Jak niedawno ogłosiliśmy, ClusterControl 1.7.4 ma nową funkcję o nazwie Cluster-to-Cluster Replication. Pozwala na uruchomienie replikacji między dwoma autonomicznymi klastrami. Aby uzyskać bardziej szczegółowe informacje, zapoznaj się z wyżej wymienionym ogłoszeniem.
Przyjrzymy się, jak wykorzystać tę nową funkcję w istniejącym klastrze PostgreSQL. W tym zadaniu założymy, że masz zainstalowany ClusterControl, a Master Cluster został wdrożony przy jego użyciu.
Wymagania dla Master Cluster
Istnieją pewne wymagania, aby Master Cluster działał:
- PostgreSQL 9.6 lub nowszy.
- Musi istnieć serwer PostgreSQL z rolą ClusterControl „Master”.
- Podczas konfigurowania klastra podrzędnego poświadczenia administratora muszą być identyczne jak w klastrze głównym.
Przygotowywanie głównego klastra
Główny klaster musi spełniać powyższe wymagania.
Jeśli chodzi o pierwsze wymaganie, upewnij się, że używasz właściwej wersji PostgreSQL w klastrze głównym i wybrałeś tę samą dla klastra podrzędnego.
$ psql
postgres=# select version();
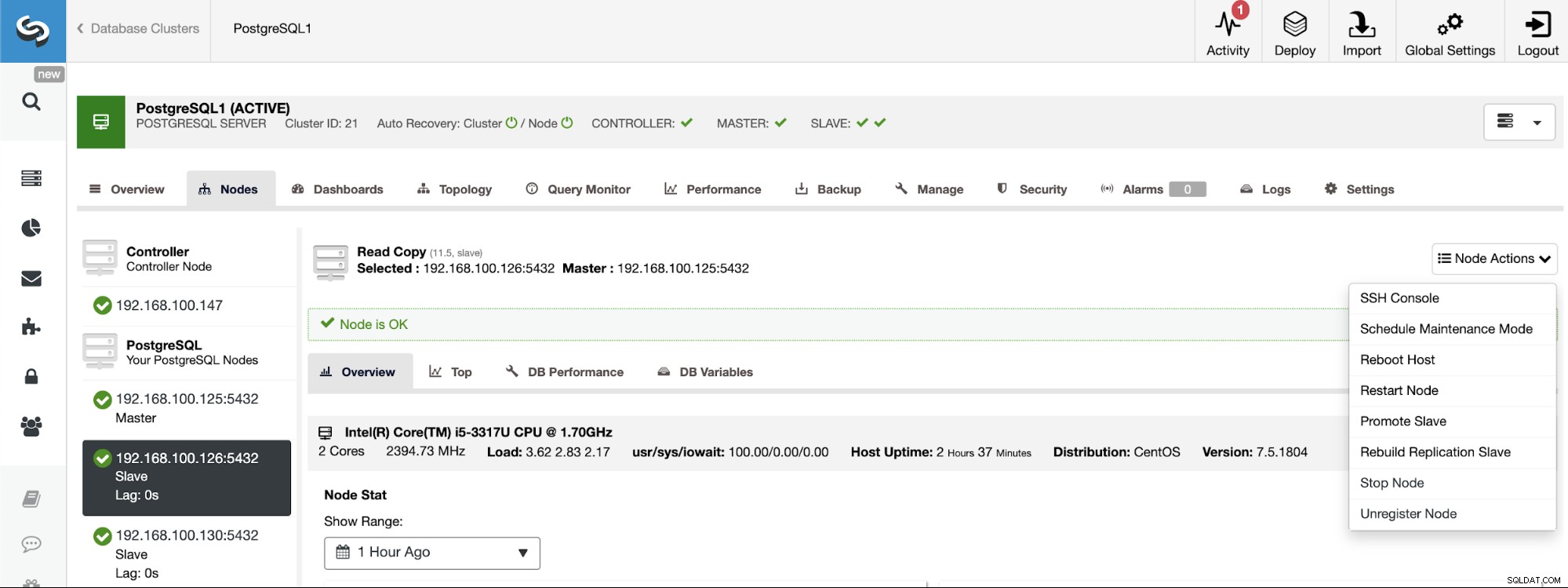
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitJeśli musisz przypisać rolę master do określonego węzła, możesz to zrobić z interfejsu użytkownika ClusterControl. Przejdź do ClusterControl -> Wybierz Master Cluster -> Nodes -> Wybierz Node -> Node Actions -> Promuj Slave.
I na koniec, podczas tworzenia klastra Slave, musisz użyć tego samego administratora poświadczenia, których aktualnie używasz w Master Cluster. Zobaczysz, gdzie go dodać w następnej sekcji.
Tworzenie klastra slave z interfejsu użytkownika ClusterControl
Aby utworzyć nowy klaster Slave, przejdź do ClusterControl -> Wybierz Cluster -> Cluster Actions -> Create Slave Cluster.
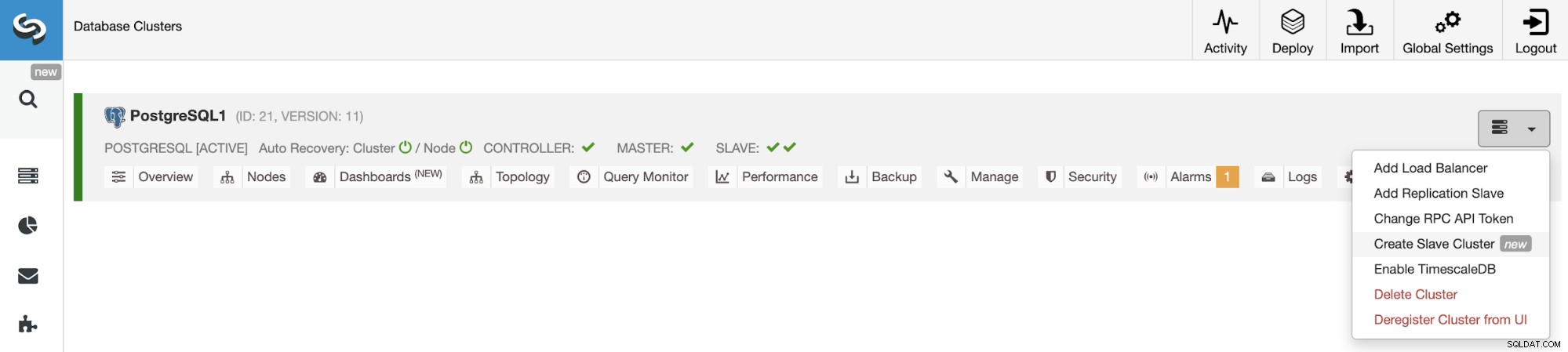
Klaster Slave zostanie utworzony przez strumieniowe przesyłanie danych z bieżącego klastra głównego.
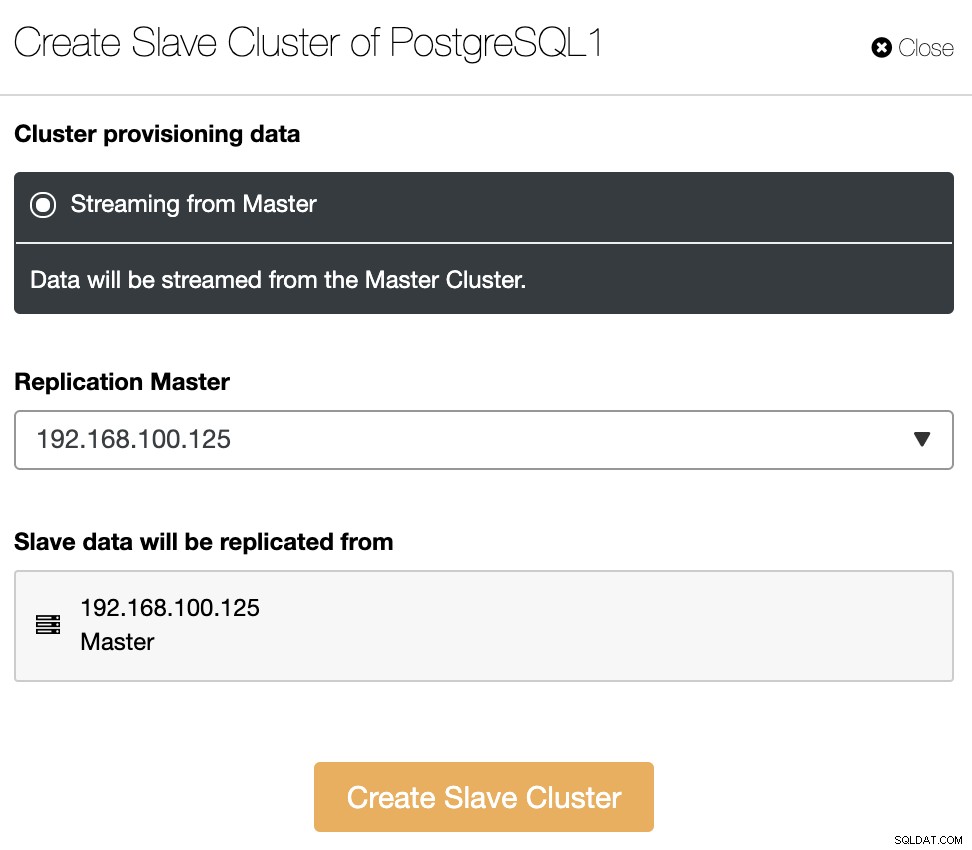
W tej sekcji należy również wybrać węzeł główny bieżącego klastra z którego dane będą replikowane.
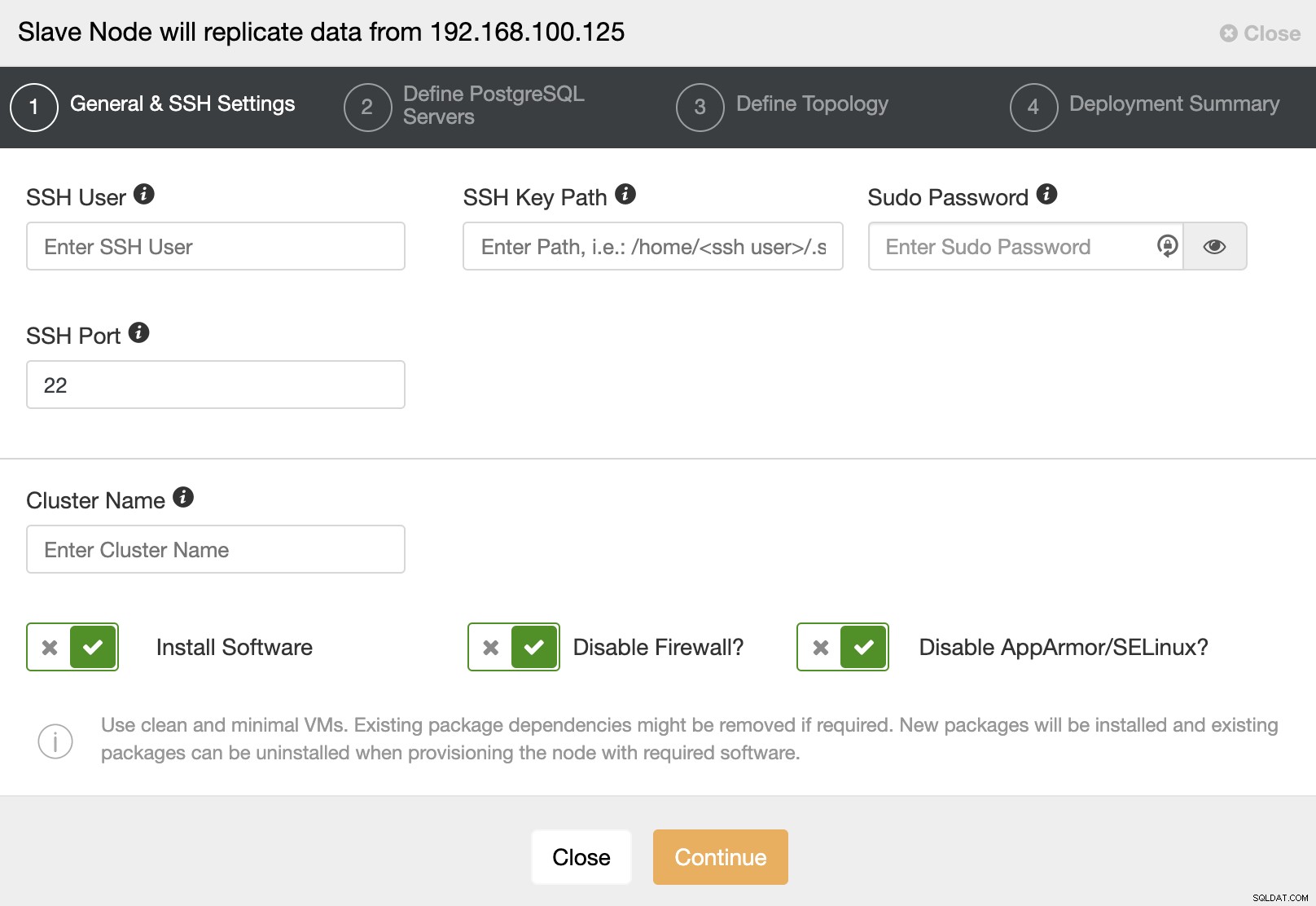
Gdy przejdziesz do następnego kroku, musisz określić Użytkownika, Klucz lub Hasło i port do łączenia się przez SSH z Twoimi serwerami. Potrzebujesz również nazwy dla swojego klastra Slave i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
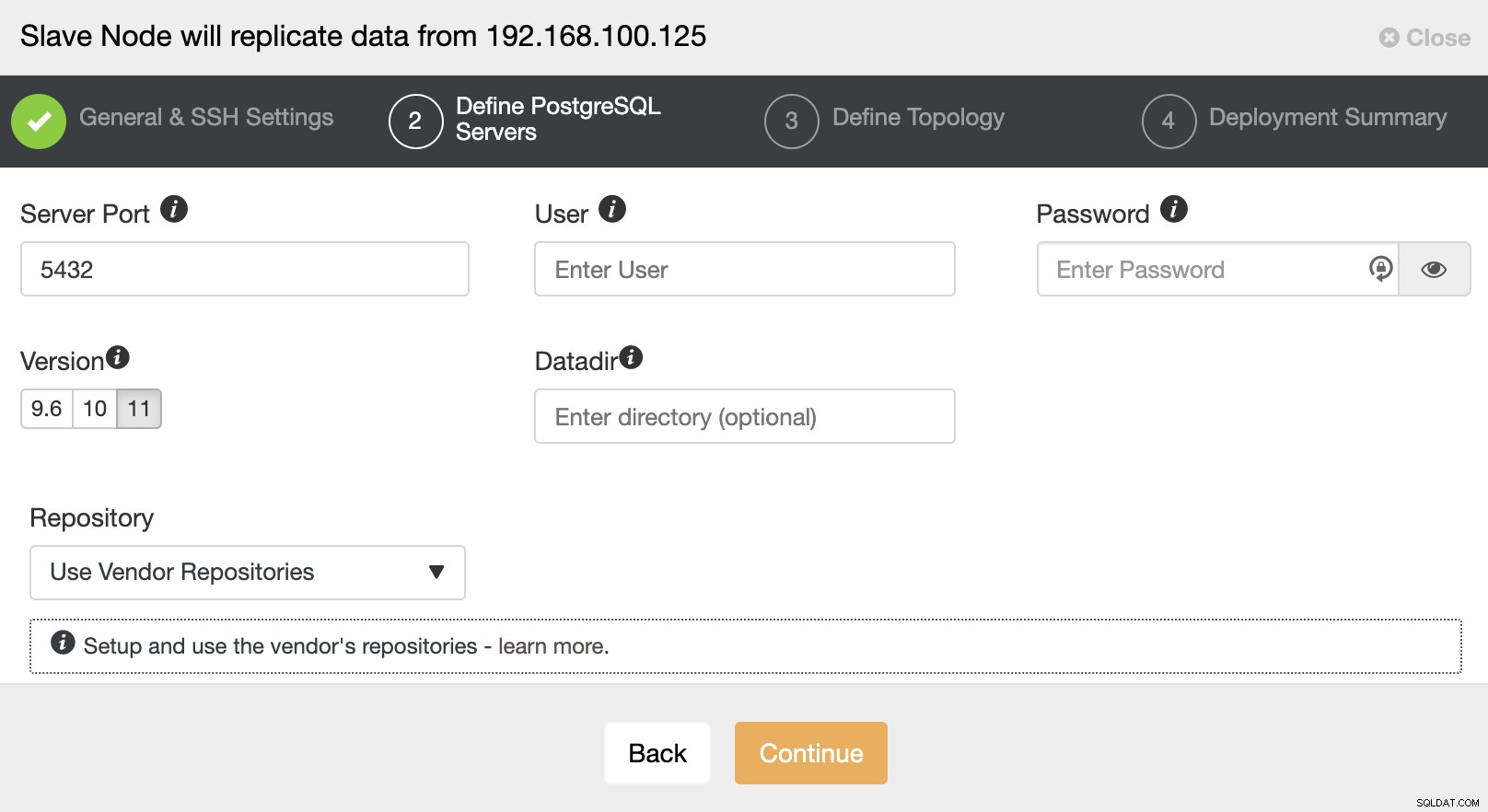
Po skonfigurowaniu informacji dostępowych SSH należy zdefiniować wersję bazy danych, datadir, port i poświadczenia administratora. Ponieważ będzie korzystać z replikacji strumieniowej, upewnij się, że używasz tej samej wersji bazy danych, a jak wspomnieliśmy wcześniej, poświadczenia muszą być takie same, jak używane przez klaster Master. Możesz także określić, którego repozytorium chcesz użyć.
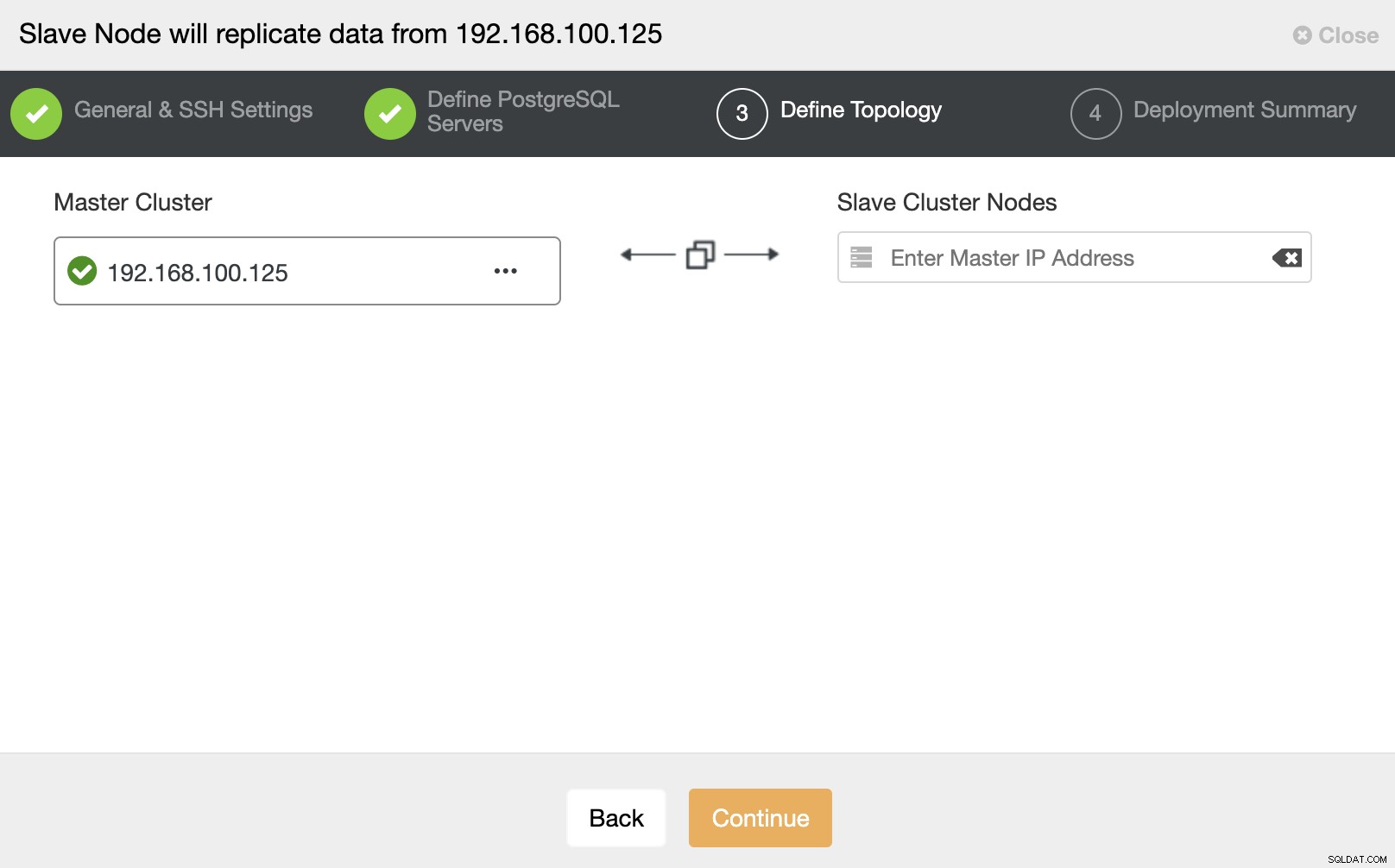
W tym kroku musisz dodać serwer do nowego klastra Slave . W tym zadaniu możesz wprowadzić adres IP lub nazwę hosta węzła bazy danych.
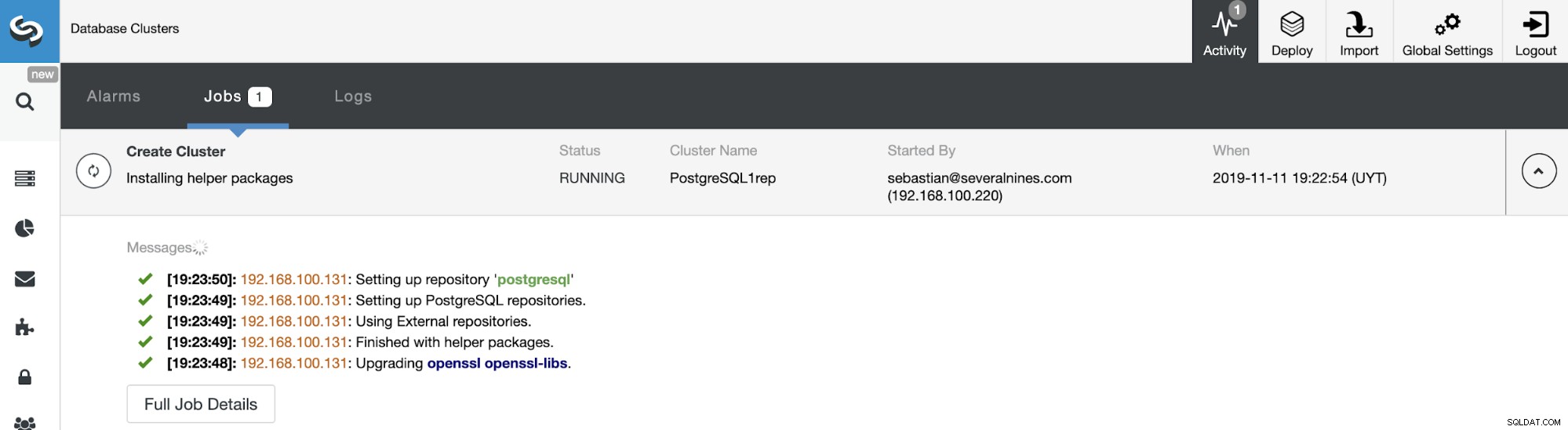
Możesz monitorować stan tworzenia nowego klastra niewolników z poziomu Monitor aktywności ClusterControl. Po zakończeniu zadania możesz zobaczyć klaster na głównym ekranie ClusterControl.
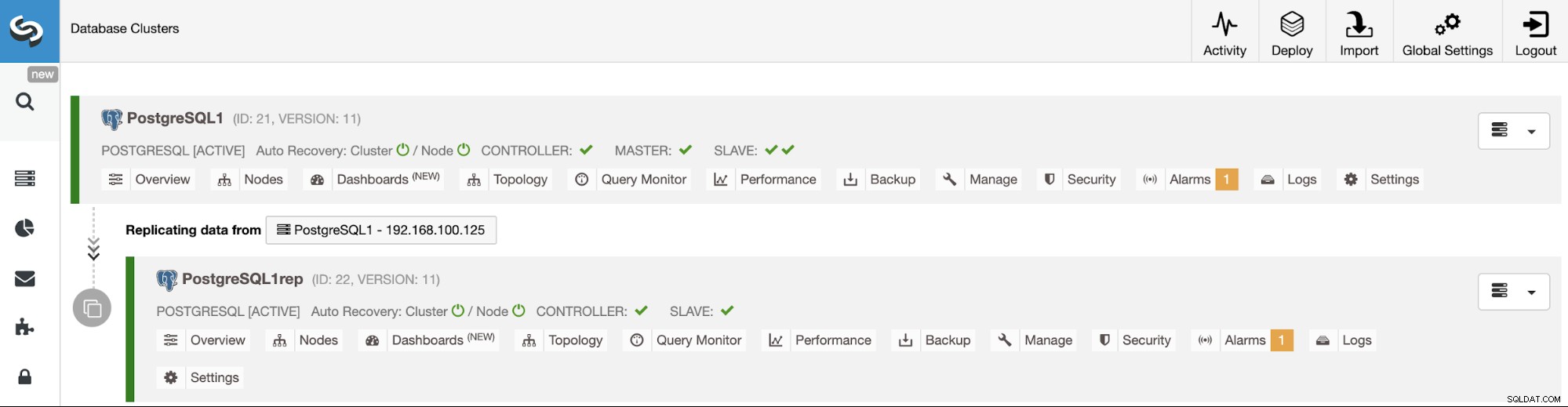
Zarządzanie replikacją między klastrami za pomocą interfejsu użytkownika ClusterControl
Teraz masz już uruchomioną replikację klastrów do klastrów, możesz wykonać różne czynności w tej topologii za pomocą ClusterControl.
Odbudowa klastra niewolników
Aby odbudować klaster podrzędny, przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz węzeł podłączony do klastra głównego -> Akcje węzła -> Odbuduj podrzędny węzeł replikacji.
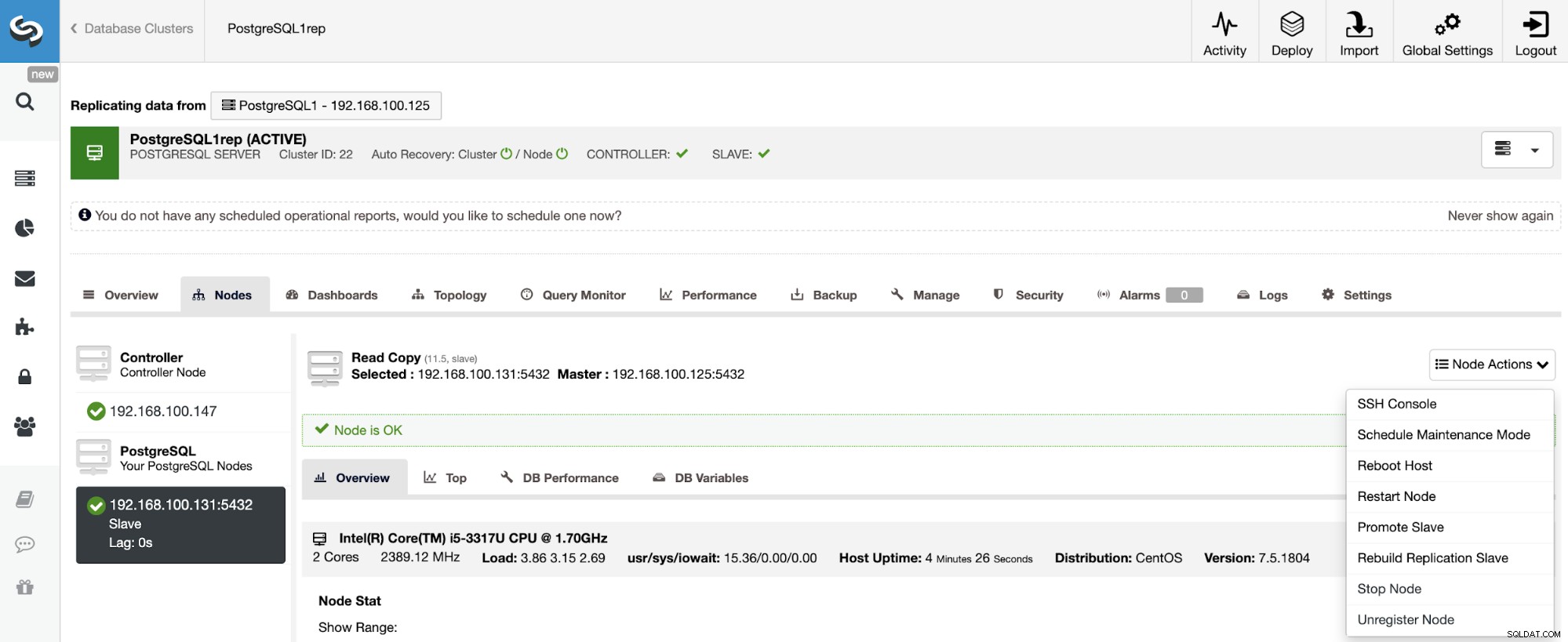
ClusterControl wykona następujące kroki:
- Zatrzymaj serwer PostgreSQL
- Usuń zawartość z katalogu danych
- Przesyłaj strumieniowo kopię zapasową z Master do Slave za pomocą pg_basebackup
- Uruchom Slave
Zatrzymaj/uruchom replikację podrzędną
Zatrzymanie i rozpoczęcie replikacji w PostgreSQL oznacza wstrzymanie i wznowienie jej, ale używamy tych terminów, aby zachować spójność z innymi wspieranymi przez nas technologiami baz danych.
Ta funkcja będzie wkrótce dostępna do użycia z interfejsu użytkownika ClusterControl. Ta akcja użyje funkcji pg_wal_replay_pause i pg_wal_replay_resume PostgreSQL do wykonania tego zadania.
Tymczasem możesz skorzystać z obejścia, aby zatrzymać i uruchomić podrzędne zatrzymywanie replikacji i uruchamianie węzła bazy danych w łatwy sposób za pomocą ClusterControl.
Przejdź do ClusterControl -> Wybierz klaster podrzędny -> Węzły -> Wybierz Węzeł -> Akcje węzła -> Zatrzymaj węzeł/uruchom węzeł. Ta czynność spowoduje bezpośrednie zatrzymanie/uruchomienie usługi bazy danych.
Zarządzanie replikacją między klastrami za pomocą interfejsu wiersza polecenia ClusterControl
W poprzedniej sekcji można było zobaczyć, jak zarządzać replikacją między klastrami za pomocą interfejsu użytkownika ClusterControl. Zobaczmy teraz, jak to zrobić za pomocą wiersza poleceń.
Uwaga:jak wspomnieliśmy na początku tego bloga, założymy, że masz zainstalowany ClusterControl i Master Cluster został wdrożony przy jego użyciu.
Utwórz klaster niewolników
Najpierw spójrzmy na przykładowe polecenie tworzenia klastra podrzędnego za pomocą CLI Control CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logTeraz masz uruchomiony proces tworzenia podrzędnego, zobaczmy każdy użyty parametr:
- Klaster:do wyświetlania i manipulowania klastrami.
- Utwórz:utwórz i zainstaluj nowy klaster.
- Nazwa klastra:nazwa nowego klastra podrzędnego.
- Typ klastra:typ klastra do zainstalowania.
- Wersja dostawcy:Wersja oprogramowania.
- Węzły:Lista nowych węzłów w Klastrze Slave.
- Os-user:nazwa użytkownika dla poleceń SSH.
- Plik klucza systemu operacyjnego:plik klucza używany do połączenia SSH.
- Db-admin:nazwa użytkownika administratora bazy danych.
- Db-admin-passwd:hasło administratora bazy danych.
- Remote-cluster-id:identyfikator głównego klastra dla replikacji klaster-klaster.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Używając flagi --log, będziesz mógł zobaczyć logi w czasie rzeczywistym:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Odbudowa klastra niewolników
Możesz odbudować klaster Slave za pomocą następującego polecenia:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logParametry to:
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Etap:Etapowanie/odbudowa niewolnika replikacji.
- Master:wzorzec replikacji w klastrze głównym.
- Slave:urządzenie podrzędne replikacji w klastrze podrzędnym.
- Identyfikator klastra:identyfikator klastra podrzędnego.
- Remote-cluster-id:identyfikator nadrzędnego klastra.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Dziennik zadań powinien być podobny do tego:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Zatrzymaj/uruchom replikację podrzędną
Jak wspomnieliśmy w sekcji dotyczącej interfejsu użytkownika, zatrzymanie i uruchomienie replikacji w PostgreSQL oznacza wstrzymanie i wznowienie jej, ale używamy tych terminów, aby zachować równoległość z innymi technologiami.
Możesz zatrzymać replikację danych z Master Cluster w ten sposób:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logZobaczysz to:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Teraz możesz zacząć od nowa:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logWięc zobaczysz:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Teraz sprawdźmy używane parametry.
- Replikacja:Do monitorowania i kontrolowania replikacji danych.
- Stop/Start:Aby urządzenie podrzędne zatrzymało/rozpoczęło replikację.
- Slave:węzeł podrzędny replikacji.
- Identyfikator klastra:identyfikator klastra, w którym znajduje się węzeł podrzędny.
- Dziennik:Poczekaj i monitoruj wiadomości o zadaniach.
Wnioski
Ta nowa funkcja ClusterControl pozwoli Ci szybko skonfigurować replikację między różnymi klastrami PostgreSQL oraz zarządzać konfiguracją w łatwy i przyjazny sposób. Zespół programistów Manynines pracuje nad ulepszeniem tej funkcji, więc wszelkie pomysły lub sugestie będą bardzo mile widziane.