Pisałem wcześniej o korzyściach płynących z używania NOEXPAND podpowiedzi, nawet w wersji Enterprise Edition. Wszystkie szczegóły znajdują się w artykule, do którego prowadzi link, ale krótko podsumowując:
- SQL Server będzie tylko automatycznie utworzył statystyki zindeksowanego widoku, gdy
NOEXPANDużywana jest wskazówka tabeli. Pominięcie tej wskazówki może prowadzić do ostrzeżeń planu wykonania o brakujących statystykach, których nie można rozwiązać, tworząc statystyki ręcznie. - SQL Server będzie tylko używał automatycznie lub ręcznie tworzone statystyki widoku w obliczeniach szacowania liczności, gdy zapytanie odwołuje się bezpośrednio do widoku i
NOEXPANDpodpowiedź jest używana. W przypadku wszystkich, z wyjątkiem najbardziej trywialnych definicji widoków, oznacza to, że jakość oszacowań kardynalności może być niższa, gdy ta wskazówka nie jest używana, co często skutkuje mniej optymalnymi planami wykonania. - Brak lub niemożność użycia statystyk widoku może spowodować, że optymalizator będzie odgadywał oszacowania kardynalności, nawet jeśli dostępne są statystyki tabeli podstawowej. Może się to zdarzyć, gdy część planu zapytania zostanie zastąpiona indeksowanym odwołaniem widoku przez funkcję automatycznego dopasowywania widoków, ale statystyki widoku nie są dostępne, jak opisano powyżej.
Jest jeszcze jedna konsekwencja nieużywania NOEXPAND wskazówka, o której wspomniałem kilka lat temu w moim artykule, Ograniczenia Optimizer with Filtered Indexes:
NOEXPAND wskazówki są potrzebne nawet w wersji Enterprise, aby zapewnić, że gwarancja unikalności zapewniana przez indeksy widoków jest używana przez optymalizator.
W tym artykule bardziej szczegółowo przeanalizujemy to stwierdzenie i jego implikacje.
Konfiguracja wersji demonstracyjnej
Poniższy skrypt tworzy prostą tabelę i widok indeksowany:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Tworzy to pojedynczą tabelę sterty kolumn i nieograniczony widok tej samej tabeli z unikalnym indeksem klastrowym. Nie jest to realistyczny przypadek użycia dla widoku indeksowanego; ale pomoże zilustrować kluczowe punkty przy minimalnym rozpraszaniu uwagi. Ważnym punktem jest to, że tabela bazowa tutaj nie ma żadnych indeksów (nawet indeksu klastrowego), ale widok ma, a ten indeks jest unikalny.
Przykładowe zapytanie
Rozważ następujące proste zapytanie względem tabeli bazowej:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Plan wykonania, który zobaczysz dla tego zapytania, zależy od używanej wersji SQL Server. Jeśli nie Enterprise Edition (lub odpowiednik), zobaczysz plan podobny do tego:

Optymalizator zapytań SQL Server wybrał przeskanowanie tabeli podstawowej i zastosowanie określonej odrębności przy użyciu operatora Distinct Sort. Ten kształt planu jest w pełni oczekiwany, ponieważ automatyczne dopasowywanie widoków indeksowanych nie jest dostępne poza Enterprise Edition. Od tego momentu przestanę mówić „Enterprise Edition lub ekwiwalent”, ale proszę dalej wywnioskować, że mam na myśli każdą edycję, która obsługuje automatyczne dopasowywanie widoku, gdy mówię „Enterprise Edition”.
Wskazówka ROZWIJAJ WIDOKI
To trochę na marginesie, ale aby uzyskać ten sam plan w wersji Enterprise, musimy użyć EXPAND VIEWS wskazówka dotycząca zapytania:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Użycie tej wskazówki może wydawać się nieco dziwne, gdy brak odniesień do widoków w zapytaniu, ale tak to działa. EXPAND VIEWS wskazówka skutecznie określa, że dopasowywanie widoków indeksowanych powinno być wyłączone podczas kompilowania i optymalizacji zapytania. Dla jasności:bez tej wskazówki Enterprise Edition może w inny sposób dopasować (części) zapytanie do jednego lub więcej zindeksowanych widoków.
Z włączonym automatycznym dopasowywaniem widoków
Bez EXPAND VIEWS wskazówka, kompilacja tego samego zapytania w wersji Developer Edition (na przykład) daje inny plan:
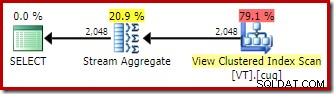
Zastosowanie dopasowywania widoków indeksowanych oznacza, że plan wykonania obejmuje skanowanie indeksu klastrowego widoku zamiast skanowania tabeli bazowej.
Ten sam plan jest tworzony w tym przypadku, jeśli zapytanie odwołuje się bezpośrednio do widoku (zamiast tabeli bazowej):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; We wszystkich wydaniach odwołanie do widoku jest rozwijane przed rozpoczęciem optymalizacji zapytań. W wersjach równoważnych Enterprise, rozwinięty formularz może być później dopasowany z powrotem do widoku. Jest to kluczowa koncepcja, którą należy zrozumieć, gdy myślimy o tym, jak kompilator i optymalizator zapytań wykorzystują widoki indeksowane w SQL Server.
Agregacja strumienia
Najbardziej interesującą różnicą między dwoma planami, które widzieliśmy do tej pory, jest Stream Aggregate w planie z dopasowaniem widoku. Jeśli spojrzysz na szacunkowe koszty operatorów Table Scan i View Scan, zobaczysz, że są one dokładnie takie same. Optymalizator nie zdecydował się na użycie widoku indeksowanego, ponieważ dzięki temu dostęp do danych stał się tańszy. Zamiast tego skanowanie indeksu widoku pozwala na DISTINCT wymóg implementacji jako Stream Aggregate, a nie Hash Aggregate lub Distinct Sort (jak w pierwszym planie).
Stream Aggregate wymaga danych wejściowych uporządkowanych według kolumn grupujących. W takim przypadku wyróżnienie jest równoważne grupowaniu według pojedynczej kolumny, a unikatowy indeks klastrowy widoku zapewnia niezbędną gwarancję porządkowania. Model kosztów optymalizatora identyfikuje Stream Aggregate jako tańszą opcję niż Distinct Sort lub Hash Aggregate dla tego zapytania. Jest to podstawa dla optymalizatora decydującego się na dostęp do zindeksowanego widoku, gdy dostępne jest automatyczne dopasowywanie widoków.
Biorąc pod uwagę wszystko, co zostało powiedziane i zrozumiane, Stream Aggregate jest nadal nieoczekiwany:biorąc pod uwagę gwarancję unikalności zapewnianą przez indeks widoku, nie ma potrzeby wykonywania tej operacji grupowania w ogóle. wyjątkowy indeks klastrowy już zapewnia, że kolumna nie zawiera duplikatów.
Na tym, w skrócie, jest problem. Gdy używane jest automatyczne dopasowywanie widoków, optymalizator rozpoznaje gwarancję kolejności zapewnianą przez indeks widoku, ale nie gwarantuje niepowtarzalności.
Korzystanie z podpowiedzi NOEXPAND
Aby uzyskać idealny plan wykonania dla tego zapytania, musimy bezpośrednio odwołać się do widoku i użyć NOEXPAND wskazówka tabeli:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Daje nam to plan, jakiego oczekiwałaby doświadczona osoba zajmująca się bazą danych; taki, który poprawnie rozpoznaje, że odrębna operacja jest zbędna i można ją usunąć:
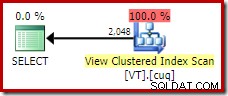
Drugi przykład
Nieskorzystanie z gwarancji unikalności zapewnianej przez indeks widoku może mieć inny wpływ na ostateczny plan wykonania. Rozważmy teraz samo złączenie indeksowanego widoku (ponownie, aby zilustrować koncepcję – nie ma to być realistyczne zapytanie):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Korzystając z wersji Developer Edition, wybrany plan wykonania w ogóle nie ma dostępu do widoku indeksowanego i zawiera sprzężenie haszujące (czasami oznacza to, że brakuje przydatnego indeksu):
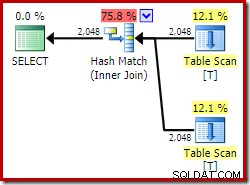
Teraz spróbujmy dokładnie to samo zapytanie, ale z NOEXPAND wskazówka dotycząca każdego odnośnika widoku:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Plan wykonania zawiera teraz dwa indeksowane dostępy do widoków i połączenie scalające:
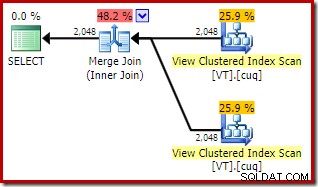
Ten nowy plan ma znacznie niższy szacowany koszt niż plan łączenia mieszającego, dlaczego więc optymalizator nie wybrał wcześniej tej opcji? Możemy zobaczyć dlaczego, dodając wskazówkę dotyczącą łączenia scalającego do oryginalnego zapytania:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Daje to podobny wygląd plan, który decyduje się na dostęp do widoku, mimo że NOEXPAND nie określono:
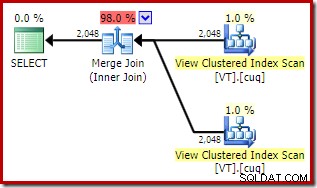
Całkowity szacunkowy koszt tego planu jest wyższy niż w obu poprzednich przykładach. Połączenie scalające w tym planie stanowi również wyższy odsetek całkowitego szacowanego kosztu niż wcześniej (98% w porównaniu do 48,2%).
Powód tego można zobaczyć, patrząc na właściwości złączenia scalającego. W NOEXPAND plan, było to połączenie scalające jeden-do-wielu. W planie bezpośrednio powyżej jest to połączenie scalające wiele do wielu. Model kosztów optymalizatora przypisuje wyższy koszt łączeniom scalającym wiele do wielu, ponieważ do obsługi wszelkich duplikatów potrzebna jest tabela robocza tempdb.
Wnioski
Gwarancje, jakie daje unikalny indeks, mogą być potężnym narzędziem optymalizacyjnym, więc szkoda, że obecnie automatyczne dopasowywanie indeksów nie jest w stanie z niego skorzystać. Potencjalne korzyści wykraczają poza eliminację niepotrzebnych agregacji lub umożliwienie łączenia scalającego jeden-do-wielu, jak widać w poprzednich prostych przykładach. Ogólnie rzecz biorąc, trudno zauważyć, że plan wykonania jest nieoptymalny, ponieważ optymalizator nie skorzystał z gwarancji niepowtarzalności.
To ograniczenie optymalizatora dotyczy nie tylko unikalnego indeksu klastrowego, który musi mieć widok, aby mógł zostać zmaterializowany. W bardziej złożonych scenariuszach w widoku mogą być również obecne dodatkowe indeksy nieklastrowane; być może w celu odzwierciedlenia relacji krzyżowych, które są trudne do wyegzekwowania lub przedstawienia w inny sposób. Jeśli te indeksy nieklastrowane zostaną zdefiniowane jako unikatowe, optymalizator przeoczy również te gwarancje, jeśli zostanie użyte automatyczne dopasowywanie indeksów.
Dodając to do ograniczeń związanych z tworzeniem i wykorzystywaniem informacji statystycznych, wydaje się, że poleganie na automatycznym dopasowywaniu widoków może skutkować gorszymi planami wykonania. Najbezpieczniejszą opcją jest prawdopodobnie jawne odwoływanie się do widoków indeksowanych i użycie NOEXPAND podpowiedź za każdym razem – przynajmniej do czasu rozwiązania tych problemów w produkcie.
Czynniki łagodzące
Należy podkreślić, że problem opisany w tym artykule dotyczy tylko gwarancji unikalności, jaką zapewnia unikalny indeks widoku. Jeśli optymalizator może uzyskać wymagane informacje o niepowtarzalności inny sposób , są duże szanse na uniknięcie problemów z optymalizacją.
Na przykład może istnieć odpowiedni unikalny indeks w tabeli bazowej, do której odwołuje się widok. Lub, w przypadku widoku zawierającego agregację, optymalizator może już wywnioskować użyteczną gwarancję unikalności na podstawie GROUP BY widoku klauzula. Powszechna praktyka dodawania indeksu klastrowego widoku do kluczy grupujących nie dodaje w takim przypadku żadnych dodatkowych informacji o unikalności.
Niemniej jednak zdarzają się sytuacje, w których to „nadzór nad unikatowością” może oznaczać, że uzyskasz lepszą jakość planów wykonania, używając wyraźnego odniesienia do widoku i NOEXPAND podpowiedzi, nawet w wersji Enterprise.