Grupy dostępności, wprowadzone w SQL Server 2012, reprezentują fundamentalną zmianę w sposobie, w jaki myślimy o wysokiej dostępności i odzyskiwaniu po awarii naszych baz danych. Jedną ze wspaniałych rzeczy, które są tutaj możliwe, jest przeniesienie operacji tylko do odczytu do repliki pomocniczej, dzięki czemu podstawowe wystąpienie odczytu/zapisu nie jest zawracane przez nieznośne rzeczy, takie jak raportowanie przez użytkownika końcowego. Konfiguracja nie jest prosta, ale jest o wiele łatwiejsza i łatwiejsza w utrzymaniu niż poprzednie rozwiązania (podnieś rękę, jeśli lubisz konfigurować kopie lustrzane i migawki oraz całą związaną z tym ciągłą konserwację).
Ludzie są bardzo podekscytowani, gdy słyszą o grupach dostępności. Potem uderza rzeczywistość:funkcja wymaga SQL Server w wersji Enterprise (w każdym razie od SQL Server 2014). Enterprise Edition jest kosztowna, zwłaszcza jeśli masz dużo rdzeni, a zwłaszcza od czasu wyeliminowania licencjonowania opartego na CAL (chyba że jesteś dziadkiem od 2008 R2, w którym to przypadku jesteś ograniczony do pierwszych 20 rdzeni). Wymaga również Windows Server Failover Clustering (WSFC), co jest komplikacją nie tylko do demonstrowania technologii na laptopie, ale także wymaga systemu Windows w wersji Enterprise Edition, kontrolera domeny i całej gamy konfiguracji do obsługi klastrowania. W związku z pakietem Software Assurance pojawiły się również nowe wymagania; dodatkowy koszt, jeśli chcesz, aby Twoje instancje rezerwowe były zgodne.
Niektórzy klienci nie mogą uzasadnić ceny. Inni widzą wartość, ale po prostu nie mogą sobie na to pozwolić. Co więc mają zrobić ci użytkownicy?
Twój nowy bohater:wysyłka dziennika
Wysyłka dzienników istnieje od wieków. To proste i po prostu działa. Prawie zawsze. Oprócz ominięcia kosztów licencjonowania i przeszkód konfiguracyjnych przedstawionych przez grupy dostępności, może również uniknąć 14-bajtowej kary, o której mówił Paul Randal (@PaulRandal) w biuletynie SQLskills Insider z tego tygodnia (13 października 2014 r.).
Jednym z wyzwań, jakie napotykają ludzie przy używaniu kopii dziennika jako czytelnej kopii pomocniczej, jest to, że musisz wyrzucić wszystkich obecnych użytkowników, aby zastosować nowe dzienniki – więc albo masz użytkowników, którzy się denerwują, ponieważ są wielokrotnie zakłócani z uruchamiania zapytań lub użytkownicy denerwują się, ponieważ ich dane są nieaktualne. Dzieje się tak, ponieważ ludzie ograniczają się do jednego, czytelnego materiału pomocniczego.
Nie musi tak być; Myślę, że jest tutaj wdzięczne rozwiązanie i chociaż może to wymagać dużo więcej pracy z przodu niż, powiedzmy, włączenie grup dostępności, z pewnością będzie to atrakcyjna opcja dla niektórych.
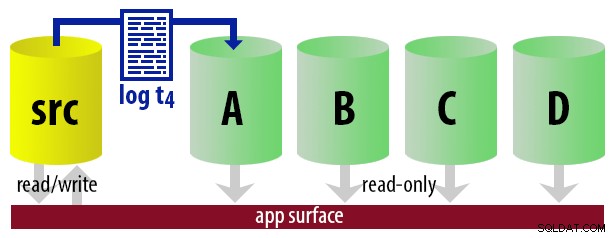
Zasadniczo, możemy ustawić kilka drugorzędnych, w których będziemy rejestrować statek i uczynić tylko jeden z nich „aktywnym” drugorzędnym, stosując podejście round-robin. Zadanie, które wysyła logi, wie, który z nich jest aktualnie aktywny, więc przywraca nowe logi tylko do „następnego” serwera za pomocą Z OCZEKIWANIEM opcja. Aplikacja raportowania używa tych samych informacji, aby określić w czasie wykonywania, jakie parametry połączenia powinny mieć dla następnego raportu uruchomionego przez użytkownika. Gdy kolejna kopia zapasowa dziennika jest gotowa, wszystko przesuwa się o jeden, a instancja, która stanie się teraz nową, czytelną kopią zapasową, zostanie przywrócona przy użyciu Z OCZEKIWANIEM .
Aby model był nieskomplikowany, załóżmy, że mamy cztery instancje, które służą jako czytelne elementy pomocnicze i co 15 minut wykonujemy kopie zapasowe dziennika. W dowolnym momencie będziemy mieć jedną aktywną pomocniczą w trybie gotowości, z danymi nie starszymi niż 15 minut i trzema dodatkowymi w trybie gotowości, które nie obsługują nowych zapytań (ale nadal mogą zwracać wyniki dla starszych zapytań).
Będzie to działać najlepiej, jeśli oczekuje się, że żadne zapytania nie będą trwać dłużej niż 45 minut. (Być może trzeba będzie dostosować te cykle w zależności od charakteru operacji tylko do odczytu, liczby jednoczesnych użytkowników uruchamiających dłuższe zapytania i tego, czy kiedykolwiek możliwe jest zakłócenie pracy użytkowników przez wyrzucenie wszystkich).
Będzie również działać najlepiej, jeśli kolejne zapytania uruchamiane przez tego samego użytkownika mogą zmienić parametry połączenia (jest to logika, która będzie musiała być w aplikacji, chociaż możesz użyć synonimów lub widoków w zależności od architektury) i zawierać różne dane, które mają w międzyczasie uległy zmianie (tak jak gdyby sprawdzali aktualną, stale zmieniającą się bazę danych).
Mając na uwadze wszystkie te założenia, oto przykładowa sekwencja wydarzeń z pierwszych 75 minut naszej implementacji:
| czas | wydarzenia | wizualny |
|---|---|---|
| 12:00 (t0) |
| 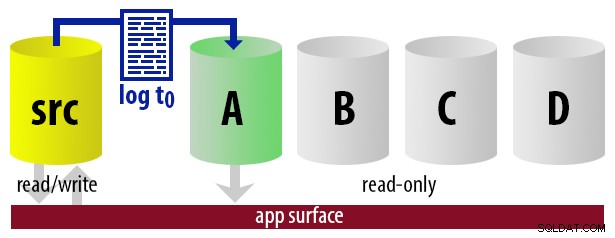 |
| 12:15 (t1) |
| 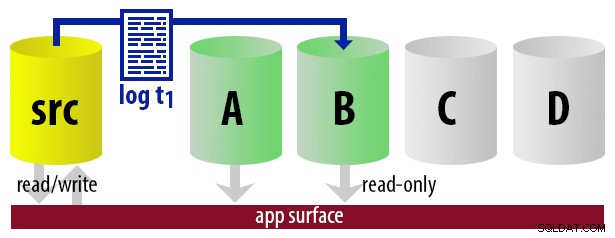 |
| 12:30 (t2) |
| 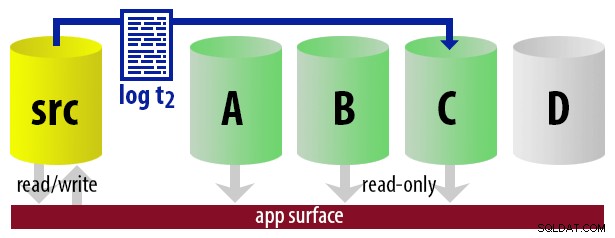 |
| 12:45 (t3) |
| 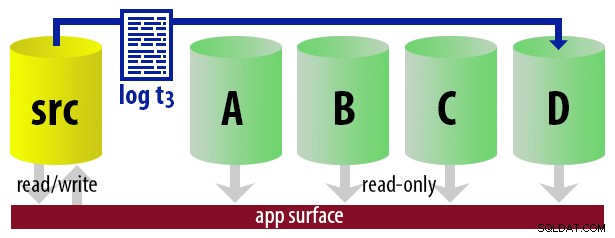 |
| 13:00 (t4) |
|  |
To może wydawać się dość proste; napisanie kodu do obsługi wszystkiego, co jest trochę bardziej zniechęcające. Ogólny zarys:
- Na głównym serwerze (nazwę go
BOSS), utwórz bazę danych. Zanim nawet pomyślisz o dalszych krokach, włącz opcję Trace Flag 3226, aby zapobiec zaśmiecaniu dziennika błędów SQL Server przez komunikaty o udanych kopiach zapasowych. - Na
BOSS, dodaj połączony serwer dla każdego serwera pomocniczego (nazwę jePEON1->PEON4). - Miejsce dostępne dla wszystkich serwerów, utwórz udział plików do przechowywania kopii zapasowych bazy danych/dzienników i upewnij się, że konta usług dla każdej instancji mają dostęp do odczytu/zapisu. Ponadto każda instancja dodatkowa musi mieć określoną lokalizację dla pliku gotowości.
- W oddzielnej bazie danych narzędzi (lub MSDB, jeśli wolisz), utwórz tabele, które będą przechowywać informacje konfiguracyjne dotyczące baz danych, wszystkich pomocniczych i rejestruj historię tworzenia kopii zapasowych i przywracania.
- Utwórz procedury składowane, które stworzą kopię zapasową bazy danych i przywrócą pliki pomocnicze
Z NORECOVERY, a następnie zastosuj jeden dziennikZ GOTOWOŚCIĄi oznacz jedno wystąpienie jako bieżące rezerwowe urządzenie pomocnicze. Procedury te można również wykorzystać do ponownej inicjalizacji całej konfiguracji wysyłki dziennika w przypadku, gdy coś pójdzie nie tak. - Utwórz zadanie, które będzie uruchamiane co 15 minut, aby wykonać zadania opisane powyżej:
- utwórz kopię zapasową dziennika
- określ, do którego urządzenia pomocniczego zastosować niezastosowane kopie zapasowe dziennika
- przywróć te dzienniki z odpowiednimi ustawieniami
- Utwórz procedurę składowaną (i/lub widok?), która poinformuje aplikacje wywołujące, których drugorzędnych powinny używać dla nowych zapytań tylko do odczytu.
- Utwórz procedurę czyszczenia, aby wyczyścić historię kopii zapasowej dziennika dla dzienników, które zostały zastosowane do wszystkich plików pomocniczych (i być może także w celu przeniesienia lub usunięcia samych plików).
- Rozszerz rozwiązanie o solidną obsługę błędów i powiadomienia.
Krok 1 – utwórz bazę danych
Moje podstawowe wystąpienie to wersja standardowa o nazwie .\BOSS . W tym przypadku tworzę prostą bazę danych z jedną tabelą:
USE [master]; GO CREATE DATABASE UserData; GO ALTER DATABASE UserData SET RECOVERY FULL; GO USE UserData; GO CREATE TABLE dbo.LastUpdate(EventTime DATETIME2); INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Następnie tworzę zadanie agenta SQL Server, które jedynie aktualizuje ten znacznik czasu co minutę:
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
To po prostu tworzy początkową bazę danych i symuluje aktywność, co pozwala nam sprawdzić, w jaki sposób zadanie wysyłania dziennika przechodzi przez każdą z czytelnych części pomocniczych. Chcę wyraźnie powiedzieć, że celem tego ćwiczenia nie jest testowanie warunków skrajnych wysyłania dzienników ani udowodnienie, jak dużą objętość możemy przebić; to zupełnie inne ćwiczenie.
Krok 2 – dodaj połączone serwery
Mam cztery dodatkowe instancje Express Edition o nazwie .\PEON1 , .\PEON2 , .\PEON3 i .\PEON4 . Więc uruchomiłem ten kod cztery razy, zmieniając @s za każdym razem:
USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t; Krok 3 – zweryfikuj udziały plików
W moim przypadku wszystkie 5 instancji znajduje się na tym samym serwerze, więc właśnie stworzyłem folder dla każdej instancji:C:\temp\Peon1\ , C:\temp\Peon2\ , i tak dalej. Pamiętaj, że jeśli serwery pomocnicze znajdują się na różnych serwerach, lokalizacja powinna odnosić się do tego serwera, ale nadal być dostępna z serwera podstawowego (więc zwykle używana jest ścieżka UNC). Należy sprawdzić, czy każda instancja może zapisywać w tym udziale, a także sprawdzić, czy każda instancja może zapisywać w lokalizacji określonej dla pliku gotowości (użyłem tych samych folderów do trybu gotowości). Możesz to sprawdzić, tworząc kopię zapasową małej bazy danych z każdej instancji do każdej z jej określonych lokalizacji – nie kontynuuj, dopóki to nie zadziała.
Krok 4 – tworzenie tabel
Postanowiłem umieścić te dane w msdb , ale tak naprawdę nie mam żadnych silnych uczuć za lub przeciw tworzeniu oddzielnej bazy danych. Pierwsza tabela, której potrzebuję, to ta, która zawiera informacje o bazach danych, z których będę przesyłać dzienniki:
CREATE TABLE dbo.PMAG_Databases ( DatabaseName SYSNAME, LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15), CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName) ); GO INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(Jeśli interesuje Cię schemat nazewnictwa, PMAG to skrót od „Poor Man's Availability Groups”).
Kolejna wymagana tabela to tabela zawierająca informacje o elementach pomocniczych, w tym o ich poszczególnych folderach i ich aktualnym statusie w sekwencji wysyłania dziennika.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
);
Jeśli chcesz wykonać kopię zapasową z serwera źródłowego lokalnie i zdalnie przywrócić pliki pomocnicze lub odwrotnie, możesz podzielić CommonFolder na dwie kolumny (BackupFolder i RestoreFolder ) i wprowadź odpowiednie zmiany w kodzie (nie będzie ich tak wiele).
Ponieważ mogę wypełnić tę tabelę przynajmniej częściowo na podstawie informacji z sys.servers – wykorzystując fakt, że foldery data/log i inne są nazwane po nazwach instancji:
INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]';
Potrzebuję również tabeli do śledzenia pojedynczych kopii zapasowych dziennika (nie tylko ostatniej), ponieważ w wielu przypadkach będę musiał przywracać wiele plików dziennika po kolei. Mogę uzyskać te informacje z msdb.dbo.backupset , ale uzyskanie informacji takich jak lokalizacja jest znacznie bardziej skomplikowane – i mogę nie mieć kontroli nad innymi zadaniami, które mogą czyścić historię kopii zapasowych.
CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Można by pomyśleć, że przechowywanie wiersza dla każdego pomocniczego i przechowywanie lokalizacji każdej kopii zapasowej jest marnotrawstwem, ale jest to zabezpieczenie na przyszłość — aby poradzić sobie z przypadkiem, w którym przenosisz CommonFolder dla dowolnego dodatkowego.
I wreszcie historia przywracania dzienników, więc w dowolnym momencie mogę zobaczyć, które dzienniki zostały przywrócone i gdzie, a zadanie przywracania może mieć pewność, że przywróci tylko te dzienniki, które nie zostały jeszcze przywrócone:
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Krok 5 – zainicjuj wtórne
Potrzebujemy procedury składowanej, która wygeneruje plik kopii zapasowej (i odzwierciedli go w dowolnych lokalizacjach wymaganych przez różne instancje), a także przywrócimy po jednym dzienniku do każdego dodatkowego serwera, aby przełączyć je w stan gotowości. W tym momencie wszystkie będą dostępne dla zapytań tylko do odczytu, ale tylko jeden będzie w „bieżącym” trybie gotowości w danym momencie. Jest to procedura składowana, która obsługuje zarówno pełne kopie zapasowe dziennika transakcji, jak i kopie zapasowe; gdy wymagana jest pełna kopia zapasowa i @init jest ustawiony na 1, automatycznie ponownie inicjuje wysyłanie dziennika.
CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END To z kolei wywołuje dwie procedury, które możesz wywołać osobno (ale najprawdopodobniej nie). Po pierwsze, procedura, która zainicjuje wtórne przy pierwszym uruchomieniu:
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END A potem procedura, która przywróci logi:
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END (Wiem, że to dużo kodu i dużo tajemniczego dynamicznego SQL. Starałem się być bardzo liberalny z komentarzami; jeśli jest jakiś fragment, z którym masz problem, daj mi znać.)
Więc teraz wszystko, co musisz zrobić, aby uruchomić system, to wykonać dwa wywołania procedur:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1; EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Teraz powinieneś zobaczyć każdą instancję z zapasową kopią bazy danych:
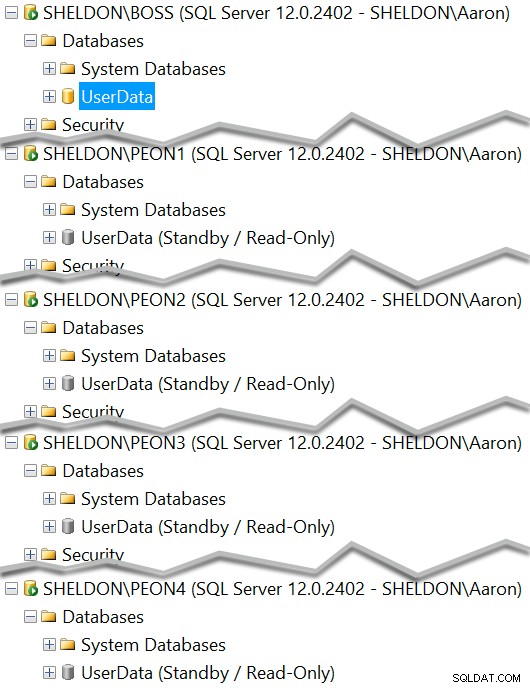
I możesz zobaczyć, który z nich powinien obecnie służyć jako tryb gotowości tylko do odczytu:
SELECT ServerInstance, IsCurrentStandby FROM dbo.PMAG_Secondaries WHERE DatabaseName = N'UserData';
Krok 6 – utwórz zadanie, które tworzy kopię zapasową / przywraca logi
Możesz umieścić to polecenie w zaplanowanym zadaniu co 15 minut:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Spowoduje to przesunięcie aktywnego wtórnego co 15 minut, a jego dane będą o 15 minut świeższe niż poprzedni aktywny wtórny. Jeśli masz wiele baz danych według różnych harmonogramów, możesz utworzyć wiele zadań lub zaplanować zadanie częściej i sprawdzić dbo.PMAG_Databases tabela dla każdego indywidualnego LogBackupFrequency_Minutes wartość, aby określić, czy należy uruchomić kopię zapasową/przywracanie tej bazy danych.
Krok 7 – widok i procedura informowania aplikacji, który tryb czuwania jest aktywny
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO
W moim przypadku również ręcznie utworzyłem połączenie widoków we wszystkich UserData baz danych, abym mógł porównać ostatnie dane na podstawowym z każdym wtórnym.
CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
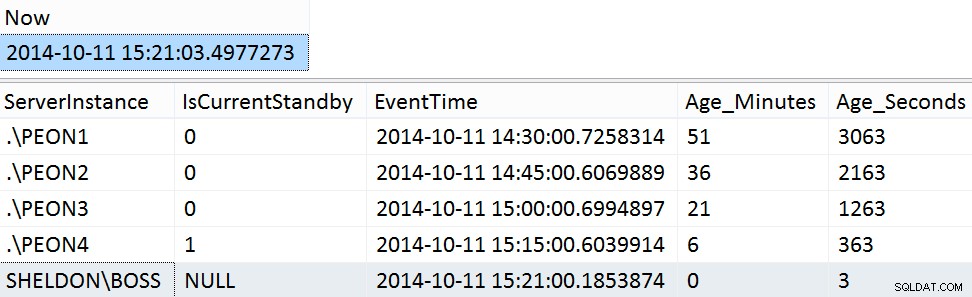
GO Przykładowe wyniki z weekendu:
SELECT [Now] = SYSDATETIME(); SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds FROM dbo.PMAG_CompareRecency_UserData ORDER BY Age_Seconds DESC;
Krok 8 – procedura czyszczenia
Czyszczenie historii kopii zapasowej i przywracania dziennika jest dość łatwe.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO Teraz możesz dodać to jako krok w istniejącym zadaniu lub możesz zaplanować to całkowicie osobno lub jako część innych procedur czyszczenia.
Zostawię czyszczenie systemu plików na kolejny post (i prawdopodobnie zupełnie oddzielny mechanizm, taki jak PowerShell lub C# – zazwyczaj nie jest to coś, czego oczekujesz od T-SQL).
Krok 9 – rozszerz rozwiązanie
Prawdą jest, że może być tutaj lepsza obsługa błędów i inne drobiazgi, aby to rozwiązanie było pełniejsze. Na razie pozostawię to jako ćwiczenie dla czytelnika, ale planuję przyjrzeć się kolejnym postom, aby szczegółowo ulepszyć i udoskonalić to rozwiązanie.
Zmienne i ograniczenia
Zauważ, że w moim przypadku użyłem Standard Edition jako podstawowego, a Express Edition dla wszystkich dodatkowych. Możesz pójść o krok dalej w skali budżetu, a nawet użyć Express Edition jako podstawowego – wiele osób uważa, że Express Edition nie obsługuje przesyłania dzienników, podczas gdy w rzeczywistości jest to tylko kreator, którego nie było w wersjach Management Studio Express przed SQL Server 2012 z dodatkiem Service Pack 1. To powiedziawszy, ponieważ Express Edition nie obsługuje agenta SQL Server, trudno byłoby uczynić go wydawcą w tym scenariuszu — należałoby skonfigurować własny harmonogram, aby wywoływał procedury składowane (C# aplikacja wiersza polecenia uruchamiana przez Harmonogram zadań systemu Windows, zadania PowerShell lub zadania agenta SQL Server w jeszcze innym wystąpieniu). Aby korzystać z Express na obu końcach, musisz mieć pewność, że plik danych nie przekroczy 10 GB, a Twoje zapytania będą działać poprawnie z ograniczeniami pamięci, procesora i funkcji tej edycji. W żadnym wypadku nie sugeruję, że Express jest idealny; Użyłem go jedynie, aby zademonstrować, że można mieć bardzo elastyczne, czytelne pliki wtórne za darmo (lub bardzo blisko).
Ponadto te oddzielne instancje w moim scenariuszu działają na tej samej maszynie wirtualnej, ale wcale nie musi to działać w ten sposób — można rozłożyć instancje na wiele serwerów; lub możesz pójść w drugą stronę i przywrócić różne kopie bazy danych o różnych nazwach w tej samej instancji. Te konfiguracje wymagałyby minimalnych zmian w tym, co przedstawiłem powyżej. A ile baz danych przywracasz i jak często, zależy wyłącznie od Ciebie – chociaż będzie praktyczna górna granica (gdzie [średni czas zapytania]> [liczba pomocniczych] x [interwał tworzenia dzienników] ).
Wreszcie, takie podejście ma pewne ograniczenia. Niepełna lista:
- Choć możesz nadal tworzyć pełne kopie zapasowe zgodnie z własnym harmonogramem, kopie zapasowe dziennika muszą służyć jako jedyny mechanizm tworzenia kopii zapasowych dziennika. Jeśli musisz przechowywać kopie zapasowe dzienników do innych celów, nie będziesz mieć możliwości tworzenia kopii zapasowych dzienników oddzielnie od tego rozwiązania, ponieważ będą one zakłócać łańcuch dzienników. Zamiast tego możesz rozważyć dodanie dodatkowego
MIRROR TOarguments to the existing log backup scripts, if you need to have copies of the logs used elsewhere. - While "Poor Man's Availability Groups" may seem like a clever name, it can also be a bit misleading. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication:a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing:I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete – which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.



