Wszystkie moje posty w tym roku dotyczyły odruchowych reakcji na statystyki oczekiwania, ale w tym poście odchodzę od tego tematu, aby porozmawiać o moim konkretnym błędzie:liczniku oczekiwanej długości życia strony (który będę nazywał PLE ).
Co oznacza PLE?
W Internecie można znaleźć wszelkiego rodzaju nieprawidłowe stwierdzenia dotyczące oczekiwanej długości życia strony, a najbardziej rażące są te, które określają, że wartość 300 jest progiem, w którym powinieneś się martwić.
Aby zrozumieć, dlaczego to stwierdzenie jest tak mylące, musisz zrozumieć, czym właściwie jest PLE.
Definicja PLE to oczekiwany czas w sekundach, przez który strona pliku danych wczytana do puli buforów (pamięć podręczna stron plików danych) pozostanie w pamięci, zanim zostanie wypchnięta z pamięci, aby zrobić miejsce na inne dane strona pliku. Innym sposobem myślenia o PLE jest natychmiastowa miara nacisku na pulę buforów, aby zwolnić miejsce na strony czytane z dysku. W przypadku obu tych definicji wyższa liczba jest lepsza.
Co to jest dobry próg PLE?
PLE 300 oznacza, że cała pula buforów jest skutecznie opróżniana i ponownie odczytywana co pięć minut. Kiedy około 2005/2006 Microsoft po raz pierwszy podał wytyczne dotyczące progu PLE wynoszące 300, liczba ta mogła mieć więcej sensu, ponieważ średnia ilość pamięci na serwerze była znacznie niższa.
W dzisiejszych czasach, gdy serwery rutynowo mają 64 GB, 128 GB i większe ilości pamięci, mniej więcej tyle danych odczytywanych z dysku co pięć minut może być przyczyną paraliżującego problemu z wydajnością
W rzeczywistości wtedy, zanim PLE osiągnie lub spadnie poniżej 300, twój serwer jest już w poważnych tarapatach. Zacząłbyś się martwić, zanim PLE będzie tak niski.
Więc jaki jest próg, którego należy użyć, kiedy powinieneś się martwić?
Cóż, o to właśnie chodzi. Nie mogę podać progu, ponieważ ta liczba będzie się różnić dla każdego. Jeśli naprawdę, naprawdę chcesz użyć numeru, mój kolega Jonathan Kehayias wymyślił formułę:
(Pamięć puli buforów w GB/4) x 300Nawet ta liczba jest nieco arbitralna, a Twój przebieg będzie się różnić.
Nie lubię polecać żadnych liczb. Moja rada jest taka, abyś mierzył swoje PLE, gdy wydajność jest na pożądanym poziomie – to jest używany próg.
Czy zaczynasz się martwić, gdy tylko PLE spadnie poniżej tego progu? Nie. Zaczynasz się martwić, gdy PLE spadnie poniżej tego progu i pozostanie poniżej tego progu lub jeśli gwałtownie spadnie i nie wiesz dlaczego.
Dzieje się tak, ponieważ istnieją pewne operacje, które spowodują upuszczenie PLE (np. uruchomienie DBCC CHECKDB lub przebudowy indeksu mogą czasami to zrobić) i nie są powodem do niepokoju. Ale jeśli zauważysz duży spadek PLE i nie wiesz, co go powoduje, właśnie wtedy powinieneś się martwić.
Być może zastanawiasz się, jak DBCC CHECKDB może spowodować spadek PLE, gdy jest nieprzychylny i bardzo stara się uniknąć opróżniania puli buforów danymi, których używa (wyjaśnienie można znaleźć w tym poście na blogu). Dzieje się tak, ponieważ przyznanie pamięci wykonania zapytania dla DBCC CHECKDB jest błędnie obliczona przez Optymalizator zapytań i może spowodować duże zmniejszenie rozmiaru puli buforów (pamięć dla grantu jest skradziona z puli buforów) i w konsekwencji spadek PLE.
Jak monitorować PLE?
To jest podchwytliwe. Większość ludzi przejdzie bezpośrednio do Buffer Manager obiektu wydajności w PerfMon i monitoruj Page life expectancy lada. Czy to właściwe podejście? Najprawdopodobniej nie.
Powiedziałbym, że znaczna większość dzisiejszych serwerów korzysta z architektury NUMA, co ma ogromny wpływ na sposób monitorowania PLE.
Gdy zaangażowana jest NUMA, pula buforów jest dzielona na węzły buforów, z jednym węzłem bufora na węzeł NUMA, który SQL Server może „zobaczyć”. Każdy węzeł bufora osobno śledzi PLE, a Buffer Manager:Page life expectancy licznik jest średnią wartości PLE węzła bufora. Jeśli monitorujesz tylko ogólną pulę buforów PLE, ciśnienie na jednym z węzłów bufora może być maskowane przez uśrednianie (omawiam to w poście na blogu tutaj).
Jeśli więc Twój serwer używa NUMA, musisz monitorować indywidualny Buffer Node:Page life expectancy liczniki (będzie jeden obiekt wydajności węzła bufora dla każdego węzła NUMA), w przeciwnym razie dobrze monitorujesz Buffer Manager:Page life expectancy licznik.
Jeszcze lepszym rozwiązaniem jest użycie narzędzia do monitorowania, takiego jak SQL Sentry Performance Advisor, które pokaże ten licznik jako część pulpitu nawigacyjnego, biorąc pod uwagę węzły NUMA na serwerze i pozwoli łatwo skonfigurować alerty.
Przykłady korzystania z Doradcy wydajności
Poniżej znajduje się przykładowy fragment zrzutu ekranu z Performance Advisor dla systemu z pojedynczym węzłem NUMA:
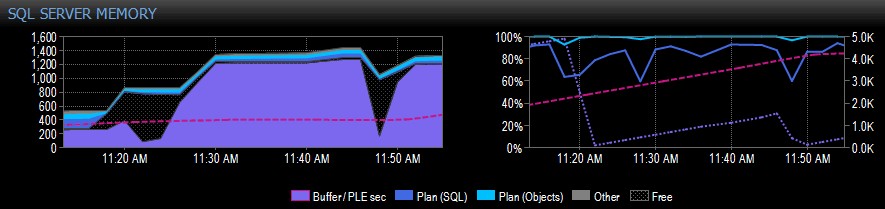
Po prawej stronie przechwycenia różowa przerywana linia to PLE między 10.30 a około 11.20 – stale rośnie do około 5000, naprawdę zdrowa liczba. Tuż przed 11:20 następuje ogromny spadek, a potem znów zaczyna się wspinać, aż do 11:45, gdzie znów spada.
Zwykle jest to widoczne, gdy pula buforów jest pełna, a wszystkie używane strony są używane, a następnie uruchamiane jest zapytanie, które powoduje odczytanie ogromnej ilości różnych danych z dysku, przesuwając większość tego, co już jest w pamięci i powodując gwałtowny spadek PLE. Jeśli nie wiesz, co spowodowało coś takiego, chciałbyś zbadać, jak opiszę poniżej.
Jako drugi przykład, zrzut ekranu poniżej pochodzi z jednego z naszych klientów Remote DBA, na którym serwer ma dwa węzły NUMA (widać, że są to dwie fioletowe linie PLE) i gdzie intensywnie korzystamy z Doradcy wydajności:

Na serwerze tego klienta, każdego ranka około 5 rano, rozpoczyna się zadanie konserwacji indeksu i sprawdzania spójności, które powoduje, że PLE spada w obu węzłach bufora. Jest to oczekiwane zachowanie, więc nie ma potrzeby sprawdzania, dopóki PLE ponownie wzrośnie w ciągu dnia.
Co możesz zrobić z porzucaniem PLE?
Jeśli przyczyna spadku PLE nie jest znana, możesz zrobić kilka rzeczy:
- Jeśli problem występuje teraz, sprawdź, które zapytania powodują odczyty, używając
sys.dm_os_waiting_tasksDMV, aby zobaczyć, które wątki czekają na odczytanie stron z dysku (tj. te, które czekają naPAGEIOLATCH_SH), a następnie napraw te zapytania. - Jeśli problem wystąpił w przeszłości, poszukaj w DMV sys.dm_exec_query_stats zapytań z dużą liczbą fizycznych odczytów lub użyj narzędzia do monitorowania, które może dostarczyć te informacje (np. widok Top SQL w Performance Advisor) oraz następnie napraw te zapytania.
- Powiąż spadek PLE z zaplanowanymi zadaniami agenta, które wykonują konserwację bazy danych.
- Poszukaj zapytań z bardzo dużymi przydziałami pamięci na wykonanie zapytań, używając
sys.dm_exec_query_memory_grantsDMV, a następnie napraw te zapytania.
Mój poprzedni post tutaj wyjaśnia więcej na temat #1 i #2, a skrypt do badania oczekiwań występujących na serwerze i link do ich planów zapytań jest tutaj.
„Napraw te zapytania” wykracza poza zakres tego postu, więc zostawię to na inny czas lub jako ćwiczenie dla czytelnika ☺
Podsumowanie
Nie wpadaj w pułapkę wiary w jakikolwiek zalecany próg PLE, który możesz przeczytać online. Najlepszym sposobem reagowania na zmiany PLE jest spadek PLE poniżej twojego poziom komfortu jest i pozostaje tam - to jest wskazanie problemu z wydajnością, który należy zbadać.
W następnym artykule z tej serii omówię kolejną częstą przyczynę gwałtownego dostrajania wydajności. Do tego czasu życzę miłego rozwiązywania problemów!