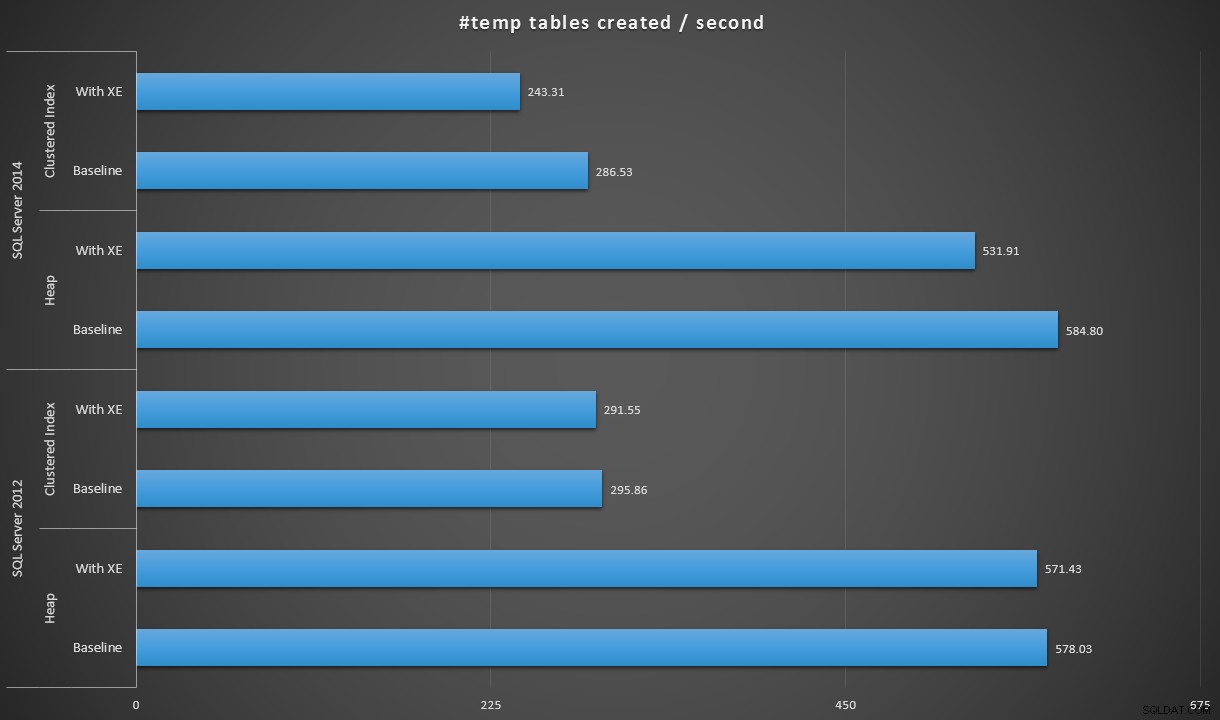
#tabele #temp tworzone na sekundę w każdym scenariuszu
Wyniki były dla mnie trochę zaskakujące – spodziewałem się, że dzięki ulepszeniom SQL Server 2014 w gorliwej logice zapisu, populacja sterty co najmniej będzie działać znacznie szybciej. Sterta w 2014 r. była o dwie sekundy marnie krótsza niż w 2012 r. w konfiguracji bazowej, ale zdarzenia rozszerzone nieco wydłużyły czas (około 10% wzrost w stosunku do linii bazowej); podczas gdy czas indeksowania klastrowego był porównywalny z 2012 r. w punkcie odniesienia, ale wzrósł o prawie 18% przy włączonych zdarzeniach rozszerzonych. W 2012 roku delty dla hałd i indeksów klastrowych były znacznie skromniejsze – odpowiednio 1,1% i 1,5%. (A żeby było jasne, podczas żadnego z testów nie wystąpiły żadne zdarzenia autogrowne).
Pomyślałem więc, co jeśli utworzę szczuplejszą, bardziej wredną sesję Extended Events? Z pewnością mógłbym usunąć niektóre z tych kolumn akcji - może potrzebuję tylko nazwy logowania i spid, a mogę zignorować nazwę aplikacji, nazwę hosta i potencjalnie kosztowny sql_text. Być może mógłbym usunąć dodatkowy filtr przeciwko zatwierdzeniu (zbierając dwa razy więcej zdarzeń, ale mniej procesora zużywanego na filtrowanie) i pozwolić na utratę wielu zdarzeń, aby zmniejszyć potencjalny wpływ na obciążenie. Ta szczuplejsza sesja wygląda tak:
UTWÓRZ SESJĘ ZDARZENIA [TempTableCreation2014_LeanerMeaner] NA SERWERZE DODAJ ZDARZENIE sqlserver.object_created(ACTION (sqlserver.server_principal_name, sqlserver.session_id ) GDZIE ( sqlserver.like_i_sql__TA). ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32768, MAX_ROLLOVER_FILES =10)Z ( EVENT_RETENTION_MODE =ALLOW_MULTIPLE_EVENT_LOSS);GOALTER EVENT SESSION2014 =TempTableCreation>;Niestety nie, te same wyniki. Nieco ponad trzy minuty w przypadku stosu i niecałe siedem minut w przypadku indeksu klastrowego. Aby głębiej zagłębić się w to, gdzie spędzano dodatkowy czas, obejrzałem instancję 2014 z SQL Sentry i uruchomiłem tylko klastrowaną partię indeksu bez skonfigurowanych żadnych sesji Extended Events. Następnie ponownie uruchomiłem wsad, tym razem ze skonfigurowaną lżejszą sesją XE. Czasy partii wynosiły 5:47 (347 sekund) i 6:55 (415 sekund) – tak bardzo zgodne z poprzednią partią (ucieszyłem się, że nasz monitoring nie wpłynął na czas trwania :-)) . Sprawdziłem, że żadne zdarzenia nie zostały usunięte i ponownie, że nie wystąpiły żadne zdarzenia autogrowu.
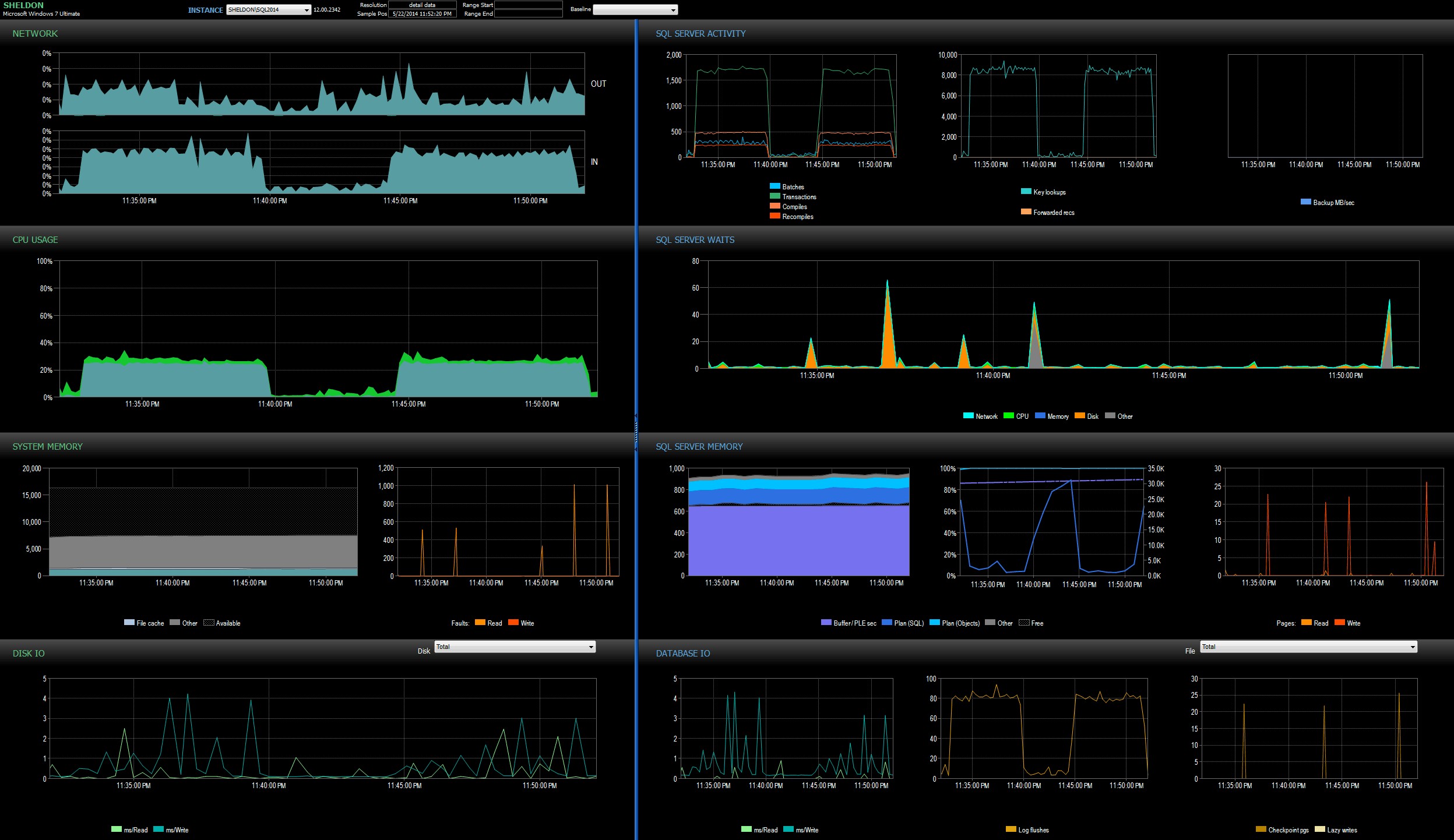
Spojrzałem na pulpit nawigacyjny SQL Sentry w trybie historii, co pozwoliło mi szybko wyświetlić metryki wydajności obu partii obok siebie:
Panel informacyjny SQL Sentry w trybie historii, pokazujący obie partieObie partie były praktycznie identyczne pod względem sieci, procesora, transakcji, kompilacji, wyszukiwania kluczy itp. Istnieje niewielka różnica w Waits – skoki podczas pierwszej partii były wyłącznie WRITELOG, podczas gdy w druga partia. Moja teoria robocza dobrze po północy jest taka, że być może duża część zaobserwowanego opóźnienia była spowodowana przełączaniem kontekstu spowodowanym przez proces zdarzeń rozszerzonych. Ponieważ nie mamy żadnego wglądu w to, co dokładnie XE robi pod okładkami, ani nie wiemy, jakie podstawowe mechanizmy zmieniły się w XE w latach 2012-2014, jest to historia, której będę się trzymać na razie, dopóki nie wygodniej z Xperf i/lub WinDbg.
Wniosek
W każdym razie oczywiste jest, że śledzenie tworzenia tabeli #temp nie jest bezpłatne, a koszt może się różnić w zależności od typu tworzonych tabel #temp, ilości informacji gromadzonych podczas sesji XE, a nawet wersji SQL Server, którego używasz. Możesz więc przeprowadzić podobne testy do tego, co zrobiłem tutaj, i zdecydować, jak cenne jest zbieranie tych informacji w Twoim środowisku.