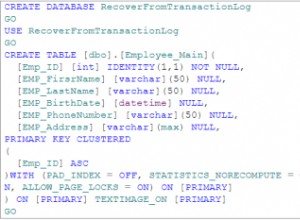
W tej kontynuacji mojej serii „dostrajania wydajności z zawrotną prędkością” chciałbym omówić dyski półprzewodnikowe (SSD) i niektóre problemy, które widzę przy ich użyciu w środowisku SQL Server. Szczegółowy opis dysków SSD można znaleźć w tym artykule w Wikipedii.
Co robią dyski SSD w zakresie wydajności serwera SQL?
Dyski SSD nie mają żadnych ruchomych części, więc gdy następuje odczyt lub zapis, prawie nie ma opóźnień we/wy. Opóźnienie w wirującym dysku wynika z dwóch rzeczy:
- Przesuwanie głowicy dysku na właściwą ścieżkę na powierzchni dysku (tzw. czas wyszukiwania)
- Oczekiwanie, aż dysk obróci się we właściwy punkt na ścieżce (znane jako opóźnienie rotacyjne)
Oznacza to, że dyski SSD zapewniają duży wzrost wydajności, gdy występuje wąskie gardło we/wy.
To takie proste.
Jest trochę komplikacji, o których warto wspomnieć, ale poza zakresem tego artykułu, aby zagłębić się w szczegóły:wydajność dysku SSD może zacząć spadać, gdy dysk jest naprawdę pełny (przeanalizowane i wyjaśnione szczegółowo w tym artykule od AnandTech). Może być również wymagana pewna pamięć systemowa dla sterownika SSD, aby pomóc w niwelowaniu zużycia (przedłużając żywotność komórek NAND na dysku SSD), a to będzie się różnić w zależności od dostawcy. Dość tego – wracając do rzeczy SQL Server.
Unikaj złych porad internetowych
Są dwie bardzo kiepskie rady, które widzę w Internecie na temat SQL Server i dysków SSD.
Pierwsza dotyczy tego, co umieścić na dysku SSD, gdzie rada jest taka, aby zawsze umieszczać tempdb i dzienniki transakcji na dyskach SSD. Na pierwszy rzut oka brzmi to jak dobra rada, ponieważ dzienniki transakcji i tempdb są często wąskimi gardłami w systemie.
Ale co, jeśli nie są?
Twoje obciążenie może być głównie do odczytu, w którym to przypadku dziennik transakcji prawdopodobnie nie będzie wąskim gardłem obciążenia, a więc umieszczenie go na dysku SSD może być marnowaniem drogiego dysku SSD.
Twoja baza danych tempdb może nie być używana zbyt często według obciążenia, więc umieszczenie go na dysku SSD może być stratą drogiego dysku SSD.
Gdy zastanawiasz się, którą część środowiska SQL Server przenieść na dysk SSD, chcesz zbadać, gdzie znajdują się wąskie gardła we/wy. Można to zrobić bardzo łatwo, korzystając z kodu, który opublikowałem w zeszłym tygodniu, który używa DMV sys.dm_io_virtual_file_stats, aby zapewnić migawkę opóźnień we/wy dla wszystkich plików we wszystkich bazach danych w instancji. Aby zrozumieć liczby opóźnień i porównać je z dobrymi/złymi wartościami, przeczytaj ten długi post, który zrobiłem w szczególności na temat opóźnień we/wy tempdb i dziennika transakcji.
A potem, nawet jeśli masz duże opóźnienia, nie szarpnij się i pomyśl, że jedynym rozwiązaniem jest przeniesienie słabo działających plików na dysk SSD:
- W przypadku opóźnień odczytu plików danych sprawdź, dlaczego występuje tak wiele odczytów. Omówię to tutaj.
- W przypadku opóźnień zapisu w plikach dziennika rozważ wszystkie sposoby dostosowania wydajności dziennika i tego, co jest rejestrowane. Omówię to tutaj, tutaj i tutaj.
Najgorszy możliwy przypadek to taki, w którym otrzymujesz kilka dysków SSD, postępuj zgodnie z poradami internetowymi, aby przenieść do nich tempdb i pliki dziennika, a wtedy nie ma wzrostu wydajności obciążenia. To nie zachęci kierownictwa do dostarczania droższych dysków SSD.
Druga słaba rada dotyczy fragmentacji indeksu, gdzie rada jest taka, że ponieważ dyski SSD są tak szybkie, nie musisz się martwić o fragmentację indeksu podczas korzystania z dysków SSD.
Co za bzdury!
Istnieją trzy sposoby na odrzucenie tej złej rady:
- Dyski SSD w żaden sposób nie zatrzymują przyczyny fragmentacji indeksu:strona dzieli się na strony wymagające wolnego miejsca na losowe wstawienie lub zwiększenie rozmiaru wiersza. Podział strony generuje taką samą ilość dziennika transakcji, wykorzystania zasobów i potencjalnego oczekiwania wątku, niezależnie od tego, gdzie przechowywane są pliki danych/logów.
- Fragmentacja indeksu obejmuje posiadanie wielu stron danych/indeksów o niskiej gęstości stron (tj. Dużo pustego, wolnego miejsca). Czy naprawdę chcesz, aby twoje drogie dyski SSD przechowywały dużo pustej przestrzeni? Dyski SSD w ogóle nie pomagają.
- Mój kolega Jonathan Kehayias przeprowadził dogłębne badanie wzorców we/wy wokół fragmentacji indeksu, używając zdarzeń rozszerzonych, specjalnie w celu rozwiązania tej złej rady i stwierdził, że nadal występuje spadek wydajności wynikający z fragmentacji indeksu podczas korzystania z dysków SSD. Możesz przeczytać jego długi post tutaj.
Jedyną rzeczą, jaką dyski SSD robią wokół fragmentacji indeksu, jest przyspieszenie odczytu, dzięki czemu skanowanie zakresu indeksów jest mniejsze, gdy występuje fragmentacja indeksu, ale punkt 3 powyżej pokazuje, że nadal istnieje kara.
Dyski SSD nie zmieniają sposobu radzenia sobie z fragmentacją indeksu i/lub zapobiegają jej fragmentacji w środowisku SQL Server.
Upewnij się, że chronisz swoje dane
Jednym z głównych grzechów, które widzę, że ludzie popełniają przy użyciu dysków SSD, jest używanie tylko jednego z nich. Z tylko jednym dyskiem, jakiego poziomu RAID używasz? Zero. RAID-0 nie zapewnia żadnej redundancji.
Jeśli zamierzasz używać dysku SSD, musisz użyć co najmniej dwóch w konfiguracji RAID-1 (dublowanie). Nie ma sensu zwiększać wydajności, jeśli w zamian poświęcasz dostępność systemu.
Jednym naciskiem, który czasami zdarza mi się używać co najmniej dwóch dysków SSD, jest to, że karta SSD zapewnia dwa dyski do systemu Windows, a więc z pewnością utworzenie woluminu lustrzanego systemu Windows na dwóch dyskach jest takie samo, jak RAID-1 na dwóch fizycznie oddzielnych dyskach SSD?
Nie, nie jest. To wciąż jeden fizyczny dysk SSD, bez nadmiarowości. Czy kiedykolwiek widziałeś awarię połowy karty SSD? Nie, ja też nie. Zrób to dobrze i użyj dwóch z nich i uzyskaj prawdziwą redundancję dla swoich danych.
Drugim odepchnięciem, jakie otrzymuję, jest to, że są to dyski SSD, a nie dyski obrotowe, więc nie zawiedzią. To jest źle. Dyski SSD mogą i zawodzą, podobnie jak dyski wirujące. Osobiście widziałem, jak dwa dyski SSD klasy korporacyjnej zawiodły podczas testów w naszym środowisku laboratoryjnym. Zgodnie z tym artykułem na stronie StorageReview.com, dyski SSD klasy konsumenckiej mają współczynnik MTBF wynoszący 2 miliony godzin w porównaniu do 1,5 miliona godzin w przypadku dysków wirujących klasy konsumenckiej, i spodziewałbym się podobnych wyników w przypadku dysków klasy korporacyjnej, ale dyski SSD zawodzą.
Podsumowanie
Nie wpadaj w pułapkę myślenia, że cokolwiek założysz na dysk SSD, oznacza to, że uzyskasz wzrost wydajności – musisz wybierać ostrożnie. I nie wierz w bzdury o ignorowaniu fragmentacji indeksu podczas korzystania z dysków SSD.
Dyski SSD są bardzo przydatnym sposobem na zwiększenie wydajności, ale ze względu na ich koszt, chcesz mieć pewność, że maksymalizujesz zwrot z inwestycji firmy, używając ich prawidłowo i tylko tam, gdzie jest to właściwe.
W następnym artykule z tej serii omówię kolejną częstą przyczynę gwałtownego dostrajania wydajności. Do tego czasu życzę miłego rozwiązywania problemów!