Często widzę, jak ludzie zmagają się z SQL Server, gdy widzą dwa różne plany wykonania dla tego, co uważają za to samo zapytanie. Zwykle odkrywa się to po innych obserwacjach, takich jak bardzo różne czasy wykonania. Mówię, że wierzą, że to to samo zapytanie, ponieważ czasami tak jest, a czasami nie.
Jednym z najczęstszych przypadków jest testowanie zapytania w programie SSMS i uzyskiwanie innego planu niż ten, który otrzymują z ich aplikacji. W grę wchodzą potencjalnie dwa czynniki (które mogą być również istotne, gdy porównanie NIE dotyczy aplikacji i SSMS):
- Aplikacja prawie zawsze ma inny
SETustawienia niż SSMS (są to rzeczy takie jakARITHABORT,ANSI_NULLSiQUOTED_IDENTIFIER). Zmusza to SQL Server do oddzielnego przechowywania dwóch planów; Erland Sommarskog omówił to bardzo szczegółowo w swoim artykule Wolno w aplikacji, szybko w SSMS?
- Parametry używane przez aplikację podczas pierwszej kompilacji jej planu mogły być bardzo różne i prowadzić do innego planu niż te użyte przy pierwszym uruchomieniu zapytania z SSMS – jest to znane jako sniffing parametrów . Erland też mówi o tym dogłębnie i nie zamierzam wyrzucać jego zaleceń, ale podsumowując, przypominając, że testowanie zapytania aplikacji w SSMS nie zawsze jest przydatne, ponieważ jest to mało prawdopodobne, aby był to test typu „jabłka na jabłka”. /li>
Istnieje kilka innych, nieco bardziej niejasnych scenariuszy, które poruszam w moim przemówieniu o Złych nawykach i najlepszych praktykach. Są to przypadki, w których plany nie różnią się, ale istnieje wiele kopii tego samego planu, które powiększają pamięć podręczną planu. Pomyślałem, że powinienem o nich tutaj wspomnieć, ponieważ zawsze zaskakują tak wielu ludzi.
CASE i białe znaki są ważne
SQL Server miesza tekst zapytania do formatu binarnego, co oznacza, że każdy znak w tekście zapytania ma kluczowe znaczenie. Weźmy następujące proste zapytania:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO SELECT StoreID FROM Sales.Customer; GO -- original query GO SELECT StoreID FROM Sales.Customer; GO ----^---- extra space GO SELECT storeid FROM sales.customer; GO ---- lower case names GO select StoreID from Sales.Customer; GO ---- lower case keywords GO
Generują one oczywiście dokładnie te same wyniki i generują dokładnie ten sam plan. Jeśli jednak spojrzymy na to, co mamy w pamięci podręcznej planu:
SELECT t.[text], p.size_in_bytes, p.usecounts FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t WHERE LOWER(t.[text]) LIKE N'%sales'+'.'+'customer%';
Wyniki są niefortunne:
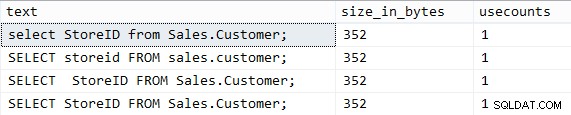
Tak więc w tym przypadku jasne jest, że wielkość liter i białe znaki są bardzo ważne. Mówiłem o tym bardziej szczegółowo w maju.
Odwołania do schematów są ważne
Pisałem wcześniej na blogu o tym, jak ważne jest określanie prefiksu schematu podczas odwoływania się do dowolnego obiektu, ale w tamtym czasie nie byłem w pełni świadomy, że ma to również wpływ na pamięć podręczną planu.
Przyjrzyjmy się bardzo prostemu przypadkowi, w którym mamy dwóch użytkowników z różnymi domyślnymi schematami, którzy uruchamiają dokładnie ten sam tekst zapytania, nie odwołując się do obiektu za pomocą jego schematu:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO CREATE USER SQLPerf1 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Sales; CREATE USER SQLPerf2 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Person; GO CREATE TABLE dbo.AnErrorLog(id INT); GRANT SELECT ON dbo.AnErrorLog TO SQLPerf1, SQLPerf2; GO EXECUTE AS USER = N'SQLPerf1'; GO SELECT id FROM AnErrorLog; GO REVERT; GO EXECUTE AS USER = N'SQLPerf2'; GO SELECT id FROM AnErrorLog; GO REVERT; GO
Teraz, jeśli spojrzymy na pamięć podręczną planu, możemy pobrać sys.dm_exec_plan_attributes aby dokładnie zobaczyć, dlaczego otrzymujemy dwa różne plany dla identycznych zapytań:
SELECT t.[text], p.size_in_bytes, p.usecounts, [schema_id] = pa.value, [schema] = s.name FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS pa INNER JOIN sys.schemas AS s ON s.[schema_id] = pa.value WHERE t.[text] LIKE N'%AnError'+'Log%' AND pa.attribute = N'user_id';
Wyniki:

A jeśli uruchomisz to wszystko ponownie, ale dodasz dbo. prefiksu do obu zapytań, zobaczysz, że jest tylko jeden plan, który jest używany dwukrotnie. Staje się to bardzo przekonującym argumentem, aby zawsze w pełni odwoływać się do obiektów.
Zmiana ustawień SET
Na marginesie, możesz użyć podobnego podejścia do określenia, czy SET ustawienia są różne dla co najmniej dwóch wersji tego samego zapytania. W tym przypadku badamy zapytania związane z wieloma planami wygenerowanymi przez różne wywołania tej samej procedury składowanej, ale można je również zidentyfikować na podstawie tekstu zapytania lub skrótu zapytania.
SELECT p.plan_handle, p.usecounts, p.size_in_bytes, set_options = MAX(a.value) FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS a WHERE t.objectid = OBJECT_ID(N'dbo.procedure_name') AND a.attribute = N'set_options' GROUP BY p.plan_handle, p.usecounts, p.size_in_bytes;
Jeśli masz tutaj wiele wyników, powinieneś zobaczyć różne wartości dla set_options (co jest maską bitową). To dopiero początek; Zamierzam wyskoczyć tutaj i powiedzieć, że możesz określić, jaki zestaw opcji jest włączony dla każdego planu, rozpakowując wartość zgodnie z sekcją „Ocenianie opcji zestawu”. Tak, jestem taki leniwy.
Wniosek
Istnieje kilka powodów, dla których możesz zobaczyć różne plany dla tego samego zapytania (lub tego, co uważasz za to samo zapytanie). W większości przypadków przyczynę można dość łatwo wyizolować; wyzwaniem jest często wiedza, aby go najpierw poszukać. W następnym poście poruszę nieco inny temat:dlaczego baza danych przywrócona na „identyczny” serwer może dać różne plany dla tego samego zapytania.



