W kwietniu pisałem o kilku natywnych metodach w SQL Server, które mogą być używane do śledzenia automatycznych aktualizacji statystyk. Trzy opcje, które podałem, to śledzenie SQL, zdarzenia rozszerzone i migawki sys.dm_db_stats_properties. Chociaż te trzy opcje są nadal opłacalne (nawet w SQL Server 2014, chociaż moją najlepszą rekomendacją jest nadal XE), dodatkową opcją, którą zauważyłem podczas ostatnich testów, jest SQL Sentry Plan Explorer.
Wielu z was używa Eksploratora planów po prostu do czytania planów wykonywania, co jest świetne. Ma wiele zalet w porównaniu z Management Studio, jeśli chodzi o przeglądanie planów – od drobiazgów, takich jak możliwość sortowania według najlepszych operatorów i łatwego przeglądania problemów z szacowaniem kardynalności, po większe korzyści, takie jak obsługa złożonych i dużych planów oraz możliwość wyboru jednego oświadczenie w partii, aby ułatwić przegląd planu. Ale za wizualizacjami, które ułatwiają analizowanie planów, Plan Explorer oferuje również możliwość wykonania zapytania i wyświetlenia rzeczywistego planu (zamiast uruchamiania go w Management Studio i zapisywania go). Co więcej, kiedy uruchamiasz plan z PE, są przechwytywane dodatkowe informacje, które mogą być przydatne.
Zacznijmy od demonstracji, której użyłem w moim ostatnim poście, Jak automatyczne aktualizacje statystyk mogą wpływać na wydajność zapytań. Zacząłem od bazy danych AdventureWorks2012 i stworzyłem kopię tabeli SalesOrderHeader z ponad 200 milionami wierszy. Tabela ma indeks klastrowy na SalesOrderID i indeks nieklastrowany na CustomerID, OrderDate, SubTotal. [Ponownie:jeśli zamierzasz robić powtarzające się testy, zrób kopię zapasową tej bazy danych w tym momencie, aby zaoszczędzić sobie trochę czasu.] Najpierw zweryfikowałem obecną liczbę wierszy w tabeli i liczbę wierszy, które będą musiały się zmienić aby wywołać automatyczną aktualizację:
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Big_SalesOrderHeader CIX i informacje NCI
Zweryfikowałem również aktualny nagłówek statystyk indeksu:
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

Statystyki NCI:na początku
Procedura składowana, której używam do testowania, została już utworzona, ale dla kompletności kod znajduje się poniżej:
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END Wcześniej albo uruchomiłem sesję Trace lub Extended Events, albo ustawiłem moją metodę na migawkę sys.dm_db_stats_properties do tabeli. W tym przykładzie po prostu kilka razy uruchomiłem powyższą procedurę składowaną:
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
Następnie sprawdziłem pamięć podręczną procedur, aby zweryfikować liczbę wykonań, a także zweryfikowałem plan, który został zapisany w pamięci podręcznej:
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

Informacje o pamięci podręcznej planu dla SP:na początku
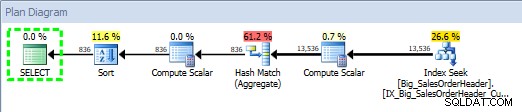
Plan zapytań dla procedury składowanej przy użyciu Eksploratora planów SQL Sentry
Plan powstał 29.09.2014 23:23.01.
Następnie dodałem do tabeli 61 milionów wierszy, aby unieważnić aktualne statystyki, a po zakończeniu wstawiania sprawdziłem liczbę wierszy:

Big_SalesOrderHeader Informacje CIX i NCI:Po wstawieniu 61 mln wiersze
Przed ponownym uruchomieniem procedury składowanej sprawdziłem, że liczba wykonań nie uległa zmianie, że czas_tworzenia nadal wynosił 2014-09-29 23:23.01 dla planu, a statystyki nie zostały zaktualizowane:
Informacje o pamięci podręcznej planu dla SP:natychmiast po wstawieniu

Statystyki NCI:po wstawieniu
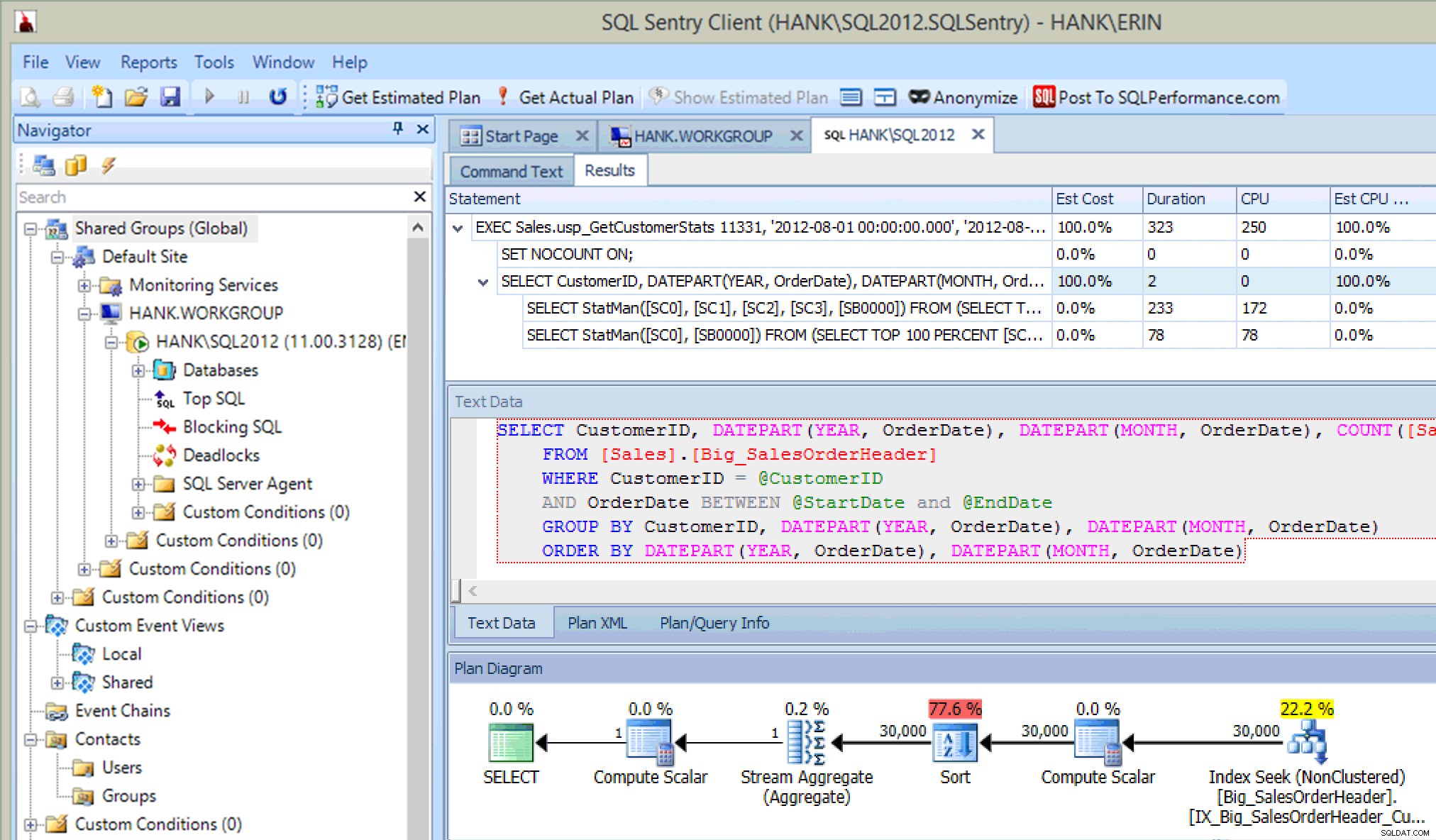
Teraz, w poprzednim poście na blogu, uruchomiłem oświadczenie w Management Studio, ale tym razem uruchomiłem zapytanie bezpośrednio z Eksploratora planów i przechwyciłem rzeczywisty plan przez PE (opcja zakreślona na czerwono na poniższym obrazku).
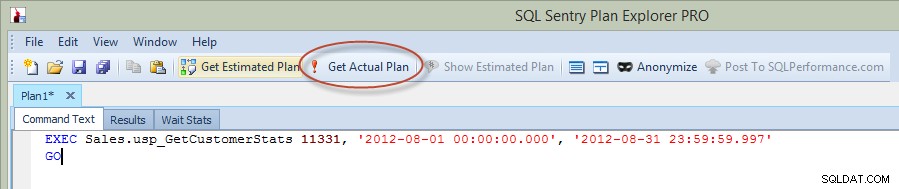
Wykonywanie procedury przechowywanej w Eksploratorze planów
Gdy wykonujesz instrukcję z PE, musisz wprowadzić instancję i bazę danych, z którą chcesz się połączyć, a następnie zostaniesz powiadomiony, że zapytanie zostanie uruchomione i zostanie zwrócony rzeczywisty plan, ale wyniki nie zostaną zwrócone. Zwróć uwagę, że jest to coś innego niż Management Studio, w którym widzisz wyniki.
Po uruchomieniu procedury składowanej w wyniku nie tylko otrzymuję plan, ale widzę, jakie instrukcje zostały wykonane:
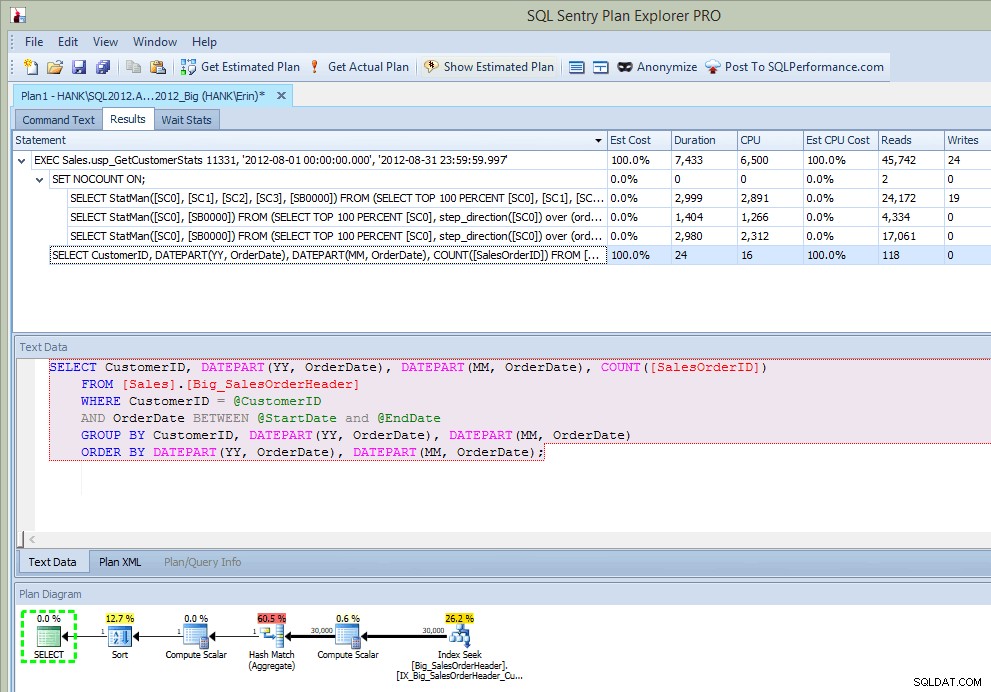
Wyniki programu Plan Explorer po wykonaniu SP (po wstawieniu)
To jest całkiem fajne… oprócz tego, że widzę instrukcję wykonywaną w procedurze składowanej, widzę również aktualizacje statystyk, tak jak robiłem to, gdy przechwyciłem aktualizacje za pomocą rozszerzonych zdarzeń lub śledzenia SQL. Wraz z wykonaniem instrukcji możemy również zobaczyć informacje o procesorze, czasie trwania i we/wy. Teraz – zastrzeżenie polega na tym, że widzę te informacje jeśli Uruchamiam oświadczenie, które wywołuje aktualizację statystyk z programu Plan Explorer. To prawdopodobnie nie zdarza się często w twoim środowisku produkcyjnym, ale możesz to zauważyć podczas testowania (ponieważ mam nadzieję, że twoje testowanie nie tylko obejmuje uruchamianie zapytań SELECT, ale także obejmuje zapytania INSERT/UPDATE/DELETE, tak jak robisz to zobacz w normalnym obciążeniu pracą). Jeśli jednak monitorujesz swoje środowisko za pomocą narzędzia takiego jak SQL Sentry, możesz zobaczyć te aktualizacje w Top SQL o ile przekraczają próg gromadzenia Top SQL. SQL Sentry ma domyślne progi, które zapytania muszą przekroczyć, zanim zostaną przechwycone jako Top SQL (np. czas trwania musi przekraczać pięć (5) sekund), ale możesz je zmienić i dodać inne progi, takie jak odczyty. W tym przykładzie tylko do celów testowych , zmieniłem próg minimalnego czasu trwania Top SQL na 10 milisekund, a próg odczytu na 500, a program SQL Sentry był w stanie przechwycić niektóre aktualizacje statystyk:
Aktualizacje statystyk przechwyconych przez SQL Sentry
To powiedziawszy, to, czy monitorowanie może uchwycić te zdarzenia, będzie ostatecznie zależeć od zasobów systemowych i ilości danych, które należy odczytać, aby zaktualizować statystyki. Aktualizacje statystyk nie mogą przekraczać tych progów, więc może być konieczne bardziej proaktywne wyszukiwanie, aby je znaleźć.
Podsumowanie
Zawsze zachęcam administratorów baz danych do proaktywnego zarządzania statystykami – co oznacza, że istnieje zadanie regularnego aktualizowania statystyk. Jednak nawet jeśli ta praca jest uruchamiana co noc (co niekoniecznie polecam), nadal jest całkiem możliwe, że aktualizacje statystyk następują automatycznie w ciągu dnia, ponieważ niektóre tabele są bardziej zmienne niż inne i mają dużą liczbę modyfikacji. Nie jest to nienormalne i w zależności od rozmiaru tabeli i ilości modyfikacji, automatyczne aktualizacje mogą nie zakłócać znacząco zapytań użytkowników. Ale jedynym sposobem, aby wiedzieć, jest monitorowanie tych aktualizacji – niezależnie od tego, czy korzystasz z narzędzi natywnych, czy narzędzi innych firm – dzięki czemu możesz wyprzedzić potencjalne problemy i rozwiązać je, zanim się eskalują.