W styczniu 2015 roku mój dobry przyjaciel i kolega MVP SQL Server, Rob Farley, napisał o nowatorskim rozwiązaniu problemu znajdowania mediany w wersjach SQL Server sprzed 2012 roku. świetny przykład do wykorzystania w celu zademonstrowania zaawansowanej analizy planu wykonania i podkreślenia pewnych subtelnych zachowań optymalizatora zapytań i silnika wykonywania.
Pojedyncza mediana
Chociaż artykuł Roba skupia się w szczególności na obliczeniu zgrupowanej mediany, zacznę od zastosowania jego metody do dużego problemu z pojedynczą medianą, ponieważ najdobitniej podkreśla ona najważniejsze kwestie. Przykładowe dane będą ponownie pochodzić z oryginalnego artykułu Aarona Bertranda:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Zastosowanie techniki Roba Farleya do tego problemu daje następujący kod:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Jak zwykle skomentowałem liczenie wierszy w tabeli i zastąpiłem je stałą, aby uniknąć źródła wariancji wydajności. Plan wykonania ważnego zapytania jest następujący:

To zapytanie trwa 5800ms na moim komputerze testowym.
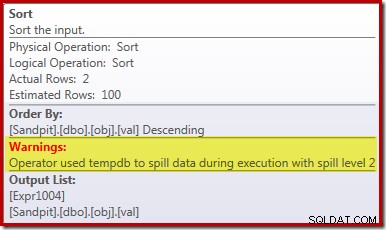
Wyciek sortowania
Główna przyczyna tej słabej wydajności powinna być jasna, patrząc na powyższy plan wykonania:ostrzeżenie operatora Sort pokazuje, że niewystarczający przydział pamięci obszaru roboczego spowodował rozlanie poziomu 2 (wieloprzebiegowego) do fizycznego pliku tempdb dysk:
W wersjach programu SQL Server sprzed 2012 r. trzeba by oddzielnie monitorować zdarzenia rozlania sortowania, aby to zobaczyć. W każdym razie niewystarczająca rezerwacja pamięci sortowania jest spowodowana błędem oszacowania liczności, jak pokazuje plan przed wykonaniem (szacowany):

Szacunkowa liczność dla 100 wierszy na wejściu Sort to (dziko niedokładne) odgadnięcie przez optymalizator, ze względu na lokalne wyrażenie zmiennej w poprzednim operatorze Top:

Należy zauważyć, że ten błąd oszacowania kardynalności nie jest problemem związanym z celami rzędu. Zastosowanie flagi śledzenia 4138 usunie efekt wiersz-cel poniżej pierwszego Top, ale oszacowanie post-Top nadal będzie zgadywać 100 wierszy (więc rezerwacja pamięci dla sortowania nadal będzie zbyt mała):

Wskazówka na wartość zmiennej lokalnej
Istnieje kilka sposobów rozwiązania tego problemu z oszacowaniem kardynalności. Jedną z opcji jest użycie podpowiedzi w celu dostarczenia optymalizatorowi informacji o wartości przechowywanej w zmiennej:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Użycie podpowiedzi poprawia wydajność do 3250 ms od 5800 ms. Z planu powykonawczego wynika, że sortowanie już się nie rozlewa:

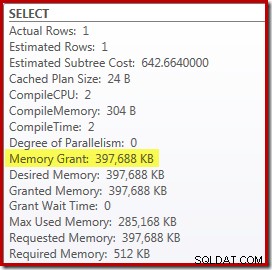
Jest to jednak kilka wad. Po pierwsze, ten nowy plan wykonania wymaga 388 MB przyznanie pamięci – pamięć, która w innym przypadku mogłaby być wykorzystana przez serwer do buforowania planów, indeksów i danych:
Po drugie, może być trudno wybrać dobrą liczbę dla podpowiedzi, która będzie dobrze działać we wszystkich przyszłych wykonaniach, bez niepotrzebnego rezerwowania pamięci.
Zauważ również, że musieliśmy wskazać wartość zmiennej, która jest o 10% wyższa niż rzeczywista wartość zmiennej, aby całkowicie wyeliminować wyciek. Nie jest to rzadkie, ponieważ ogólny algorytm sortowania jest bardziej złożony niż proste sortowanie w miejscu. Rezerwowanie pamięci równej rozmiarowi sortowanego zestawu nie zawsze (a nawet ogólnie) wystarczy, aby uniknąć rozlania w czasie wykonywania.
Osadzanie i ponowna kompilacja
Inną opcją jest skorzystanie z Optymalizacji osadzania parametrów włączonej przez dodanie wskazówki dotyczącej ponownej kompilacji na poziomie zapytania w programie SQL Server 2008 SP1 CU5 lub nowszym. Ta czynność pozwoli optymalizatorowi zobaczyć wartość zmiennej w czasie wykonywania i odpowiednio zoptymalizować:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Skraca to czas wykonania do 3150ms – 100 ms lepiej niż przy użyciu OPTIMIZE FOR wskazówka. Powód tej dalszej niewielkiej poprawy można dostrzec w nowym planie powykonawczym:

Wyrażenie (2 – @Count % 2) – jak widzieliśmy wcześniej w drugim napędzie Top – można go teraz złożyć do jednej znanej wartości. Przepisywanie po optymalizacji może następnie połączyć Top z sortowaniem, co daje w wyniku pojedyncze sortowanie Top N. To przepisanie nie było wcześniej możliwe, ponieważ zwijanie Top + Sort do Top N Sort działa tylko ze stałą wartością literału Top (nie zmiennymi lub parametrami).
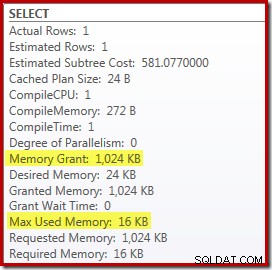
Zastąpienie Topu i sortowania sortowaniem Top N ma niewielki korzystny wpływ na wydajność (tutaj 100 ms), ale prawie całkowicie eliminuje wymagania dotyczące pamięci, ponieważ sortowanie Top N musi tylko śledzić N najwyższych (lub najniższych) rzędy, a nie cały zestaw. W wyniku tej zmiany algorytmu plan wykonania dla tego zapytania pokazuje, że minimum 1 MB pamięć była zarezerwowana dla Top N Sort w tym planie i tylko 16 KB był używany w czasie wykonywania (pamiętaj, że plan pełnego sortowania wymagał 388 MB):
Unikanie ponownej kompilacji
(Oczywistą) wadą korzystania z podpowiedzi dotyczącej kwerendy dotyczącej rekompilacji jest to, że wymaga ona pełnej kompilacji przy każdym wykonaniu. W tym przypadku obciążenie jest dość małe – około 1 ms czasu procesora i 272 KB pamięci. Mimo to istnieje sposób na ulepszenie zapytania tak, aby uzyskać korzyści z sortowania według Top N bez używania podpowiedzi i bez ponownej kompilacji.
Pomysł pochodzi z rozpoznania, że maksymalna dwóch rzędów będzie wymagane do ostatecznego obliczenia mediany. Może to być jeden wiersz lub dwa w czasie wykonywania, ale nigdy więcej. Ten wgląd oznacza, że możemy dodać logicznie nadmiarowy górny (2) krok pośredni do zapytania w następujący sposób:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Nowy Top (z najważniejszym literałem stałym) oznacza, że ostateczny plan wykonania zawiera żądany operator Top N Sort bez ponownej kompilacji:

Wydajność tego planu wykonania pozostaje niezmieniona w stosunku do wersji ze wskazaną rekompilacją przy 3150ms a wymagania dotyczące pamięci są takie same. Należy jednak pamiętać, że brak osadzania parametrów oznacza, że oszacowania kardynalności poniżej sortowania są domysłami 100-wierszowymi (chociaż nie ma to wpływu na wydajność).
Głównym wnioskiem na tym etapie jest to, że jeśli chcesz sortować z małą ilością pamięci Top N, musisz użyć stałego literału lub umożliwić optymalizatorowi zobaczenie literału poprzez optymalizację osadzania parametrów.
Skalar obliczeniowy
Eliminacja 388 MB Przyznanie pamięci (przy jednoczesnym zwiększeniu wydajności o 100 ms) jest z pewnością warte zachodu, ale istnieje znacznie większa wygrana wydajności. Nieprawdopodobnym celem tego ostatecznego ulepszenia jest skalar obliczeniowy tuż nad skanowaniem indeksu klastrowego.
Ten skalar obliczeniowy odnosi się do wyrażenia (0E + f.val) zawarte w AVG agregacja w zapytaniu. Jeśli wydaje ci się to dziwne, jest to dość powszechna sztuczka przy pisaniu zapytań (jak mnożenie przez 1,0), aby uniknąć arytmetyki liczb całkowitych w obliczeniach średniej, ale ma ona kilka bardzo ważnych skutków ubocznych.
Jest tu szczególna sekwencja wydarzeń, którą musimy śledzić krok po kroku.
Po pierwsze, zauważ, że 0E jest stałym dosłownym zerem, z zmienną zmiennoprzecinkową typ danych. Aby dodać to do wartości val kolumny integer, procesor zapytań musi przekonwertować kolumnę z liczby całkowitej na zmiennoprzecinkową (zgodnie z regułami pierwszeństwa typu danych). Podobny rodzaj konwersji byłby konieczny, gdybyśmy zdecydowali się pomnożyć kolumnę przez 1,0 (literał z niejawnym liczbowym typem danych). Ważne jest to, że ta rutynowa sztuczka wprowadza wyrażenie .
Teraz SQL Server zazwyczaj próbuje przesunąć wyrażenia w dół drzewo planu w miarę możliwości podczas kompilacji i optymalizacji. Dzieje się tak z kilku powodów, między innymi w celu ułatwienia dopasowywania wyrażeń z wyliczonymi kolumnami oraz uproszczenia przy użyciu informacji o ograniczeniach. Ta zasada przesuwania w dół wyjaśnia, dlaczego skalar obliczeniowy pojawia się znacznie bliżej poziomu liścia planu niż sugerowałaby oryginalna pozycja tekstowa wyrażenia w zapytaniu.
Ryzyko wykonania tego przesunięcia polega na tym, że wyrażenie może zostać obliczone więcej razy, niż jest to konieczne. Większość planów charakteryzuje się zmniejszaniem liczby wierszy, gdy poruszamy się w górę drzewa planów, ze względu na efekt łączeń, agregacji i filtrów. Przesuwanie wyrażeń w dół drzewa wiąże się zatem z ryzykiem oceny tych wyrażeń więcej razy (tj. w większej liczbie wierszy) niż to konieczne.
Aby to złagodzić, SQL Server 2005 wprowadził optymalizację, dzięki której skalary obliczeniowe mogą po prostu definiować wyrażenie, z pracą polegającą na faktycznej ocenie wyrażenie odroczone dopóki późniejszy operator w planie nie zażąda wyniku. Kiedy ta optymalizacja działa zgodnie z przeznaczeniem, efektem jest uzyskanie wszystkich korzyści płynących z przesuwania wyrażeń w dół drzewa, przy jednoczesnym ocenianiu wyrażenia tylko tyle razy, ile jest to rzeczywiście potrzebne.
Co to wszystko oznacza Compute Scalar
W naszym uruchomionym przykładzie 0E + val wyrażenie było pierwotnie powiązane z AVG zagregowane, więc możemy się spodziewać, że zobaczymy go w (lub nieco później) zagregowanym strumieniu. Jednak to wyrażenie zostało przesunięte drzewo, które stanie się nowym skalarem obliczeniowym zaraz po skanowaniu, z wyrażeniem oznaczonym jako [Wyr1004].
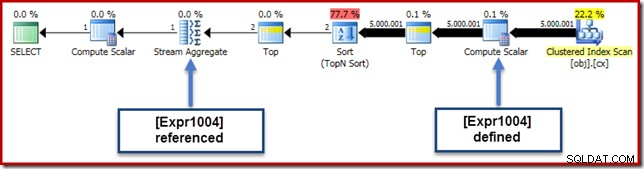
Patrząc na plan wykonania, widzimy, że [Expr1004] odwołuje się do Stream Aggregate (wyciąg z zakładki Plan Explorer Expressions Tab pokazany poniżej):

Jeśli wszystkie rzeczy są równe, ocena wyrażenia [Expr1004] byłaby odroczona dopóki agregat nie potrzebuje tych wartości do części sumy obliczenia średniej. Ponieważ agregat może napotkać tylko jeden lub dwa wiersze, powinno to spowodować, że [Expr1004] zostanie ocenione tylko raz lub dwa razy:
Niestety nie do końca tak to działa. Problemem jest blokujący operator sortowania:
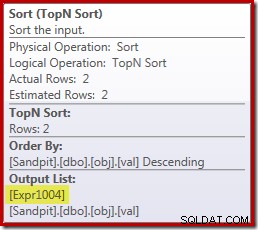
To wymusza ocenę [Expr1004], więc zamiast oceniania go tylko raz lub dwa razy w Stream Aggregate, sortowanie oznacza, że w końcu konwertujemy val kolumna do liczby zmiennoprzecinkowej i dodanie do niej zera 5,000,001 razy!
Obejście
Idealnie byłoby, gdyby SQL Server był nieco mądrzejszy w tym wszystkim, ale dzisiaj tak nie działa. Nie ma wskazówki dotyczącej zapytania, aby zapobiec wypychaniu wyrażeń w dół drzewa planu, a także nie możemy wymusić obliczeń skalarnych za pomocą przewodnika po planach. Nieuchronnie istnieje nieudokumentowana flaga śledzenia, ale nie jest to taka, o której mogę odpowiedzialnie mówić w obecnym kontekście.
Tak więc, na lepsze lub gorsze, to pozostawia nam to próbę znalezienia przepisanego zapytania, które akurat uniemożliwia SQL Server oddzielenie wyrażenia od agregacji i wypchnięcie go poza sortowanie, bez zmiany wyniku zapytania. Nie jest to tak proste, jak mogłoby się wydawać, ale (co prawda nieco dziwnie wyglądająca) modyfikacja poniżej osiąga to za pomocą CASE wyrażenie na niedeterministycznej funkcji wewnętrznej:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Plan wykonania dla tej ostatecznej formy zapytania jest pokazany poniżej:

Zauważ, że skalar obliczeniowy nie jest już wyświetlany między skanowaniem indeksu klastrowego a górą. 0E + val wyrażenie jest teraz obliczane w Stream Aggregate w maksymalnie dwóch wierszach (zamiast pięciu milionów!), a wydajność wzrasta o dalsze 32% od 3150ms do 2150ms w rezultacie.
To nadal nie jest tak dobre w porównaniu z wydajnością poniżej sekundy OFFSET i dynamiczne rozwiązania do obliczania mediany kursora, ale nadal stanowią bardzo znaczącą poprawę w stosunku do oryginalnych 5800 ms dla tej metody dla dużego zestawu problemów z pojedynczą medianą.
Oczywiście nie ma gwarancji, że sztuczka CASE zadziała w przyszłości. Na wynos nie tyle chodzi o używanie dziwnych sztuczek wyrażania wielkości liter, ile o potencjalne implikacje wydajnościowe skalarów obliczeniowych. Gdy już wiesz o tym, możesz pomyśleć dwa razy przed pomnożeniem przez 1,0 lub dodaniem zmiennoprzecinkowego zera w obliczeniach średniej.
Aktualizacja: zobacz pierwszy komentarz dotyczący fajnego obejścia autorstwa Roberta Heiniga, które nie wymaga żadnych nieudokumentowanych sztuczek. O czym należy pamiętać, gdy następnym razem będziesz kuszony, aby pomnożyć liczbę całkowitą przez dziesiętną (lub zmiennoprzecinkową) przez jeden w średniej agregacji.
Media zgrupowane
Aby uzyskać kompletność i ściślej powiązać tę analizę z oryginalnym artykułem Roba, na koniec zastosujemy te same ulepszenia do zgrupowanego obliczania mediany. Mniejsze rozmiary zestawów (na grupę) oznaczają oczywiście, że efekty będą mniejsze.
Pogrupowane mediany danych próbki (znowu w postaci pierwotnie stworzonej przez Aarona Bertranda) obejmują dziesięć tysięcy wierszy dla każdego ze stu wyimaginowanych sprzedawców:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
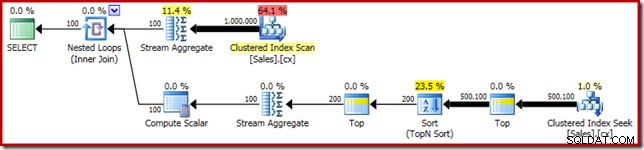
(SalesPerson, Amount); Bezpośrednie zastosowanie rozwiązania Roba Farleya daje następujący kod, który wykonuje się w 560ms na moim komputerze.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
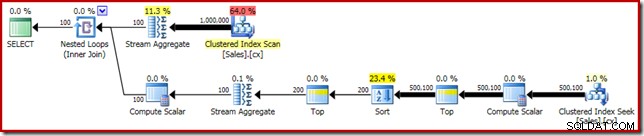
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Plan wykonania ma oczywiste podobieństwa do pojedynczej mediany:
Naszym pierwszym ulepszeniem jest zastąpienie sortowania sortowaniem Top N poprzez dodanie wyraźnego Top (2). To nieznacznie poprawia czas wykonania z 560 ms do 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Plan wykonania pokazuje sortowanie Top N zgodnie z oczekiwaniami:
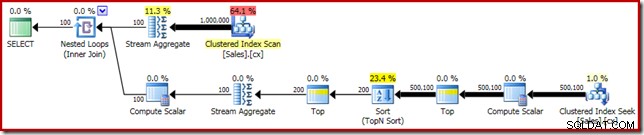
Na koniec wdrażamy dziwnie wyglądające wyrażenie CASE, aby usunąć wypchnięte wyrażenie Compute Scalar. To dodatkowo poprawia wydajność do 450 ms (20% poprawa w stosunku do oryginału):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Gotowy plan wykonania wygląda następująco: