Uwaga:ten post został pierwotnie opublikowany tylko w naszym e-booku, Techniki wysokiej wydajności dla SQL Server, tom 4. Możesz dowiedzieć się o naszych e-bookach tutaj.
Często otrzymuję pytanie:„Od czego zacząć, jeśli chodzi o dostrajanie instancji SQL Server?” Moją pierwszą odpowiedzią jest pytanie o konfigurację ich instancji. Jeśli pewne rzeczy nie są poprawnie skonfigurowane, natychmiastowe przyjrzenie się długo działającym lub kosztownym zapytaniom może być zmarnowanym wysiłkiem.
Pisałem na blogu o typowych rzeczach, których brakuje administratorom, gdzie udostępniam wiele ustawień, które administratorzy powinni zmienić z domyślnej instalacji SQL Server. W przypadku elementów związanych z wydajnością mówię im, że powinni sprawdzić następujące elementy:
- Ustawienia pamięci
- Aktualizowanie statystyk
- Utrzymanie indeksu
- MAXDOP i próg kosztów dla równoległości
- najlepsze praktyki tempdb
- Optymalizuj pod kątem obciążeń ad hoc
Gdy przejdę przez elementy konfiguracji, pytam, czy obejrzeli statystyki plików i oczekiwania, a także zapytania o wysokim koszcie. W większości przypadków odpowiedź brzmi „nie” – z wyjaśnieniem, że nie są pewni, jak znaleźć te informacje.
Zazwyczaj powszechną zgodnością, gdy ktoś mówi, że musi dostroić SQL Server, jest to, że działa on wolno. Co oznacza wolno? Czy to jakiś raport, konkretna aplikacja, czy wszystko? Czy to właśnie zaczęło się dziać, czy też z biegiem czasu było coraz gorzej? Zaczynam od zadawania zwykłych pytań dotyczących oceny, jakie jest porównanie wykorzystania pamięci, procesora i dysku z normalnym stanem rzeczy, czy problem dopiero się zaczął i co ostatnio się zmieniło. O ile klient nie rejestruje punktu odniesienia, nie ma danych, z którymi można by porównać, aby wiedzieć, czy obecne statystyki są nieprawidłowe.
Prawie każdy serwer SQL, na którym pracuję, obsługuje więcej niż jedną bazę danych użytkowników. Gdy klient zgłasza, że program SQL Server działa wolno, przez większość czasu jest zaniepokojony konkretną aplikacją, która powoduje problemy u jego klientów. Odruchową reakcją jest natychmiastowe skupienie się na tej konkretnej bazie danych, jednak często inny proces może zużywać cenne zasoby i ma to wpływ na bazę danych aplikacji. Na przykład, jeśli masz dużą bazę danych raportowania i ktoś wygenerował ogromny raport, który nasyca dysk, zwiększa moc procesora i opróżnia pamięć podręczną planu, możesz się założyć, że inne bazy danych użytkowników spowolnią podczas generowania tego raportu.
Zawsze lubię zaczynać od przejrzenia statystyk plików. W przypadku SQL Server 2005 i nowszych można wysłać zapytanie do DMV sys.dm_io_virtual_file_stats, aby uzyskać statystyki we/wy dla każdego pliku danych i dziennika. Ten DMV zastąpił funkcję fn_virtualfilestats. Aby przechwycić statystyki plików, lubię użyć skryptu, który ułożył Paul Randal:przechwytywanie opóźnień we/wy przez pewien okres czasu. Ten skrypt przechwyci linię bazową i 30 minut później (chyba że zmienisz czas trwania w sekcji CZEKAJ NA OPÓŹNIENIE), przechwyci statystyki i obliczy delty między nimi. Skrypt Paula wykonuje również trochę matematyki, aby określić opóźnienia odczytu i zapisu, co znacznie ułatwia nam czytanie i rozumienie.
Na moim laptopie przywróciłem kopię bazy danych AdventureWorks2014 na dysk USB, aby mieć wolniejsze prędkości dysku; Następnie uruchomiłem proces, aby wygenerować ładunek przeciwko niemu. Poniżej możesz zobaczyć wyniki, w których opóźnienie zapisu mojego pliku danych wynosi 240 ms, a opóźnienie zapisu mojego pliku dziennika wynosi 46 ms. Tak wysokie opóźnienia są kłopotliwe.
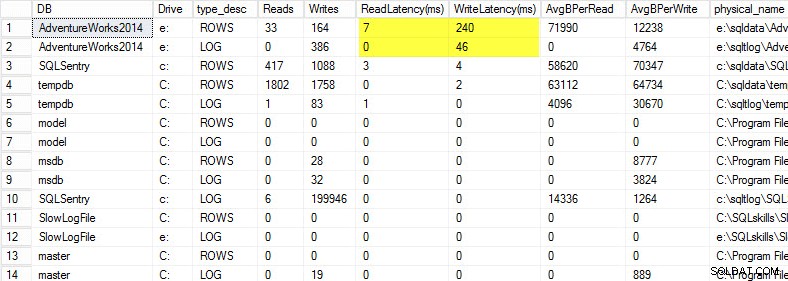
Wszystko powyżej 20 ms należy uznać za złe, jak podzieliłem się w poprzednim poście:monitorowanie opóźnień odczytu/zapisu. Moje opóźnienie odczytu jest przyzwoite, ale baza danych AdventureWorks2014 cierpi na powolne zapisy. W tym przypadku zbadałbym, co generuje zapisy, a także zbadał wydajność mojego podsystemu I/O. Gdyby to były zbyt duże opóźnienia odczytu, zacząłbym badać wydajność zapytań (dlaczego wykonuje tak wiele odczytów, na przykład z brakujących indeksów), a także ogólną wydajność podsystemu I/O.
Ważne jest, aby znać ogólną wydajność podsystemu we/wy, a najlepszym sposobem sprawdzenia jego możliwości jest przeprowadzenie testów porównawczych. Glenn Berry mówi o tym w swoim artykule analizującym wydajność I/O dla SQL Server. Glenn wyjaśnia opóźnienia, IOPS i przepustowość oraz pokazuje CrystalDiskMark, które jest darmowym narzędziem, którego można użyć do bazowania pamięci masowej.
Po ustaleniu, jak działają statystyki plików, lubię spojrzeć na statystyki oczekiwania za pomocą DMV sys.dm_os_wait_stats, który zwraca informacje o wszystkich oczekiwaniach, które wystąpiły. W tym celu zwracam się do innego skryptu, który Paul Randal udostępnia w swoim tworzeniu statystyk oczekiwania na pewien okres czasu na blogu. Scenariusz Paula znowu trochę dla nas matematycznie, ale, co ważniejsze, wyklucza wiele łagodnych oczekiwań, na których zwykle nie zależy. Ten skrypt ma również OPÓŹNIENIE OCZEKIWANIA i jest ustawiony na 30 minut. Odczytywanie statystyk oczekiwania może być nieco trudniejsze:możesz mieć oczekiwania, które wydają się być wysokie w oparciu o wartości procentowe, ale średni czas oczekiwania jest tak niski, że nie ma się czym martwić.
Rozpocząłem ten sam proces ładowania i uchwyciłem moje statystyki oczekiwania, które pokazałem poniżej. Aby uzyskać wyjaśnienia dotyczące wielu z tych typów oczekiwania, możesz przeczytać inny post Paula na blogu, statystyki oczekiwania lub proszę powiedzieć mi, gdzie boli, a także kilka jego postów na tym blogu.
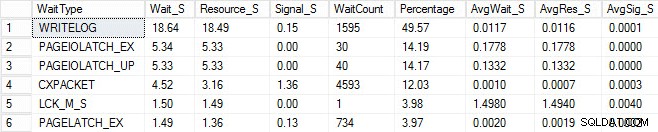
W tych wymyślonych danych wyjściowych czekanie PAGEIOLATCH może wskazywać na wąskie gardło w moim podsystemie we/wy, ale może to być również problem z pamięcią, skanowanie tabeli zamiast wyszukiwania lub wiele innych problemów. W moim przypadku wiemy, że jest to problem z dyskiem, ponieważ przechowuję bazę danych na pendrive'ie. Czas oczekiwania LCK_M_S jest bardzo długi, jednak istnieje tylko jedna instancja oczekiwania. Mój WRITELOG jest również wyższy, niż bym chciał, ale jest zrozumiałe, wiedząc o problemach z opóźnieniami w pamięci USB. Pokazuje to również, że CXPACKET czeka, i łatwo byłoby mieć odruchową reakcję i pomyśleć, że masz problem z równoległością/MAXDOP, jednak licznik AvgWait_S jest bardzo niski. Zachowaj ostrożność podczas używania czeka na rozwiązanie problemu. Niech będzie przewodnikiem, który powie ci, co nie stanowi problemu, a także poda kierunek, gdzie szukać problemów. Właściwe rozwiązywanie problemów polega na skorelowaniu zachowań z wielu obszarów w celu zawężenia problemu.
Po przejrzeniu pliku i statystykach oczekiwania zaczynam kopać w zapytaniach o wysokich kosztach w oparciu o znalezione problemy. W tym celu zwracam się do informacji diagnostycznych Glenna Berry'ego. Te zestawy zapytań to skrypty, z których korzysta wielu konsultantów. Glenn i społeczność stale dostarczają aktualizacje, aby były jak najbardziej informacyjne i solidne. Jednym z moich ulubionych zapytań jest najczęściej buforowane zapytania według liczby wykonań. Uwielbiam znajdować zapytania lub procedury składowane, które mają wysoką liczbę_wykonań w połączeniu z wysokimi wartościami total_logical_reads. Jeśli te zapytania mają możliwości dostrajania, możesz szybko zmienić serwer. Skrypty uwzględniają również górne buforowane SP według łącznej liczby odczytów logicznych i górne buforowane SP według łącznej liczby odczytów fizycznych. Obie te opcje są dobre do wyszukiwania wysokich odczytów z dużą liczbą wykonań, dzięki czemu można zmniejszyć liczbę operacji we/wy.
Oprócz skryptów Glenna lubię używać sp_whoisactive Adama Machanica, aby zobaczyć, co jest aktualnie uruchomione.
Dostrajanie wydajności to o wiele więcej niż tylko przeglądanie statystyk plików i czekania oraz zapytań o wysokich kosztach, jednak od tego lubię zaczynać. Jest to sposób na szybkie sprawdzenie środowiska i rozpoczęcie określania przyczyny problemu. Nie ma całkowicie niezawodnego sposobu na dostrojenie:to, czego potrzebuje każdy produkcyjny administrator DBA, to lista kontrolna czynności do wykonania w celu wyeliminowania i naprawdę dobry zbiór skryptów do wykonania w celu przeanalizowania stanu systemu. Posiadanie linii bazowej jest kluczem do szybkiego wykluczenia normalnego lub nienormalnego zachowania. Moja dobra przyjaciółka Erin Stellato ma cały kurs na temat Pluralsight o nazwie SQL Server:Benchmarking and Baselining, jeśli potrzebujesz pomocy w skonfigurowaniu i uchwyceniu swojej linii bazowej.
Co więcej, uzyskaj najnowocześniejsze narzędzie, takie jak SQL Sentry Performance Advisor, które nie tylko będzie gromadzić i przechowywać informacje historyczne na potrzeby profilowania i trendów, a także zapewnia łatwy dostęp do wszystkich szczegółów wymienionych powyżej i nie tylko, ale także zapewnia możliwość porównywania aktywności z wbudowanymi lub zdefiniowanymi przez użytkownika liniami bazowymi, efektywnego utrzymywania indeksów bez kiwnięcia palcem oraz ostrzegania lub automatyzacji odpowiedzi w oparciu o bardzo solidną architekturę warunków niestandardowych. Poniższy zrzut ekranu przedstawia widok historyczny pulpitu Performance Advisor z oczekiwaniem na dysku w kolorze pomarańczowym, we/wy bazy danych w prawym dolnym rogu i liniami bazowymi porównującymi bieżący i poprzedni okres na każdym wykresie (kliknij, aby powiększyć):
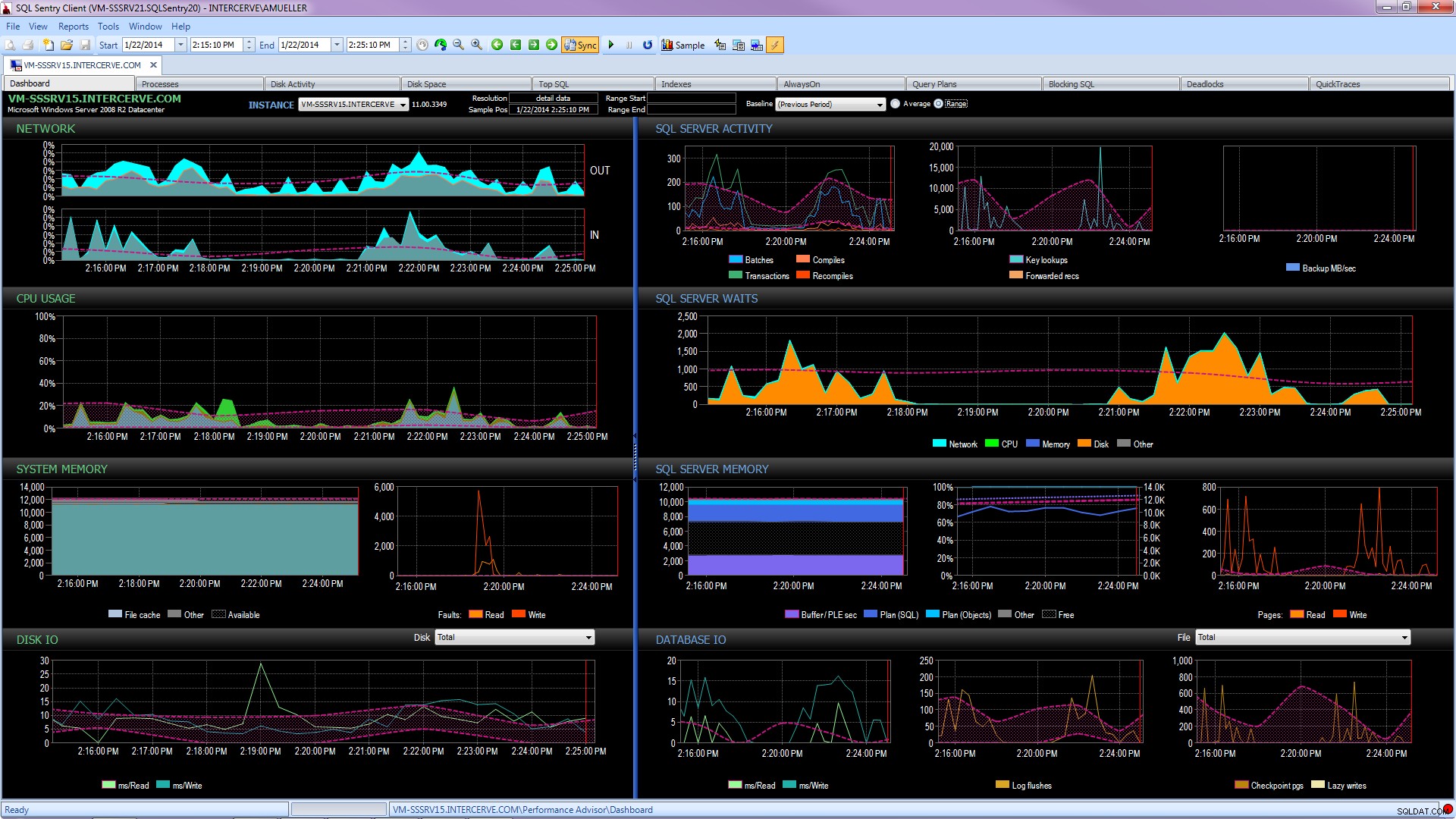
Narzędzia do monitorowania jakości nie są bezpłatne, ale zapewniają mnóstwo funkcji i wsparcia, które pozwalają skupić się na problemach z wydajnością na serwerach, zamiast skupiać się na zapytaniach, zadaniach i alertach, które mogą pozwalają Ci skoncentrować się na problemach z wydajnością – ale tylko wtedy, gdy je naprawisz. Niewymyślanie koła na nowo ma często wielką wartość.