Plany wykonania stanowią bogate źródło informacji, które mogą pomóc nam zidentyfikować sposoby poprawy wydajności ważnych zapytań. Ludzie często szukają takich rzeczy, jak duże skany i wyszukiwania, jako sposób na zidentyfikowanie potencjalnych optymalizacji ścieżek dostępu do danych. Te problemy można często szybko rozwiązać, tworząc nowy indeks lub rozszerzając istniejący o więcej dołączonych kolumn.
Możemy również użyć planów powykonawczych, aby porównać rzeczywistą i oczekiwaną liczbę wierszy między operatorami planu. Tam, gdzie okaże się, że są one znacząco rozbieżne, możemy spróbować dostarczyć optymalizatorowi lepsze informacje statystyczne, aktualizując istniejące statystyki, tworząc nowe obiekty statystyczne, wykorzystując statystyki dotyczące obliczonych kolumn lub być może dzieląc złożone zapytanie na mniej złożone komponenty części.
Poza tym możemy również przyjrzeć się kosztownym operacjom w planie, szczególnie pochłaniającym pamięć, takim jak sortowanie i mieszanie. Sortowanie można czasem uniknąć poprzez zmiany w indeksowaniu. Innym razem możemy być zmuszeni do refaktoryzacji zapytania przy użyciu składni, która faworyzuje plan, który zachowuje określoną pożądaną kolejność.
Czasami wydajność nadal nie będzie wystarczająco dobra, nawet po zastosowaniu tych wszystkich technik dostrajania wydajności. Możliwym następnym krokiem jest dogłębniejsze przemyślenie planu jako całości . Oznacza to cofnięcie się o krok, próbę zrozumienia ogólnej strategii wybranej przez optymalizator zapytań, aby sprawdzić, czy możemy zidentyfikować poprawę algorytmiczną.
W tym artykule omówiono ten drugi typ analizy, używając prostego przykładowego problemu znajdowania unikalnych wartości kolumn w umiarkowanie dużym zestawie danych. Jak to często bywa w przypadku analogicznych problemów rzeczywistych, interesująca kolumna będzie miała stosunkowo niewiele unikalnych wartości w porównaniu z liczbą wierszy w tabeli. Ta analiza składa się z dwóch części:tworzenia przykładowych danych i pisania samego zapytania o odrębnych wartościach.
Tworzenie przykładowych danych
Aby podać najprostszy możliwy przykład, nasza tabela testowa ma tylko jedną kolumnę z indeksem klastrowym (ta kolumna będzie zawierać zduplikowane wartości, więc indeks nie może być zadeklarowany jako unikalny):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Aby wybrać niektóre liczby z powietrza, zdecydujemy się załadować dziesięć milionów wierszy w sumie, z równomiernym rozkładem na tysiąc odrębnych wartości . Powszechną techniką generowania takich danych jest krzyżowe łączenie niektórych tabel systemowych i zastosowanie ROW_NUMBER funkcjonować. Użyjemy również operatora modulo, aby ograniczyć generowane liczby do pożądanych odrębnych wartości:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); Szacowany plan wykonania dla tego zapytania jest następujący (kliknij obraz, aby go powiększyć, jeśli to konieczne):

Zajmuje to około 30 sekund stworzyć przykładowe dane na moim laptopie. W żadnym wypadku nie jest to ogromna ilość czasu, ale nadal warto zastanowić się, co możemy zrobić, aby ten proces był bardziej wydajny…
Analiza planu
Zaczniemy od zrozumienia, do czego służy każda operacja w planie.
Część planu wykonania po prawej stronie operatora Segmentu dotyczy wytwarzania rzędów poprzez krzyżowe łączenie tabel systemowych:

Operator segmentu występuje na wypadek, gdyby funkcja okna miała PARTITION BY klauzula. Tak nie jest w tym przypadku, ale i tak jest on obecny w planie zapytań. Operator Sequence Project generuje numery wierszy, a Top ogranicza wynik planu do dziesięciu milionów wierszy:

Skalar obliczeniowy definiuje wyrażenie, które stosuje funkcję modulo i dodaje jeden do wyniku:

Możemy zobaczyć, w jaki sposób etykiety wyrażeń Sequence Project i Compute Scalar są powiązane, korzystając z karty Wyrażenia w Eksploratorze planów:

Daje nam to pełniejsze wyczucie przebiegu tego planu:projekt Sequence numeruje wiersze i etykietuje wyrażenie Expr1050; Compute Scalar oznacza wynik obliczeń modulo i plus-one jako Expr1052 . Zwróć także uwagę na niejawną konwersję w wyrażeniu Compute Scalar. Kolumna tabeli docelowej jest typu integer, podczas gdy ROW_NUMBER funkcja generuje bigint, więc konieczna jest konwersja zawężająca.
Kolejnym operatorem w planie jest Sort. Zgodnie z szacunkami kosztów optymalizatora zapytań jest to prawdopodobnie najdroższa operacja (88,1% szacunkowo ):

Może nie być od razu oczywiste, dlaczego ten plan obejmuje sortowanie, ponieważ w zapytaniu nie ma wyraźnego wymogu porządkowania. Sort jest dodawany do planu, aby upewnić się, że wiersze docierają do operatora wstawiania indeksu klastrowego w kolejności indeksu klastrowego. Promuje to sekwencyjne zapisy, pozwala uniknąć dzielenia stron i jest jednym z warunków wstępnych minimalnego rejestrowania INSERT operacje.
To wszystko potencjalnie dobre rzeczy, ale sam Sort jest dość drogi. Rzeczywiście, sprawdzenie planu wykonania po wykonaniu ("rzeczywistego") ujawnia, że sortowaniu zabrakło również pamięci w czasie wykonania i musiało się rozlać do fizycznego tempdb dysk:

Rozlewanie sortowania występuje pomimo tego, że szacowana liczba wierszy jest dokładnie poprawna i pomimo faktu, że kwerenda otrzymała całą pamięć, o którą poprosiła (jak widać we właściwościach planu dla katalogu głównego INSERT węzeł):

Rozlania sortowania są również wskazywane przez obecność IO_COMPLETION czeka w zakładce Plan Explorer PRO wait stats:

Na koniec w tej sekcji analizy planu zwróć uwagę na DML Request Sort właściwość operatora Clustered Index Insert jest ustawiona na true:

Ta flaga wskazuje, że optymalizator wymaga, aby poddrzewo pod wstawką dostarczało wiersze w kolejności posortowanej według klucza indeksu (stąd potrzeba problematycznego operatora sortowania).
Unikanie sortowania
Teraz, gdy wiemy, dlaczego pojawia się Sort, możemy przetestować, aby zobaczyć, co się stanie, jeśli go usuniemy. Istnieją sposoby na przepisanie zapytania, aby „oszukać” optymalizator, tak aby myślał, że zostanie wstawionych mniej wierszy (więc sortowanie nie byłoby opłacalne), ale szybkim sposobem na uniknięcie bezpośredniego sortowania (tylko do celów eksperymentalnych) jest użycie nieudokumentowanej flagi śledzenia 8795. To ustawia DML Request Sort właściwość na wartość false, dzięki czemu wiersze nie muszą już docierać do wstawiania indeksu klastrowanego w kolejności kluczy klastrowych:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); Nowy plan zapytań powykonawczych wygląda następująco (kliknij obrazek, aby powiększyć):

Operator Sort zniknął, ale nowe zapytanie działa przez ponad 50 sekund (w porównaniu z 30 sekundami zanim). Istnieje kilka powodów takiego stanu rzeczy. Po pierwsze, tracimy jakąkolwiek możliwość minimalnie rejestrowanych wstawek, ponieważ wymagają one posortowanych danych (DML Request Sort =true). Po drugie, podczas wstawiania wystąpi duża liczba „złych” podziałów stron. Jeśli wydaje się to sprzeczne z intuicją, pamiętaj, że chociaż ROW_NUMBER funkcja numeruje wiersze po kolei, efektem działania operatora modulo jest przedstawienie powtarzającej się sekwencji liczb 1…1000 wstawce indeksu klastrowego.
Ten sam podstawowy problem pojawia się, gdy używamy sztuczek T-SQL, aby zmniejszyć oczekiwaną liczbę wierszy, aby uniknąć sortowania, zamiast używać nieobsługiwanej flagi śledzenia.
Unikanie sortowania II
Patrząc na plan jako całość, wydaje się jasne, że chcielibyśmy generować wiersze w sposób, który unika jawnego sortowania, ale nadal czerpie korzyści z minimalnego rejestrowania i unikania złego podziału stron. Mówiąc prościej:chcemy planu, który przedstawia wiersze w kolejności kluczy klastrowych, ale bez sortowania.
Uzbrojeni w ten nowy wgląd, możemy wyrazić nasze zapytanie w inny sposób. Poniższe zapytanie generuje każdą liczbę od 1 do 1000 i sprzężenia krzyżowe, które mają zestaw 10 000 wierszy, aby uzyskać wymagany stopień duplikacji. Pomysł polega na wygenerowaniu zestawu wkładek, który przedstawia 10 000 wierszy ponumerowanych „1”, a następnie 10 000 ponumerowanych „2”… i tak dalej.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Niestety optymalizator nadal tworzy plan z sortowaniem:

Nie ma tu wiele do powiedzenia w obronie optymalizatora, to tylko głupi plan. Postanowił wygenerować 10 000 wierszy, a następnie połączyć krzyżowo te z liczbami od 1 do 1000. Nie pozwala to na zachowanie naturalnej kolejności liczb, więc sortowania nie można uniknąć.
Unikanie sortowania – wreszcie!
Strategią, którą pominął optymalizator, jest przyjęcie liczb 1…1000 najpierw i krzyżowe łączenie każdej liczby z 10 000 wierszy (co daje 10 000 kopii każdej liczby w sekwencji). Oczekiwany plan pozwoli uniknąć sortowania za pomocą zagnieżdżonych pętli krzyżowych, które zachowują kolejność wierszy na wejściu zewnętrznym.
Możemy osiągnąć ten wynik, zmuszając optymalizator do dostępu do tabel pochodnych w kolejności określonej w zapytaniu, używając FORCE ORDER wskazówka dotycząca zapytania:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); W końcu otrzymujemy plan, którego szukaliśmy:
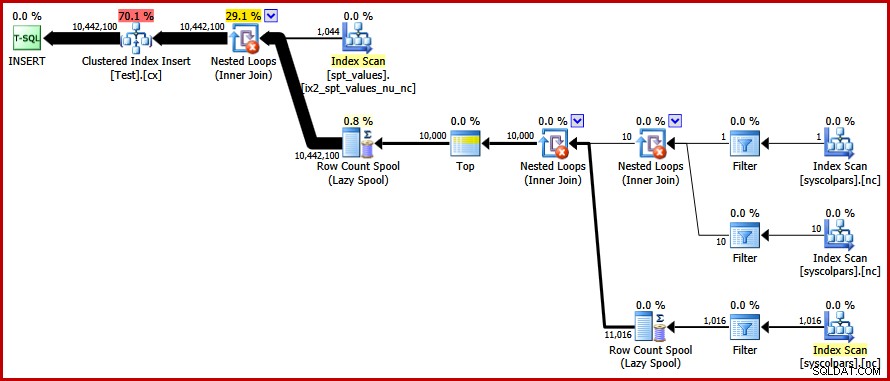
Ten plan pozwala uniknąć jawnego sortowania, jednocześnie unikając „złych” podziałów stron i umożliwiając minimalnie rejestrowane wstawki do indeksu klastrowego (przy założeniu, że baza danych nie używa FULL model odzyskiwania). Ładuje wszystkie dziesięć milionów wierszy w około 9 sekund na moim laptopie (z pojedynczym dyskiem wirującym SATA 7200 obr./min). Oznacza to znaczny wzrost wydajności w ciągu 30-50 sekund czas, jaki upłynął przed przepisaniem.
Znajdowanie odrębnych wartości
Po utworzeniu przykładowych danych możemy skupić się na napisaniu zapytania, aby znaleźć różne wartości w tabeli. Naturalny sposób wyrażenia tego wymagania w T-SQL jest następujący:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
Plan wykonania jest bardzo prosty, jak można się spodziewać:

Zajmuje to około 2900 ms działać na moim komputerze i wymaga 43 406 odczyty logiczne:

Usuwanie MAXDOP (1) wskazówka zapytania generuje plan równoległy:

Kończy się to za około 1500 ms (ale przy zużyciu 8764 ms czasu procesora) i 43 804 odczyty logiczne:

Te same plany i wyniki wydajności, jeśli użyjemy GROUP BY zamiast DISTINCT .
Lepszy algorytm
Przedstawione powyżej plany zapytań odczytują wszystkie wartości z tabeli podstawowej i przetwarzają je za pośrednictwem Stream Aggregate. Myśląc o zadaniu jako całości, skanowanie wszystkich 10 milionów wierszy wydaje się nieefektywne, gdy wiemy, że istnieje stosunkowo niewiele odrębnych wartości.
Lepszą strategią może być znalezienie pojedynczej najniższej wartości w tabeli, następnie znalezienie następnej najwyższej i tak dalej, aż skończą się nam wartości. Co najważniejsze, to podejście nadaje się do wyszukiwania pojedynczych elementów w indeksie, zamiast skanowania każdego wiersza.
Możemy zaimplementować ten pomysł w pojedynczym zapytaniu przy użyciu rekurencyjnego CTE, w którym część kotwicy znajduje najniższą odrębna wartość, następnie część rekurencyjna znajduje następną odrębną wartość i tak dalej. Pierwsza próba napisania tego zapytania to:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Niestety ta składnia się nie kompiluje:

Ok, więc funkcje agregujące nie są dozwolone. Zamiast używać MIN , możemy napisać tę samą logikę za pomocą TOP (1) z ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Nadal nie ma radości.
Okazuje się, że możemy obejść te ograniczenia, przepisując część rekurencyjną, aby ponumerować kandydujące wiersze w wymaganej kolejności, a następnie odfiltrować wiersz, który ma numer „jeden”. Może się to wydawać nieco zawiłe, ale logika jest dokładnie taka sama:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); To zapytanie robi skompilować i utworzyć następujący plan wykonania:

Zwróć uwagę na operator Top w rekurencyjnej części planu wykonania (podświetlony). Nie możemy napisać TOP T-SQL w rekurencyjnej części rekurencyjnego wyrażenia tabelowego, ale to nie znaczy, że optymalizator nie może go użyć! Optymalizator wprowadza Top w oparciu o rozumowanie dotyczące liczby wierszy, które trzeba będzie sprawdzić, aby znaleźć ten o numerze „1”.
Wydajność tego (nierównoległego) planu jest znacznie lepsza niż podejście Stream Aggregate. Kończy się w około 50 ms , z 3007 odczyty logiczne z tabeli źródłowej (i 6001 wierszy odczytanych z tabeli roboczej buforowania), w porównaniu z poprzednim najlepszym z 1500 ms (8764 ms czasu procesora przy DOP 8) i 43 804 odczyty logiczne:


Wniosek
Nie zawsze jest możliwe osiągnięcie przełomu w wydajności zapytań poprzez samodzielne uwzględnianie poszczególnych elementów planu zapytań. Czasami musimy przeanalizować strategię stojącą za całym planem wykonania, a następnie pomyśleć z boku, aby znaleźć bardziej wydajny algorytm i implementację.