Wcześniej omówiłem podstawy metryk i testowania podsystemów pamięci masowej w moim artykule Analiza wydajności podsystemu we/wy dla SQL Server, w tym wprowadzenie CrystalDiskMark 4.0. CrystalDiskMark został niedawno przepisany, aby używać Microsoft DiskSpd do testowania, co czyni go jeszcze bardziej wartościowym narzędziem do początkowych testów podsystemu pamięci masowej. DiskSpd zapewnia funkcjonalność niezbędną do generowania szerokiej gamy wzorców żądań dysków, co może być bardzo pomocne w diagnozowaniu i analizie problemów z wydajnością we/wy z dużo większą elastycznością niż starsze narzędzia testowe, takie jak SQLIO. Jest to niezwykle przydatne do testowania syntetycznych podsystemów pamięci masowej, gdy chcesz uzyskać wyższy poziom kontroli niż ten dostępny w CrystalDiskMark.
Teraz zagłębimy się nieco w to, jak faktycznie używać Microsoft DiskSpd do testowania podsystemu pamięci masowej bez użycia CrystalDiskMark 4.0. Aby to zrobić, musisz pobrać i rozpakować DiskSpd. Aby to ułatwić, zawsze kopiuję żądany plik wykonywalny diskspd.exe z odpowiedniego folderu wykonywalnego (amd64fre, armfre lub x86fre) do krótkiej, prostej ścieżki, takiej jak C:\DiskSpd . W większości przypadków będziesz potrzebować 64-bitowej wersji DiskSpd z folderu amd64fre.
Po udostępnieniu pliku wykonywalnego diskspd.exe należy otworzyć wiersz poleceń z uprawnieniami administratora (wybierając „Uruchom jako administrator”), a następnie przejść do katalogu, do którego skopiowano plik diskspd.exe.
Oto niektóre parametry wiersza poleceń, od których będziesz chciał zacząć:
| Parametr | Opis |
| -b | Rozmiar bloku we/wy określony jako (K/M/G). Na przykład –b8K oznacza rozmiar bloku 8KB, co jest istotne dla SQL Server |
| -d | Czas trwania testu w sekundach. Testy trwające 30-60 sekund są zwykle wystarczająco długie, aby uzyskać prawidłowe wyniki |
| -o | Wyjątkowe operacje we/wy (co oznacza głębokość kolejki) na cel, na wątek roboczy |
| -t | Wątki robocze na docelowy plik testowy |
| -h | Wyłącz buforowanie oprogramowania na poziomie systemu operacyjnego i sprzętowe buforowanie zapisu, co jest dobrym pomysłem do testowania SQL Server |
| -r | Flaga losowa lub sekwencyjna. Jeśli użyto –r, wykonywane są testy losowe, w przeciwnym razie wykonywane są testy sekwencyjne |
| -w | Procent zapisu. Na przykład –w25 oznacza 25% zapisuje, 75% czyta |
| -Z | Rozmiar bufora źródła zapisu testu obciążenia określony jako (K/M/G). Służy do dostarczania losowych danych do zapisów, co jest dobrym pomysłem do testowania SQL Server |
| -L | Przechwytywanie informacji o opóźnieniach podczas testu, co jest bardzo dobrym pomysłem do testowania SQL Server |
| -c | Tworzy plik(i) obciążenia o określonym rozmiarze, określonym jako (K/M/G) |
Tabela 1:Podstawowe parametry wiersza poleceń dla DiskSpd
Będziesz także chciał określić lokalizację pliku testowego i nazwę pliku wyników na końcu wiersza. Oto przykładowa linia poleceń:
diskspd –b8K –d30 –o4 –t8 –h –r –w25 –L –Z1G –c20G T:\iotest.dat> DiskSpeedResults.txtTen przykładowy wiersz poleceń uruchomi 30-sekundowy losowy test we/wy przy użyciu pliku testowego o wielkości 20 GB znajdującego się na dysku T:, ze współczynnikiem zapisu 25% i odczytu 75%, z rozmiarem bloku 8K. Wykorzysta osiem wątków roboczych, każdy z czterema zaległymi operacjami we/wy i zalążkiem wartości entropii zapisu 1 GB. Wyniki testu zostaną zapisane w pliku tekstowym o nazwie DiskSpeedResults.txt. To całkiem niezły zestaw parametrów dla obciążenia SQL Server OLTP.
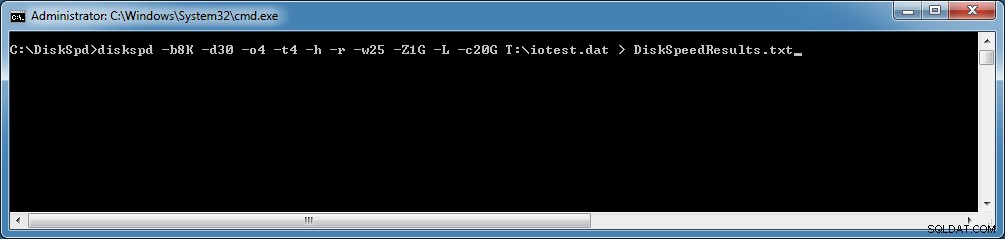 Rysunek 1:Przykładowy wiersz poleceń dla DiskSpd
Rysunek 1:Przykładowy wiersz poleceń dla DiskSpd
Przeprowadzenie testu rozpoczyna się z domyślnym pięciosekundowym czasem nagrzewania (przed faktycznym rozpoczęciem jakichkolwiek pomiarów), a następnie rzeczywisty test będzie wykonywany przez określony czas w sekundach z domyślnym czasem ochładzania równym zero sekund. Po zakończeniu testu DiskSpd przedstawi opis testu i szczegółowe wyniki. Domyślnie będzie to proste podsumowanie tekstowe w pliku tekstowym o podanej nazwie pliku, który będzie znajdował się w tym samym katalogu, co plik wykonywalny diskspd.
Oto, jak wyglądają wyniki tego konkretnego testu uruchomionego na mojej stacji roboczej.
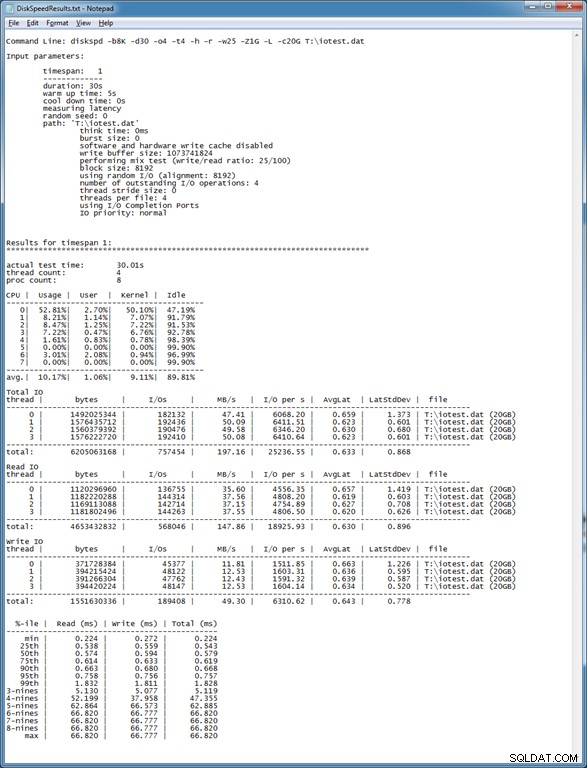 Rysunek 2:Przykładowe wyniki testu DiskSpd
Rysunek 2:Przykładowe wyniki testu DiskSpd
Pierwsza sekcja wyników podaje dokładną linię poleceń, która została użyta do testu, a następnie określa wszystkie parametry wejściowe, które zostały użyte do uruchomienia testu (w tym wartości domyślne, które mogły nie zostać określone w rzeczywistym wierszu poleceń ). Następnie wyświetlane są wyniki testu, zaczynając od rzeczywistego czasu testu, liczby wątków i liczby procesorów logicznych. Sekcja CPU pokazuje wykorzystanie procesora dla każdego procesora logicznego, w tym czas użytkownika i jądra, dla interwału testu.
Kolejna jest ciekawsza część wyników testu. Otrzymasz całkowitą liczbę bajtów, całkowitą liczbę operacji we/wy, MB/sekundę, operacje we/wy na sekundę (IOPS) oraz średnie opóźnienie w milisekundach. Te wyniki są podzielone dla każdego wątku (cztery w naszym przypadku), z oddzielnymi sekcjami w wynikach dla Total IO, Read IO i Write IO. Wyniki dla każdego wątku powinny być w większości przypadków bardzo podobne. Zamiast początkowo skupiać się na wartościach bezwzględnych dla każdego pomiaru, lubię porównywać wartości, gdy przeprowadzam ten sam test na różnych dyskach logicznych (po zmianie lokalizacji pliku testowego w wierszu poleceń), co pozwala porównać wydajność dla każdego dysku logicznego.
Jeszcze ciekawsza jest ostatnia część wyników testu. Pokazuje analizę percentylową rozkładu wyników testu latencji, począwszy od wartości minimalnej w milisekundach do maksymalnej wartości w milisekundach, z podziałem na odczyty, zapisy i całkowite opóźnienie. „Dziewiątki” w kolumnie %-ile odnoszą się do liczby dziewiątek, gdzie 3-dziewiątki oznaczają 99,9, 4-dziewiątki oznacza 99,99 itd. Powodem, dla którego wartości w rzędach z wyższym percentylem są takie same, jest to, że ten test miał stosunkowo mała liczba operacji ogółem. Jeśli chcesz dokładnie scharakteryzować wyższe percentyle, będziesz musiał przeprowadzić test o dłuższym czasie trwania, który wygeneruje większą liczbę oddzielnych operacji we/wy.
To, czego chcesz szukać w tych wynikach, to punkt, w którym wartości robią duży skok. Na przykład w tym teście widzimy, że 99% odczytów miało opóźnienie wynoszące 1,832 milisekundy lub mniej.
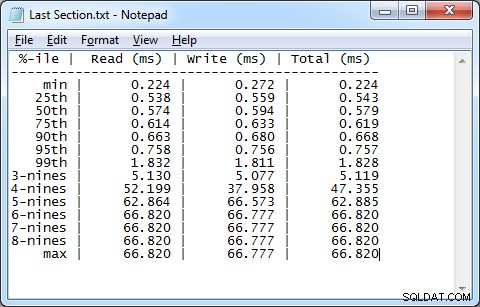 Rysunek 3:Rozkład wyników opóźnień
Rysunek 3:Rozkład wyników opóźnień
Jak widać, uruchamianie DiskSpd jest w rzeczywistości całkiem proste, gdy zrozumiesz, co oznaczają podstawowe parametry i jak są używane. DiskSpd można uruchomić nie tylko ze staromodnego wiersza poleceń, ale także uruchomić go za pomocą PowerShell. DiskSpd zapewnia również o wiele bardziej szczegółowe informacje niż te, które otrzymujesz z SQLIO. Bardziej skomplikowaną częścią korzystania z DiskSpd jest analiza i interpretacja wyników, o czym opowiem w przyszłym artykule.