Ważną częścią dostrajania zapytań jest zrozumienie algorytmów, które są dostępne dla optymalizatora do obsługi różnych konstrukcji zapytań, np. filtrowania, łączenia, grupowania i agregowania, oraz sposobu ich skalowania. Ta wiedza pomaga w przygotowaniu optymalnego środowiska fizycznego dla zapytań, takich jak tworzenie odpowiednich indeksów. Pomaga również intuicyjnie wyczuć, którego algorytmu należy się spodziewać w planie w określonych okolicznościach, w oparciu o znajomość progów, w których optymalizator powinien przełączać się z jednego algorytmu na inny. Następnie, podczas dostrajania źle działających zapytań, możesz łatwiej wykryć obszary w planie zapytań, w których optymalizator mógł dokonać nieoptymalnych wyborów, na przykład z powodu niedokładnych szacunków kardynalności, i podjąć działania, aby je naprawić.
Inną ważną częścią dostrajania zapytań jest nieszablonowe myślenie — wykraczające poza algorytmy, które są dostępne dla optymalizatora podczas korzystania z oczywistych narzędzi. Bądź kreatywny. Załóżmy, że masz zapytanie, które działa źle, mimo że zorganizowałeś optymalne środowisko fizyczne. W przypadku użytych konstrukcji zapytania algorytmami dostępnymi dla optymalizatora są x, y i z, a optymalizator wybrał najlepsze z możliwych w danych okolicznościach. Mimo to zapytanie działa źle. Czy możesz sobie wyobrazić teoretyczny plan z algorytmem, który może dać znacznie lepsze zapytanie? Jeśli możesz to sobie wyobrazić, są szanse, że będziesz w stanie to osiągnąć za pomocą przepisania zapytania, być może z mniej oczywistymi konstrukcjami zapytań dla zadania.
W tej serii artykułów skupiam się na grupowaniu i agregowaniu danych. Zacznę od omówienia algorytmów, które są dostępne dla optymalizatora podczas korzystania z zapytań zgrupowanych. Następnie opiszę scenariusze, w których żaden z istniejących algorytmów nie działa dobrze i pokażę przepisywanie zapytań, które skutkuje doskonałą wydajnością i skalowaniem.
Chciałbym podziękować Craigowi Freedmanowi, Vassilisowi Papadimosowi i Joe Sackowi, członkom grupy najmądrzejszych ludzi na świecie i programistom SQL Server, za odpowiedzi na moje pytania dotyczące optymalizacji zapytań!
Dla przykładowych danych użyję bazy danych o nazwie PerformanceV3. Tutaj możesz pobrać skrypt do tworzenia i wypełniania bazy danych. Użyję tabeli o nazwie dbo.Orders, która zawiera 1 000 000 wierszy. Ta tabela zawiera kilka indeksów, które nie są potrzebne i mogą kolidować z moimi przykładami, więc uruchom następujący kod, aby usunąć te niepotrzebne indeksy:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Jedyne dwa indeksy pozostałe w tej tabeli to indeks klastrowy o nazwie idx_cl_od w kolumnie orderdate oraz nieklastrowany unikalny indeks o nazwie PK_Orders w kolumnie orderid, wymuszający ograniczenie klucza podstawowego.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Istniejące algorytmy
SQL Server obsługuje dwa główne algorytmy agregowania danych:Stream Aggregate i Hash Aggregate. W przypadku zapytań zgrupowanych algorytm Stream Aggregate wymaga uporządkowania danych według zgrupowanych kolumn, dlatego należy rozróżnić dwa przypadki. Jednym z nich jest wstępnie uporządkowany Stream Aggregate, np. gdy dane są uzyskiwane w przedsprzedaży z indeksu. Innym jest agregacja strumienia nie zamówiona w przedsprzedaży, w której do jawnego sortowania danych wejściowych wymagany jest dodatkowy krok. Te dwa przypadki skalują się bardzo różnie, więc równie dobrze można je uznać za dwa różne algorytmy.
Algorytm Hash Aggregate organizuje grupy i ich agregaty w tablicy mieszającej. Nie wymaga zamawiania danych wejściowych.
Przy wystarczającej ilości danych optymalizator rozważa zrównoleglenie pracy, stosując tak zwaną agregację lokalno-globalną. W takim przypadku dane wejściowe są dzielone na wiele wątków, a każdy wątek stosuje jeden z wyżej wymienionych algorytmów, aby lokalnie agregować swój podzbiór wierszy. Agregat globalny używa następnie jednego z wyżej wymienionych algorytmów do agregowania wyników agregatów lokalnych.
W tym artykule skupię się na zamówionym w przedsprzedaży algorytmie Stream Aggregate i jego skalowaniu. W kolejnych częściach tej serii omówię inne algorytmy i opiszę progi, w których optymalizator przełącza się między sobą oraz kiedy należy rozważyć przepisanie zapytania.
Zamówiona w przedsprzedaży agregacja strumienia
Biorąc pod uwagę zgrupowane zapytanie z niepustym zestawem grupowania (zestawem wyrażeń, według którego grupujesz), algorytm Stream Aggregate wymaga uporządkowania wierszy wejściowych według wyrażeń tworzących zestaw grupowania. Gdy algorytm przetwarza pierwszy wiersz w grupie, inicjuje element członkowski przechowujący pośrednią wartość agregacji z odpowiednią wartością (np. wartość pierwszego wiersza dla agregacji MAX). Gdy przetwarza niepierwszy wiersz w grupie, przypisuje temu członkowi wynik obliczeń obejmujący pośrednią wartość zagregowaną i wartość nowego wiersza (np. maksimum między pośrednią wartością zagregowaną a nową wartością). Gdy tylko którykolwiek z elementów zestawu grupującego zmieni swoją wartość lub dane wejściowe zostaną zużyte, aktualna wartość zbiorcza jest uważana za ostateczny wynik dla ostatniej grupy.
Jednym ze sposobów uporządkowania danych, tak jak wymaga tego algorytm Stream Aggregate, jest uzyskanie ich w kolejności wstępnej z indeksu. Potrzebujesz, aby indeks był zdefiniowany z kolumnami zestawu grupującego jako kluczami — w dowolnej kolejności wśród nich. Chcesz również, aby indeks obejmował. Rozważmy na przykład następujące zapytanie (nazwiemy je Zapytanie 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Optymalnym indeksem magazynu wierszy do obsługi tego zapytania byłby indeks zdefiniowany z wiodącą kolumną klucza i datą zamówienia jako uwzględnioną kolumną lub drugą kolumną klucza:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Mając ten indeks, otrzymasz szacunkowy plan pokazany na rysunku 1 (przy użyciu SentryOne Plan Explorer).

Rysunek 1:Plan dla zapytania 1
Zwróć uwagę, że operator skanowania indeksu ma właściwość Ordered:True oznaczającą, że wymagane jest dostarczenie wierszy uporządkowanych według klucza indeksu. Operator Stream Aggregate następnie pozyskuje wiersze uporządkowane zgodnie z potrzebami. Jeśli chodzi o sposób obliczania kosztów operatora; zanim do tego dojdziemy, najpierw krótka przedmowa…
Jak już zapewne wiesz, gdy SQL Server optymalizuje zapytanie, ocenia wiele planów kandydujących i ostatecznie wybiera ten o najniższym szacowanym koszcie. Szacunkowy koszt planu to suma wszystkich szacunkowych kosztów operatorów. Z kolei szacowany koszt każdego operatora to suma szacowanego kosztu we/wy i szacowanego kosztu procesora. Jednostka kosztów sama w sobie nie ma znaczenia. Jego znaczenie polega na porównaniu, jakie optymalizator przeprowadza między planami kandydatów. Oznacza to, że formuły kosztów zostały zaprojektowane w taki sposób, aby między planami kandydata ten o najniższym koszcie (miejmy nadzieję) reprezentował ten, który zakończy się szybciej. Strasznie złożone zadanie do dokładnego wykonania!
Im bardziej formuły kosztów adekwatnie uwzględniają czynniki, które naprawdę wpływają na wydajność i skalowanie algorytmu, tym są one dokładniejsze i tym bardziej prawdopodobne, że przy dokładnych szacunkach kardynalności optymalizator wybierze optymalny plan. W każdym razie, jeśli chcesz zrozumieć, dlaczego optymalizator wybiera jeden algorytm zamiast drugiego, musisz zrozumieć dwie główne rzeczy:jedną jest sposób działania i skalowania algorytmów, a drugą model kosztów SQL Server.
Wróćmy więc do planu na rysunku 1; spróbujmy zrozumieć, jak obliczane są koszty. Zgodnie z polityką firma Microsoft nie będzie ujawniać stosowanych przez siebie wewnętrznych formuł kalkulacji kosztów. Kiedy byłem dzieckiem, fascynowało mnie rozbieranie rzeczy na części. Zegarki, radia, kasety magnetofonowe (tak, jestem tak stary), co tylko chcesz. Chciałem wiedzieć, jak powstają rzeczy. Podobnie widzę wartość w inżynierii odwrotnej formuł, ponieważ jeśli uda mi się dość dokładnie przewidzieć koszt, to prawdopodobnie oznacza to, że dobrze rozumiem algorytm. Podczas tego procesu wiele się nauczysz.
Nasze zapytanie przetwarza 1 000 000 wierszy. Nawet przy takiej liczbie wierszy koszt we/wy wydaje się być znikomy w porównaniu z kosztem procesora, więc prawdopodobnie można go zignorować.
Jeśli chodzi o koszt procesora, chcesz spróbować dowiedzieć się, jakie czynniki na niego wpływają iw jaki sposób. Teoretycznie może być wiele czynników:liczba wierszy wejściowych, liczba grup, liczność zbioru grupującego, typ danych i wielkość elementów zbioru grupującego. Tak więc, aby spróbować zmierzyć wpływ dowolnego z tych czynników, chcesz porównać szacunkowe koszty dwóch zapytań, które różnią się tylko czynnikiem, który chcesz zmierzyć. Na przykład, aby zmierzyć wpływ liczby wierszy na koszt, użyj dwóch zapytań z różną liczbą wierszy wejściowych, ale ze wszystkimi innymi aspektami takimi samymi (liczba grup, liczność zbioru grupującego itp.). Ponadto ważne jest, aby zweryfikować, czy liczby szacunkowe — a nie rzeczywiste — są wartościami pożądanymi, ponieważ optymalizator polega na liczbach szacunkowych przy obliczaniu kosztów.
Dokonując takich porównań dobrze jest mieć techniki, które pozwalają w pełni kontrolować szacowane liczby. Na przykład prostym sposobem kontrolowania szacowanej liczby wierszy wejściowych jest wykonanie zapytania do wyrażenia tabelowego opartego na zapytaniu TOP i zastosowanie funkcji agregującej w zapytaniu zewnętrznym. Jeśli obawiasz się, że ze względu na użycie operatora TOP optymalizator zastosuje cele wierszowe i że spowodują one korektę kosztów pierwotnych, dotyczy to tylko operatorów, którzy pojawiają się w planie poniżej operatora Top (do po prawej), nie powyżej (po lewej). Operator Stream Aggregate naturalnie pojawia się nad operatorem Top w planie, ponieważ pozyskuje przefiltrowane wiersze.
Jeśli chodzi o kontrolowanie szacowanej liczby grup wyjściowych, możesz to zrobić za pomocą wyrażenia grupującego
Aby upewnić się, że otrzymasz algorytm Stream Aggregate i plan szeregowy, możesz wymusić to za pomocą wskazówek dotyczących zapytania:OPTION(ORDER GROUP, MAXDOP 1).
Chcesz również dowiedzieć się, czy operator ponosi jakiekolwiek koszty początkowe, aby uwzględnić je w swojej formule inżynierii odwrotnej.
Zacznijmy od ustalenia, w jaki sposób liczba wierszy wejściowych wpływa na szacowany koszt procesora przez operatora. Oczywiście czynnik ten powinien mieć znaczenie dla kosztów operatora. Można też oczekiwać, że koszt na wiersz będzie stały. Oto kilka zapytań do porównania, które różnią się tylko szacowaną liczbą wierszy wejściowych (nazwij je odpowiednio Zapytaniem 2 i Zapytaniem 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Rysunek 2 przedstawia odpowiednie części szacunkowych planów dla tych zapytań:

Rysunek 2:Plany dla zapytania 2 i zapytania 3
Zakładając, że koszt na wiersz jest stały, można go obliczyć jako różnicę między kosztami operatora podzieloną przez różnicę między licznościami wprowadzonymi przez operatora:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Aby sprawdzić, czy otrzymana liczba jest rzeczywiście stała i poprawna, możesz spróbować przewidzieć szacunkowe koszty w zapytaniach z inną liczbą wierszy wejściowych. Na przykład przewidywany koszt z 500 000 wierszy wejściowych to:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Użyj następującego zapytania, aby sprawdzić, czy Twoja prognoza jest trafna (nazwij ją Zapytanie 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Odpowiednia część planu dla tego zapytania jest pokazana na rysunku 3.
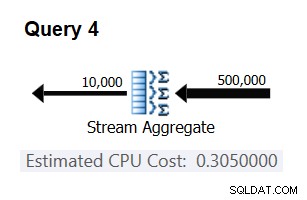
Rysunek 3:Plan dla zapytania 4
Bingo. Oczywiście dobrym pomysłem jest sprawdzenie wielu dodatkowych kardynałów danych wejściowych. Ze wszystkimi, które sprawdziłem, teza, że istnieje stały koszt na wiersz wejściowy wynoszący 0,0000006, była poprawna.
Następnie spróbujmy dowiedzieć się, w jaki sposób szacowana liczba grup wpływa na koszt procesora operatora. Można by się spodziewać, że do przetworzenia każdej grupy będzie potrzebna trochę pracy procesora, a także rozsądne jest oczekiwanie, że będzie ona stała dla każdej grupy. Aby przetestować tę tezę i obliczyć koszt na grupę, możesz użyć następujących dwóch zapytań, które różnią się tylko liczbą grup wyników (nazwij je odpowiednio Zapytaniem 5 i Zapytaniem 6):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Odpowiednie części szacunkowych planów zapytań pokazano na rysunku 4.
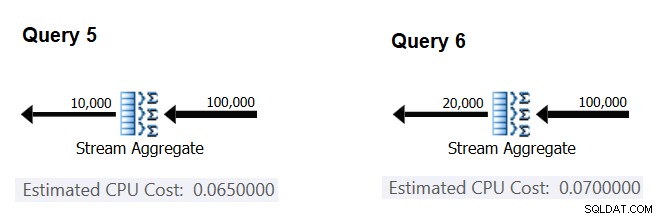
Rysunek 4:Plany dla zapytania 5 i zapytania 6
Podobnie jak w przypadku obliczania kosztu stałego na wiersz wejściowy, możesz obliczyć koszt stały na grupę wyników jako różnicę między kosztami operatora podzieloną przez różnicę między licznościami wyjściowymi operatora:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
I tak jak zademonstrowałem wcześniej, możesz zweryfikować swoje odkrycia, przewidując koszty z innymi liczbami grup wyników i porównując przewidywane liczby z tymi wygenerowanymi przez optymalizator. Przy całej liczbie grup, które wypróbowałem, przewidywane koszty były dokładne.
Korzystając z podobnych technik, możesz sprawdzić, czy inne czynniki wpływają na koszt operatora. Moje testy pokazują, że liczność zbioru grupowania (liczba wyrażeń, według których grupujesz), typy danych i rozmiary zgrupowanych wyrażeń nie mają wpływu na szacowany koszt.
Pozostało tylko sprawdzić, czy zakładany jest jakiś znaczący koszt uruchomienia dla operatora. Jeśli taki istnieje, pełna (miejmy nadzieję) formuła obliczania kosztu procesora operatora powinna wyglądać następująco:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Możesz więc obliczyć koszt uruchomienia od reszty:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
W tym celu możesz użyć dowolnego planu zapytań z tego artykułu. Na przykład, używając liczb z planu dla Zapytania 5 pokazanego wcześniej na Rysunku 4, otrzymasz:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Jak się wydaje, operator Stream Aggregate nie ma żadnych kosztów uruchomienia związanych z procesorem lub jest tak niski, że nie jest pokazywany z dokładnością pomiaru kosztów.
Podsumowując, formuła inżynierii odwrotnej dla kosztu operatora Stream Aggregate to:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Rysunek 5 przedstawia skalowanie kosztu operatora Stream Aggregate w odniesieniu zarówno do liczby wierszy, jak i liczby grup.
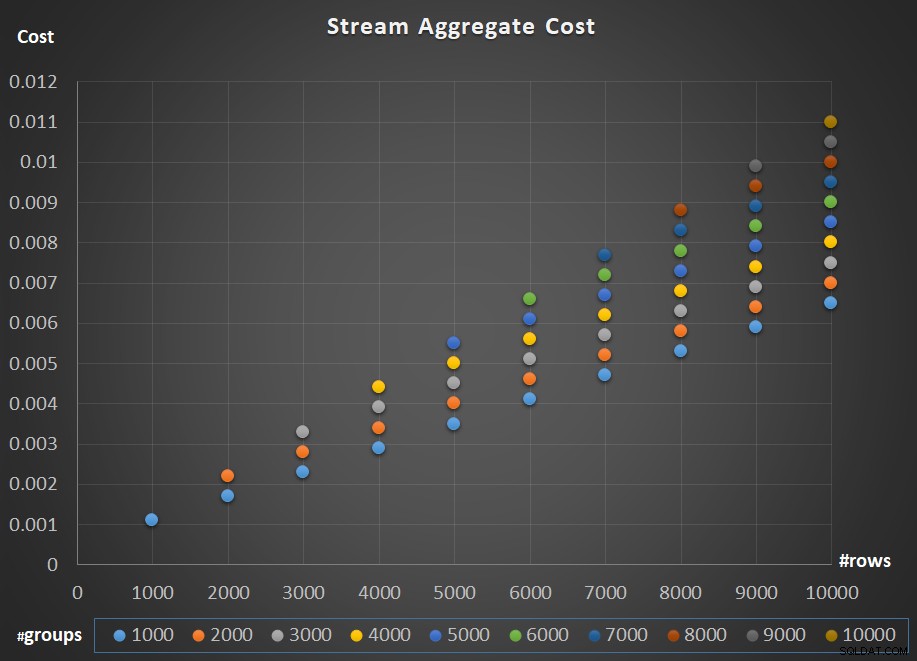
Rysunek 5:Wykres skalowania algorytmu Stream Aggregate
Jeśli chodzi o skalowanie operatora; to jest liniowe. W przypadkach, w których liczba grup jest proporcjonalna do liczby wierszy, całkowity koszt operatora wzrasta o taki sam współczynnik, jak liczba wierszy i grup. Oznacza to, że podwojenie liczby zarówno wierszy wejściowych, jak i grup wejściowych powoduje podwojenie całego kosztu operatora. Aby zobaczyć dlaczego, załóżmy, że przedstawiamy koszt operatora jako:
r * 0.0000006 + g * 0.0000005
Jeśli zwiększysz zarówno liczbę wierszy, jak i liczbę grup o ten sam współczynnik p, otrzymasz:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Jeśli więc dla danej liczby wierszy i grup koszt operatora Stream Aggregate wynosi C, zwiększenie liczby wierszy i grup o ten sam współczynnik p skutkuje kosztem operatora pC. Sprawdź, czy możesz to zweryfikować, identyfikując przykłady na wykresie na rysunku 5.
W przypadkach, w których liczba grup pozostaje dość stabilna, nawet gdy liczba wierszy wejściowych rośnie, nadal otrzymujesz skalowanie liniowe. Po prostu bierzesz pod uwagę koszt związany z liczbą grup jako stałą. Oznacza to, że jeśli dla danej liczby wierszy i grup koszt operatora wynosi C =G (koszt związany z liczbą grup) plus R (koszt związany z liczbą wierszy), zwiększając tylko liczbę wierszy o czynnik równy p daje w wyniku G + pR. W takim przypadku oczywiście cały koszt operatora jest mniejszy niż PC. Oznacza to, że podwojenie liczby wierszy powoduje mniej niż podwojenie całego kosztu operatora.
W praktyce w wielu przypadkach podczas grupowania danych liczba wierszy wejściowych jest znacznie większa niż liczba grup wyjściowych. Ten fakt, w połączeniu z faktem, że alokowany koszt na wiersz i koszt na grupę są prawie takie same, część kosztów operatora, która jest przypisana do liczby grup, staje się nieistotna. Jako przykład spójrz na plan dla Zapytania 1, pokazany wcześniej na Rysunku 1. W takich przypadkach można spokojnie pomyśleć, że koszt operatora jest po prostu skalowany liniowo w odniesieniu do liczby wierszy wejściowych.
Przypadki specjalne
Istnieją szczególne przypadki, w których operator Stream Aggregate w ogóle nie potrzebuje sortowania danych. Jeśli się nad tym zastanowisz, algorytm Stream Aggregate ma bardziej zrelaksowany wymóg porządkowania danych wejściowych w porównaniu z sytuacją, w której potrzebne są dane uporządkowane do celów prezentacji, np. gdy zapytanie ma klauzulę ORDER BY zewnętrznej prezentacji. Algorytm Stream Aggregate wymaga po prostu uporządkowania wszystkich wierszy z tej samej grupy. Weź zbiór wejściowy {5, 1, 5, 2, 1, 2}. Dla celów porządkowania prezentacji ten zestaw musi być uporządkowany w następujący sposób:1, 1, 2, 2, 5, 5. Dla celów agregacji algorytm Stream Aggregate nadal działałby dobrze, gdyby dane były ułożone w następującej kolejności:5, 5, 1, 1, 2, 2. Mając to na uwadze, gdy obliczasz agregację skalarną (zapytanie z funkcją agregującą i bez klauzuli GROUP BY) lub grupujesz dane według pustego zestawu grupującego, nigdy nie ma więcej niż jednej grupy . Niezależnie od kolejności wierszy wejściowych można zastosować algorytm Stream Aggregate. Algorytm Hash Aggregate haszuje dane na podstawie wyrażeń zbioru grupującego jako danych wejściowych i zarówno w przypadku agregatów skalarnych, jak i pustego zbioru grupowania, nie ma danych wejściowych do mieszania. Tak więc zarówno w przypadku agregacji skalarnych, jak i agregacji zastosowanych do pustego zestawu grupowania, optymalizator zawsze używa algorytmu Stream Aggregate, bez konieczności wcześniejszego zamawiania danych. Tak jest przynajmniej w trybie wykonywania wierszy, ponieważ obecnie (od SQL Server 2017 CU4) tryb wsadowy jest dostępny tylko z algorytmem Hash Aggregate. Użyję następujących dwóch zapytań, aby to zademonstrować (nazwijmy je Zapytanie 7 i Zapytanie 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Plany dla tych zapytań pokazano na rysunku 6.
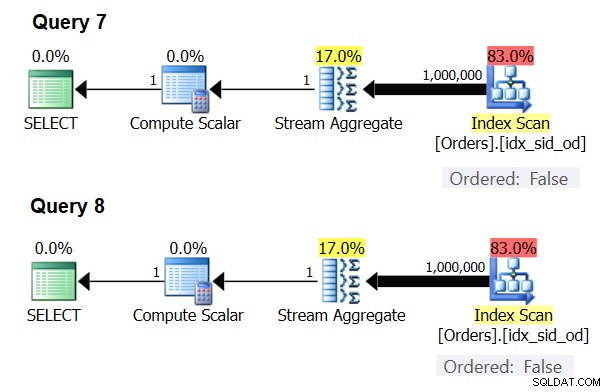
Rysunek 6:Plany dla zapytania 7 i zapytania 8
Spróbuj wymusić algorytm Hash Aggregate w obu przypadkach:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Optymalizator ignoruje Twoje żądanie i tworzy takie same plany, jak pokazano na rysunku 6.
Szybki quiz:jaka jest różnica między agregatem skalarnym a agregatem zastosowanym do pustego zbioru grupowania?
Odpowiedź:przy pustym zbiorze wejściowym agregacja skalarna zwraca wynik z jednym wierszem, podczas gdy agregacja w zapytaniu z pustym zbiorem grupowania zwraca pusty zbiór wyników. Wypróbuj:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Kiedy skończysz, uruchom następujący kod w celu oczyszczenia:
DROP INDEX idx_sid_od ON dbo.Orders;
Podsumowanie i wyzwanie
Inżynieria odwrotna wzoru kosztów dla algorytmu Stream Aggregate jest dziecinnie prosta. Mogłem po prostu powiedzieć, że wzór kosztowy dla zamówionego w przedsprzedaży algorytmu Stream Aggregate to @numrows * 0,0000006 + @numgroups * 0,0000005 zamiast całego artykułu wyjaśniającego, jak to rozgryźć. Chodziło jednak o opisanie procesu i zasad inżynierii odwrotnej, zanim przejdziemy do bardziej złożonych algorytmów i progów, w których jeden algorytm staje się bardziej optymalny od innych. Uczyć cię, jak łowić ryby, zamiast dawać ci coś w rodzaju ryb. Wiele się nauczyłem i odkryłem rzeczy, o których nawet nie pomyślałem, próbując odtworzyć formuły kosztów dla różnych algorytmów.
Gotowy do sprawdzenia swoich umiejętności? Twoja misja, jeśli zdecydujesz się ją zaakceptować, jest oczko trudniejsza niż inżynieria wsteczna operatora Stream Aggregate. Odtwórz formułę kosztorysową szeregowego operatora sortowania. Jest to ważne dla naszych badań, ponieważ algorytm Stream Aggregate zastosowany do zapytania z niepustym zestawem grupowania, w którym dane wejściowe nie są ułożone w kolejności wstępnej, wymaga jawnego sortowania. W takim przypadku koszt i skalowanie operacji agregacji zależy od kosztu i skalowania połączonych operatorów Sort i Stream Aggregate.
Jeśli uda ci się przyzwoicie zbliżyć do przewidywania kosztów operatora sortowania, możesz poczuć, że zasłużyłeś na prawo do dodania do podpisu „Inżyniera odwrotnego”. Jest wielu inżynierów oprogramowania; ale z pewnością nie widzisz wielu inżynierów odwrotnych! Tylko upewnij się, że testujesz swoją formułę zarówno z małymi, jak i dużymi liczbami; możesz być zaskoczony tym, co znajdziesz.