Aparat wykonywania zapytań programu SQL Server ma dwa sposoby na zaimplementowanie logicznej operacji „unij wszystko” przy użyciu operatorów fizycznych Łączenie i Łączenie łączenia Łączenie. Chociaż operacja logiczna jest taka sama, istnieją istotne różnice między dwoma operatorami fizycznymi, które mogą mieć ogromny wpływ na wydajność twoich planów wykonania.
Optymalizator zapytań wykonuje w wielu przypadkach sensowną pracę, wybierając jedną z dwóch opcji, ale w tej dziedzinie daleko mu do doskonałości. W tym artykule opisano możliwości dostrajania zapytań oferowane przez funkcję Merge Join Concatenation oraz szczegółowo opisano wewnętrzne zachowania i kwestie, o których należy pamiętać, aby jak najlepiej je wykorzystać.
Konkatenacja

Operator konkatenacji jest stosunkowo prosty:jego dane wyjściowe są wynikiem pełnego odczytu z każdego z jego danych wejściowych w kolejności. Operator konkatenacji to n-ar operator fizyczny, co oznacza, że może mieć wejścia '2…n'. Aby to zilustrować, wróćmy do przykładu opartego na AdventureWorks z mojego poprzedniego artykułu „Przepisywanie zapytań w celu poprawy wydajności”:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Poniższe zapytanie zawiera listę identyfikatorów produktów i transakcji dla sześciu konkretnych produktów:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
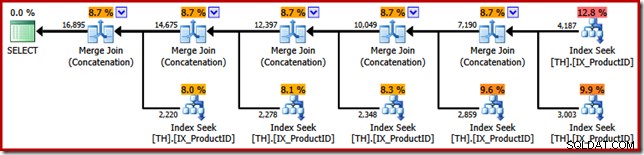
Tworzy plan wykonania zawierający operator konkatenacji z sześcioma danymi wejściowymi, jak widać w SQL Sentry Plan Explorer:
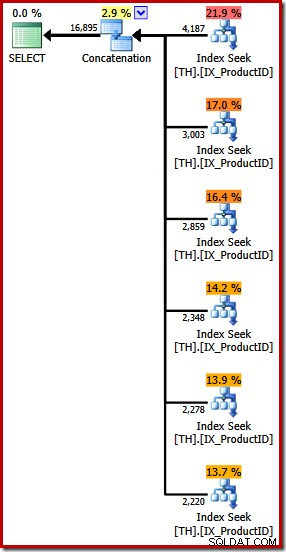
Powyższy plan zawiera oddzielne wyszukiwanie indeksu dla każdego wymienionego identyfikatora produktu, w takiej samej kolejności, jak określono w zapytaniu (od góry do dołu). Najwyższe wyszukiwanie indeksu dotyczy produktu 870, następne w dół dotyczy produktu 873, następnie 921 i tak dalej. Nic z tego nie gwarantuje oczywiście zachowania, jest to po prostu coś interesującego do zaobserwowania.
Wspomniałem wcześniej, że operator konkatenacji tworzy swoje dane wyjściowe, odczytując kolejno z jego danych wejściowych. Po wykonaniu tego planu istnieje duża szansa, że w zestawie wyników najpierw zostaną wyświetlone wiersze dla produktu 870, następnie 873, 921, 712, 707, a na końcu produktu 711. Ponownie nie jest to gwarantowane, ponieważ nie określiliśmy ZAMÓWIENIA Klauzula BY, ale pokazuje, jak konkatenacja działa wewnętrznie.
Plan wykonania usługi SSIS
Z powodów, które za chwilę będą miały sens, zastanów się, jak zaprojektować pakiet SSIS do wykonania tego samego zadania. Z pewnością moglibyśmy również napisać całość jako pojedynczą instrukcję T-SQL w SSIS, ale ciekawszą opcją jest utworzenie oddzielnego źródła danych dla każdego produktu i użycie komponentu SSIS „Union All” zamiast SQL Server Concatenation operator:
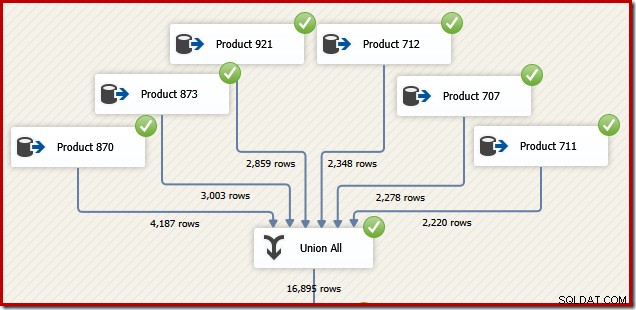
Teraz wyobraź sobie, że potrzebujemy ostatecznych danych wyjściowych z tego przepływu danych w kolejności identyfikatora transakcji. Jedną z opcji byłoby dodanie jawnego komponentu Sort po Union All:
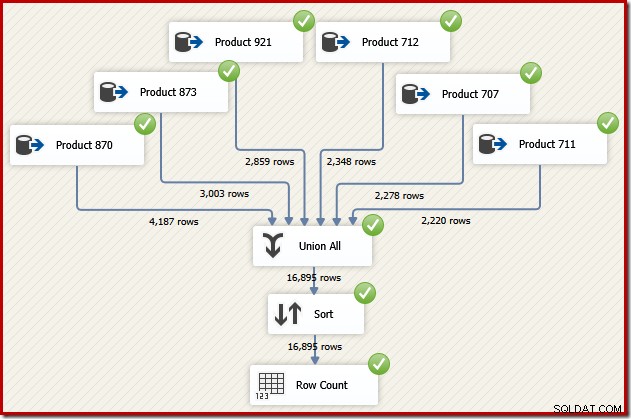
To z pewnością załatwiłoby sprawę, ale wykwalifikowany i doświadczony projektant SSIS zdałby sobie sprawę, że istnieje lepsza opcja:przeczytaj dane źródłowe dla każdego produktu w kolejności identyfikatora transakcji (wykorzystując indeks), a następnie użyj operacji zachowywania kolejności, aby połączyć zestawy .
W SSIS składnik, który łączy wiersze z dwóch posortowanych przepływów danych w jeden posortowany przepływ danych, nazywa się „Scalanie”. Przeprojektowany przepływ danych SSIS, który używa funkcji scalania do zwracania żądanych wierszy w kolejności identyfikatora transakcji:
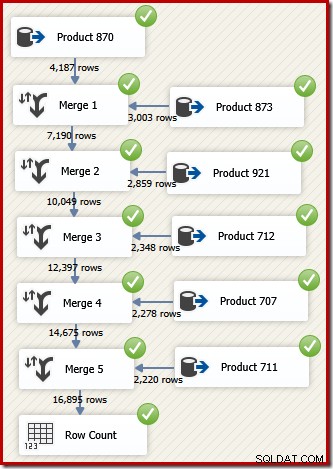
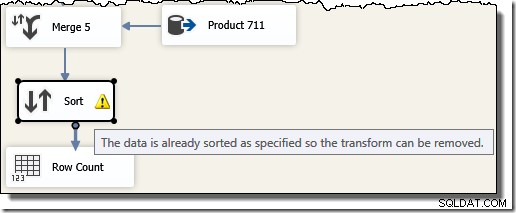
Zauważ, że potrzebujemy pięciu oddzielnych komponentów Merge, ponieważ Merge jest komponentem binarnym, w przeciwieństwie do komponentu SSIS „Union All”, który był n-ary . Nowy przepływ scalania generuje wyniki w kolejności identyfikatora transakcji, bez konieczności stosowania drogiego (i blokującego) składnika sortowania. Rzeczywiście, jeśli spróbujemy dodać Sortuj według identyfikatora transakcji po ostatecznym scaleniu, SSIS wyświetli ostrzeżenie, aby poinformować nas, że strumień jest już posortowany w pożądany sposób:
Można teraz ujawnić sens przykładu SSIS. Spójrz na plan wykonania wybrany przez optymalizator zapytań SQL Server, gdy poprosimy go o zwrócenie oryginalnych wyników zapytania T-SQL w kolejności identyfikatora transakcji (poprzez dodanie klauzuli ORDER BY):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Podobieństwa do pakietu SSIS Merge są uderzające; nawet do konieczności użycia pięciu binarnych operatorów „Scal”. Jedyną ważną różnicą jest to, że SSIS ma oddzielne składniki dla „Scalanie” i „Scalanie”, podczas gdy SQL Server używa tego samego operatora podstawowego dla obu.
Aby było jasne, operatory łączenia łączenia (konkatenacji) w planie wykonania programu SQL Server nie wykonanie sprzężenia; silnik po prostu ponownie wykorzystuje tego samego operatora fizycznego do wdrożenia unii wszystkich zachowujących porządek.
Pisanie planów wykonania w SQL Server
Usługi SSIS nie mają języka specyfikacji przepływu danych ani optymalizatora umożliwiającego przekształcenie takiej specyfikacji w wykonywalne zadanie przepływu danych. Projektant pakietów SSIS musi zdać sobie sprawę, że możliwe jest scalanie z zachowaniem kolejności, odpowiednio ustawić właściwości składników (takie jak klucze sortowania), a następnie porównać wydajność. Wymaga to większego wysiłku (i umiejętności) ze strony projektanta, ale zapewnia bardzo dobry stopień kontroli.
Sytuacja w SQL Server jest odwrotna:piszemy zapytanie specyfikacja używając języka T-SQL, a następnie polegaj na optymalizatorze zapytań, aby zbadać opcje implementacji i wybrać skuteczną. Nie mamy możliwości bezpośredniego skonstruowania planu wykonania. W większości przypadków jest to bardzo pożądane:SQL Server bez wątpienia byłby mniej popularny, gdyby każde zapytanie wymagało od nas napisania pakietu w stylu SSIS.
Niemniej jednak (jak wyjaśniłem w moim poprzednim poście), plan wybrany przez optymalizator może być wrażliwy na T-SQL użyty do opisania pożądanych wyników. Powtarzając przykład z tego artykułu, mogliśmy napisać oryginalne zapytanie T-SQL, używając alternatywnej składni:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
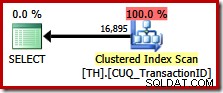
To zapytanie określa dokładnie ten sam zestaw wyników co poprzednio, ale optymalizator nie bierze pod uwagę planu zachowania kolejności (konkatenacji scalania), wybierając zamiast tego skanowanie indeksu klastrowego (opcja znacznie mniej wydajna):
Wykorzystywanie zachowania zamówień w SQL Server
Unikanie niepotrzebnego sortowania może prowadzić do znacznego wzrostu wydajności, niezależnie od tego, czy mówimy o SSIS, czy SQL Server. Osiągnięcie tego celu może być bardziej skomplikowane i trudniejsze w SQL Server, ponieważ nie mamy tak szczegółowej kontroli nad planem wykonania, ale wciąż są rzeczy, które możemy zrobić.
W szczególności zrozumienie, w jaki sposób operator SQL Server Merge Join Concatenation działa wewnętrznie, może pomóc nam w dalszym pisaniu przejrzystego, relacyjnego T-SQL, jednocześnie zachęcając optymalizatora zapytań do rozważenia opcji przetwarzania zachowywania kolejności (scalania) tam, gdzie jest to właściwe.
Jak działa konkatenacja łączenia łączenia

Zwykłe sprzężenie scalające wymaga posortowania obu danych wejściowych według kluczy sprzężenia. Z drugiej strony Merge Join Conkatenacja po prostu łączy dwa już uporządkowane strumienie w jeden uporządkowany strumień – nie ma połączenia jako takiego.
Nasuwa się pytanie:czym dokładnie jest „zamówienie”, które jest zachowywane?
W SSIS musimy ustawić właściwości klucza sortowania na wejściach scalania, aby zdefiniować kolejność. SQL Server nie ma odpowiednika tego. Odpowiedź na powyższe pytanie jest trochę skomplikowana, więc zajmiemy się nią krok po kroku.
Rozważmy następujący przykład, który żąda połączenia scalającego dwóch niezindeksowanych tabel sterty (najprostszy przypadek):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Te dwie tabele nie mają indeksów ani klauzuli ORDER BY. Jaką kolejność „zachowa” połączenie łączenia łączenia? Aby dać ci chwilę na przemyślenie, spójrzmy najpierw na plan wykonania stworzony dla powyższego zapytania w wersjach SQL Server przed 2012:
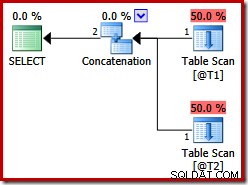
Nie ma konkatenacji łączenia łączenia, pomimo wskazówki dotyczącej kwerendy:przed SQL Server 2012 ta wskazówka działa tylko z UNION, a nie z UNION ALL. Aby uzyskać plan z żądanym operatorem scalania, musimy wyłączyć implementację logicznego UNION ALL (UNIA) za pomocą fizycznego operatora Concatenation (CON). Należy pamiętać, że następujące elementy są nieudokumentowane i nie są obsługiwane do użytku produkcyjnego:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
To zapytanie generuje ten sam plan, co SQL Server 2012 i 2014 z samą wskazówką dotyczącą zapytania MERGE UNION:
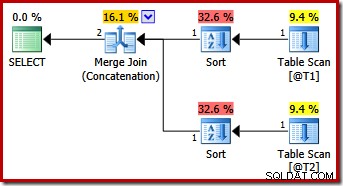
Być może nieoczekiwanie plan wykonania zawiera jawne sortowanie obu danych wejściowych do scalenia. Właściwości sortowania to:
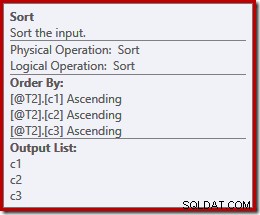
To ma sens, że scalanie z zachowaniem kolejności wymaga spójnego uporządkowania danych wejściowych, ale dlaczego wybrało (c1, c2, c3) zamiast powiedzmy (c3, c1, c2) lub (c2, c3, c1)? Jako punkt wyjścia, dane wejściowe konkatenacji scalania są sortowane na liście rzutowania wyjściowego. Gwiazdka wyboru w zapytaniu rozwija się do (c1, c2, c3), więc jest to wybrana kolejność.
Sortuj według listy projekcji scalania danych wyjściowych
Aby dokładniej zilustrować tę kwestię, możemy sami rozwinąć gwiazdę wyboru (tak jak powinniśmy!) wybierając inną kolejność (c3, c2, c1), gdy już jesteśmy przy niej:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Rodzaje teraz się zmieniają, aby pasowały (c3, c2, c1):
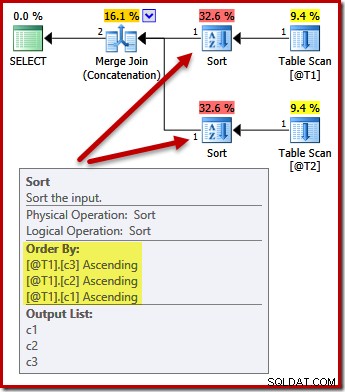
Ponownie zapytanie wyjście zamówienie (zakładając, że dodaliśmy jakieś dane do tabel) nie jest gwarantowane, że zostanie posortowane tak, jak pokazano, ponieważ nie mamy klauzuli ORDER BY. Te przykłady mają po prostu pokazać, w jaki sposób optymalizator wybiera początkową kolejność sortowania danych wejściowych, przy braku innego powodu do sortowania.
Sprzeczne porządki sortowania
Zastanówmy się teraz, co się stanie, jeśli zostawimy listę projekcji jako (c3, c2, c1) i dodamy wymóg uporządkowania wyników zapytania według (c1, c2, c3). Czy dane wejściowe do scalenia nadal będą sortowane według (c3, c2, c1) z sortowaniem po scaleniu według (c1, c2, c3), aby spełnić ORDER BY?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Nie. Optymalizator jest wystarczająco inteligentny, aby uniknąć dwukrotnego sortowania:
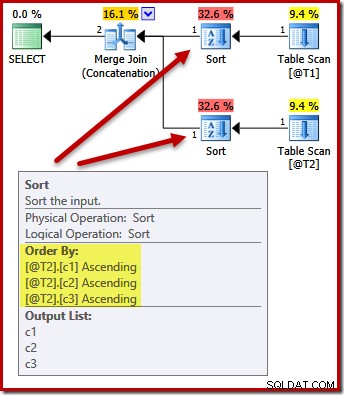
Sortowanie obu danych wejściowych według (c1, c2, c3) jest całkowicie akceptowalne w przypadku łączenia scalającego, więc nie jest wymagane podwójne sortowanie.
Pamiętaj, że ten plan tak zagwarantować, że kolejność wyników będzie (c1, c2, c3). Plan wygląda tak samo jak wcześniejsze plany bez ORDER BY, ale nie wszystkie szczegóły wewnętrzne są przedstawione w planach wykonania widocznych dla użytkownika.
Efekt wyjątkowości
Podczas wybierania kolejności sortowania danych wejściowych scalania na optymalizator wpływają również wszelkie istniejące gwarancje unikalności. Rozważmy następujący przykład z pięcioma kolumnami, ale zwróć uwagę na różne kolejność kolumn w operacji UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Plan wykonania zawiera sortowania na (c5, c1, c2, c4, c3) dla tabeli @T1 oraz (c5, c4, c3, c2, c1) dla tabeli @T2:
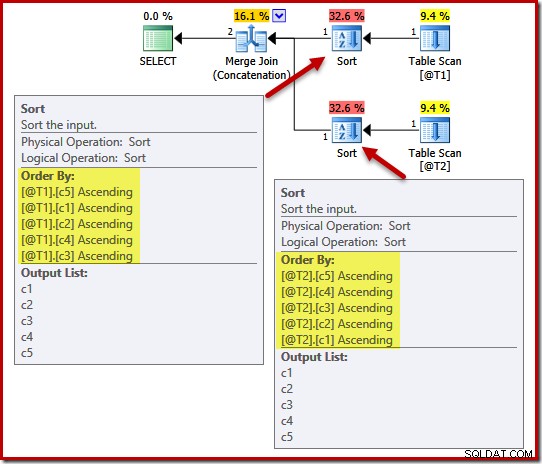
Aby zademonstrować wpływ unikalności na te rodzaje, dodamy ograniczenie UNIQUE do kolumny c1 w tabeli T1 i kolumny c4 w tabeli T2:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Kwestia unikalności polega na tym, że optymalizator wie, że może przerwać sortowanie, gdy tylko napotka kolumnę, która na pewno jest unikalna. Sortowanie według dodatkowych kolumn po napotkaniu unikalnego klucza z definicji nie wpłynie na ostateczną kolejność sortowania.
Z ograniczeniami typu UNIQUE, optymalizator może uprościć listę sortowania (c5, c1, c2, c4, c3) dla T1 do (c5, c1), ponieważ c1 jest unikatowe. Podobnie lista sortowania (c5, c4, c3, c2, c1) dla T2 jest uproszczona do (c5, c4), ponieważ c4 jest kluczem:
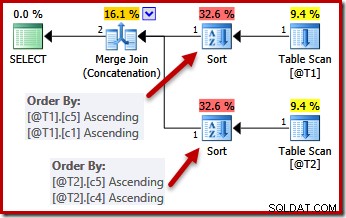
Równoległość
Uproszczenie dzięki unikalnemu kluczowi nie jest doskonale realizowane. W planie równoległym strumienie są podzielone na partycje, dzięki czemu wszystkie wiersze dla tego samego wystąpienia scalania kończą się w tym samym wątku. To partycjonowanie zestawu danych jest oparte na scalanych kolumnach i nie jest uproszczone przez obecność klucza.
Poniższy skrypt używa nieobsługiwanej flagi śledzenia 8649 w celu wygenerowania planu równoległego dla poprzedniej kwerendy (który w przeciwnym razie pozostaje niezmieniony):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
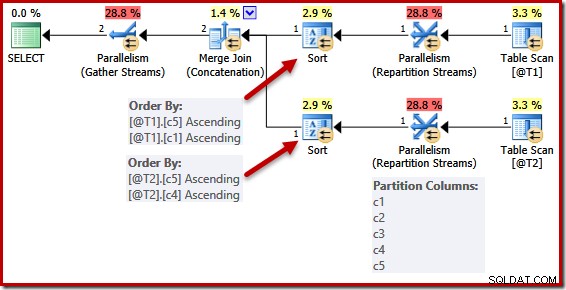
Listy sortowania są uproszczone jak poprzednio, ale operatory strumieni podziału nadal dzielą się na wszystkie kolumny. Gdyby to uproszczenie było konsekwentnie wdrażane, operatory podziału na partycje również działałyby na samych (c5, c1) i (c5, c4).
Problemy z nieunikalnymi indeksami
Sposób, w jaki optymalizator uzasadnia wymagania sortowania dla łączenia scalającego, może skutkować niepotrzebnymi problemami z sortowaniem, jak pokazuje następny przykład:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Patrząc na zapytanie i dostępne indeksy, spodziewalibyśmy się planu wykonania, który wykona uporządkowane skanowanie indeksów klastrowych, używając konkatenacji łączenia scalającego, aby uniknąć konieczności sortowania. To oczekiwanie jest w pełni uzasadnione, ponieważ indeksy klastrowe zapewniają kolejność określoną w klauzuli ORDER BY. Niestety, plan, który otrzymujemy, obejmuje dwa rodzaje:
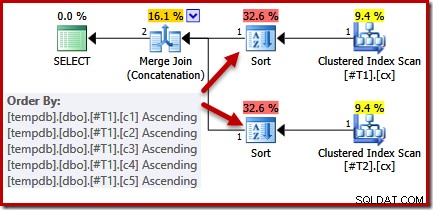
Nie ma dobrego powodu tego rodzaju, pojawiają się one tylko dlatego, że logika optymalizatora zapytań jest niedoskonała. Lista kolumn wyjściowych scalania (c1, c2, c3, c4, c5) jest nadzbiorem ORDER BY, ale nie ma unikalnego klucz do uproszczenia tej listy. W wyniku tej luki w rozumowaniu optymalizatora dochodzi do wniosku, że scalanie wymaga posortowania danych wejściowych według (c1, c2, c3, c4, c5).
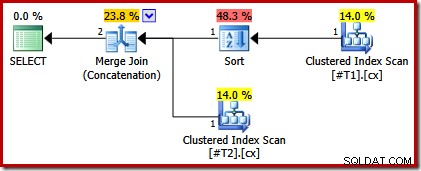
Możemy zweryfikować tę analizę, modyfikując skrypt, aby jeden z klastrowanych indeksów był unikalny:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Plan wykonania ma teraz tylko sortowanie nad tabelą z nieunikalnym indeksem:
Jeśli teraz zrobimy oba indeksy klastrowe są unikalne, nie pojawiają się żadne sortowania:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Ponieważ oba indeksy są unikalne, początkowe listy sortowania danych wejściowych scalania można uprościć do samej kolumny c1. Uproszczona lista dokładnie pasuje do klauzuli ORDER BY, więc w ostatecznym planie nie ma potrzeby sortowania:
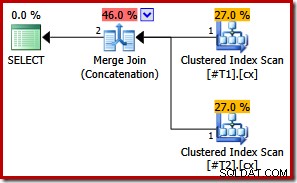
Zauważ, że w tym ostatnim przykładzie nie potrzebujemy nawet podpowiedzi do zapytania, aby uzyskać optymalny plan wykonania.
Ostateczne myśli
Wyeliminowanie rodzajów w planie wykonania może być trudne. W niektórych przypadkach dostarczenie wierszy w wymaganej kolejności może być tak proste, jak zmodyfikowanie istniejącego indeksu (lub dostarczenie nowego). Optymalizator zapytań wykonuje ogólnie rozsądną pracę, gdy dostępne są odpowiednie indeksy.
Jednak w (wielu) innych przypadkach unikanie sortowania może wymagać znacznie głębszego zrozumienia mechanizmu wykonywania, optymalizatora zapytań i samych operatorów planu. Unikanie sortowania to niewątpliwie zaawansowany temat dostrajania zapytań, ale także niezwykle satysfakcjonujący, gdy wszystko jest w porządku.