Jednym z najczęstszych wąskich gardeł wydajności, które widzę jako konsultant, jest niewystarczająca wydajność podsystemu pamięci masowej. Istnieje wiele przyczyn słabej wydajności pamięci masowej, ale pomiar jej i zrozumienie, co należy mierzyć i monitorować, jest zawsze przydatnym ćwiczeniem.
W rzeczywistości istnieją trzy główne metryki, które są najważniejsze, jeśli chodzi o pomiar wydajności podsystemu we/wy:
Opóźnienie
Pierwsza metryka to opóźnienie, czyli po prostu czas potrzebny na wykonanie operacji we/wy. Jest to często nazywane czasem odpowiedzi lub czasem obsługi. Pomiar rozpoczyna się, gdy system operacyjny wysyła żądanie do dysku (lub kontrolera dysku) i kończy się, gdy dysk zakończy przetwarzanie żądania. Odczyty są zakończone, gdy system operacyjny otrzyma dane, natomiast zapisy są zakończone, gdy dysk poinformuje system operacyjny, że otrzymał dane.
W przypadku zapisów dane mogą nadal znajdować się w pamięci podręcznej DRAM na dysku lub kontrolerze dysku, w zależności od zasad buforowania i sprzętu. Buforowanie z zapisem jest znacznie szybsze niż buforowanie z zapisem, ale wymaga podtrzymania bateryjnego kontrolera dysku. W przypadku użycia programu SQL Server chcesz się upewnić, że używasz buforowania z zapisem, a nie buforowania z zapisem, jeśli to w ogóle możliwe. Chcesz również upewnić się, że pamięć podręczna dysku sprzętowego jest rzeczywiście włączona, ponieważ niektóre narzędzia do zarządzania dyskami dostawców wyłączają ją domyślnie.
Operacje wejścia/wyjścia na sekundę (IOPS)
Druga metryka to operacje wejścia/wyjścia na sekundę (IOPS). Ta metryka jest bezpośrednio związana z opóźnieniem. Na przykład stałe opóźnienie wynoszące 1 ms oznacza, że dysk może przetwarzać 1000 operacji we/wy na sekundę przy głębokości kolejki 1. W miarę dodawania większej liczby operacji we/wy do kolejki, opóźnienie będzie wzrastać. Jedną z kluczowych zalet pamięci flash jest możliwość równoległego odczytu/zapisu w wielu kanałach NAND, a także brak elektromechanicznych części ruchomych, które spowalniałyby dostęp do dysku. IOPS w rzeczywistości równa się głębokości kolejki podzielonej przez opóźnienie, a sam IOPS nie uwzględnia rozmiaru transferu dla pojedynczego transferu dysku. Możesz przełożyć IOPS na MB/s i MB/s na opóźnienie, o ile znasz głębokość kolejki i rozmiar transferu.
Przepustowość sekwencyjna
Przepustowość sekwencyjna to szybkość przesyłania danych, zwykle mierzona w megabajtach na sekundę (MB/s) lub gigabajtach na sekundę (GB/s). Metryka przepływności sekwencyjnej w MB/s jest równa liczbie IOPS pomnożonej przez rozmiar transferu. Na przykład 556 MB/s równa się 135 759 IOPS razy rozmiar transferu 4096 bajtów, a 135 759 IOPS razy rozmiar transferu 8192 bajtów to 1112 MB/s przepustowości sekwencyjnej. Pomimo swojego codziennego znaczenia dla SQL Server, sekwencyjna przepustowość dysków często ulega niewielkim zmianom w pamięci masowej przedsiębiorstwa, zarówno przez dostawców pamięci masowej, jak i administratorów pamięci masowej. Często zdarza się również, że rzeczywiste dyski magnetyczne w obudowie pamięci masowej dołączanej bezpośrednio (DAS) lub urządzeniu sieci pamięci masowej (SAN) są tak zajęte, że nie mogą zapewnić pełnej znamionowej przepustowości sekwencyjnej.
Przepustowość sekwencyjna ma kluczowe znaczenie dla wielu typowych działań serwera bazy danych, w tym tworzenia pełnych kopii zapasowych i przywracania bazy danych, tworzenia i odbudowy indeksu oraz skanowania sekwencyjnego odczytu dużych ilości danych (gdy dane nie mieszczą się w puli buforów programu SQL Server). Jednym z celów wydajności, do którego lubię strzelać w przypadku nowych kompilacji serwerów baz danych, jest uzyskanie co najmniej 1 GB/s przepustowości sekwencyjnej dla każdej litery dysku lub punktu montowania. Posiadanie tego poziomu wydajności (lub lepszej) znacznie ułatwia życie profesjonalistom ds. baz danych. Dzięki temu wiele typowych zadań związanych z bazą danych jest o wiele szybszych, a także daje swobodę częstszego dostrajania indeksów, gdy możesz utworzyć indeks na dużym stole w ciągu sekund lub minut zamiast godzin.
Metryki obciążenia we/wy SQL Server
Jeśli chodzi o wydajność SQL Server i we/wy, jest kilka rzeczy, które należy mierzyć i monitorować w miarę upływu czasu. Powinieneś znać stosunek odczytu do zapisu dla obciążenia dla wszystkich plików bazy danych użytkowników i tempdb. Proporcje będą różne dla różnych typów plików i obciążeń programu SQL Server. Możesz użyć moich zapytań diagnostycznych DMV, aby to ustalić, a także możesz użyć widoku aktywności dysku w SQL Sentry Performance Advisor, aby łatwo uzyskać pełniejszy widok aktywności dysku, od ogólnego obrazu na wysokim poziomie, aż do samego dołu do poszczególnych plików:
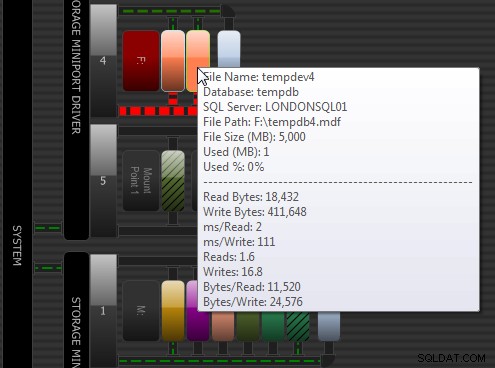 Doradca wydajności SQL Sentry:aktywność dysku
Doradca wydajności SQL Sentry:aktywność dysku
Należy również zmierzyć typowe szybkości we/wy dla IOPS i przepustowości sekwencyjnej. W Monitorze wydajności systemu Windows (PerfMon) odczyty/s i zapisy/s pokazują liczbę operacji we/wy na sekundę, podczas gdy odczyt dysków w bajtach/s i zapis na dysku w bajtach/s reprezentują przepustowość sekwencyjną. Należy użyć PerfMon do pomiaru średniej liczby sekund dysku/odczytu i średniej liczby sekund dysku/zapisu, co oznacza opóźnienie odczytu i zapisu na poziomie dysku. Wreszcie, możesz użyć moich zapytań diagnostycznych DMV, aby zmierzyć średnie opóźnienie odczytu i zapisu na poziomie plików dla wszystkich plików bazy danych użytkowników, a także dla tempdb.
Metody pomiaru wydajności we/wy
Możesz użyć sekcji Dysk w Monitorze zasobów systemu Windows, aby uzyskać szybki podgląd w czasie rzeczywistym niektórych kluczowych metryk dysku dla wszystkich plików bazy danych programu SQL Server. Idąc głębiej, możesz użyć PerfMon do mierzenia i monitorowania krytycznych liczników wydajności, o których wspomniałem wcześniej. Zanim przejdziesz do środowiska produkcyjnego z nowym serwerem bazy danych, powinieneś przeprowadzić testy porównawcze dysków, aby określić, jaką wydajność może faktycznie zapewnić Twój podsystem we/wy. W rzeczywistości nie jest to takie trudne ani czasochłonne (jeśli używasz odpowiednich narzędzi), ale często zapomina się o tym, gdy nowy serwer bazy danych jest udostępniany i testowany.
Pierwszym testem dysku, który należy zawsze uruchamiać, jest CrystalDiskMark 4.0, który został niedawno przepisany, aby używać stosunkowo nowego programu do testowania dysków Microsoft DiskSpd. Interfejs użytkownika CDM 4.0 umożliwia wybór szerszego zakresu rozmiarów plików testowych, a także pozwala wybrać głębokość kolejki i liczbę wątków dla przebiegów testowych. Pozwala to uzyskać bardziej zbliżone do serwera obciążenie we/wy, a także pozwala lepiej obciążać nowsze urządzenia pamięci flash NVMe, które mogą obsługiwać kolejki o głębokości większej niż 32.
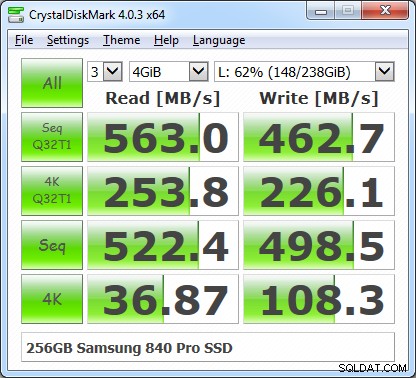 CrystalDiskMark 4.03 wyniki z QD =32 i wątkami =1
CrystalDiskMark 4.03 wyniki z QD =32 i wątkami =1
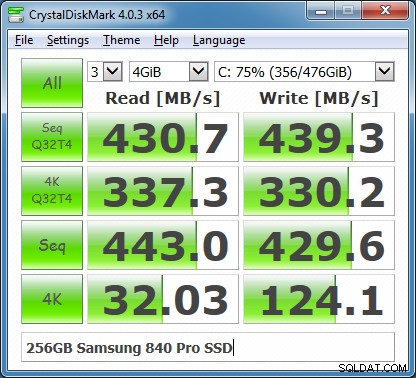 Rysunek 2:CrystalDiskMark 4.03 wyniki przy QD =32 i wątkach =4
Rysunek 2:CrystalDiskMark 4.03 wyniki przy QD =32 i wątkach =4
W przeciwieństwie do poprzednich wersji CDM, dwa najbardziej odpowiednie wiersze dotyczące użycia programu SQL Server znajdują się pośrodku wyświetlanego wyniku. Są to losowe odczyty i zapisy 4K z dużą głębokością kolejki (domyślnie 32) oraz sekwencyjne odczyty i zapisy. Po wykonaniu kilku testów porównawczych pamięci masowej za pomocą CrystalDiskMark 4.0, powinieneś przeprowadzić bardziej wyczerpujące testy za pomocą Microsoft DiskSpd. W przyszłym artykule omówię, jak używać DiskSpd do pełniejszego testowania SQL Server.