W zeszłym roku przedstawiłem rozwiązanie symulujące czytelne pliki pomocnicze dostępne w grupie dostępności bez inwestowania w Enterprise Edition. Nie po to, aby powstrzymywać ludzi przed kupowaniem wersji Enterprise, ponieważ istnieje wiele korzyści poza AG, ale przede wszystkim dla tych, którzy nie mają szans na posiadanie wersji Enterprise Edition:
- Czytelne materiały pomocnicze w ramach budżetu
Staram się być nieugiętym orędownikiem klienta Wersji Standardowej; to prawie żart, że z pewnością – biorąc pod uwagę liczbę funkcji, jakie otrzymuje w każdym nowym wydaniu – ta edycja jako całość jest na ścieżce odrzucenia. Podczas prywatnych spotkań z firmą Microsoft naciskałem, aby funkcje były również uwzględnione w wersji Standard Edition, zwłaszcza w przypadku funkcji, które są znacznie korzystniejsze dla małych firm niż te z nieograniczonym budżetem sprzętowym.
Klienci wersji Enterprise Edition korzystają z zalet zarządzania i wydajności oferowanych przez partycjonowanie tabel, ale ta funkcja nie jest dostępna w wersji Standard Edition. Niedawno przyszło mi do głowy, że jest sposób na osiągnięcie przynajmniej niektórych zalet partycjonowania w dowolnej edycji i nie wymaga partycjonowania widoków. Nie oznacza to, że poglądy podzielone na partycje nie są realną opcją, którą warto rozważyć; są one dobrze opisane przez innych, w tym Daniela Hutmachera (Podzielone widoki na partycjonowanie tabel) i Kimberly Tripp (Podzielone tabele a widoki podzielone – dlaczego wciąż są dostępne?). Mój pomysł jest trochę prostszy do wdrożenia.
Twój nowy bohater:filtrowane indeksy
Teraz wiem, ta funkcja jest dla niektórych czteroliterowym słowem; zanim przejdziesz dalej, powinieneś czuć się komfortowo z filtrowanymi indeksami lub przynajmniej mieć świadomość ich ograniczeń. Trochę czytania, aby dać ci sprawiedliwą równowagę, zanim spróbuję ci je sprzedać:
- Opowiadam o kilku niedociągnięciach w tym, jak filtrowane indeksy mogą być potężniejszą funkcją, i zwracam uwagę na wiele elementów Connect, na które możesz zagłosować;
- Paul White (@SQL_Kiwi) mówi o problemach z dostrajaniem w ograniczeniach Optimizer z filtrowanymi indeksami, a także o nieoczekiwanym efekcie ubocznym dodawania filtrowanego indeksu; oraz,
- Jes Borland (@grrl_geek) mówi nam, co możesz (a czego nie możesz) zrobić z filtrowanymi indeksami.
Czytać to wszystko? A ty nadal tu jesteś? Świetnie.
TL; DR polega na tym, że możesz używać filtrowanych indeksów, aby przechowywać wszystkie swoje „gorące dane” w oddzielnej strukturze fizycznej, a nawet na oddzielnym sprzęcie bazowym (możesz mieć dostępny szybki dysk SSD lub PCIe, ale może „ trzymaj cały stół).
Szybki przykład
Istnieje wiele przypadków użycia, w których część danych jest odpytywana znacznie częściej niż reszta – pomyśl o sklepie detalicznym zarządzającym zamówieniami, piekarni planującej dostawy tortu weselnego lub stadionie piłkarskim mierzącym dane dotyczące frekwencji i koncesji. W takich przypadkach większość lub cała codzienna aktywność związana z zapytaniami dotyczy „bieżących” danych.
Niech to będzie proste; stworzymy bazę danych z bardzo wąską tabelą Orders:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
Załóżmy teraz, że masz wystarczająco dużo miejsca w szybkiej pamięci masowej, aby przechowywać dane z miesiąca (z dużą ilością miejsca na sezonowość i przyszły wzrost). Możemy dodać nową grupę plików i umieścić plik danych na szybkim dysku.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
Teraz utwórzmy filtrowany indeks w naszej grupie plików HotData, w której filtr obejmuje wszystko od początku listopada 2015 r., a wspólne kolumny związane z zapytaniami opartymi na czasie znajdują się na liście kluczy lub włączeń:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData; Możemy wstawić kilka wierszy i sprawdzić plan wykonania, aby mieć pewność, że objęte zapytania mogą w rzeczywistości korzystać z indeksu:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106'; Wynikowy plan wykonania z pewnością korzysta z filtrowanego indeksu (nawet jeśli predykat filtra w zapytaniu nie jest dokładnie zgodny z definicją indeksu):
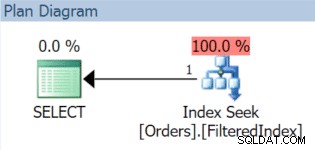
Teraz nadchodzi 1 grudnia i nadszedł czas, aby wymienić nasze listopadowe dane i zastąpić je grudniem. Możemy po prostu odtworzyć filtrowany indeks z nowym predykatem filtra i użyć DROP_EXISTING opcja:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; Teraz możemy dodać kilka dodatkowych wierszy, sprawdzić statystyki partycji i uruchomić nasze poprzednie zapytanie oraz nowe, aby sprawdzić używane indeksy:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; W tym przypadku otrzymujemy skan indeksu klastrowego z zapytaniem listopadowym:
(Ale byłoby inaczej, gdybyśmy mieli oddzielny, niefiltrowany indeks z OrderDate jako kluczem).
I nie pokażę tego ponownie, ale w przypadku zapytania z grudnia otrzymujemy takie samo przefiltrowane wyszukiwanie indeksu jak poprzednio.
Możesz także utrzymywać wiele indeksów, jeden dla bieżącego miesiąca, jeden dla poprzedniego miesiąca itd., i możesz nimi zarządzać osobno (na przykład 1 grudnia po prostu odrzucasz indeks z października i zostawiasz na przykład listopad). . Możesz także utrzymywać wiele indeksów krótszych lub dłuższych przedziałów czasowych (bieżący i poprzedni tydzień, bieżący i poprzedni kwartał) itp. Rozwiązanie jest dość elastyczne.
Ze względu na ograniczenia indeksów filtrowanych nie będę próbował wciskać tego jako idealnego rozwiązania, ani całkowitego zastąpienia partycjonowania tabel lub widoków partycjonowanych. Na przykład wyłączenie partycji jest operacją na metadanych podczas ponownego tworzenia indeksu za pomocą DROP_EXISTING może mieć dużo rejestrowania (a ponieważ nie korzystasz z wersji Enterprise, nie można go uruchomić online). Może się również okazać, że widoki partycjonowane są szybsze – jest więcej pracy nad utrzymywaniem oddzielnych tabel fizycznych i ograniczeń, które umożliwiają widok partycjonowany, ale opłacalność pod względem wydajności zapytań może być w niektórych przypadkach lepsza.
Automatyzacja
Czynność ponownego tworzenia indeksu można dość łatwo zautomatyzować, używając prostego zadania, które robi coś takiego raz w miesiącu (lub jakikolwiek inny jest twój "gorący" rozmiar okna):
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
Możesz także tworzyć wiele indeksów z miesięcznym wyprzedzeniem, podobnie jak tworzenie przyszłych partycji z wyprzedzeniem — w końcu przyszłe indeksy nie zajmą miejsca, dopóki nie pojawią się dane istotne dla ich predykatów. Możesz po prostu usunąć indeksy, które segmentowały starsze dane, które teraz chcesz schłodzić.
Wzroku
Po skończeniu tego artykułu, oczywiście, natknąłem się na kolejny post Kimberly Tripp, który powinieneś przeczytać przed kontynuowaniem czegokolwiek, o czym tutaj opowiadam (i który przeczytałem, zanim zacząłem):
- Co powiesz na filtrowane indeksy zamiast partycjonowania?
Z wielu powodów Kimberly zdecydowanie bardziej opowiada się za widokami partycjonowanymi, aby zaimplementować coś podobnego do partycjonowania w wersji Standard Edition; jednak w niektórych scenariuszach użycie filtrowanych indeksów nadal intryguje mnie na tyle, aby kontynuować moje eksperymenty. Jednym z obszarów, w których filtrowane indeksy mogą być korzystne, jest sytuacja, w której „gorące” dane mają wiele kryteriów – nie tylko podzielone według daty, ale także według innych atrybutów (być może potrzebujesz szybkich zapytań do wszystkich zamówień z tego miesiąca, które dotyczą określonego poziomu klienta lub powyżej określonej kwoty w dolarach).
Następny…
W przyszłym poście będę bawić się tą koncepcją w systemie z wyższej półki, z pewną ilością i obciążeniem pracą w świecie rzeczywistym. Chcę odkryć różnice w wydajności między tym rozwiązaniem, niefiltrowanym indeksem pokrywającym, widokiem podzielonym na partycje i tabelą podzieloną na partycje. Wewnątrz maszyny wirtualnej na laptopie z dostępnymi tylko dyskami SSD prawdopodobnie nie dałoby się uzyskać realistycznych ani uczciwych testów na dużą skalę.